基于RVM和全纯嵌入法的考虑多风电场出力相关性的电-热互联概率能流计算方法
2021-06-19苏晨博刘教民
朱 溪,苏晨博,刘教民
(华北电力大学 电气与电子工程学院,北京102206)
0 引言
随着电网中风电等可再生能源数量的不断攀升,新能源的不确定性对IES运行状态的影响愈发突出[1],[2]。目前,主要采用概率能流(Probabilistic Energy Flow,PEF)研究不确定性对IES的影响[3]。PEF分析方法主要包括蒙特卡罗模拟法(Monte Carlo Method,MCM)[4]、半不变量法[5]和点估计法[6]。半不变量法根据输入变量的半不变量结合级数展开求取输出量的概率密度函数,该方法既能维持较高的运算效率,又能保证计算结果的精度[7]~[9]。然而传统的半不变量计算方法都是基于NR法,当电-热联合系统包含大量新能源时,该算法容易出现迭代不收敛的情况。
为了解决上述问题,SD Rao提出了一种新的非迭代方法,称为全纯嵌入法(Holomorphic Embedding Method,HEM)[10]。HEM具有一个显著的优点:如果系统存在解,则该方法能够保证最终找到一个可以运行的解;相反,如果系统没有解,则计算出的有理近似值会产生数值振荡[11],[12]。
风机的输出功率受到风速的影响,且同一地理区域内的风速存在非线性相关性[13],因此在计算含风电场的电-热联合系统的概率能流时要充分考虑这种时空相关性[14]。根据Copula函数的特性和原理,多元变量的相关性模型可利用二元Copula的概率密度函数和边缘概率密度函数相乘获得[15]。但是特定的二元Copula很难准确地刻画风速这类复杂变量的分布特性[16]~[18]。
为此,本文首先提出一种基于RVM的多维风场风速的联合分布计算方法,该方法采用核函数能有效地避免参数估计带来的二次误差,从而提高计算精度,并且其权重系数矩阵为稀疏阵,能够大幅度提升计算效率。其次,基于HEM方法提出一种考虑风电出力相关性的计算电-热互联系统概率能流的新算法。相较于传统的NR法,该算法具有更好的收敛性和准确性。
1基于RVM的多维Copula函数模型
RVM以基函数为框架,以贝叶斯理论中的先验分布和极大似然估计为基础,将低维度的非线性问题转化为高维空间的线性问题,并采用自动相关决策理论(Automatic Relevance Determination,ARD)来约束模型,进而获得更加稀疏和精确的结果。假设给定训练集{xi,ti},其中,xi和ti分别表示输入样本矢量和相应的目标值;N为样本总数,则RVM的数学模型可以表示为
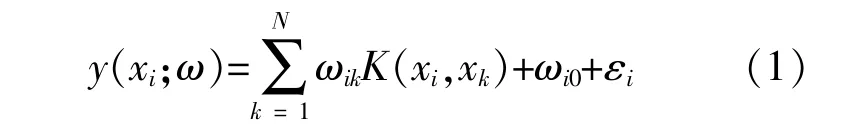
式中:K(xi,xk)为核函数;序列ω=(ω1,ω2,…,ωn)T为每个核函数所对应的权重系数;ωik为对应于输入矢量xi的第k个权重系数;ωi0为权重系数的偏差量(即常数项);εi为与目标值之间的误差。
权重系数ω的条件分布表达式如下:
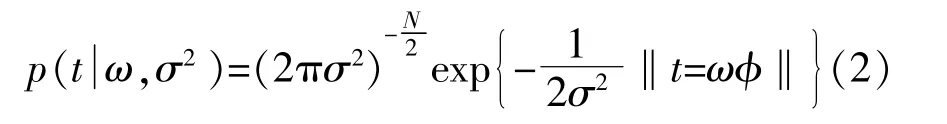
式中:φ=[φ(x1),φ(x2),…,φ(xN)]为基函数序列,通过核函数构建,它们之间的关系可以表示为φ(xi)=[1,K(xi,x1),K(xi,x2),…,K(xi,xN)]T。
在本文中,输入矢量是从不同的风速序列V=(v1,v2,…,vN)T中采样所得。
根据统计学理论可知,极大似然法可以直接估计ω和σ2的值,但是很容易过拟合,导致拟合不准确。因此,采用标准正态分布的权重先验概率分布来约束这两个参数。根据贝叶斯理论可知,后验概率分布等于加权先验分布乘以极大似然估计[20],则后验概率分布p(ω|t,σ2,α)的表达式如下:
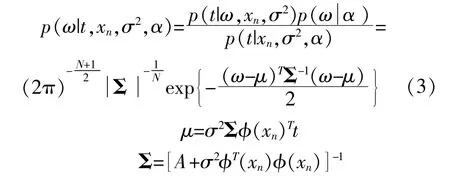
式中:A=diag(αi);σ为样本矢量xn的标准差;μ为样本均值矢量;Σ为样本协方差矩阵。
本文中的目标函数t(t1,t2,…,tn)T是从多维经验Copula序列Cn中采样获得。根据R-Vine Copula理论[19],多维经验Copula函数可以由二维经验Copula函数Cb、边缘概率密度fi(vi)和条件分布fi|j(vi|vj)共同构建[21]。由RVM的定义可知,其回归精度主要取决于核函数的种类。为了能够更加准确地描述风速这类非线性变量的联合分布,本文采用高斯核函数作为RVM的基函数[21],因此,式(3)中的α和σ2可以由迭代获得,分别为
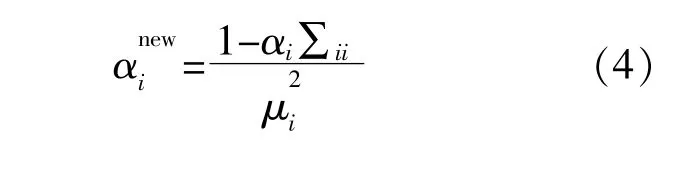
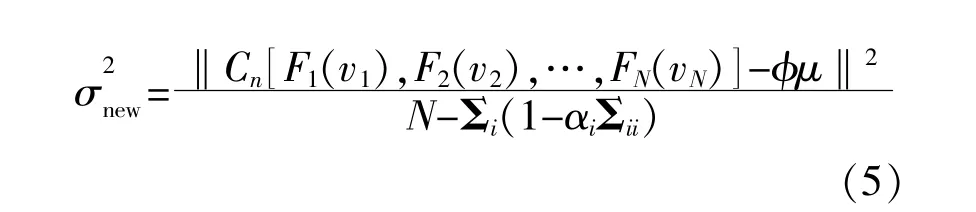
式中:μi为后验均值μ的第i个分量;∑ii为后验协方差Σ中的第i个对角线分量。
将迭代得到的α和σ2代入式(3),可以得到权重系数ω的修正值。因此,基于RVM的多元Copula可以表示为
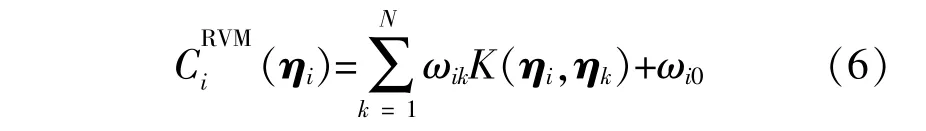
式中:ηi=[F1i(v1),F2i(v2),…,FNi(vN)]T为风速序列i的边缘分布矢量。
利用计算出的多维风场风速的联合分布计算得到相关系数矩阵ρ,结合Nataf变换[24],获得计及相关性的独立风速分布序列,然后根据风速和风电功率的函数关系得到独立的风功率序列。
综上,RVM有两个关键优势:①利用核函数为基本框架代替参数估计,能够更加精确地刻画风速这类非线性变量的联合分布;②该模型中,每个权重参数ωi均有一个单独的超参数αi,而不需要与其它权重参数共享超参数。在计算过程中,参数矩阵α中的大部分元素将增至无穷大,此时ω的后验分布大量集中在零处,保证了权重矩阵的稀疏性,因此,该方法既能确保计算精度又能提高计算速度。
2 基于全纯嵌入法的概率能流计算方法
2.1 电力网络模型
电力系统采用经典交流系统模型,其直角坐标系下PQ和PV节点表达式为
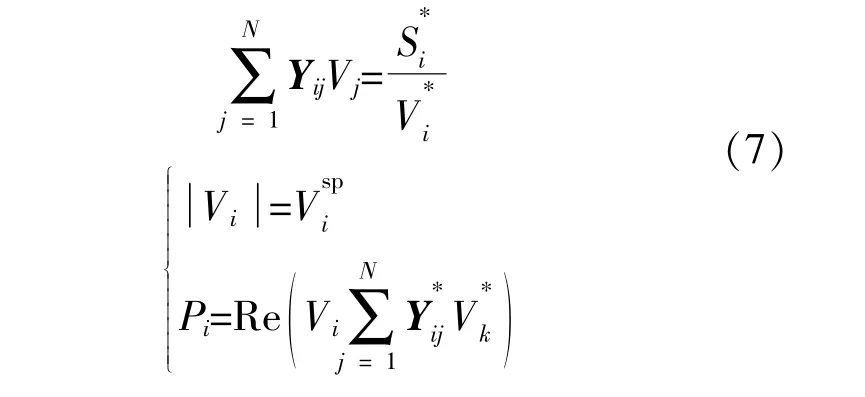
式中:Si为节点i注入的功率,Si=Pi+jQi,Pi,Qi分别为有功功率和无功功率;Vj为节点j的电压;Vi为节点i的电压;V为平衡节点电压幅值;Yij为导纳矩阵。
HEM方法通过构造状态量复数域的级数展开求解系统潮流问题,其表达式为[10]
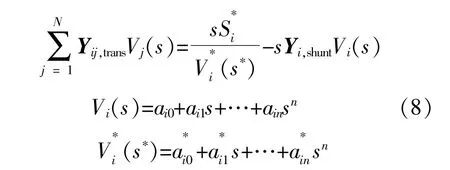
式中:Yij,trans和Yi,shunt分别为导纳矩阵Y的串联支路部分和并联支路部分;a*in为复幂级数系数ain的共轭;Vi(s)为电压复幂级数。
为了求解上式中的级数序列,将Vi(s)的倒数表示为Wi(s)=bi0+bi1s+…+binsn。Vi(s)和Wi(s)的乘积可以表示为其系数的卷积,系数矩阵ain和bin的关系为
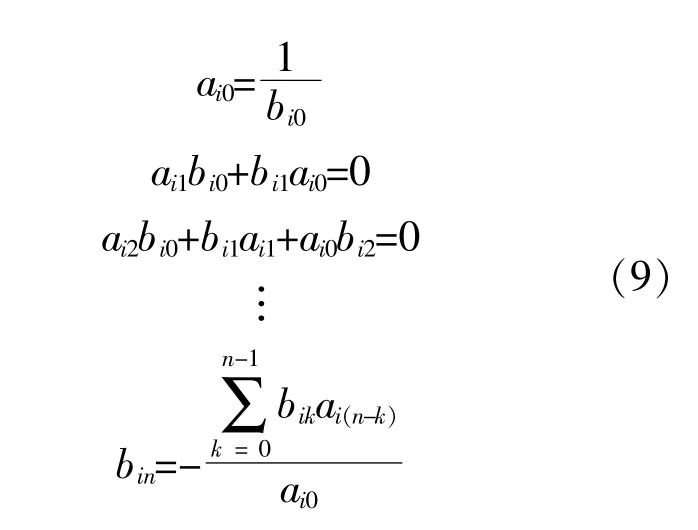
将式(9)代入式(8),得到节点功率的复幂级数展开式:
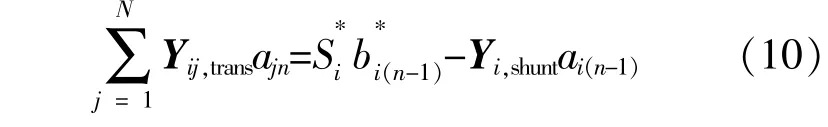
通过式(9)和(10)定义的递推关系计算得到系数ain和bin,然后进一步计算PQ节点的电压序列。PV节点的电压幅值和有功功率均为已知量,而无功功率和节点电压相角为未知量。假设节点i的无功功率为Qi,则其所对应的复幂级数展开式为

将式(9)带入式(11),得到PV节点电压和无功功率的复幂级数展开式:
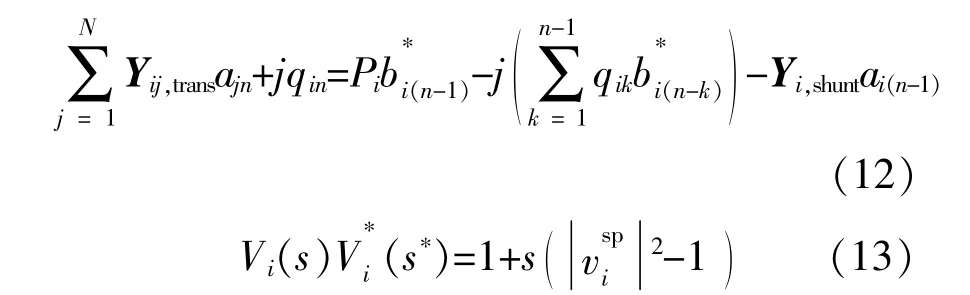
将式(7)带入式(12),并假设电压复幂级数的常数项ai0=1.0,则其余项的系数可以表示为
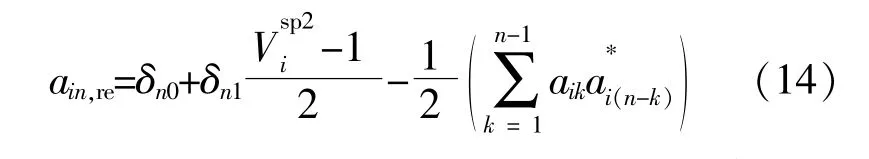
式中:ain,re为电压复幂级数的系数实部值;δn0和δn1为示性函数,其值为0或1。
结合式(9),(12)和(14),计算得到节点电压复幂级数Vi(s)和Qi(s)的值。
2.2 热力系统模型
在热力系统模型中,水为主要的液体热媒,在管道中实现热能的传递与转换。各管道中的热水在传输过程中满足流量连续性方程,根据能量守恒定律可得,热水在热力网络中各个管道的压头损失的总和应该为零。基于此,则有:
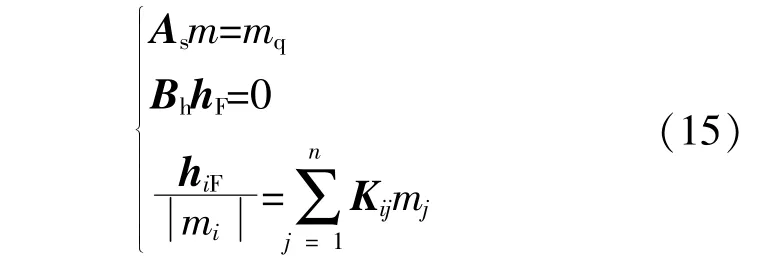
式中:As为热力网络流量方向的关联矩阵;m为各管道热媒的流量;mq为各管道节点中流出的热媒流量;Bh为管道的回路-支路关联矩阵;hF为热媒的压头损失向量;K为管道的阻力系数矩阵;mi为节点i流入的总流量;mj为管道j的流量。
针对热力网络中的负荷节点,基于节点供热温度Ts和节点输出温度To,可得热力网络的模型如下[22]:
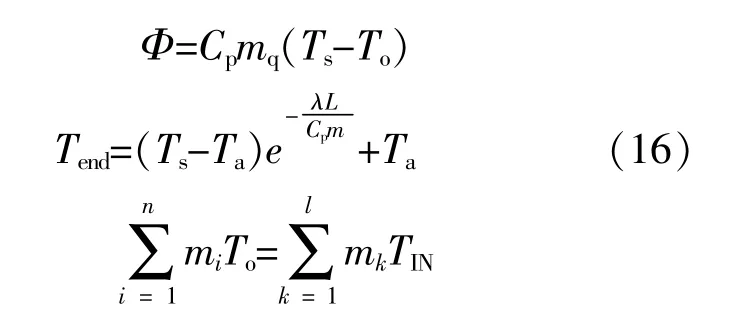
式中:Φ为热力网络中流过各节点的热功率;Cp为热媒介的比热容;Ta为热力网络外部的环境温度;Tend为各条管道的末端温度;λ为管道的热传导系数;L为各条管道的长度。
通过HEM方法,构造热力网络状态量的复数域级数展开求解热力网络模型。首先通过热力网回路-支路关联矩阵求得hF的值,将式(15)展开为复数级数形式:
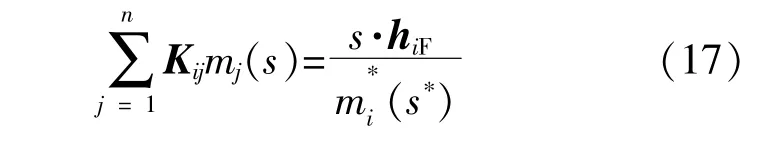
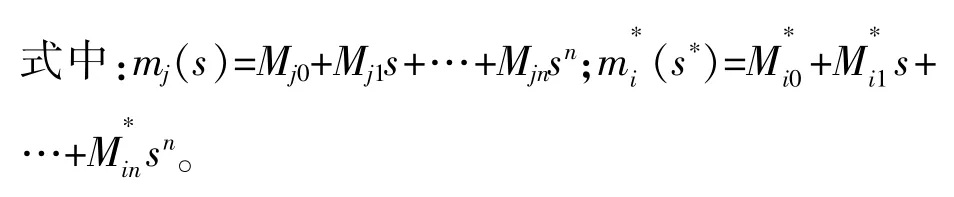
然后假设Ni(s)为Mi(s)的倒数,且其复数域级数展开式的系数有如下关系:
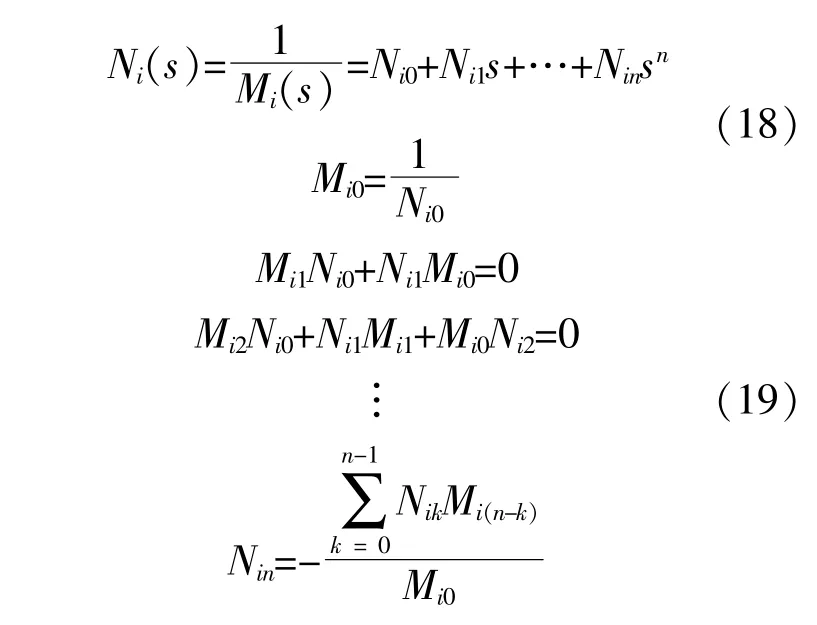
最后将式(18)和(19)代入式(17),得到热力网络各支路流量的复幂级数展开式。
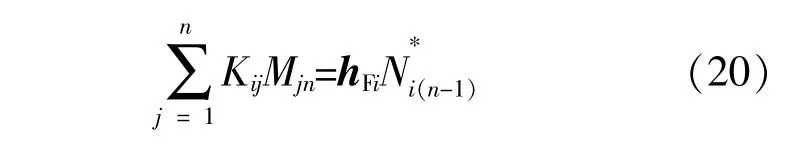
因此,可以通过式(19)和(20)定义的递推关系计算得到系数Min和Nin,进一步用式(16)计算出各节点的热力功率。
2.3 电热耦合环节
IES系统中存在着很多耦合环节,包括CHP机组、电锅炉和热锅炉等,本文只考虑电-热机组的耦合,其中电功率P和热功率Φ的关系为

式中:cm为热电比例系数,本文假设其为常数。
若节点k为电-热耦合节点,则热力网络功率方程须修正为
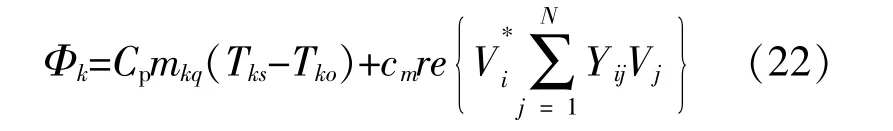
将修正后得到的节点k的热功率带入式(8)和(11),对电力系统网络的功率方程进行修正,由此可计算得到考虑耦合元件的电-热网络功率。其修正后的表达式如下:
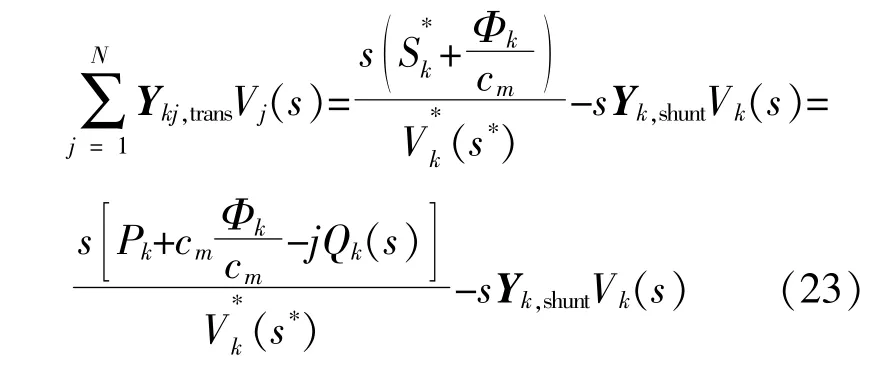
2.4 基于全纯嵌入法的半不变量模型
假设随机输入变量X的概率密度函数(Probability Density Function,PDF)和累积分布函数(Cumulative Distribution Function,CDF)分别为f(x)和F(x),则X的v阶矩和v阶中心矩的数学表达式为
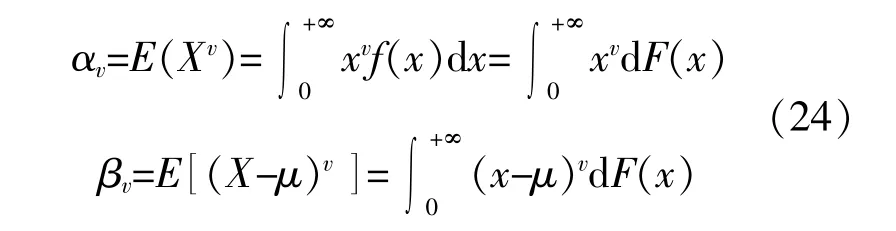
式中:μ为X的平均值。
进而推出v阶半不变量κv和αv的关系为
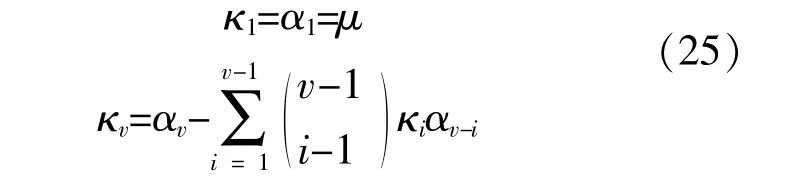
传统的半不变量是基于牛顿-拉夫逊算法,为了将其更好地应用于全纯嵌入方法,须要做进一步改进。假设P¯,Q¯和h¯F分别为电-热联合网络的有功功率、无功功率和节点压头损失向量的平均值,则联合网络能流的平均值模型为
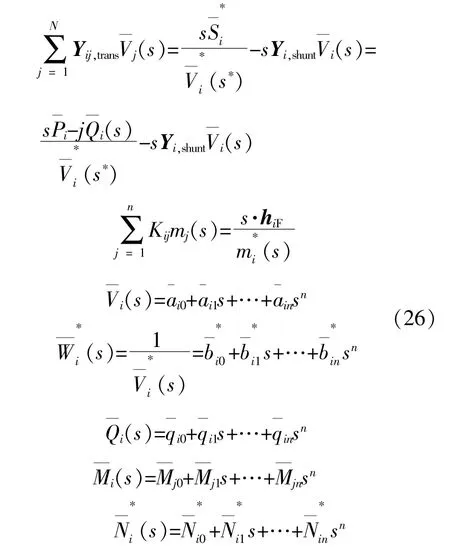
当s=0时,式(26)的解与无负载和无分流元件的联合网络相对应,其解可作为复数域幂级数的常数项系数。若Padé[10]逼近在s=1时的解不发生数值振荡,则系统收敛,此时系统状态量的均值可以表示为各系数的和:
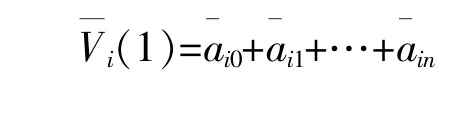

式中:G0和S0为由式(27)构成的系数矩阵。

式中:Zl0=Z0-G0S0W0。
因此,可以通过级数展开来计算电-热网络中状态量的PDF。与Gram-Charlier级数和Edgeworth级数相比,Cornish-Fisher级数在处理非正态分布的随机变量时具有更高的精度。本文采用Cornish-Fisher级数[23]计算热力网络状态量的概率密度。根据Cornish-Fisher级数展开理论,可得其前五阶的数学表达如下:
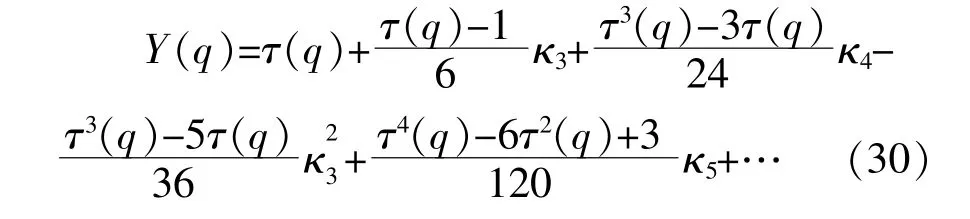
式中:Y(q)为输出的分位数;τ(q)为标准正态分布的分位数,满足τ(q)=Φ-1(q)。
3 算例分析
本文选取的IES系统如图1所示,其中:电气网络节点数为33个;风电场为4个,各个风电场中风电机组的额定功率为80MW,其运行参数为中国张北地区采集的风场的实际历史数据。本算例设定平衡节点的电压标幺值为1 p.u.,功率因数为0.98。除此之外,系统还有13个热力网络节点,其中包含两台电锅炉。
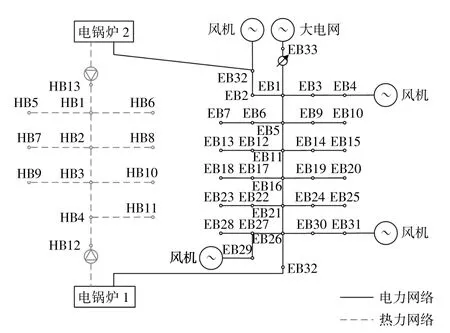
图1 电-热网络结构图Fig.1 Electrical-Heart structure network
热-电互联IES概率能流的计算过程如下。
①根据张北地区的实际采集数据,可以获得一定时间间隔的风速序列。基于风速的历史数据,利用核密度估计的方法计算得到各个风场中风速的边缘分布;然后基于RVM算法和二元经验Copula函数以及D-Vine结构计算四维风电场风速的联合概率密度以及联合分布。为了验证所提方法的精确性,本算例采用K-S检验和欧式距离对比分析不同算法[最小二乘法(Ordinary Least Squares,OLS)、最大期望值估计法(Expectation-Maximization Algorithm,EM)和RVM算法]得出的联合分布与经验分布之间的差异。改变风速的采样间隔,分别用每隔6 h,每隔1 h和每隔10min的风速序列作为采样空间,用以验证算例结果的普适性。本算例在采样风速数据时,选取了5%的显著水平,所得的d值和K值结果如表1所示。在K-S检验中,K值和欧式距离d越小,代表计算得到的各个风场的联合概率分布与实际各个风场的联合概率分布越接近。从表1中可以看出,所提算法拟合得到的联合分布函数的d值和K值均为最小。结果表明,本文所提算法能够更加精确地计算多维风电场风速的联合分布。
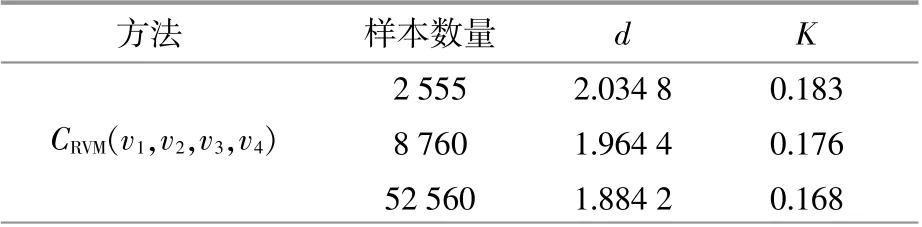
表1 风电机群风速联合分布对比Table 1 Comparison between differentmethods

续表1
注:CRVM(v1,v2,v3,v4)表示用RVM算法计算出的联合分布函数;COLS(v1,v2,v3,v4)表示采用OLS算法计算出的联合分布函数;CEM(v1,v2,v3,v4)表示用EM算法计算出的联合分布函数。
②利用计算出的多维风场风速的联合分布计算得到相关系数矩阵ρ,结合Nataf变换[24]得到计及相关性的独立风速分布序列,带入式(31)计算得到独立风功率序列Pw,然后进一步采用所提出的基于HEM算法的半不变量计算概率能流。
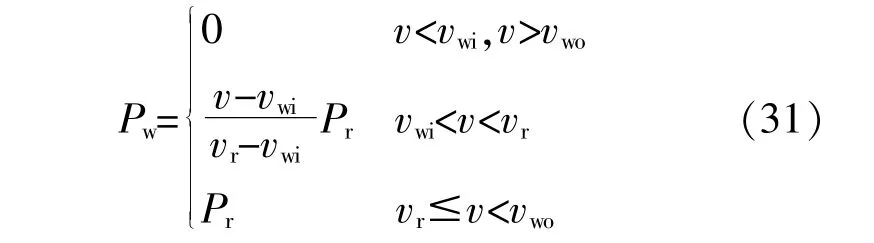
式中:vwi为切入风速;vwo为切出风速;vr为额定风速;Pr为风电机组的额定功率。
本文计算时参考实际风电场,设vwi为4m/s,vwo为25m/s,vr为12m/s。因为模型中的输入变量具有随机不确定性,通过所提方法计算得到的能流结果为概率分布的形式。利用搜集到的网络历史数据作为参考值,计算输出变量的期望值和标准差的相对误差。
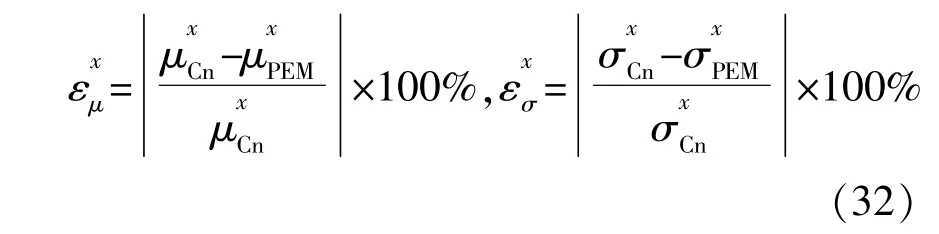
考虑到电-热互联IES概率能流模型的输出变量数量较大,本文计算了每类输出变量的相对误差的平均值AVG以及最大值MAX,来量化和评估所提算法的精确性。
本文分别利用基于考虑风电相关性的NR法的半不变量与基于考虑风电相关性的HEM法的半不变量,计算电-热网络状态量的概率密度并进行比较,结果如表2,3所示。结果表明,基于HEM法的半不变量计算得到的状态量期望值和标准差的平均误差小于基于NR法得到的平均误差,验证了所提算法的精确性;该方法将平均相对误差限制在4%以内,最大相对误差限制在10%以内;标准差的误差大于期望值的误差,这也符合半不变量法的特点。
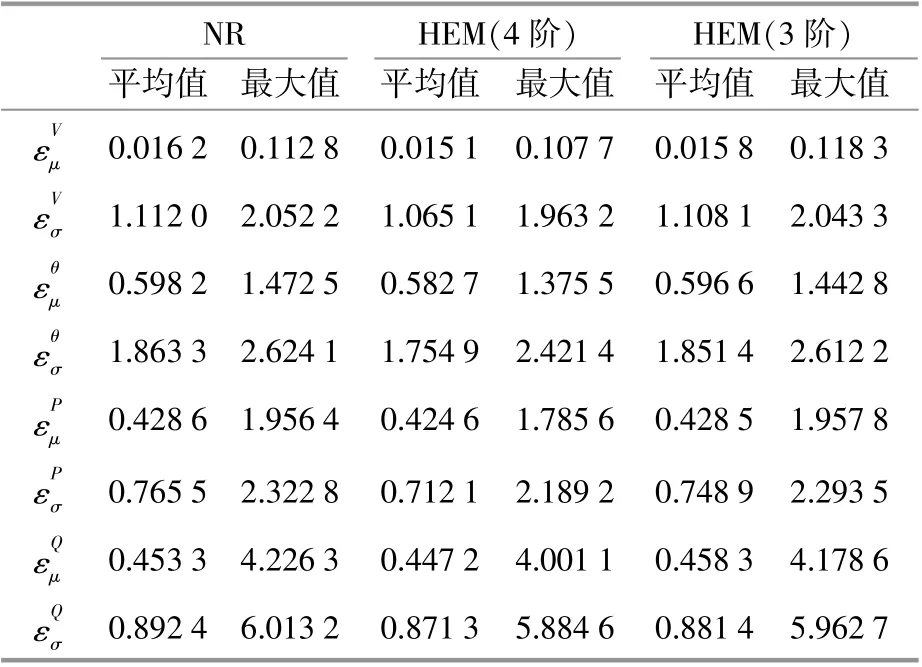
表2 电力网络概率能流误差结果Table 2 The PEF results of power system
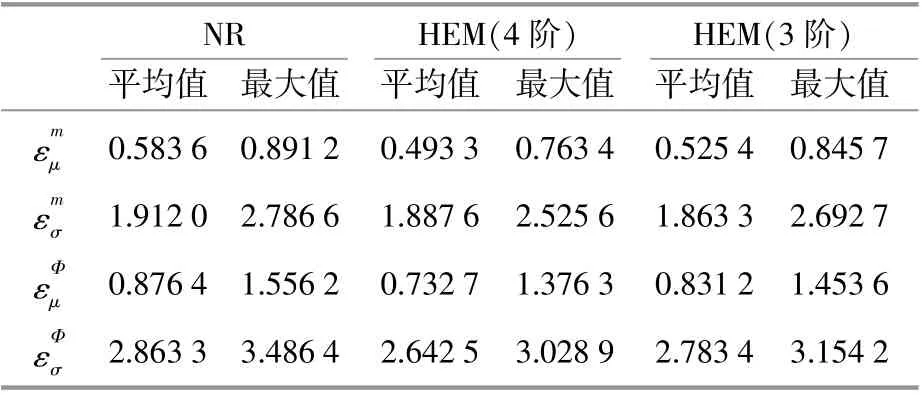
表3 热力网络概率能流误差结果Table 3 The PEF results of heartnetwork
电-热系统的节点电压和管道流量期望误差分别如图2,3所示,随着Padé逼近阶数的增加,所提算法的精度也在提高。然而,Padé逼近的阶数越高所需要的计算时间也越高,因此,在确保计算结果准确的前提下,应尽量减少其阶数。
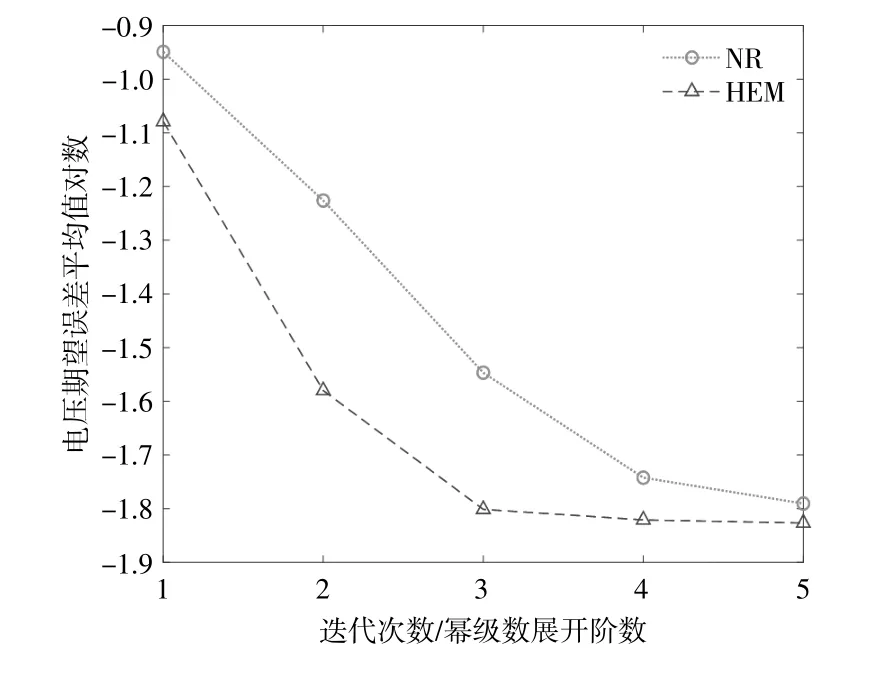
图2 电-热系统节点电压期望误差Fig.2 The error of node voltage in IES
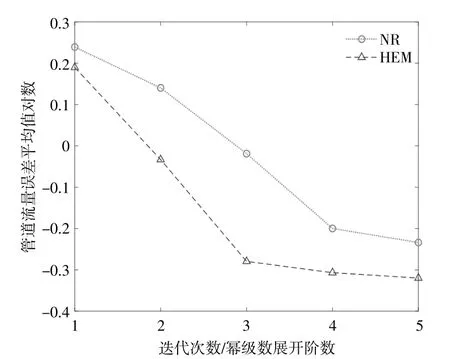
图3 电-热系统管道流量期望误差Fig.3 The error of pipeline flow in IES
4 结论
本文提出了一种基于RVM的多维风电场风速的联合分布计算方法。在此基础上,提出了一种基于HEM方法的新半不变量法用于电-热联合网络的概率能流计算,该算法具有更好的收敛性和计算精度。经过采用修改的IEEE 33节点系统结合热力网络13节点系统进行算例分析,得出以下结论。
①在分析多能源系统的运行状态时,应该考虑风速之间的相关性,其对系统能流具有重要影响。与传统的参数估计方法相比,基于RVM的多元Copula函数以核函数为基础,能够有效地避免参数估计带来的二次误差,计算结果也更加接近真实风速的联合分布。
②基于HEM和半不变量法的概率能流分析方法实现了对传统PEF计算方法的改进,具有更准确的概率分布计算结果。与NR方法相比,它在幂级数收敛半径以内或以外都能提供较好的收敛性,能够保证更好的计算精度。
