一种基于用户兴趣特征的微博信息转发预测方法
2021-06-24张霁雯
张霁雯,周 军
(辽宁工业大学 电子与信息工程学院,辽宁 锦州 121001)
微博是一种基于注册用户关联的关系、信息的分享、传播以及信息获取的移动信息社交网络平台。微博用户在手机等移动终端或者电脑登入,以图片、文字、视频、影像等形式呈现,可以实现信息用户间分享与互动,微博传播的速度和形式与电视新闻、报纸等传统的媒介传播方式都大不相同,微博更为简单、迅速、快捷、清晰地表述了事件的整个过程。
截至到2019 年第一季度,微博总活跃用户已达到4.65 亿,超过Twitter 总使用人数。对微博转发进行预测,既能够为信息传播效率、广泛性等合理预测提供重要支持,同时在信息推荐、广告信息精准投放、突发事件预警等方面有重大作用。
目前,现有对微博信息传播进行分析的方法大多数都是侧重于挖掘数据、电子商务应用等相关方面。现有办法对于微博转发预测的准确度较低,主要是因为现有办法没考虑到用户在一段时间之内的兴趣态势变化,而且认为用户的兴趣仅仅为用户的标签内容。本文在分析影响微博转发、分享的客观因素的基础之上,通过TF-IDF 统计算法结合LDA 主题分析模型来分析文本,并创建了一个基于在线被动攻击算法的微博转发分享预测模型,该预测模型采用融合用户兴趣特征的PA 算法,使得微博转发预测模型的准确度大大提高。
1 相关工作
本文加入了用户在一段时间内的兴趣点,加入原创微博以用来分析用户对最近新鲜事件的关注度。LDA 主题模型是以“文本、单词”“单词、矩阵”构成的。原有的LDA 主题模型通过计算文本中每个单词的出现频率就可以得到“文本、单词”矩阵。本文主要采用了TF-IDF 算法与LDA 主题模型结合的方法来对微博文章中的单词矩阵进行简化使得预测结果更加准确。
信息传播具有多样性,研究人员从不同视角使用不同的方法对信息转发预测进行了不同角度的研究。2016 年马晓峰等[1]研究认为提高转发预测精度,应通过科学合理的方法抓取重要影响因素,由此创建了以混合特征学习为基础的信息转发预测模型。此模型采用了社会知名度特征、微博具体内容特征、用户特征的预估办法。2016 年刘玮等[2]学者经过全面深入地研究,提出了一种以用户单位时间内活跃度为基础的转发微博、忽略微博、未接收微博的一种识别方法,为获得准确的模型分析结果提供了可靠的信息支持。
2017 年陈鹏飞[3]研究特定兴趣内的用户影响力对于转发预测的影响。2018 年郝苗苗等[4]采用词典权重的规则算法,构建了一个微博情绪化分析词典,通过该词典识别微博中的5 种情感极性:过度积极、轻微积极、中性、轻微消极、过度消极;并采用监督学习的情绪分类预测方法对微博的情感极性展开分类预测,实验结果表明该预测方法对短文本的预测准确度较高。2018 年王宁等[5]提出了一种基于马尔科夫随机场构架下分析微博具体内容特点、用户特点与用户转发行为束缚等客观因素对用户转发行为的影响,并在逻辑回归数学模型之上构造了相应的函数对用户转发行为展开系统的预测。2019 年穆圣坤等[6]采用基于循环神经网络的方法来对微博转发量级进行预测,该神经网络模型融入微博营销策略及用户粉丝数量的变化,利用SIM-LSTM 模型构建微博转发趋势度,通过该神经网络模型来预测用户是否进行微博转发行为。2019年王绍卿等[7]提出了联合概率模型,该模型将用户之间多重信任关系融入传统的BPF 模型,通过模型可捕捉到用户之间的社交关系。2019 年王飞[8]针对以微博为例的社交网络信息分享问题中影响力最大化,提出了基于记忆效应和社交增强效应的社交网络影响最大化模型,提高传播效果和传播效率,构建了一种基于Hadoop 的网络舆情分析模型,采用了HDFS 用来存放大量数据,实验验证了其有效性,实现了一个微博舆情分析和预警原型系统。
上述研究主要针对客观因素对用户转发行为的影响、微博特定兴趣内转发率等问题,但是对在线微博转发预测的准确度的研究方向提及的内容比较有限,本研究基于LDA 主题模型、采用TF-IDF算法、改进的在线被动攻击算法,从而提高了微博转发预测的准确度。
2 算法分析
2.1 算法流程
(1)用python 爬取数据
爬取新华视点从2019.1.1—2019.3.25 期间发布的微博数据以及关注该微博用户的粉丝发布的微博内容共35 600 条,算法随机将23 600 条数据作为训练数据集,将12 000 条数据作为验证集。采取合适的方法对数据进行严格规范的预处理,同时要进行合理分词;文本采集是利用python 爬虫,安装request(用来获取htlm 页面)和beautifulsoup(用来进行htlm 解析)框架,登录新浪微博,为了查看具体的粉丝信息,通过调试工具,用cookie 复制出来,用ajax 异步下拉加载。作为当前备受业内人士推崇且应用比较广泛的一种网页开发技术,Ajax 借助JavaScript 在确保页面不会被刷新、页面链接保持原状的前提下和服务器完成数据交换、网页更新等操作。在chrome 的调试模式之下捕获相应请求爬取下用户名、关注量、点赞量、转发量等。
(2)微博内容的兴趣特征提取
对用户微博内容进行分词处理、对用户的兴趣特征进行提取,将微博内容归纳为6 大主题。分析出每篇文章的主题和在每个主题上的权重分布。
(3)分析影响微博用户转发行为因素
研究影响微博用户转发行为的其他因素包括微博本身特征以及不同类型的用户特征。
(4)预测分享模型的建立
预测用户是否会转发指定微博。
2.2 用户兴趣特征提取
用户兴趣特征提取采用LDA 主题模型。LDA主题模型简单来讲是一种由“文档、词语”等相关元素共同构成的模型。假定一篇文章中的所有词都是借助“以某种可能确定某主题,并在此主题中以某种可能确定某文档”的方式而获取的,无论是词语到主题,还是主题到文档,均满足多项式分布要求[9]。
LDA 的联合概率原理如下所示:
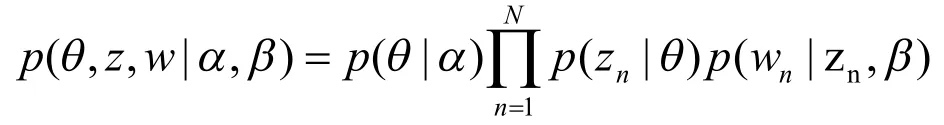
LDA 主题模型流程如图1 所示。

图1 LDA 主题模型流程
LDA 主题模型结合结巴算法对文本数据进行分词[10],使用正向词频统计和逆向文档数统计即TF-IDF 值作为每个词语的属性值,结合停用词表对文本无用词进行停用以提高预测准确性。
2.3 微博信息预测分享模型
微博中转发用户是比较多的,如果当信息量达到一定量时选用关联规则、决策树等传统式算法对微博转发进行预测的速度是比较慢的。本文基于PA算法,构建一种基于用户兴趣特征的微博信息分享转发预测模型,该模型在处理大规模数据的转发预测时速度较快,但是需要大量的数据对该信息分享转发预测模型进行训练,对存储空间要求高。
PA 算法思想为:人们普遍认为微博信息形成于一个不间断的动态数列,对所有动态数列内出现的新的信息进行用户能否转发预判,把用户标记为0(不转发)或1(转发),预判结束后,用户在该动态数列结束时是否进行了转发也就出现了。
算法有3 种表示形式如表1 所示。

表1 算法表现形式
算法瞬时损失函数如下:
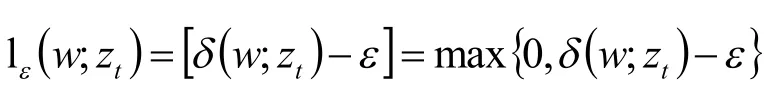

新的向量Wt+1被设定为Wt对Cε(zt)的推测,即:

与传统的PA 算法不同,在测出待测用户每条微博的主题和与系统主题的相似度的同时,除了新更新的规则外还考虑到用户的兴趣度因素影响用户是否进行微博转发,并在原有的全局模型中加入用户的兴趣度局部模型来一同决定用户转发微博的概率。本文对此模型进行如下构建。
(1)使用PA 算法建立全域模型,使用局部模型更新局部规则。
(2)用户的兴趣特征提供了对微博数据的训练,并对模型的局部规则进行更新。
(3)在预测过程中,更新用户兴趣权重对传统PA 算法的模型进行合理更新,根据全局规则以及局部规则对判别结果进行合理确定:

式中:wt为全局权重;wξ为特定微博ξ的兴趣相似度权重;α为权重系数,可以定义为兴趣相似度权重与全局影响力权重比例,即α=ξn/N;N为时间段的全局影响力权重;ξn为兴趣相似度权重,在ξ时间序列内兴趣相似度权重越大则表示该时间序列内的局部规则起到的作用也越大。
2.4 预测指标选取
用户原创的微博可以代表用户最近的兴趣趋势,用户转发的微博表示用户对该事件感兴趣,转发博主微博的概率权重增加。微博用户的主要特征有关注博主数量、用户是否认证、历史转发微博、用户是否VIP、微博等级、活跃度等。
微博用户的特征都是比较好区分的,不同的影响力对用户微博转发率有所影响,其中粉丝数量多少就可以代表该博主的影响力大小,例如带有大V标识的微博用户发布的微博更容易被其他用户转发,因为该微博用户与其他用户相比较具有更高的可信度。微博用户粉丝数量的多少也会影响微博转发率,因为在一定的浏览时间内,博主用户的粉丝数量越多则看见该博主发布的微博内容的人就越多。用户发布微博数量多少可以代表用户的活跃度,一般来讲,用户的活跃度愈高,发布的微博被其他用户看到并转发的可能性愈大。用户进行实名认证或者转为VIP、用户等级高都可以提高用户的可信度,用户的历史转发过微博可以代表该用户在这段时间内的兴趣点,用来分析用户标签。
3 实例分析
爬取新浪微博用户新华视点从 2019.1.1~2019.3.28 发布的微博作为试验数据,选取有二次转发可能的用户微博数据进行分析预测。
首先通过严谨规范、成熟合理的LDA主题预测模型高效合理地分类文本,在对文本的主题特征展开分析时,应结合实际情况对LDA模型生成的主题数量进行科学合理地明确,通常利用perplexity 算法进行运算,详情如下:
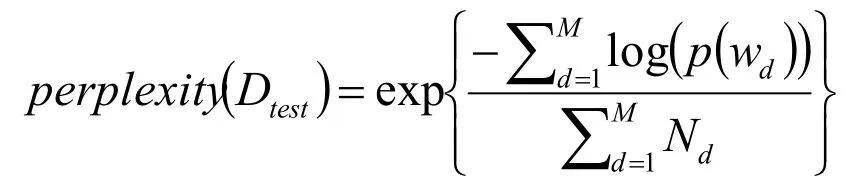
式中:M表示测试语料库的规模;Nd表示第d篇文本大小。

在上式,z是主题,w是文档,gamma表示基于训练集学而推导的文本-主题分布情况,由此可知,perplexity 的上半部分即为生成文档的似然估计的负值,本文将概率的区间定义为[0,1],根据对数函数的含义能够了解到,分子值较大时,分母表示测试集中所含有的所有单词数量,一般来讲,分析模型的生成水平愈低,perplexity 的值就越高。试验结果表明主题数为6 时模型生成能力较强。
具体数据如表2 所示。

表2 主题数目
因为影响微博转发的的因素有很多,参考之前学者研究的经验以及对实验的验证结果,选取了以下预测项目:从用户信息角度:用户名、关注量、粉丝量、微博数、用户信息。从微博信息角度:发布时间、微博内容、点赞量、转发量、评论量、转发博主。
基本预测:在对微博转发展开预判前要对样本数据展开归一化,数据归一化的目的是为了让不同样本数据具有不同的量纲单位。为避免各样本数据间的量纲彼此干扰,影响预测精度,所以需要采取科学合理的方法对采集到的数据进行严格规范的归一化处理。当前应用比较广泛的方法主要包括min-max 法、均值方法、中间值法等。因为min-max方法会把数据样本归一到[0,1]范围内,所以本文采取的是min-max 方法。公式如下:
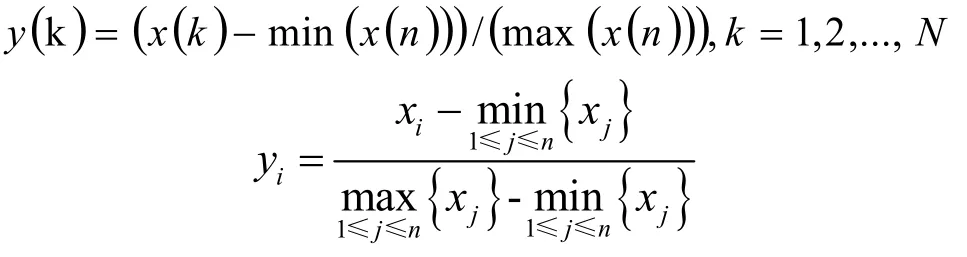
采用标准的PA 算法、改进的PA 算法、随机识别法3 种方法构建的预测模型分别对样本进行是否转发预判,获得预测准确度,如图2 所示。

图2 预测准确度
实验验证了改进PA 算法的有效性及可行性。
4 结束语
设计了一种基于用户兴趣特征的微博转发预测模型,挖掘了用户的兴趣特征,分析了影响转发因素,改进了在线被动攻击算法以提高预测准确度。实验结果证明了该预测模型的有效性,提高了微博转发预测的准确度。
