基于自注意力的双向LSTM网络的情感分析模型
2021-06-24孙璇马晖男周胜利徐婧王成
孙璇, 马晖男, 周胜利, 徐婧, 王成
(上海杉达学院 信息科学与技术学院, 上海 201209)
0 引言
情感分析是自然语言处理领域经典的研究任务之一,主要分析一个句子或段落的情感倾向[1]。近年来,随着信息技术和互联网的快速发展,人们不仅享受着数字化带来的便利,也在不断地产生新的信息。微博、Twitter、豆瓣等社交媒体平台成为人们发表对产品、人物和事件等个人观点的主要平台。这些文本蕴含了发布者对目标对象的情感信息。通过对这些情感信息进行挖掘,可以帮助客户更好地理解用户行为,预测出事件的发展方向或趋势。
在社交媒体中,这些评论文本呈爆炸式增长,一方面对耗时耗力的人工分析构成了巨大的挑战,另一方面促进了智能文本分析技术的发展。这对情感分析任务来说尤为重要,因为在社交媒体中用户评论的情感倾向呈现出了复杂的多维度形态,已经不再是“好,不错”“我不喜欢”“还可以”这样简单的评论,而是对目标对象的某些属性或方面表达积极、消极或中立的情感倾向。由此,用户对目标对象的真实评价不再是整条评论上粗粒度的情感倾向分析,而是每条语句上细粒度的情感倾向分析。一般情况下,用户习惯对目标对象的多个属性进行评价,有积极、消极或中立等情感倾向,呈现多维度的特点。
先前已有学者对情感分析任务进行了许多研究[2]。但是,相对于一般的文本分析来说,这种属性级别的情感分析任务具有一定的难度。因此,本文以分析与建模用户多维度情感倾向为主要研究内容,提出了一种基于自注意力机制的双向 LSTM 网络的情感分析模型,该模型采用双向长短程记忆网络来对文本序列进行表征学习,同时融入了自注意力机制,更加有效地通过建模文本内部特征的相关性来分析用户情感倾向。
1 相关工作
情感分析是自然语言处理中的一项基本任务,引起了许多研究者的关注。传统的文本分类方法,如逻辑斯蒂回归、支持向量机、决策树等,虽然能够用来构建情感分类模型,但是常常依赖繁琐的特征工程及构建特定领域的情感字典[3]。许多研究表明:依赖特征工程的算法达到了性能瓶颈,能够为大规模数据分析带来的性能增益微乎其微[4]。2006年以来,深度学习在许多任务上取得了巨大的成就,如目标检测、机器翻译、智能问答、文本挖掘等[5]。因此,基于深度学习技术的情感分析方法显示出巨大的前景。神经网络模型的强大之处在于无需任何特征工程就能从数据中学习到文本表征的能力。代表性的文本表征学习方法有递归神经网络、卷积神经网络、长短程记忆网络以及树结构的长短程记忆网络。文献[6]利用迁移学习将传统机器学习模型和深度学习模型相融合,把CNN提取的文本特征用SVM进行分类,在情感分析任务上取得了不错的效果。文献[1]认为40%的情感分类错误是由于没有考虑到上下文当中的情感目标词导致,近期的研究工作特别倾向于在对上下文建模时增强情感目标词的作用。文献[7]提出了一种自适应递归神经网络,根据推文数据上的句法关系将情感从上下文单词传递到特定目标属性词。文献[8]将整个上下文分成三个组成部分,即目标属性词,左上下文与右上下文,然后使用情感词典和神经网络来生成目标相关的特征。文献[9]将上下文拆分成两个部分:一个部分由目标属性词与其左上下文组成,另一部分由目标属性词与其右上下文组成,然后使用两个长短期记忆网络模型分别对这两个部分进行建模,最后使用这两个部分的特定目标属性词的组合表征进行情感分类。文献[10]采用双向LSTM网络分别对微博文本及符号进行编码,通过将注意力模型和常用网络用语的微博情感符号库相结合,有效增强了对微博文本情感语义的捕获能力,提高了微博情感分类的性能。
2 研究方法
本文针对社交媒体中用户多维度情感倾向问题进行建模,提出了一种基于自注意力机制的情感分析的深度学习模型SA-LSTM,该模型的总体框架结构如图1所示。该模型主要由两个核心组件组成:双向长短程记忆网络与自注意力机制。这两个核心组件让模型具有更强的信息归纳能力,从而能够更好地关注序列文本中的重要信息。该模型主要针对目标对象的不同属性及其所依赖的上下文分别进行建模,大致分为五层,由下往上分别是:(1)词表示层:将目标对象的属性词(或词组)及其所依赖的上下文的文本映射为向量,其中,每个词以N维的实值向量表示;(2)双向长短程记忆网络层:将目标对象的属性及其所依赖的上下文的向量表示输入到双向LSMT网络当中,经过深层的LSTM计算,输出更高级别的抽象的语义表示,称之为隐藏层状态;(3)自注意力机制:将双向LSTM网络的输出拼接作为该层输入,经过一次非线性变换后乘以权重参数向量ws2,得出的结果输入到softmax层计算LSTM每个时间步的隐藏层状态的权重;(4)语义表示层:将双向 LSTM 网络层每个时间步的隐藏层状态乘以计算好的自注意力权重得到最终的语义表示;(5)分类器:将最终的语义表示拼接起来,形成一个两者的最终表示形式,输入到softmax分类器中,输出用户对目标对象的属性的情感倾向类别。每部分的详细设计如图2所示。

图1 SA-LSTM 模型的总体框架结构图

图2 详细的结构设计图
2.1 长短程记忆网络
在许多自然语言处理任务中,长短程记忆网络常被用来作为文本序列学习的基本模型,因为它能够有效地缓解梯度消失和梯度爆炸问题,让模型学习更长的文本序列表示变得可能。长短程记忆网络的内部结构图如图3所示。

图3 LSTM 单元网络内部结构图
LSTM单元网络主要由三个门控与一个记忆单元组成来控制信息流:输入门it、忘记门ft、输出门ot。在模型训练的过程中,这些门能够自适应地记住输入信息、忘记历史信息以及生成输出表示。LSTM单元网络表示如式(1)—式(6)。
it=σ(Wi·[ht-1;xt]+bi)
(1)
ft=σ(Wf·[ht-1;xt]+bf)
(2)
ot=σ(Wo·[ht-1;xt]+bo)
(3)
gt=tanh(Wr·[ht-1;xt]+br)
(4)
ct=it⊙gt+ft⊙ct-1
(5)
ht=ot⊙tanh(ct)
(6)
式中,⊙表示数组元素依次相乘;σ表示sigmoid函数;Wi、bi、Wf、bf、Wo、bo分别表示LSTM单元的输入门、忘记门、输出门的参数。[ht-1;xt]操作表示将前一时间步的隐藏状态ht-1与当前时间步的输入xt进行拼接合并操作。
本文采用预训练的word2vec词嵌入文件,每个单词用300维的向量表示,最大词序列长度为n。此时,序列S中的每个词都是彼此独立的。为了能够获得单个句子中邻接词之间的某种依赖,使用双向LSTM单元网络来处理文本序列。每一步的隐藏层结果如式(7)、式(8)。
(7)
(8)

H=(h1,h2,…,hn)
(9)
2.2 自注意力机制
注意力机制模仿了生物观察行为的内部过程, 即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务,特别是机器翻译。而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
目的是把一个变长的文本序列编码成一个固定大小的嵌入。通过计算n个LSTM隐藏层向量的一个线性组合来实现。这种线性组合就是通过自注意力机制计算得来。自注意力机制的基本结构如图4所示。

图4 自注意力机制的结构图
自注意力机制取正向与反向LSTM所有时间步的隐藏状态拼接后的向量组成的矩阵H为其输入,输出权重向量如式(10)。
A=softmax(ws2tanh(Ws1HT))
(10)
其中,Ws1为维度为da×2u的权重矩阵;Ws1为维度为r×da的权重矩阵;da为一个任意设置的参数。Ws2也可以是r=1时维度为1×da的向量,这里设置为r=1。因为H的维度为n×2u,那么自注意力权重向量A的大小则为n。softmax函数确保了所有计算得来的权重之和等于1。最后,根据这些权重把所有的LSTM隐藏层向量加起来就得到了输入序列的向量表示m。此时,m用作softmax分类器的输入得出最后的情感分类(积极、中立、消极)。
3 实验与分析
3.1 数据集
为了验证本文提出的模型在属性级的情感分析任务上的有效性,采用SemEval2014情感分析评测数据集。该数据集包含了“餐厅”“笔记本”两大类的用户真实评论数据。每条评论被标注成“积极”“中立”“消极”等三种情感,同时每条评论中也标注了其中出现的评价对象的一些属性及其情感倾向。数据集的统计数据如表1所示。

表1 SemEval 2014情感分析评测数据集概览
3.2 基准模型
为了验证提出方法的有效性,本文采用以下模型作为对比实验:
(1) CNN:使用经典的卷积神经网络提取文本特征,经过最大池化后的使用softmax进行情感分类。
(2) CNN+SVM:使用CNN提取文本特征后,将得到的句子表示使用SVM 进行分类。
(3) LSTM:使用标准LSTM网络学习句子语义表征,不需要返回所有时间步骤的隐藏层输出,只保留最后一个时间步骤的隐藏层输出,将其作为softmax分类器的输入。
(4) TD-LSTM:一种基于LSTM改进的模型,用两个LSTM网络对目标词所在位置的前后上下文分别进行建模。
(5) AE-LSTM:一种注意力机制模型,将目标词的词嵌入直接与句子中的词嵌入直接拼接在一起,作为标准LSTM网络的输入;接着,在对所有的 LSTM网络的隐藏层输出使用注意力机制进行加权;最后,将加权后的句子表征作为softmax分类器的输入进行情感分类。
(6) ATAE-LSTM:将目标词的词嵌入与LSTM隐藏层的输出进行拼接,组合在一起进行注意力,最后输入到softmax分类器进行情感分类。
3.3 实验设置
本实验采用Python语言编写,采用Keras框架实现。需要调节的参数如表2所示。

表2 模型训练参数说明及取值
3.4 实验结果与分析
本文主要采用准确率、召回率、精确率、F1值作为评估指标。在所有模型上进行实验的结果如表3显示。
从表3可以看到,本文提出的方法取得了最好的实验结果,相较于ATAE-LSTM模型在准确率、精确率、召回率、F1值上分别提升了2.2%、2.4%、2.8%、2.6%,证明了本文提出模型的有效性。可以从表3中得出结论:(1)相较于依赖外部信息的注意力机制,自注意力机制更加关注文本内部特征的相关性,这种特点显著地增强了自注意力机制表征学习的能力,丰富了表征的语义;(2)除了采用注意力机制之外,ATAE-LSTM模型取得显著性能的关键在于在词嵌入层和LSTM输出结果上都用预训练好的目标属性的向量表示进行增强。然而,在本文提出的模型中,并未使用类似的表征拼接方法来增强语义。侧面反映了本文提出的模型具有相对更好的性能表现。
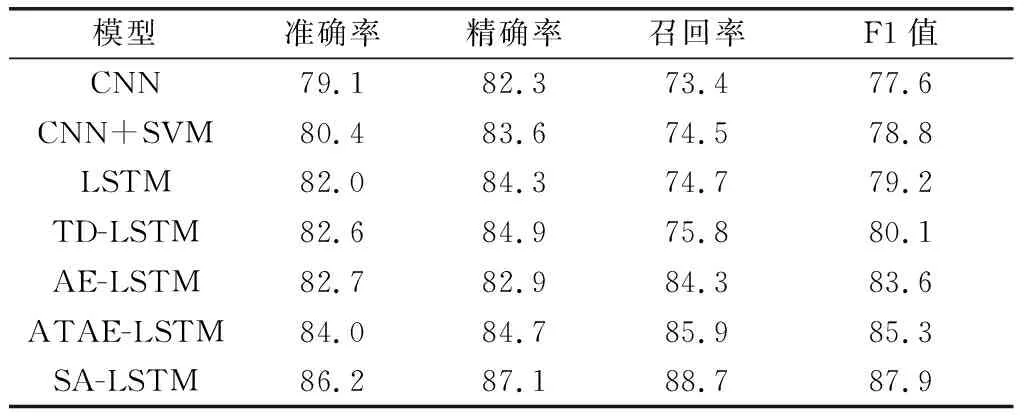
表3 实验结果
4 结束语
本文提出了一种基于自注意力机制的双向 LSTM网络的情感分析模型,通过新颖的自注意力机制来对社交媒体中用户评论的多维度情感倾向进行分析与建模。自注意力机制能够捕获评论文本序列的内部特征相关性,有效地增强了模型对于评论文本情感信息的捕获能力,进而提升了情感分析的性能表现。在SemEval2014的数据集上,本文提出的模型均表现出了最好的性能。但是,本文采用的词向量是静态不变的,而不是依据上下文动态可变的。因此,本文下一步的研究工作是采用语境化的词向量表征模型,以改善模型性能。
