基于局部方差的医学图像配准模型
2021-06-18王金泽
王金泽
(华北电力大学控制与计算机工程学院,北京,102206)
0 引言
传统的医学影像科室已经无法满足患者的诊疗需求,基于医学影像的病理分析、病灶的诊断是一个需要大量的阅片经验支持的工作,由于不同医生对于影像理解存在主观差异性,并且缺乏定量的分析,导致在诊断时存在一定偏差。医学图像配准是数字医学图像智能分析处理的重要环节,指将两幅或多幅图像的相同解剖结构、区域进行变换,使之达到空间上的匹配,建立解剖结构一致性,为精确的图像信息获取以及深入的量化研究提供保障。基于深度学习的医学图像配准凭借其参数共享,效率高等优点成为了近年来的研究热点。Guha等人提出配准框架VoxelMorph[1],实现了体素到体素的无监督配准。Mok[2]等人受到传统配准方法SyN[3]的启发,提出一种对称微分同胚图像配准网络SYM-Net,该网络考虑参考图像与浮动图像之间的逆映射,保证了图像的拓扑保持性与变换可逆性。
然而,基于深度学习的医学图像配准存在局部形变配准效果差、鲁棒性差、抗噪声能力弱等缺陷,通过分析发现造成此现象的原因是由于训练样本不均衡所导致。针对这个问题,本文参考目标检测领域的样本均衡机制,以图像的局部方差作为样本难易程度的评价指标,对无监督配准模型中的损失函数进行改进,以体素块为单位对困难样本施加权重,加强对于局部形变的学习能力,从而提升深度学习配准模型的精度。
1 相关理论
■1.1 深度学习配准模型Voxelmorph


图1 Voxelmorph配准流程
■1.2 样本均衡机制
对于深度学习而言,数据集的质量直接影响到模型的学习程度,然而大多数算法在设计过程中都假设训练样本的分布情况是均匀的,因此将这些算法应用到实际数据中时,常常会遇到训练样本不均衡导致模型泛化性差的问题,该现象在单阶段目标检测领域尤为明显, Li[6]等人将其总结为训练样本难易程度不均衡,大量的简单样本会主导梯度会使得模型识别精度降低,针对此问题,Li等人在经典的交叉熵损失函数(CE Loss)上进行改进,提出Focal Loss,其核心思想为对样本建立难易指标,并根据难易指标设置权重因子,减小简单样本对于总Loss的贡献,以达到样本均衡的目的。
■1.3 局部方差
局部方差[7](Local Variance,LV)是医学图像领域经典的评估方法,能够体现图像的结构信息,单幅图像的局部方差的计算过程如公式(1)所示:
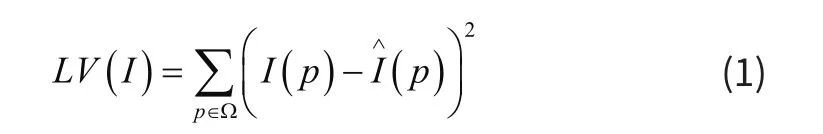
2 基于局部方差加权的损失函数FMSE-LV
基于无监督学习的医学图像配准存在大部分样本形变较为简单、易学习,而复杂形变样本数量少的特点,使得模型在处理复杂性变时往往效果不理想。因此本文参考Focal Loss的思路,对所有训练样本以难易为标准建立评价指标,并设计权重因子来为困难样本添加权重。无监督配准模型的损失函数由图像相似性测度以及变形场平滑性约束组成,其中相似性测度损失函数常用经典的均方误差LMSE惩罚变形后图像与参考图像间的相似度,LMSE如公式(2)所示。

LMSE能够指导模型在训练中更新参考图像与浮动图像之间的灰度差异,从而使得其相似性测度达到最高,是较为广泛使用的一种损失函数。然而,单个体素块的灰度差异由于其不能够体现结构信息,存在错误匹配,对噪声敏感等缺陷,使得其无法正确反馈变形场的形变难度。考虑到局部方差具有体现空间邻域性的特点,本文对原LV函数进行改进,改进成为适用于配准问题的局部方差函数RLV,如公式(3)所示:

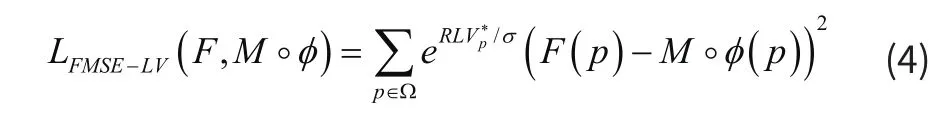
从公式(4)可以看出,权重ω可以根据局部方差平滑地调节体素块样本对于总Loss的贡献值,为困难样本增加训练权重,加强模型对于局部形变的学习能力。此外,融合了局部方差后的损失函数由于考虑了邻域体素块的灰度信息,使得在配准过程中体素块错误匹配的几率降低并且具有较好的抗噪声能力。
3 实验与分析
■3.1 数据集
本文选取公开数据集Mindboggle-101[9]中的80张3D脑部MRI图像进行实验,将全部图像进行预处理操作,包括像素值以及亮度归一化、体素间距统一等,并裁剪成160×192×160的尺寸,使用OASIS-30中的Atlas图像作为参考图像,其他图像作为浮动图像进行训练,训练数据和测试数据比例为0.75:0.25。
■3.2 实验环境与参数设置
本文的实验在Linux操作系统上进行,GPU使用NVIDIA/GeForce RTX 2080 Ti,内存为16GB,模型基于Pytorch框架编写,所有实验均使用Adam优化器,以3e-4学习率进行模型训练, Batch_Size设为1,局部方差的邻域窗口n大小设置为3,调节速率的因子σ设置为0.3,训练次数为5000次,共训练7小时。
■3.3 实验结果
为了更好地验证算法的有效性,本文从图像相似性测度,标签重叠度、变形场折叠程度三个方面进行评测,其中图像相似性测度使用互相关系数(CC),标签重叠度使用经过专业手工标注的大脑皮质区域标记之间的Dice系数,Dice和CC越高,代表图像配准结果越好。在变形场折叠度方面,使用雅克比行列式(Jac)中值为负数的体素块比例作为评价指标,Jac为负数的体素块数量越少,代表变形场越接近实际情况。分别将本文算法结果与传统仿射配准和未添加权重的MSE作为损失函数的深度学习算法进行对比,结果如表1所示。

表1 不同配准方法结果对比
从表1可以看出,在标签重叠度与相似性测度方面,本文算法在Dice与CC两个评价指标上都有所提升,在变形场折叠程度方面,本文算法得到的变形场的Jac负值比例较MSE仅提升了0.005%,说明为MSE添加了权重因子后,对模型预测的变形场质量并没有明显的影响,图2分别展示了测试集中某张病例的参考图像、浮动图像、MSE配准结果以及本文算法配准结果,可以看出,本文算法在局部细节(标注位置)的配准上更加接近于参考图像。

图2 配准结果对比
4 结论
本文通过对深度学习模型中的优化策略展开深入研究,将局部方差的空间邻域性以样本均衡机制加权的方式融入到MSE损失函数中,借助局部方差的结构信息引导权重配置,从而使所有训练样本的权重得到均衡分配,提升模型对于局部形变的学习能力,改善配准精度。然而由于在设置权重的过程中添加了超参数,使得模型在训练时缺乏一定的灵活性,后续工作将考虑设计出能够通过图像内部信息自适应调节权重的方法。
