Hybrid tree guided PatchMatch and quantizing acceleration for multiple views disparity estimation
2021-06-17ZHANGJiguangXUShibiaoZHANGXiaopeng
ZHANG Jiguang, XU Shibiao, ZHANG Xiaopeng
(National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, China)
Abstract: Existing stereo matching methods cannot guarantee both the computational accuracy and efficiency for the disparity estimation of large-scale or multi-view images.Hybrid tree method can obtain a disparity estimation fast with relatively low accuracy, while PatchMatch can give high-precision disparity value with relatively high computational cost.In this work, we propose the Hybrid Tree Guided PatchMatch which can calculate the disparity fast and accurate.Firstly, an initial disparity map is estimated by employing hybrid tree cost aggregation, which is used to constrain the label searching range of the PatchMatch.Furthermore, a reliable normal searching range for each current normal vector defined on the initial disparity map is calculated to refine the PatchMatch.Finally, an effective quantizing acceleration strategy is designed to decrease the matching computational cost of continuous disparity.Experimental results demonstrate that the disparity estimation based on our algorithm is better in binocular image benchmarks such as Middlebury and KITTI.We also provide the disparity estimation results for multi-view stereo in real scenes.
Key words:stereo matching; multiple views; disparity estimation; hybrid tree; PatchMatch
0 Introduction
Stereo matching or multiple-view matching has always been one of the most important research problems in computer vision because disparity(depth)estimation has played a crucial role in most computer vision applications, including depth of field rendering, consistent object segmentation, and multiple-view stereo(MVS).However, any of the current global or local stereo matching algorithms[1-3]is insufficient to show matching accuracy and calculation efficiency during the matching processing, therefore rendering numerous stereo matching-based applications incapable of achieving their desired performance.Most of the current stereo matching-based multiple-view reconstruction methods[4-6]suffer from low accuracy, model incompleteness, and time issues.Although many algorithms are being developed to achieve balance in processing precision and speed, several challenges still remain.
1 Related Work
In general,the traditional stereo matching process includes four main parts[7]: matching cost computation, cost aggregation, disparity estimation and disparity refinement(optional).Among them, matching cost computation and cost aggregation are the core stages in stereo matching.Firstly, according to the difference between pixels, matching cost computation will obtain a cost volume(disparity space image, DSI), which stores the similarity score for each pixel.Then, the cost aggregation is viewed as filtering over the cost volume, which plays a key role of denoising and refinement for DSI.At last, the disparities are computed with a local or global optimizer.Obviously, the quality of the matching cost computation and aggregation method has a significant impact on the success of stereo-matching algorithms.
Recently, Yang et al.[8]proposed a novel bilateral filtering method for cost aggregation processing to estimate depth information, which can be very effective for high-quality local stereo matching.Owing to the cost aggregation in local support window, the local minimum problem cannot be avoided.Yang et al.[9-10]further solved the problem by using a series of linear complexity non-local cost aggregation methods, which extends the support window size to the whole image and constructs a minimum spanning tree(MST).Because of the impact of global pixels, this method considerably improves computation speed and accuracy.In addition, Vu et al.[11]extended the above MST-based cost aggregation method and proposed a hybrid tree algorithm to estimate depth information by using pixel-and region-level MST, which can avoid the constructing errors of MST in a texture-rich region and improve the accuracy of the MST-based cost aggregation method.
By contrast to the preceding stereo correspondence algorithms mentioned in one-pixel precision, the recently proposed Patch-Match stereo[12]can directly estimate highly slanted planes and achieve notable disparity details with sub-pixel precision.Given its high-quality advantages, this kind of patch-based method has also been extended with different considerations and requirements[13-15].Furthermore, Shen[16]utilized the precise PatchMatch stereo to compute individual depthmap, which can achieve a depth-map merging-based MVS(Multi-View Stereo)reconstruction for large-scale scenes.Shen[17]extended his previous work and further proposed a PatchMatch-based MVS method for large-scale scenes.The PatchMatch process is utilized to generate depthmap at each image with acceptable errors and then enforced consistency over neighboring views to refine the disparity values.The experimental result proved that multiple-view reconstruction accuracy by using PatchMatch stereo is significantly better than other methods.Besse[18]proposed a PatchMatch belief propagation stereo matching algorithm, which improved the estimation accuracy of PatchMatch by using a global optimization strategy and achieved MVS matching in a 2-D flow field.Unfortunately, these strategies often contain a large label space for continuous disparity estimation that is difficult to balance between computational efficiency and estimation accuracy.
More recently, the development of deep learning methods have proved their convenient, efficient(excluding the time of network training)and academic potential in disparity(depth)estimation.The convolutional neural network(CNN)based pixel-level depth estimation method[34]achieved the monocular depth estimation ability by using supervised training network in the ground-truth training data collected from the depth sensor.By using multi-level contextual and structural information[35]in the CNN, depth estimation gets rid of the traditional algorithm based on geometry.However, the feature extractor of this kind of method needs repeated pooling, which leads to the reduction of feature spatial resolution and affects the accuracy of depth estimation.To solve this issue, Hu et al.[36]combined mutiple information of a single image to estimate depth.However, most of them only consider local geometric constraints, which will cause the surface of the depth map to be discontinuous and the boundary to be blurred.Chen et al.[37]proposed a spatial attention mechanism based network.The performance of depth estimation is improved by using global focus relative loss and edge sensing consistency modul.However, the lacking of real scale can not be avoided in monocular depth estimation.On the other hand, a considerable literature has grown up around the theme of CNN based stereo matching for disparity estimation, including MatchNet[19]obtains high-level feature maps through two CNNs and learns the correspondence between binocular images.MTCNN[20]transforms the stereo matching into a two-category classification problem.Then a classical stereo matching operation is required to restore the final disparity results.It can be seen that most of the deep learning-based methods perform disparity estimation by combining the learned features with the traditional stereo matching strategy.But people ignore the issue that supervised training and data set generation consume a lot of resources and time.For all this, end-to-end training strategy more or less reduces the time complexity of the deep learning algorithm.Such as DispNet[21]applies an optical flow detection end-to-end network FlowNet to improve the efficiency of binocular disparity estimation.GCNet[22]generates matching cost by using 3D convolution and end-to-end training to accelerate the speed.But most of them requires a large amount of memory space, which is not suitable for large-size images.
Although the CNN is the future development trend of stereo matching, and large number of training sets are required to improve the accuracy of parallax estimation, which is very labor-intensive and time-consuming task.At the same time, the existing deep learning based stereo matching methods have poor generalization performance and are not robust enough for real scene reconstruction.It is worth noting that the operation of the traditional stereo matching has strong mathematical theoretical foundations support(such as photo-graphic geometry and epipolar geometry), which conforms to natural imaging rules and the results are closer to the real physical environment.Therefore, deep learning methods cannot completely replace classical stereo matching.The integration of the above two is a more reasonable way to promote the development of stereo matching.So, a deep mining and development of traditional stereo matching theory still deserves to further study.
1.1 Differences and Contributions
In this paper, we extend our preliminary work[23]by applying hybrid tree-guided PatchMatch stereo and quantizing acceleration for a continuous disparity estimation framework.Therefore, the proposed disparity acquisition algorithm is based on the recently popular hybrid tree cost aggregation algorithm[11]and the accuracy PatchMatch stereo algorithm[12].Other advanced stereo matching methods(not limited to what we use)in one-and sub-pixel levels(sub-pixel and one-pixel is the precise level of disparity, which represent float-valued disparity and integer-valued disparity respectively)can also be integrated into our framework, which means two independent algorithms can be seamlessly merged to efficiently address the problem of large label spaces while maintaining or even improving the solution quality.
Our obvious differences and contributions include:
-Two independent algorithms(hybrid tree cost aggregation and PatchMatch stereo)can be seamlessly merged to achieve MVS matching applications while maintaining or even improving the solution quality.
-An initial one-pixel level disparity map is generated by hybrid tree cost aggregation to constrain the label searching range of Patch-Match stereo algorithm.The map not only significantly accelerates the estimation speed of PatchMatch but also improves the accuracy of disparity from one-pixel-to sub-pixel-level accuracy.
-Instead of stepping through large label space for similarity computation, an effective quantizing acceleration strategy is proposed by generating a linear interpolation of matching cost between the two closest disparity values to yield high efficiency in cost computation.
-Empirical experiments on Middlebury and KITTI benchmark evaluation show that our algorithm not only provides faster and higher or competitively accurate disparity results than both original binoculars[11, 12]but is also suitable for multiple-view reconstruction.

2 Proposed Method
In this section, we will further explain our method for disparity information acquisition from calibrated stereo image pair or multiple views.Our goal is to obtain a dense and high-quality disparity map while considering accuracy and efficiency.
According to the computation principle of the original Patch-Match stereoalgorithm[12], individual 3-D slant plane at each pixel is used to overcome bias problems during reconstructing fronto-parallel surfaces and extended to find an approximate nearest neighbor among all possible planes.These conditions help this method achieve remarkable disparity details with sub-pixel precision.However, the random initialization process may be inappropriate for a real scene, which is very likely to have at least one good guess for each disparity plane in the image.This observation is often false, especially for middle-or low-resolution images, in which each 3-D plane contains a small number of pixels, thereby indicating insufficient guesses.Furthermore, calculating the final disparity of each pixel with an iterative searching way from the random initialization is time consuming.
In the framework of our proposed algorithm as shown in the Fig.1, pixels from stereo image pairs are ranged into super-pixel regions.Then an initial pixel level disparity is generated by recent advanced hybrid tree cost aggregation algorithm[12].Furthermore, a novel iterative plane refinement strategy inspired by PatchMatch algorithm[11]is applied, where the label searching range and normal vector are both constrained with initial disparity values, to calculate the final sub-pixel level disparity.During the computation of PatchMatch, a quantizing acceleration strategy for continuous disparity cost computation is also proposed to significantly improve the algorithm efficiency by reducing the label number in sub-pixel level disparity estimation.We will deeply explain each core process in Algorithm 1.
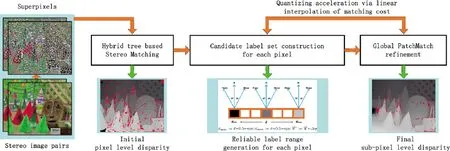
Fig.1 Overall framework of the proposed method.
2.1 Initial Disparity Set from Hybrid Tree
Given a pair of imagesI0andI1, we denoteI0(p)to be the intensity of pixelpin imageI0and denoteI1(pd)to be the intensity of pixelpdin imageI1.For stereo matching,pdcan be easily computed aspd=p-(d, 0), withdbeing the corresponding disparity value.For multiple-view matching,pdis represented aspd=H*[px,py,d]T, where the homographyHbetween imagesI0andI1should be computed through their camera-intrinsic and external parameters.We will provide more details to calculate homography.
With a set of images from different multiple views, selecting a suitable reference image from the input image set is necessary to form a stereo pair for further disparity estimation.We utilize a method similar to[24]to select eligible stereo pairs to obtain a good reference image with similar viewing direction as the target image and avoid extremely short or long baseline.Based on the assumption that the camera parameters of the image pair are {Ki,Ri,Ti} and {Kj,Rj,Tj}, theKiandKjare the two camera-intrinsic parameters[25], whereasRandTare the camera rotation and translation parameters relative to the world coordinate system, respectively.Then, the resulting induced homography is:
Hij=Kj[RiRj-1+(Ti-RiRj-1Tj)]Ki-1
(1)
We calculate the pixel-and region-level dissimilarity cost for the hybrid tree cost aggregation[11].A 3-D structure cost volume[25]is defined asD(x,y,d), wherexandyare the current pixel coordinates, anddis the user-given disparity level to store the matching costs between input images at each discrete integer-valued disparity level.The pixel-level matching costCd(p)is defined as the dissimilarity between pixelpand pixelpd, which is given by the linear combination of the color dissimilarity and the gradient difference:
Cd(p)=(1-α)min(‖I0(p)-I1(pd)‖,τ1)+
αmin(‖I0(p)-I1(pd),τ2‖)
(2)
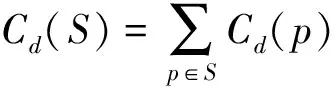
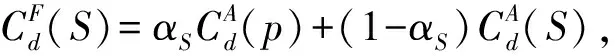
2.2 PatchMatch with label Constraints
Although we have obtained the optimal initial disparity value set, we still cannot treat them as the final results.All the processing that was previously mentioned aim to obtain a label(disparity and normal)guessing range to serve the global PatchMatch label refinement method that will be explained in this section.The goal of this part is to refine the disparity results to further reduce the matching cost.
For each pixelpof the image pair, we hope to find a planefp, which is one of the minimum aggregated matching costs among all possible planes in the reliable range:
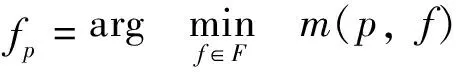
(3)
whereFdenotes the candidate set of all planes for each pixelpand is defined based on the preceding reliable disparity and normal values mentioned.We use theα-expansion algorithm[27]for the whole label optimization.
In traditional PatchMatch stereo algorithm[12], we have to calculate the pixel-matching aggregation costs according to planefas
(4)
whereωpix(p,q)=e-(|I(p)-I(q)|)/γis an adaptive weight function, which is used to solve the edge-fattening problem and is computed by pixelpandqcolor difference.The dissimilarity functionρ(p,q)is defined similar to Equation 6.Based on any given planef, we can calculate the corresponding disparity in sub-pixel precision for the current pixel as
dp=afpx+bfpy+cf
(5)
whereaf,bfandcfare the three parameters of planef,pxandpy, respectively, which are denoted as the coordinates of pixelp.Notably, this continuous and varied label space prevents rapid checking of all possible labels in the label refinement process because one would perform matching cost computation for each continuous disparity in brute force.In the next section, we will further provide an effective quantizing acceleration strategy for matching cost computation of each continuous disparity.
2.3 Quantizing Acceleration
Labels often correspond to the integer-valued disparity in standard stereo matching.Therefore, WTA[7]can be easily used to find the true minimum cost and obtain the optimal initial integer-valued disparity for each pixel.However, the label number will become infinite for disparity estimation in sub-pixel accuracy, such as PatchMatch stereo.Stepping through large label space for continuous disparity setting is difficult and will further bring numerous matching cost calculations in each label optimization process.
Based on the preceding analyses, we innovatively discretized the continuous disparity into a number of values and computed a linear filter for each value.Then, the final output is a linear interpolation of matching cost between the two closest disparity values.In practice, the disparity value for each pixel is discretized withD= {1, 2, …,Lk,Lk+1,…,LN}, whereLNis the maximum value of disparity.Given the disparityd∈[Lk,Lk+1]of pixelp, the dissimilarity functionρ(p,p-d)in Equation 4 can be expressed as:
ρ(p,p-d)=(Lk+1-d)ρ(p,p-Lk)+
(d-Lk)ρ(p,p-Lk+1)
(6)
Instead of directly computing the matching cost for continuous disparity d, we show that quantization can be easily implemented and computing performance improvement can be achieved(5~6 times faster on average)with the same output accuracy because the cost volume on the discretized disparity setDcan be pre-computed only once with constant time.
3 Experiments and Evaluation
All the experiments are implemented on a PC platform with an Intel i7 3.60 GHz CPU, 16 GB memory, and an NVIDIA GeForce GTX 980 GPU.We use the same parameters as the original PatchMatch stereo matching algorithm[12]and hybrid tree algorithm[11], which are {γ,α,τcol,τgrad} = {10, 0.9, 10, 2}, with a large patch size of 51 pixels.
The post-refinement strategy is often used to conceal the disparity estimation errors after stereo matching computation.We tested our algorithm without any post-refinement for disparity with two utilized stereo matching methods(HybridTree and PatchMatch)and six related main stream methods[30-35]on the second and third version of Middlebury[7, 28]benchmark, and KITTI dataset[29]to completely reflect the real performance of each algorithm.We compare all the disparity results from each stereo matching methods with corresponding ground-truth disparity values provided by the Middlebury and KITTI benchmark under a given threshold.If the estimation deviation of the current pixel is greater than the threshold, then it will be considered as an error pixel and marked with red(please see Fig.2~Fig.5).This condition will more vividly express the quality of disparity estimation.It is worth noting that KITTI dataset are mostly utilize to evaluate unmanned driving algorithms, in which the images are mainly complex real urban traffic scenes with ground truth obtained by depth sensors.Therefore, testing on such data is not only a great challenge, but also can prove the robustness of the algorithm in practical applications.

Fig.2 Visual comparison with other methods for disparity results on 3nd Middlebury benchmark(the red color represents the pixel with the error disparity estimation).From left to right, they are orginal stereo image pair, HybridTree results[11], PatchMatch Results[12] and Our Method Results.As can be seen from(b)and(c), there are obvious error estimates in the areas with low texture and complex edges(such as floor and background).Our method has less error pixels than the first two algorithms.

Fig.3 Visual comparison with other methods for disparity results on 2nd Middlebury benchmark(the red color represents the pixel with the error disparity estimation).As can be seen from(b)and(c), there are obvious error estimates in the areas with duplicate textures and unclear edges(such as fences and face masks).Our method has better accuracy in dealing with the above areas.

Fig.4 Visual comparison with other methods for disparity results of street scene on KITTI Benchmark(error threshold is three-pixel).From left to right, they are orginal stereo image pair, HybridTree results[11](error rate: 14.58%), PatchMatch Results[12](error rate: 9.21%)and Our Method Results(error rate: 9.36%).

Fig.5 Visual comparison with other methods for disparity results of buildings scene on KITTI benchmark(error threshold is three-pixel).From left to right, they are orginal stereo image pair, HybridTree results[11](error rate: 17.58%), PatchMatch Results [12](error rate: 17.38%)and Our Method Results(error rate:12.26%).
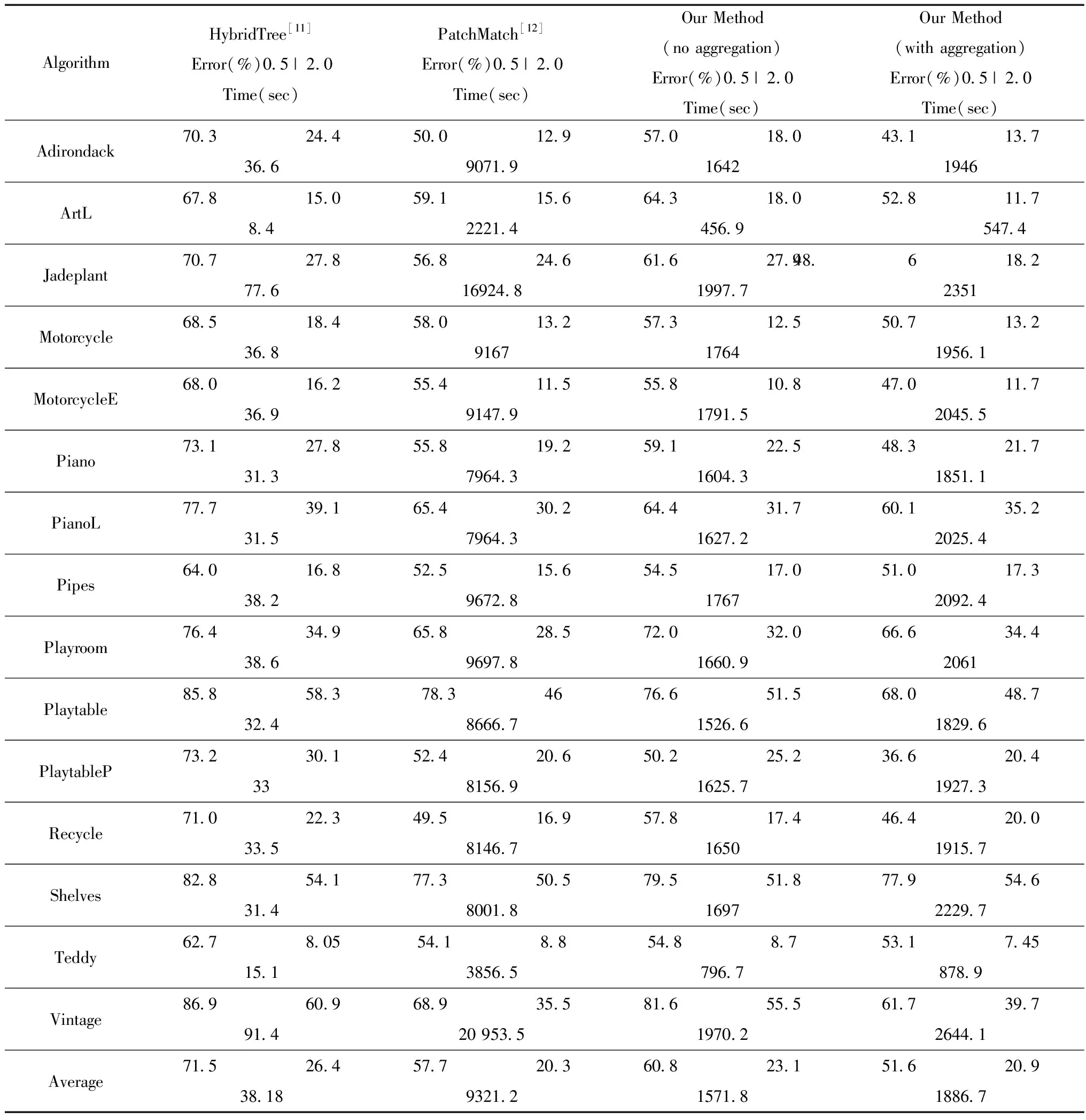
Table 1 Performance Evaluation of 3rd Middlebury Benchmark
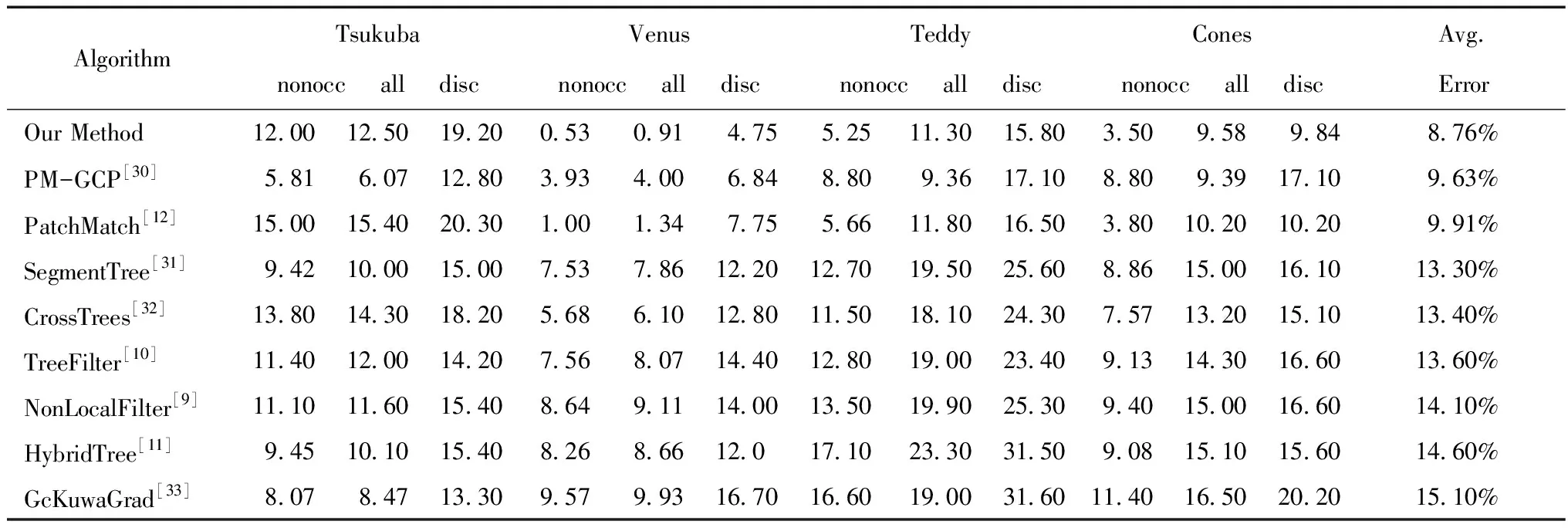
Table 2 Evaluation of 2nd Middlebury Benchmark in sub-pixel accuracy
In Table 1, we mainly illustrate that our integration strategy has certain advantages in operating efficiency while ensuring high accuracy disparity estimation, especially for stereo matching of large-scale and high-resolution images.Since our method is derived from the fusion of the hybrid tree and patch matching, So we compared the above two constituent algorithms with ours inaccuracy and time complexity evaluation of the 3rd Middlebury benchmark, which proves that our strategy does not sacrifice operating efficiency to improve the estimation accuracy.As we can see in Table 1, disparity results(our method with cost aggregation or not)are of two kinds, which are used to indicate the advantages of the cost aggregation.The results clearly show that the proposed method seamlessly merges two independent algorithms(hybrid tree cost aggregation and PatchMatch-based label search)to efficiently address the problem of large label spaces while maintaining or even improving the solution quality.Our method clearly achieved higher comprehensive performance compared with those of the two other methods[11, 12].
In Table 2, sub-pixel accuracy evaluation between the 8 mainstream algorithms and ours are provided with the second Middlebury benchmark.Because they all borrowed the strategy of patch matching and tree flitering in the calculation cost aggregation stage, they have a certain degree of comparability with our algorithm.Notably, “Tsukuba” in the benchmark should be omitted because its ground truth is quantized to integer values, which is unsuitable for sub-pixel comparisons.The average error rates of the three remaining views are PatchMatch(7.58%)versus our method(6.83%), and these rates are considered to be significant improvements in average error rates compared with that of the PatchMatch based methods.Comprehensively considering the disparity estimation results of all images, our method also has the lowest average error rate compared with the other 8 results, which shows that our method can provide a higher-precision estimation.
Finally, we also implemented our method in MVS application to prove the practicability of our algorithm.Figure 6 and Figure 7 provides our depth estimation results(without any post-refinement for depth)from images of realistic complex scenes(“statue” and “tree”).Reconstructing statue and tree in a realistic way is difficult because of the non-uniform color distribution of statue and the inherent geometric complexity of trees.We use the proposed method for statue and tree reconstruction, which can prove that this approach has good potential for multiple-view reconstruction in real scenes.

Fig.6 Our estimated multi-views depth results from statue images.Row 1 and row 3 are the input images captured from four different view points.Row 2 and row 4 are the related depth results.

Fig.7 Our estimated multi-views depth results from tree images.Row 1 and row 3 are the input images captured from four different viewpoints.Row 2 and row 4 are the related depth results.
4 Conclusion
In this paper, we presented a hybrid tree-guided PatchMatch and quantizing acceleration algorithm for stereo.In our method, hybrid tree cost aggregation and PatchMatch label search complemented with each other.The disparity searching range began with the integer-level disparity of hybrid tree cost aggregation and was then refined by a PatchMatch optimizer to enhance the accuracy.The experiments show that our approach is more robust, accurate and faster in disparity estimation than the two other comparison methods.In the future, we can integrate our algorithm into more global PatchMatch methods, including PMBP[15]and PM-Huber[14].
