基于深度学习与《中国图书馆分类法》的文献自动分类系统研究
2021-06-22孔洁
孔洁
摘 要 为了弥补传统文献分类方法的不足,满足信息时代下激增的文献分类需求,文章提出了一种文献自动分类算法,结合NLPIR分词系统与Skim-gram词向量模型提取文献的特征向量矩阵,并在此基础上结合卷积神经网络对文献的中图法分类号进行预测。实验结果显示,文章提出模型的基本大类准确率为97.66%,二级分类准确率为95.12%,详细分类的准确率为92.42%。结果证明,结合特征词向量预处理与卷积神经网络能够有效提升文献分类精度,这为实现智能图书分类提供了新的思路。
关键词 智能图书馆 深度学习 卷积神经网络 文献分类
分类号 G254.11
DOI 10.16810/j.cnki.1672-514X.2021.05.009
Research on Automatic Literature Classification System Based on Deep Learning and Chinese Library Classification
Kong Jie
Abstract In order to make up for the shortage of traditional literature classification methods and meet the demand of literature classification in the information age, this paper proposes an automatic literature classification algorithm, which combines NLPIR word segmentation system and Skim-gram word vector model to extract the eigenvector matrix of the literature, and on this basis, combine with the convolution neural network to predict the classification number of the literature. The experimental results show that the accuracy of the model proposed in this paper is 97.66% for basic categories, 95.12% for secondary classification, and 92.42% for detailed classification. The results show that the combination of feature vector preprocessing and convolutional neural network can effectively improve the classification accuracy of literature, which provides a new idea for the realization of intelligent book classification.
Keywords Intelligent library. Deep learning. Convolutional neural network. Literature classification.
1 文献分类方法发展概述
随着信息技术的发展,数据的规模效益开始显现,大数据时代推动了科技文化的发展,也带来了新的挑战。图书馆作为数据文献索引的中心,如何科学管理分类海量的文献已经成为一个重要课题。在图书馆的众多业务工作中,对文献的编目标引是其中重要的一环[1]。传统的手工分类方法是将一篇篇文档按照某种规则归类到某一个特定类别或主题之中。在我国使用最广泛的分类方法与体系是《中国图书馆分类法》。这是我国编制出版的一部具有代表性的大型综合性分类法,是当今国内图书馆界使用最广泛的分类法体系,简称《中图法》。但是,由于其类目较多,单纯依靠人工对文献进行分类,存在工作量大、效率低、对人员专业技能要求高等问题,因此寻求一种自动化文献分类方法一直是专家学者研究的重难点[2]。
自动化文本分类系统主要依靠计算机来实现,因此如何让计算机“理解”这些文本便是文本分类首先需要解决的问题。文献中的字词都是以句子形式出现的,不利于文本的处理识别。需要通过分词将连续的句子切割组合成有意义的词语。中文分词不同于英文,英文由于语言特性,单词之间有空格符作为天然的分界,而中文的汉字是相连没有分界符的。此外,中文的詞语长短不一,包含的汉字个数也有差别,这也给分词任务增加了不少难度[3-4]。现有的分词方法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[5-7]。基于字符串匹配的分词方法主要利用机械匹配的方法将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果,其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。基于统计的分词方法是在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分,如最大概率分词方法和最大熵分词方法等。随着大规模语料库的建立,以及统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为主流方法。
但是,汉字难以直接作为分类网络进行输入,需要将汉字或词语转化成对应的数学向量。传统的文本特征向量提取方法包括词袋模型、TF-IDF模型、LDA模型等等[8]。词袋子模型将字符串视为一个 “装满字符(词)的袋子”,袋子里的词语是随便摆放的,而两个词袋子的相似程度就以它们重合的词及其相关分布进行判断。这种方法虽然简单快捷但是词向量维度过高,准确率难以满足应用需求,而且无法关注词语之间的顺序关系[9]。TF-IDF模型在词袋模型的基础上进行改进,结合词频和逆文档频率来分析文本的关键词,降低了词向量维度。但是 TF-IDF 同样没有考虑文本中词的位置及结构信息,所以 TF-IDF 空间向量模型对于词的表示性能一般[10]。LDA是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。LDA将文本中词语语义、结构信息的计算,融入到矩阵的运算求解中,一定程度上提高了文本表示的效果,但是文档主题数目难以固定,资源消耗较大[11]。随着深度学习算法的流行,基于神经网络的特征提取方法逐渐成为研究重点。
基于文本的特征词向量,原先多采用机器学习算法,比如以遗传算法为基础的朴素贝叶斯分类器及支持向量机、随机森林算法等等[12-14]。但是上述文本分类算法都存在一定的局限性,文本特征的选取比较随意、语义信息不足及特征稀疏等问题使得传统算法难以取得良好的效果。而深度学习在图像识别及语音识别方面的成功,使得研究人员将重心转移到基于深度学习的自然语言处理方法研究上。卷积神经网络拥有良好的特征提取能力,能够显著降低文本分类中人工抽取特征的难度。目前基于卷积神经网络的文本分类方法研究已有一定进展,但是性能上仍有较大的改进空间。
2 基于深度学习的文献自动分类模型
对于深度学习来说,其思想就在于能够对堆叠多个层进行数据处理,通过将某一层的输出作为下一层输入的方式,实现对输入信息的分级表达。为了使输出的数据信息特征在提取时尽量准确,就要将这些网络层结构进行组合。提取特征就在于卷积,由于一次卷积可能提取的特征比较粗糙,就要进行多次卷积,以及层层纵深卷积,层层提取特征。利用卷积神经网络进行深度学习,将有利于提升文本语义判断的理解能力,实现文献的精准分类。
2.1 算法模型结构
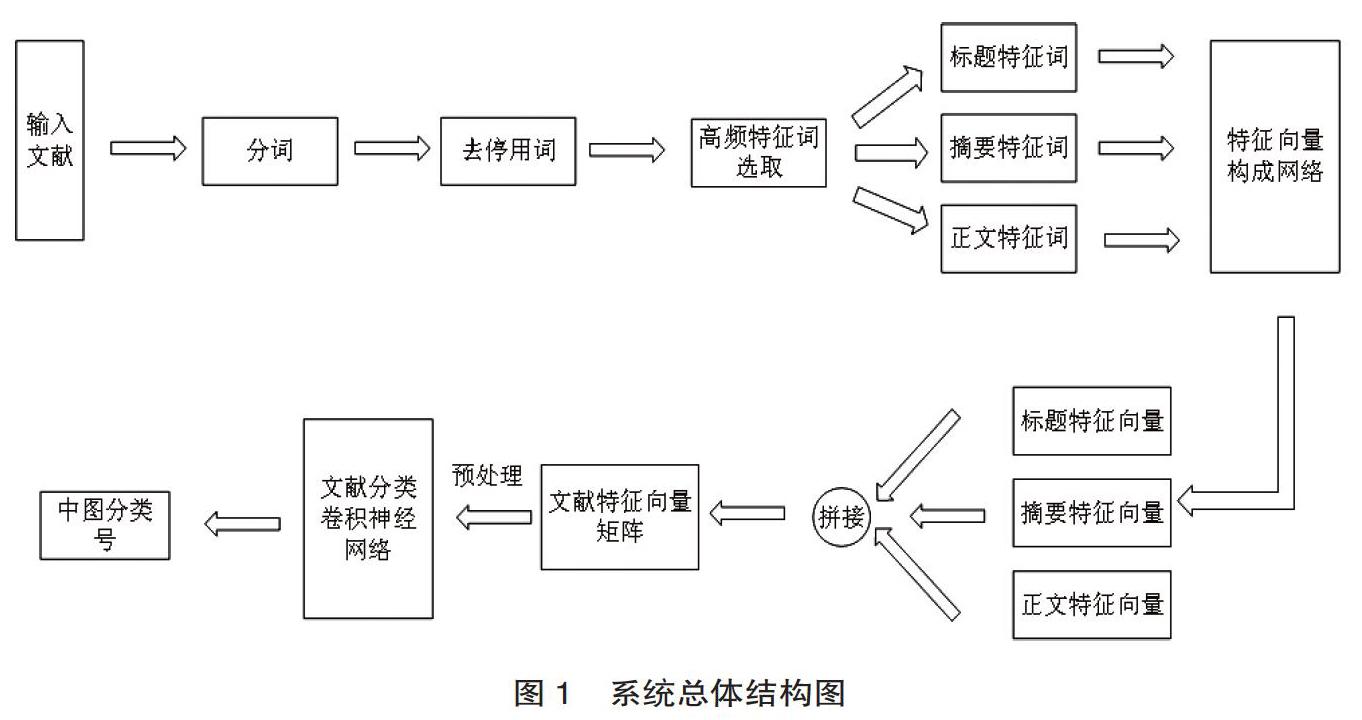
本文提出的文献自动分类方法包含三部分。第一部分是文献的分词及预处理,对目标文献的标题、摘要、正文分别进行分词,去掉停用词后筛选其中使用频率较高的词语作为特征词。第二部分是特征向量矩阵的构建,将选取的特征词转化成向量表示,并对不同方法构建的向量进行拼接。第三部分是文献分类网络,以预处理后的文献特征向量矩阵作为输入,利用卷积神经网络来对文献进行分类,得到对应的《中图法》分类号。系统总体框架如图1所示。
2.2 文献分词与预处理
本文采用NLPIR分词系统来进行分词任务。NLPIR是由北京理工大学张华平博士研发的中文分词系统,是一整套对原始文本集进行处理和加工的软件。文献一般包含标题、摘要及正文,标题与摘要包含了大量文献特征信息,特征词的密度高于正文。如图1所示,本文將标题、摘要与正文分别进行分词,对比停用词表,去除常见的停用词,剩下的词语为各部分的有效特征词。按照词频从大到小排序,标题部分取前6个,摘要部分取前12个,正文部分取前110个词作为该部分的高频特征词。高频特征词代表了文献的核心词语及基本信息点,可以为后续文献的分类提供可靠信息支持。
2.3 文献特征向量构建
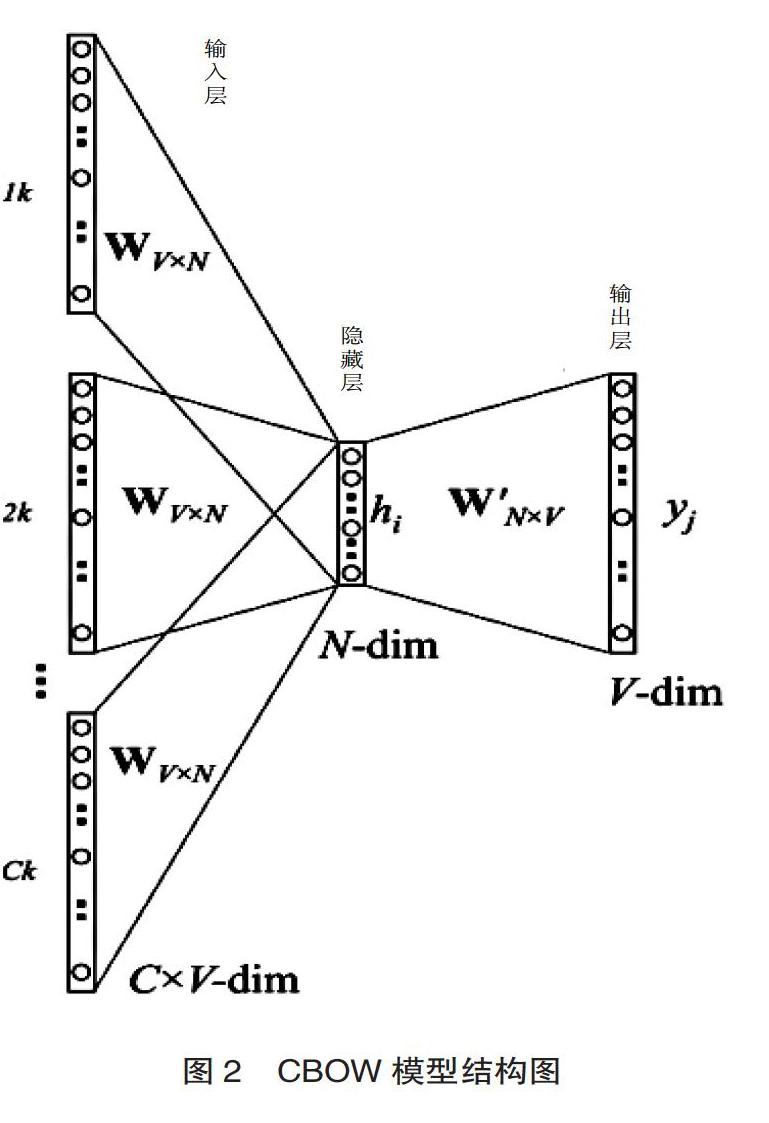
基于分词系统及预处理机制得到了包含文献核心特征的高频特征词,本文采用Word2vec来进行特征词向量的提取。Word2vec 是谷歌在NNLM(Neural network language model)基础上开源的一款词语向量化表示工具[15]。Word2vec基于上下文的语义信息,构建三层的神经网络,对当前词和其上下文词进行模型训练,最终得到词向量。Word2vec主要包含两个模型,CBOW和Skim-gram,CBOW主要是根据当前词的上下文词来推断当前词,而Skim-gram主要是根据当前词来推断上下文的词,两个模型的结构图如图2和图3所示。
本文使用中文维基百科语料库、哈工大信息检索研究室对外共享语料库及国家语委现代汉语语料库作为语料数据,对Skim-gram模型进行训练,得到长度为256的词向量模型。一篇文献对应128个高频特征词,一个特征词经过转换可得到长度为256的词向量,因此一篇文献可得到128×256的词向量矩阵,如公式(1)所示。其中每一行代表一个高频特征词对应的词向量。
2.4 基于卷积神经网络的文献分类算法
基于NLPIR分词系统与预处理系统,得到了表征文献特征的128个高频特征词,其中标题6个、摘要10个、正文112个。使用训练好的Skim-gram词向量模型将高频特征词转换成包含文献特征信息的词向量矩阵如公式(1)所示。然而该向量矩阵仅为二维矩阵,深度信息较浅,在提取特征的过程中容易丢失信息。为了充分提取特征信息,本文采用图4所示的预处理模型对文献的特征词向量矩阵进行重组拼接,使用叠加后的三通道三维特征向量组作为分类网络的输入层。
根据第五版《中国图书馆分类法》,将文献分成22个基本大类,223个二级分类,2246个详细分类。为了提升分类的准确性,本文采取多级预测的方法,在网络的不同阶段进行多次预测,利用浅层特征对基本大类进行预测,利用中层特征结合基本大类的预测结果对二级分类进行预测分析,结合深层特征与二级分类结果对文献的详细分类进行预测,分类网络的结构图如图5所示。本文使用残差网络进行特征提取,ResN即为残差网络单元,残差单元加快了深层网络的训练与收敛速度,增强了网络的非线性表达能力。本文使用了BN层(Batch Normalization Layer)来代替Dropout机制,加快网络收敛防止出现过拟合的现象,对于梯度爆炸及梯度消失有较强的抑制效果。由于需要分类的类别较多,如果采用全连接来进行特征数据映射,网络参数数量会过于庞大,网络容易出现过拟合现象。因此本文在对相关参数进行分析预测时,没有采用全连接层,而是采用了GAP层(Global Average Pooling)来代替全连接层。GAP层大大降低了网络的参数个数,使得特征图的通道数与输出的类别保持一致,相当于剔除了全连接层黑箱子操作的特征,直接赋予了每个通道实际的类别意义。网络使用Softmax函数作为网络的分类器,使用交叉熵作为网络的损失函数,如公式(2)和(3)所示。
其中,公式(2)是对网络最后一层的输出进行Softmax运算,Yi 表示第i个样本属于第j个类别的可能性,最终运算的结果通常是一个向量[Y1, Y2, Y3, …],表示当前样本属于各个类别的概率值。公式(3)是求取得到的向量与实际的样本标签的交叉熵,以此作为网络的损失值。
网络选取预测概率最高的类别作为文献的最终分类,鉴于大量文献同时属于多个图书类别,引入阈值法,设定概率阈值,当文献类别预测概率大于设定的阈值时即认为该文献属于该类别。经过对比实验分析,网络的最佳阈值为0.88。
3 实验与分析
3.1 数据集
实验数据集来自上海图书馆出版的《全国报刊索引》,该刊物收录全国社科、科技期刊6000多种,报纸200余种,内容涉及哲学、社会科学、科学与技术方面的各个学科。条目收录采取核心期刊全收、非核心期刊选收的原则,现年更新量约50余万条,为目前国内特大型文献数据库之一。实验采用2016—2019年二百万余份刊物,按照8 : 2的比例来划分训练集和测试集。实验基于Ubuntu16.04,Tensorflow框架,Python3.5环境下对网络模型进行训练,硬件设施为Intel Core i7 9700k, NVIDIA Titan X显卡。
3.2 对比实验分析
由于大量文献不仅仅只属于一个《中图法》类别,因此本文设置了概率阈值机制,只要某一类别最终预测的概率超过阈值则认为文献是属于该类别的。为了寻找最合适的概率阈值,我们设计了一组对比试验来分析不同阈值下网络分类的准确率。对比的依据为分类的完全准确率、部分准确率及错误预测率。完全准确是指网络成功预测到了文献的所有分类号,部分准确是指网络只预测到了文献的一部分分类号,错误预测是指网络错误的将文献分到了实际标签中不包含的类别。试验结果如表1所示。
从表1可以看出,网络在阈值较低时,错误率较高,容易将文献误分类。当阈值较高时,完全准确率降低,部分准确率升高,网络不能很好的将文献所有所属类别找出。当阈值为0.88时,完全准确率最高,网络的整体表现较好,因此使用0.88作为本文的概率阈值。
为了分析网络在文献分类任务上的表现力,我们设计了一组对比实验,通过与经典算法模型及目前较为领先的算法模型的对比来观察本文网络模型的表现。使用相同的训练集与测试集来对不同网络进行训练与测试,考核标准使用准确率分别对比不同网络基本大类、二级分类及详细分类的完全准确率。实验结果如表2所示。
由表2可知,本文网络模型在完全准确率上领先参与实验的其它网络模型,基本大类完全准确率为97.66%,二级分类准确率为95.12%,而详细分类的准确率为92.42%。由于本文算法模型采用多级预测,使用前一级预测的结果来影响后一级预测的结果,在很大程度时上可以规避分类错误。
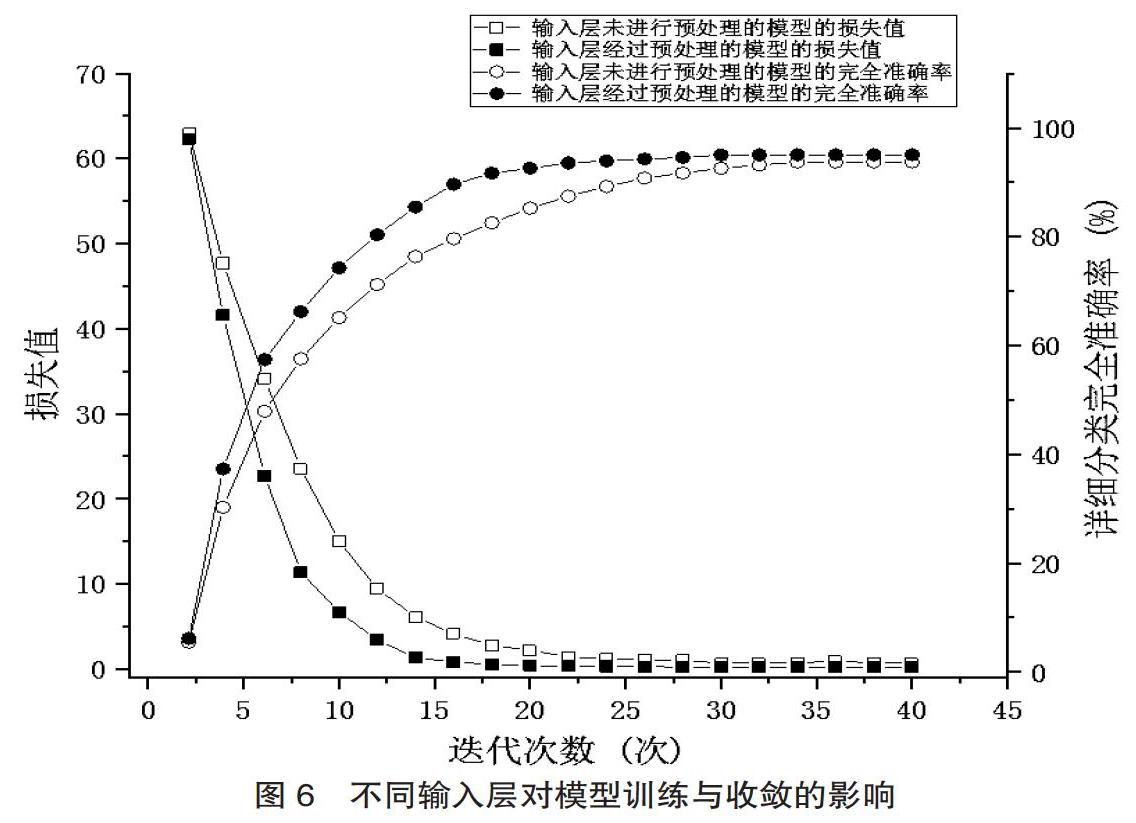
此外,本文对文献的特征向量矩阵进行了拼接组合的预处理操作,使得输入信息量扩大,神经网络提取到的特征更加丰富。为了验证这一机制的有效性,我们设计了一组对比试验,使用沒有经过拼接组合预处理的特征向量矩阵直接作为输入。对比算法模型在训练过程中的收敛情况及准确率的变化结果如图6所示。从图6可以看出,在输入层进行了拼接组合以后,网络的收敛速度得到了提升,且训练得到的模型效果也得到了一定改善。
4 结语
本文基于深度学习及《中国图书馆分类法》提出了文献的自动分类系统。使用NLPIR分词系统来对文献进行分词,使用Skim-gram词向量模型来训练词向量,基于文献的特征词向量矩阵与卷积神经网络来进行文献的归类。对比试验表明,本文的网络模型相较于其它参与试验的模型在文献的自动识别上有一定优势,基本大类完全准确率为97.66%,二级分类完全准确率为95.12%,而详细分类的完全准确率为92.42%。卷积神经网络拥有良好的特征提取能力,能够准确的提取到文献的关键信息点,基于卷积神经网络的文献分类系统拥有很大的发展潜力。此外,对于语义歧义的研究也有助于提升分类的准确性。在接下来的研究中如何解决同一语义的干扰及如何进一步细化文献特征是研究的重点与难点。
参考文献:
[ 1 ]朱红涛,李姝熹.国内图书馆智慧服务研究综述[J].图书馆学研究,2019(16):2-8.
[ 2 ]文榕生.类目控制是《中图法》修订的重点之一[J].图书馆论坛,2010,30(6):205-208.
[ 3 ]王效岳,白如江,王晓笛,等.海量网络学术文献自动分类系统[J].图书情报工作,2013,57(16):117-122.
[ 4 ]谢红玲,奉国和,何伟林.基于深度学习的科技文献语义分类研究[J].情报理论与实践,2018,41(11):149-154.
[ 5]徐彤阳,尹凯.基于深度学习的数字图书馆文本分类研究[J].情报科学,2019,37(10):13-19.
[ 6]俞敬松,魏一,张永伟,等.基于非参数贝叶斯模型和深度学习的古文分词研究[J].中文信息学报,2020,34(6):1-8.
[ 7 ]唐琳,郭崇慧,陈静锋.中文分词技术研究综述[J].数据分析与知识发现,2020,4(Z1):1-17.
[ 8 ]郭利敏.基于卷积神经网络的文献自动分类研究[J].图书与情报,2017(6):96-103.
[ 9 ]李湘东,胡逸泉,巴志超,等.数字图书馆多种类型文献混合自动分类研究[J].图书馆杂志,2014,33(11):42-48.
[ 10]吴小晴,万国金,李程文,等.一种改进TF-IDF的中文邮件识别算法研究[J].现代电子技术,2020,43(12):83-86.
[11 ]ZHANG J,CHOW C.CRATS: an LDA-based model for jointly mining latent communities, regions, activities, topics, and sentiments from geosocial network data[R].IEEE Transactions on Knowledge and Data Engineering,2016, 28(11):2895-2909.
[ 12]吴皋,李明,周稻祥,等.基于深度集成朴素贝叶斯模型的文本分类[J].济南大学学报(自然科学版),2020(5):1-8.
[ 13 ]郭超磊,陈军华.基于SA-SVM的中文文本分类研究[J].计算机应用与软件,2019,36(3):277-281.
[ 14 ]LAN M, TAN C L, SU J,et al.Supervised and traditional term weighting methods for automatic text categorization[R].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 31(4):721-735.
[ 15]MIKOLOV T , CHEN K , CORRADO G, et al. Efficient estimation of word representations in vector space[J]. Computer Ence, 2013.
[ 16 ]XIAO L, WANG G,ZUO Y.Research on patent text classification based on Word2Vec and LSTM[R].International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 2018(11):71-74.
孔 洁 中国劳动关系学院图书馆中级工程师。 北京,100048。
(收稿日期:2020-07-26 编校:曹晓文,刘 明)
