基于多尺度特征融合的行人检测方法
2021-06-24李岩孟令军
李岩, 孟令军
(中北大学 电子测试技术国防科技重点实验室, 山西 太原 030051)
0 引言
随着人们对公共安全领域日益重视,行人检测技术在智能监控和无人驾驶领域得到了广泛的应用[1]。传统的行人检测方法依赖于从训练样本中手动提取特征,精度低、模型泛化性差,难以适应复杂的行人场景[2]。相对于传统方法,行人检测方法的性能随着卷积神经网络的发展得到了极大的提高。
然而,在公共安全领域,检测智能监控下不同大小的行人目标仍然是一个挑战。当待检测行人目标送入具有自上而下结构的检测模型中,小尺度行人目标随着卷积层数的增加,特征图逐渐变小,丢失可识别特征信息,较难被检测。大尺度行人目标由于面积和感受野较大,特征信息也更丰富,较容易被检测。针对多尺度检测问题,有两种常用的方法:图像和特征金字塔。前者,将图片缩放为不同大小,并对缩放后的图片提取特征。后者把输入图像转换为特征图,在不同尺度上进行特征融合,将特征信息与空间性互补。
相对于图像金字塔,特征金字塔不需要识别多种分辨率的图像,具有速度快、精度高的特点,被广泛应用于目标检测任务中。典型的网络有特征金字塔网络(FPN)[3]、物体检测骨干网络(DetNet)[4]和反卷积单发多框检测网络(DSSD)[5]。FPN采取级联融合上采样得到的特征图,形成金字塔结构;DetNet利用空洞卷积与残差结构,使得多个融合后的特征图尺寸相同,避免上采样操作;DSDD在SSD[6]的基础上,在对应的通道上将深浅特征图作乘法运算。
为了提高在智能监控下行人检测的精度,本文在YOLOv3[7]的基础上,引入SPP和ASFF结构,融合不同特征图中的位置和分类信息,同时采用k-means算法,修改锚框的尺寸。实验表明,引入改进策略的算法,在INRIA和VOC混合行人数据集有更好的检测性能。
1 YOLOv3算法检测原理
YOLOv3是一种基于端到端的检测算法,由神经网络基本结构CBL_n和残差网络Res搭建而成,如图1所示。
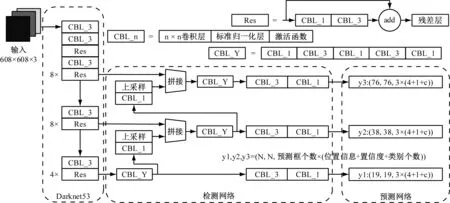
图1 YOLOv3网络结构图
其中,n代表卷积层卷积核的大小,标准归一化层可以加快网络速度,抑制梯度爆炸,防止过拟合,激活函数可以提高模型表达能力,Res可以改善网络退化问题,CBL_Y表示多个神经网络基本结构相连接。YOLOv3网络结构主要分为三个部分,首先Darknet-53提取固定尺寸的输入图像,将特征送入检测网络。然后检测网络借鉴了FPN的思想,以上采样级联的方式融合不同网络层,输出19×19、38×38和76×76三种不同尺度的特征图,获得了更好的细粒度特征[8]。最后预测网络对目标位置信息和类别的置信度进行预测,使用非极大值抑制算法确定真实目标框。
2 YOLOv3算法改进
2.1 空间金字塔池化
当图像中的行人目标差异较大,YOLOv3算法提取特征能力不足,漏检率高,精度降低。本文借鉴YOLOv3-SPP和SPP-net[9]的空间金字塔思想,在三个尺度检测YOLO层前引入SPP层,融合不同大小的特征,提高模型精度。最大池化层利用大小为5×5、9×9、13×13过滤器在n×n的特征图上滑动,大小为1的步长保证了特征图输入与输出的大小一致,最后在融合层将四个特征图的通道进行拼接,如图2所示。

图2 SPP层网络结构
SPP采用级联融合的方式,融合后特征图的通道变为原来的四倍,并保留了原始特征[10],如式(1)。
ycat=fcat(xa,xb,xc,xd)
(1)
SPP层引入位置的不同,对模型的检测精度和参数量有不同的影响,经过多次综合实验,将图1中,三条分支的CBL_Y网络替换为图3中对应y1,y2,y3网络,效果最优,如图3所示。
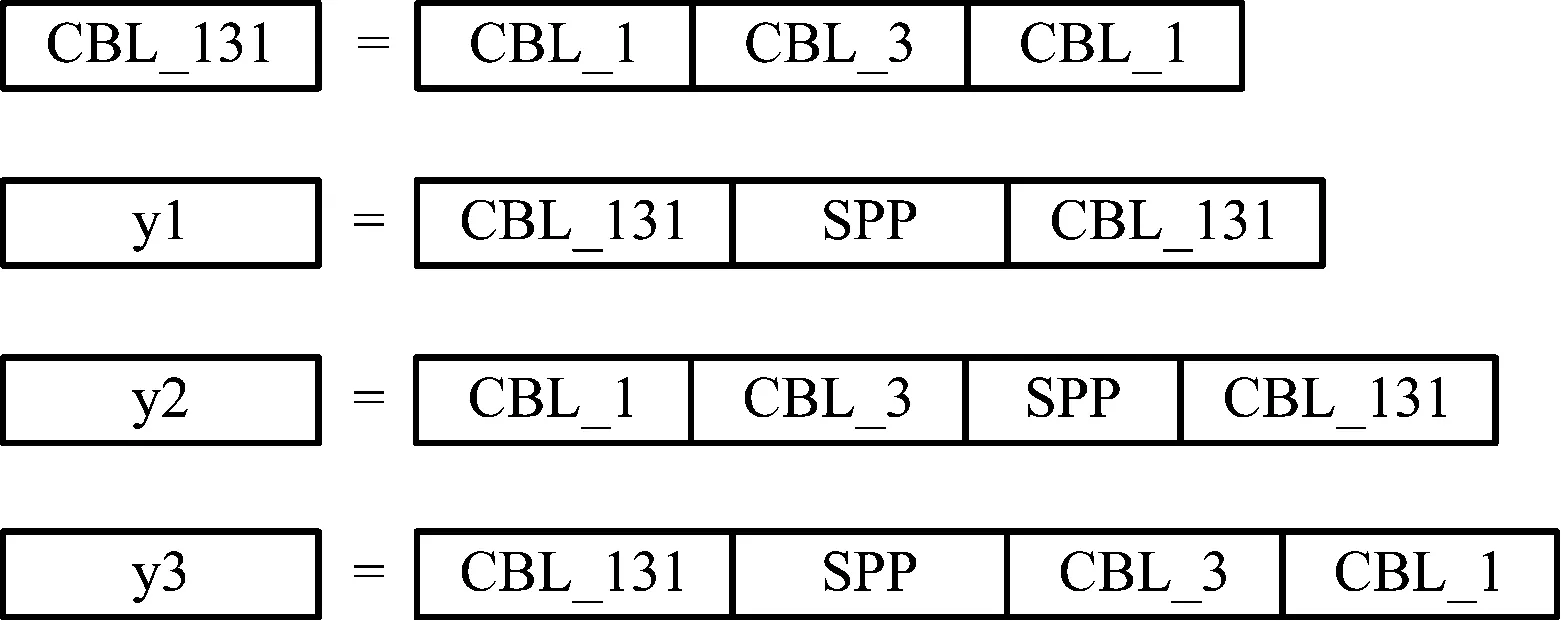
图3 YOLOv3引入SPP
CBL_131代表三个带有标准归一化层和激活函数的卷积层相连接,卷积核大小分别为1×1、3×1、1×1。
SPP层通过池化操作,特征拼接,实现局部特征和全局特征相融合,丰富了特征图的提取能力,有效防止了过拟合现象。
2.2 引入自适应多尺度特征融合
YOLOv3采用多尺度检测,在不同的尺度特征图中分别检测大小目标。一旦目标与一个特征图有关,其他相关的位置被视为一个负样本。因此,一旦图像中含有大目标和小目标,不同的特征层就会发生冲突,影响参数在模型传递中的梯度计算,降低了多尺度检测的有效性。
本文采用ASFF[11]算法,解决不同尺度特征之间的不一致性。首先,通过下采样的方式,将y2,y3的特征图调整为和y1一样的大小。然后,通过加权的方式,将y1,y2,y3的特征图融合得到融合特征ASFF1(ASFF2、ASFF3同理),如图4所示。
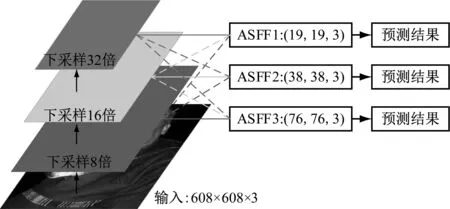
图4 ASFF网络结构图
以ASFF1为例,不同层的特征与权重相乘并相加,可以得到新的融合特征,如式(2)。
(2)
ASFF算法通过学习不同特征图之间的联系,过滤掉融合特征ASFF1、ASFF2、ASFF3空间位置矛盾的信息,同时增强带有区分性线索的特征,提高了尺度不变性,具有实现简单,附加计算成本小的优点。
2.3 锚框改进
原始锚框的宽高比适用于检测多类别目标,不适用于混合行人数据集单类别检测。利用k-means调整锚框的尺寸,可以有效提高检测精度。
k-means使用欧式距离调整锚框的尺寸计算时,检测结果易受到尺寸的影响,从而降低了精度。为了避免这一影响,本文用IOU距离替代欧式距离,如式(3)。
d(b,c)=1-IOU(b,c)
(3)
其中,b为数据集中行人数据的目标框信息;c为聚类中心;IOU为目标框与聚类中心框的平均交并比。数据集利用算法进行100次迭代聚类,可以得到较好的锚框尺寸,如图5所示。
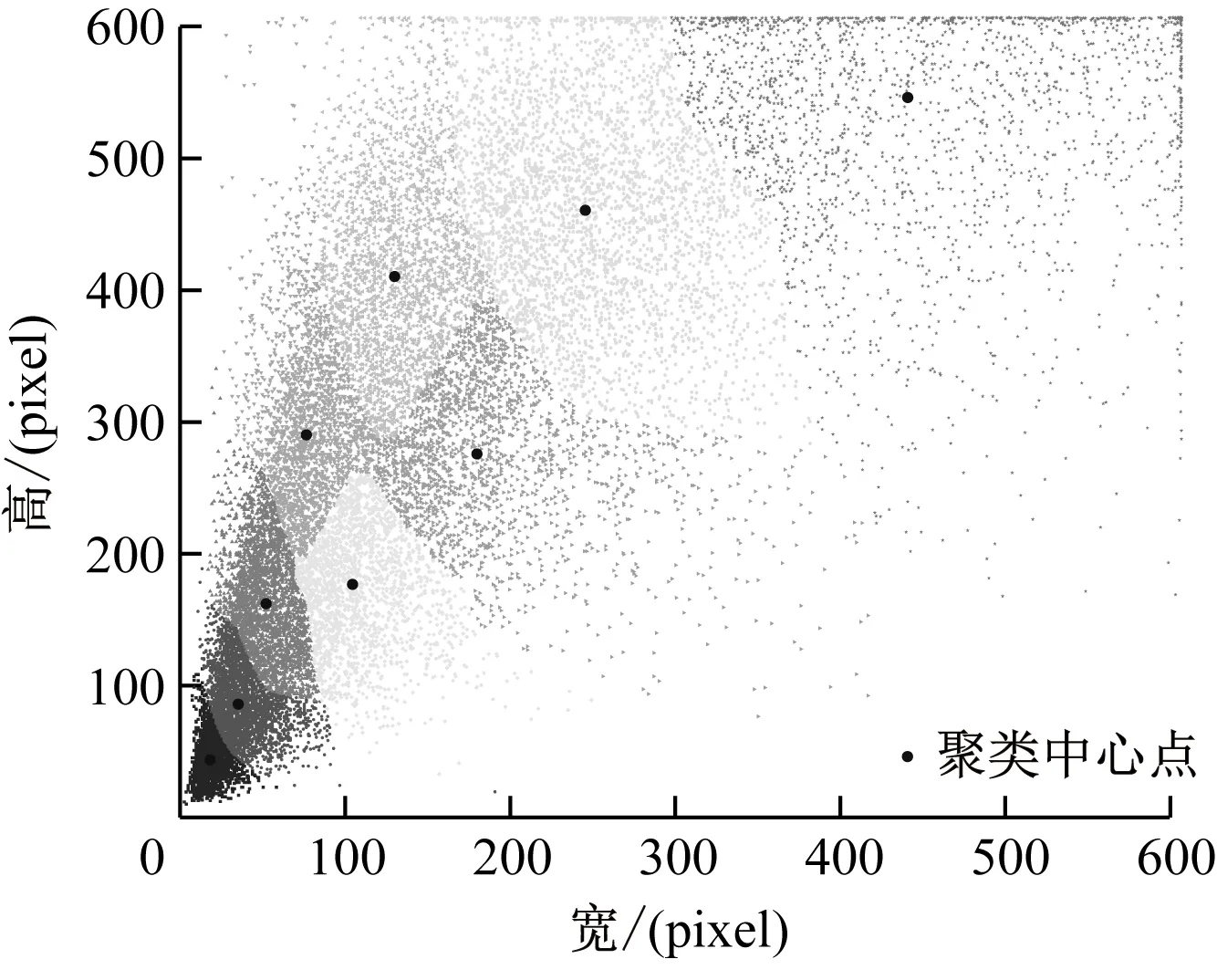
(a) 算法迭代1次
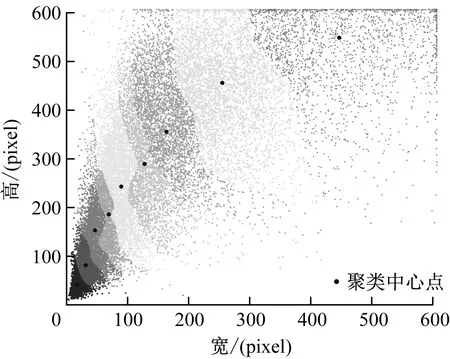
(b) 算法迭代100次
通过聚类得到聚类中心,与输入图像的尺寸进行乘积运算可以得到聚类后的锚框尺寸,如表1所示。
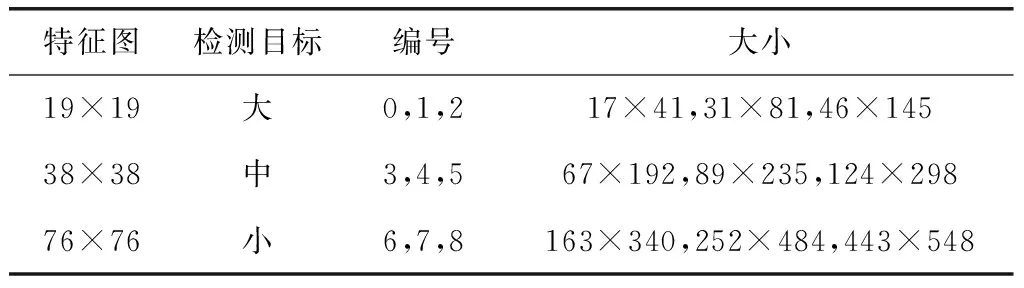
表1 聚类后的锚框尺寸
2.4 改进后算法流程
改进后的算法流程,如图6所示。

图6 改进后算法流程
将行人图像经过预处理得到608×608固定大小的输入,经过Darknent53卷积池化,送入改进的检测网络,待使用ASFF进行特征融合后,得到预测网络。
2.5 行人检测过程
当训练好改进的模型,将行人图像大小和锚框尺寸送入模型,得到特征图y1,y2,y3(N×N×[3×(4+1+1)])。其中N表示输出特征图的大小,将原始图片划分成N×N的网格。(cx,cy)表示网格左上角坐标;4表示锚框的边框坐标(tx,ty,tw,th);3表示每个网格上有3个锚框;1表示边框置信度conf;1表示对象类别class。利用公式计算预测框的位置,如式(4)。
bx=σ(tx)+cx
by=σ(ty)+cy
bw=pwetw
bh=pheth
(4)
同时利用Simgoid函数解码置信度和类别,设置阈值过滤无用的预测框,最后经过NMS算法,得到行人目标置信度最高的预测框,如表2所示。

表2 行人检测流程
3 实验结果与分析
3.1 实验环境
本文实验环境为:Inter®Xeon®E5-2689 CPU @3.60GHz,16GB内存,NVIDIA GeForce RTX 2070Ti,Ubuntu16.04系统,PyTorch深度学习框架,GPU加速库为CUDA10.2和CUDNN8.0.4。实验中,数据集分布如表3所示。

表3 混合行人数据集
3.2 性能评估指标
实验采用检测精度(AP)、查准率(precision)、查全率(recall)对模型效果进行评估,即式(5)。
(5)
其中,TP和FP分别表示真假正例;FN表示假负例。
3.3 模型训练
实验中输入图像尺寸为608×608,采用adam优化器自动调节学习率,初始超参数设置如表4所示。
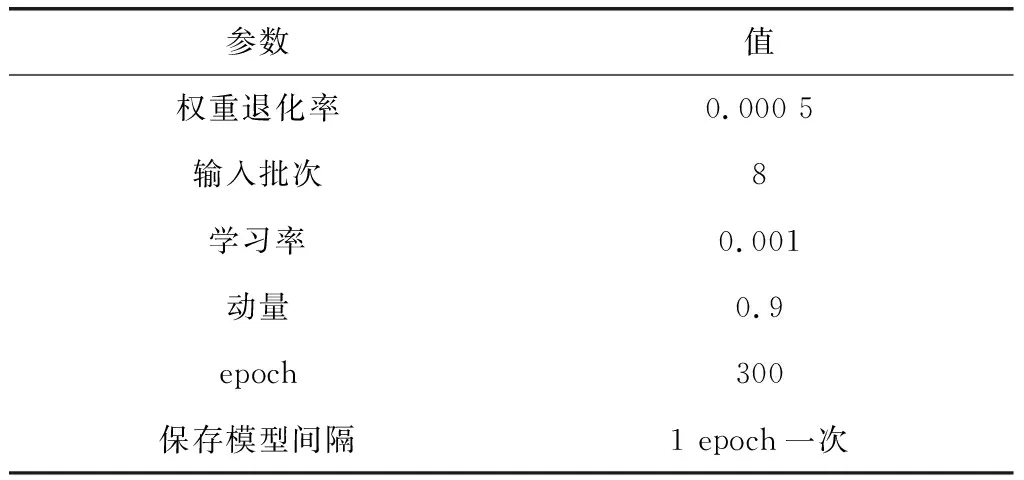
表4 初始超参数设置
损失函数如图7所示。
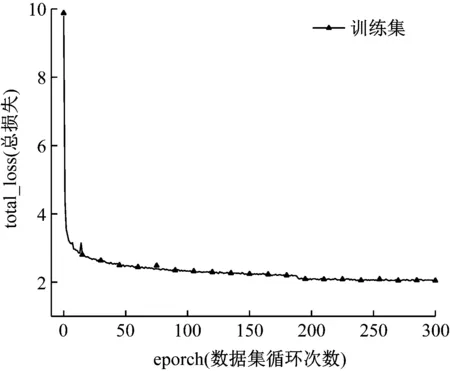
图7 损失函数曲线图
从图中可以看出,随着eporch次数增加,总损失下降较快,经过200 eporch后,总损失趋于稳定。
以AP和eporch为y轴和x轴来绘制,准确率曲线图如图8所示。
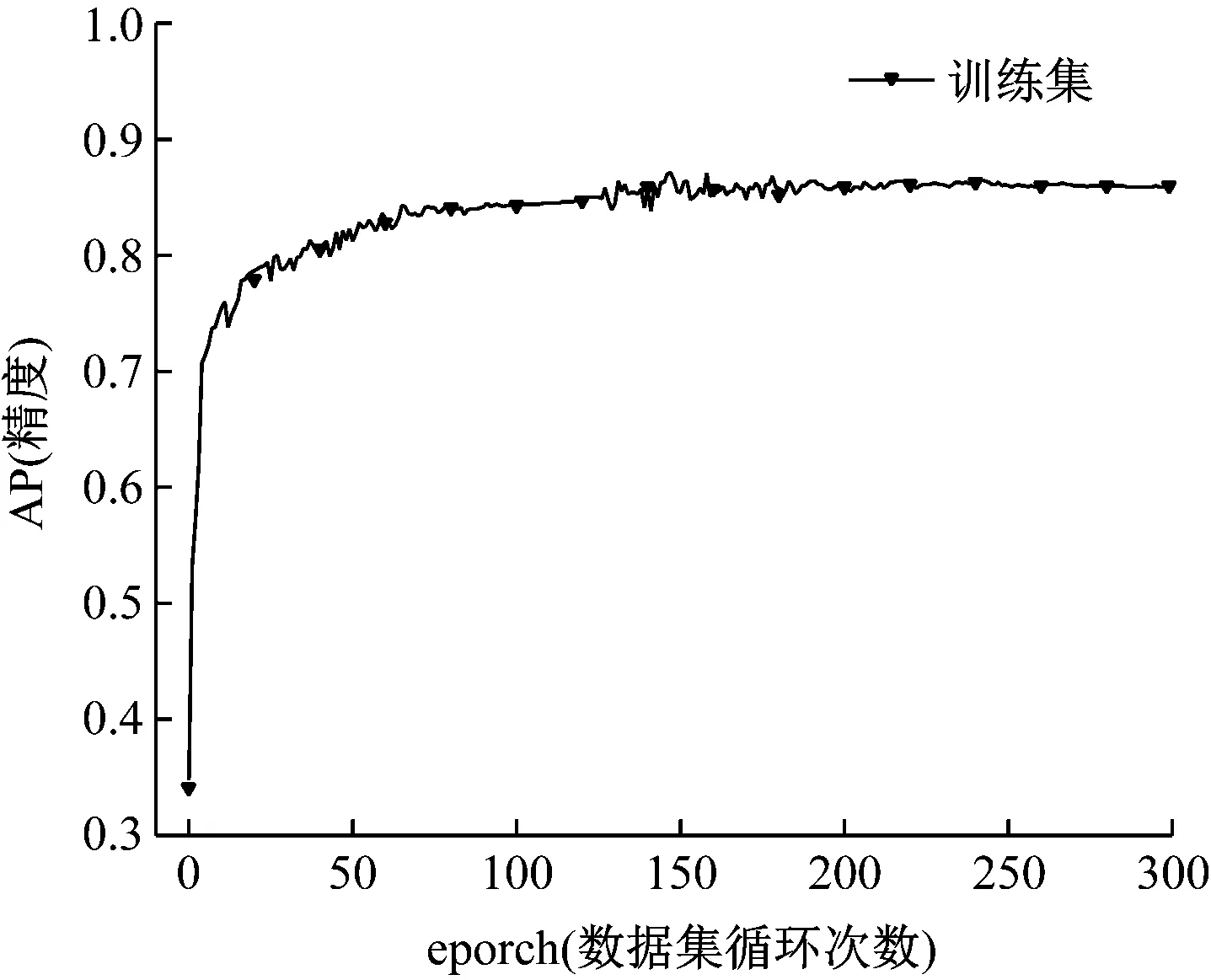
图8 准确率曲线图
3.4 结果与分析
将YOLOv3算法与不同改进策略算法,在P、R、AP上进行比较。通过对YOLOv3的网络进行修改,在三个尺度检测分支加入SPP层,融合不同大小的特征,提取特征提取能力。相对于YOLOv3-spp,查全率和准确率分别提高2.8%和1.7%,如表5和图9所示。
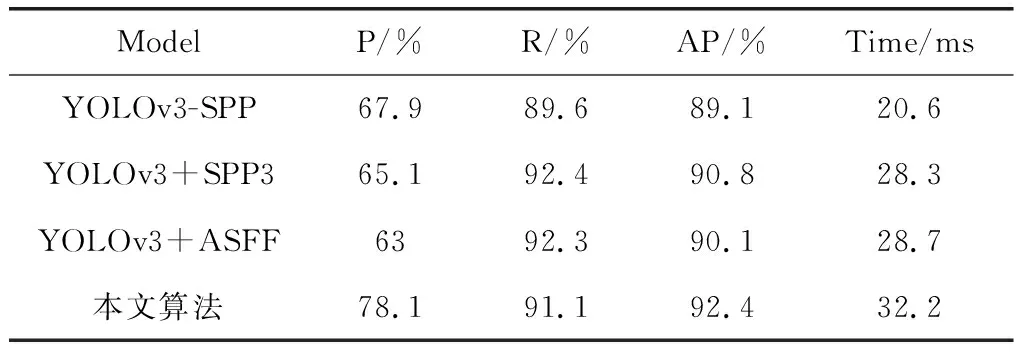
表5 不同改进策略测试结果

图9 不同改进策略结果对比
此外,引入了自适应多尺度特征融合,使用采样方式,融合三个尺度特征图的语义信息,增加特征的丰富度,提高对不同大小行人的检测能力。相对于YOLOv3-spp,查全率和准确率分别提高2.7%和1%。
在输出预测框之前,采用k-means算法,可以有效提高检测能力,提高检测网络的查全率。相对于YOLOv3-spp,查准率、查全率和精度分别提高10.2%、1.5%和3.3%。
在输出预测框之前,采用k-means算法,可以有效提高检测能力,提高检测网络的查全率。相对于YOLOv3-spp,查准率、查全率和精度分别提高10.2%、1.5%和3.3%。
神经网络通常采用浮点运算次数(FLOPS)和模型参数量或模型体积表示模型的时间和空间复杂度。对YOLOv3和本文算法进行复杂度对比,可以看到本文算法的浮点运算次数减少0.3GFLOPS,减少了模型训练和预测的时间,降低了时间复杂度。当输入相同时,本文算法在前后向传播过程中所占GPU显存降低了10.32MB,模型权重内存占用增加了2.4MB,总占用降低了7.92MB,降低了空间复杂度,如表6所示。
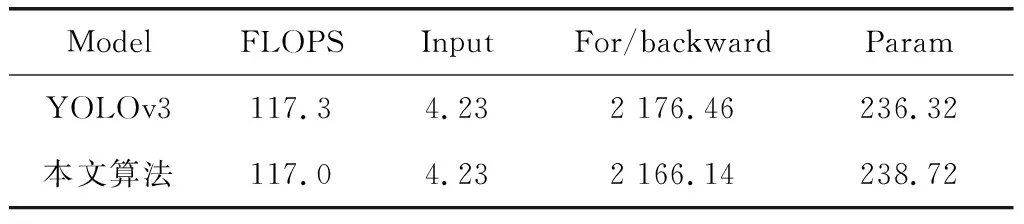
表6 复杂度分析
4 总结
为了提高智能监控下,对不同大小行人目标的检测精度。本文借鉴特征融合思想,通过引入SPP和ASFF结构,增加模型的特征提取和表达能力。在结果预测阶段,改进锚框的尺寸,提高了锚框与行人目标的匹配能力。实验结果表明,引入单一的SPP或ASFF结构,可以提高模型的检测精度。引入全部的改进策略后,检测精度得到了3.3%的提高。
