融合数据增强与多样化解码的神经机器翻译
2021-06-22张一鸣刘俊鹏宋鼎新黄德根
张一鸣,刘俊鹏,宋鼎新,黄德根
(大连理工大学计算机科学与技术学院,辽宁 大连 116024)
近年来,随着端到端结构[1]的提出,神经机器翻译获得了迅速发展.早期的神经机器翻译采用循环神经网络对句子建模,将源语言的句子压缩成一个向量供译文生成使用;但传统的循环神经网络在训练时容易发生梯度爆炸和梯度消失的问题[2],无法有效地传递长距离的信息,因此翻译效果较差.为此,长短期记忆网络[3]和门循环单元[4]的引入能更好地捕捉长距离依赖,显著改善了神经机器翻译系统的性能,从而超越了统计机器翻译方法[5-6].然而,考虑到循环神经网络训练的不稳定性以及串行执行的低效率,一些高效并行的网络结构被相继提出,其中应用最广泛的是基于卷积神经网络的ConvS2S模型[7]和基于自注意力机制的Transformer模型[8].相比之下,Transformer模型的翻译性能更加优异,目前已成为机器翻译领域的主流模型.但受限于词表大小和双语语料规模,神经机器翻译往往在实体翻译和模型泛化性上表现不佳;同时,解码阶段采用“最佳模型”进行预测的方式可能无法获得全局最优的译文结果.
面向第16届全国机器翻译大会(CCMT 2020)中英新闻领域的机器翻译任务,本文主要从以下3个方面改进上述问题:1) 数据泛化.基于规则识别匹配和外部资源对时间表达式、数字、人名等实体进行泛化.2) 数据增强.使用源端单语句子构造伪双语句对,通过长度比、词对齐等筛选条件对伪语料进行过滤,然后扩充到双语平行语料中提升翻译性能.3) 多样化解码策略.调整长度惩罚因子、束搜索宽度参数,尝试用不同的方式结合检查点平均和模型集成来进行解码,并以双语互译评估(BLEU)值作为评价标准对多个候选译文进行重打分,得到最优译文.
1 数据泛化
1.1 语料预处理
实验使用的数据集均来自CCMT 2020公开的语料,包括CCMT中英新闻领域的双语平行语料和中文单语语料XMU-CWMT 2017.其中,双语句对数量约为902万,中文单语句子数量约为500万.
首先,为了提高数据质量,在训练前对上述语料进行过滤处理,包括:过滤含有乱码的句子,将转义字符替换为对应的符号,将全角符号统一转换为半角格式,去除重复的句子.其次,为缓解词汇稀疏的现象,对语料进行泛化处理,详见1.2节.之后使用NiuTrans[9]中提供的分词工具对中英文进行分词,并筛选保留中英文句子长度比在0.4~1.6范围内的句子.最后,为了精简词表,更好地解决集外词的问题,采用Sennrich等[10]提出的字节对编码(byte pair encoding,BPE)(https:∥github.com/resennrich/subword-nmt)分别将中英文词语切分成更小粒度的子词,翻译后再进行恢复.
1.2 语料泛化处理
新闻领域的语料中常包含着大量的命名实体,如人名、地名和机构名等,这些命名实体出现的次数较多,但重复率不高,尤其是人名.为了缓解词汇稀疏的现象,本研究对语料进行泛化处理[11].对训练语料进行人名泛化,在测试阶段对中文单语进行人名、地名和机构名的泛化.同时,对时间表达式、数字等特殊表达也进行了泛化.采用基于规则的方法对数字、日期和时间表达式进行识别和匹配,然后用“$number”、“$date”和“$time”标签对匹配项进行替换.在一个句子中通常存在着多个同类泛化成分,为了加以区分并降低恢复难度,在标签中添加不同的数字编号进行区分,即“$number_i”、“$date_i”、“$time_i”(i=0,1,…,n).采用实验室内部开发的中文实体识别工具和Stanford CoreNLP开源工具(http:∥nlp.stanford.edu/software/stanford-english-corenlp-2018-10-05-models.jar)分别对中英文实体进行识别.然后,基于中英文人名词典对人名进行识别匹配.初步匹配后,根据中文人名常使用汉语拼音作为英文翻译这一特点,综合拼音模糊匹配以及中英文人名首字母音译规律对人名进行再次匹配.用“$name”标签对匹配项进行替换,同样加数字编号进行区分,即“$name_i”(i=0,1,…,n).受限于外部资源,仅在测试阶段对中文单语增加了地名和机构名的泛化.通过训练集的词频统计,使用中国省份名称的中英文翻译作为标签对两类实体进行泛化,如“北京-Beijing”和“天津-Tianjin”等.
数据泛化阶段,双语语料的泛化需要保证中英两侧泛化标签的一致性,若存在单侧识别不匹配的情况,则保持原有形式不作处理;单语语料的泛化则需要对所有匹配项进行泛化处理.由于在测试阶段对单语进行了泛化处理,所以解码后的译文中包含泛化标签,根据标签对应关系对泛化部分进行恢复后才能得到最终译文.对于数字、日期和时间表达式来说,统计常用中英文表达的转换规律,根据这些规律编写固定的翻译规则进行恢复;对于人名、地名和机构名来说,使用外部词典进行还原.对人名来说,若词典中无匹配结果,则使用中文人名的拼音作为英文翻译结果.
2 数据增强
为了更好地利用单语语料,Sennrich等[12]提出了一种利用目标端的单语数据生成伪双语句对的数据增强技术,即反向翻译技术,可以有效扩充训练语料,提升翻译质量.Zhang等[13]提出了利用源端单语句子的数据增强方法,同样可以有效地增强双语模型.在此基础上,采用正向翻译技术来构造伪双语句对,以此来增强双语模型.数据增强的总体流程如图1所示.
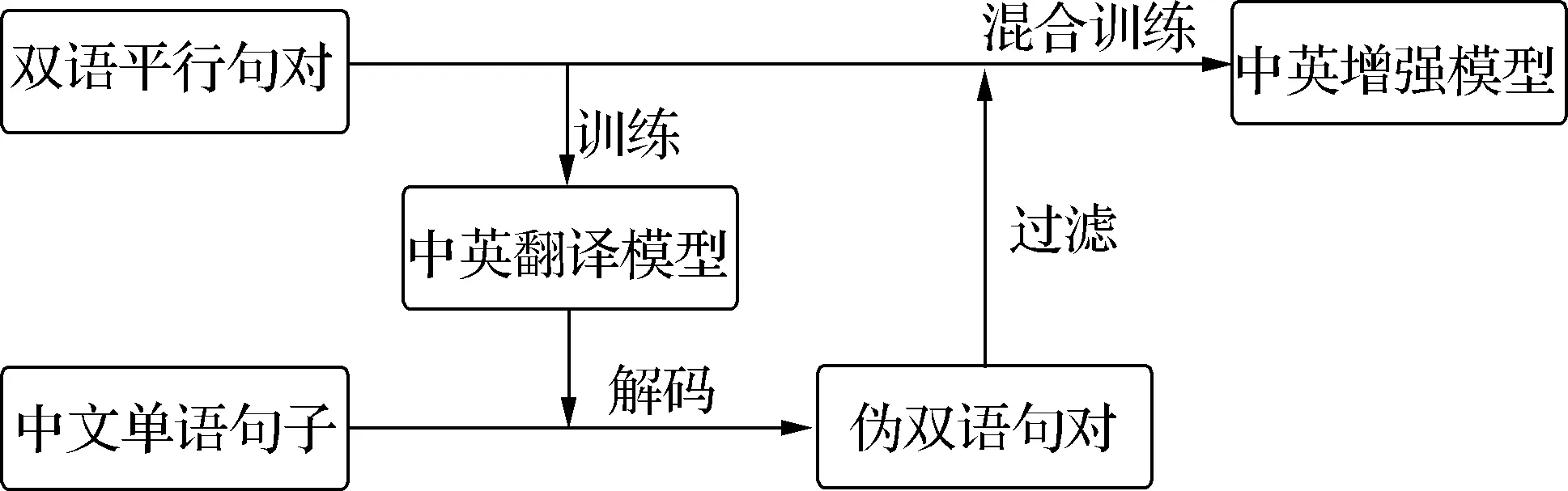
图1 数据增强流程图Fig.1 Flow chart of data enhancement
2.1 伪双语语料的构建
为了提高伪双语句对的质量,需要对中文单语语料进行额外的过滤处理,包括:去除包含特殊符号的句子,去除字符长度小于11且中文字符占比小于0.5的句子,以“;”和“。”作为切分点对长句进行切割.
过滤后得到质量相对较好的中文单语语料.利用事先训练的一个翻译性能较好的正向翻译模型将该中文单语语料翻译成英文平行语料,进而共同构成初始伪双语语料.
2.2 伪双语语料过滤
为了保证伪双语语料的质量,使用长度比和词对齐两个约束对生成的伪双语语料进行过滤:首先,将长度比限定在0.4~1.6的范围内,剔除句子长度差距过大的句对以减少干扰;其次,使用GIZA++工具(http:∥code.google.com/p/giza-pp/downloads/detail?name=giza-pp-v1.0.7.tar.gz)对伪双语句对进行词对齐,去掉词对齐比率过低的句子.过滤后,将伪双语语料扩充到双语平行语料中形成新的训练集.融合后训练集中包含的双语平行语料和伪双语语料句子数分别为670万和680万,其中关于双语平行语料和伪双语语料的统计均为过滤之后实际用于训练的数量,在此基础上训练数据增强后的中英神经翻译模型.
3 解码策略
实验融合检查点平均[14]、模型集成、重打分方法在解码阶段提高译文质量.下面分别对这3个方面进行介绍.
1) 检查点平均.检查点平均是指将同一模型在不同时刻保存的参数进行平均.保存的参数通常选择模型基本收敛时对应的最后N个时刻的参数,防止引入其他噪声.以同等的权重对N个检查点的参数进行平均,得到鲁棒性更强的模型参数.
2) 模型集成.模型集成是利用多个机器翻译系统协同进行解码的方法,在神经机器翻译领域有着广泛的应用[14-15].集成解码使用的模型可以使用同构或者异构的系统,一般来说结构和初始化均不同的模型通常更具有差异性,能够带来更大的提升.
3) 重打分.解码阶段,同一个源句子可以通过调整长度惩罚因子和束搜索宽度参数设置的方式生成多个候选译文.进一步实验发现,对于不同的源句子而言,最佳候选翻译往往对应不同的参数设置.因此,使用单一参数设置解码得到的译文结果往往无法达到最优.为此,实验中使用句子级别的BLEU值作为评分标准,通过重打分选取多个候选译文结果中得分最高的句子作为最终输出.
实验采用相同的验证集,通过调整训练语料规模以及随机初始化等方式训练了k个英文到中文的翻译模型M1,M2,…,Mk以用于重打分.当输入一个中文源句子S进行解码时,首先通过调整参数的方式生成n个候选译文,形成候选列表C.然后,选取C中的一个候选译文Ci,使用M1,M2,…,Mk对其进行反向解码,将其重新翻译成多个中文句子L1,L2,…,Lk.分别计算L1,L2,…,Lk与S的BLEU值,得到V1,…,Vk.以模型M1,M2,…,Mk在训练阶段验证集上获得的最高BLEU值作为各自的权重W1,…,Wk,通过加权求和得到译文句子Ci的评价分数Si.重复上述操作,循环n次后得到与候选列表C相对应的评价分数列表.最后,对比n个候选译文的评价分数,从C中选择得分最高的候选译文T作为最终输出.
4 实验结果
4.1 实验参数
本实验使用开源框架THUMT(http:∥github.com/THUNLP/THUMT)中提供的Transformer模型作为基线系统,实验参数如下:编码器与解码器的层数均为6层,词向量与隐层状态维度均为512,前馈神经网络中的隐层状态维度为2 048,多头注意力机制使用8个头.训练阶段中的每个批次(batch)包含6 250个词,模型训练20万步,每2 000步保存一次模型参数(检查点),并在训练过程中保存最优的10个检查点.损失函数使用极大似然估计,并使用Adam梯度优化算法,初始学习率为1.0,预热学习步数为4 000.训练集双语语料使用BPE算法进行切分,中英文词表大小均限制为3.2万,且两者不共享词表.解码阶段,使用集束搜索算法和长度惩罚因子对模型进行调优.实验使用两个NVIDIA TITAN Xp GPU进行训练.
模型方面,首先通过随机初始化参数的方式训练了4个增强的中英模型,然后选取每个模型中BLEU值得分最高的3个检查点进行检查点平均,最后对4个平均模型进行模型集成来完成最后的解码.在重打分阶段引入了4组不同参数设置下生成的译文结果作为候选项,训练了3个不同的英中模型用于译文结果的重打分.
4.2 实验结果与分析
系统在验证集newstest2019上的结果如表1所示,评测指标采用大小写不敏感的BLEU值,使用multi-BLEU(https:∥github.com/moses-smt/mose-sdecoder/blob/master/scripts/generic/multibleu.perl)作为评测工具.
从表1可以看出,在基线系统(系统0)上逐步加入正向翻译、检查点平均、模型集成、重打分构成系统1~4,这些方法对系统BLEU值的提高均有帮助,总体可提高4.89个百分点.其中,正向翻译技术提升的效果较为显著,相较于基线系统可以提高3.48个百分点,说明单语数据的引入可显著提升机器翻译的性能.
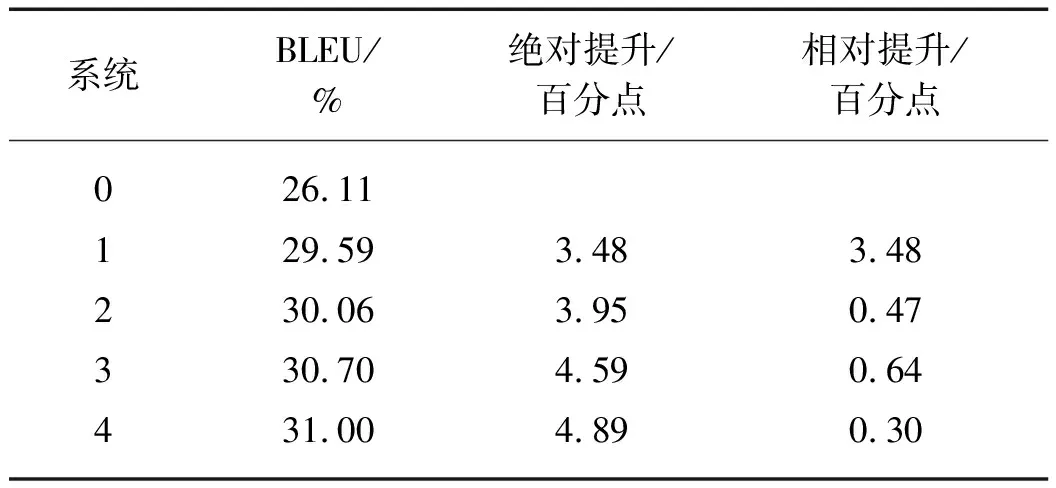
表1 newstest2019验证集的BLEU值Tab.1 BLEU values of newstest2019 validation sets
同时,在实验过程中对以下3个方面进行分析:
1) 正向翻译分析
在数据增强实验阶段,使用长度比和词对齐两个约束条件对生成的伪双语句对进行过滤.为了探索语料过滤手段的有效性,分别将过滤前和过滤后的伪双语语料与双语平行语料融合生成不同的训练集,然后各自训练生成不同的中英翻译模型.对比分析两个模型在验证集上的表现来检验语料过滤的有效性,结果如表2所示.可以看出:伪平行语料的加入有助于双语模型的提升;同时,伪双语语料的过滤能有效地消除语料中的噪声,进一步提高语料质量.

表2 语料过滤对翻译性能的影响Tab.2 Influence of corpus filteringon translation performance
2) 长度惩罚因子分析
在正向翻译实验的基础上探索了不同的长度惩罚因子α对实验的影响.首先,将束搜索大小设置为12,然后调整长度惩罚因子的值来进行实验,结果如表3所示.随着长度惩罚因子的增加,BLEU值呈现先增后减的趋势,说明在一定范围内调整长度惩罚因子有助于BLEU值的提高,而过大的长度惩罚因子可能会导致束搜索无法选择正确的结果.

表3 长度惩罚因子对BLEU值的影响Tab.3 Influence of length normalization on BLEU values
3) 束搜索大小分析和重打分分析
(a) 束搜索大小分析 实验探索了不同的束搜索大小对实验的影响.将长度惩罚因子α设置为1.6,通过调整不同的束搜索大小来进行对比实验,结果如表4所示:随着束搜索大小的增加,BLEU值有所提高.对比束搜索大小设置为12和15时得到的译文结果,可以发现:束搜索大小设置为15时整体BLEU值虽然有所提高,但是会使部分句子的BLEU值变低,即两种设置下存在不同的高分句子,使得整体的译文结果无法达到最优.进一步分析发现,当束搜索大小从12增加到15时,虽然会使验证集中194个译文句子的BLEU值上升,但也使得121个译文句子的BLEU值下降.为此本文采用重打分进一步提高整体的翻译性能.

表4 束搜索大小对BLEU值的影响Tab.4 Influence of beam size on BLEU values
(b) 重打分分析 由于条件限制,实验过程中只对束搜索大小为12和15的两种情况进行了重打分分析.将二者各自得分最高的译文句子综合在一起进行重打分,BLEU值为29.95%,可见综合不同参数设置下BLEU值得分最高的句子生成的译文结果比单一参数设置下译文结果的BLEU值有所提升,可以缓解部分句子在参数调整阶段得分降低的情况,提升整体的翻译质量.
5 结 论
面向CCMT 2020中英新闻领域机器翻译任务,本研究提出了一种融合数据增强技术和多样化解码策略的方法来提高机器翻译的性能.使用Transformer作为基线系统,从数据处理、数据增强、多样化解码策略3个方面进行了改进.实验融合了包括正向翻译、检查点平均、模型集成、重打分等多种技术来提高翻译性能.实验结果显示,这些方法能够明显提高译文质量,且改进后的系统较基线系统的BLEU值提升了4.89个百分点.
在下一步的工作中,拟扩充语料的规模并结合更深层次的模型配置以提高双语模型的整体性能,同时拟通过迭代回译等方式更好地利用单语数据增强双语模型,并尝试在重打分阶段融入更多的特征来筛选译文结果.
