大范围地景图像语义分割与处理方法研究
2021-06-17龚光红
王 丹,龚光红,李 妮,李 莹
(北京航空航天大学 自动化科学与电气工程学院,北京 100191)
0 引言
大范围地景图像的三维重建一直是虚拟现实的重要研究内容之一,快速、准确地识别地景图像中所包含的地物并对其进行分类处理,可以为后续的模型重建及时提供准确的数据,而现有的地物分类和处理方法则存在准确性低、速度慢等问题。随着倾斜摄影等技术的发展,获得更高分辨率的地景影像成为可能,对快速提取地景图像中所包含的地物,并对其进行高效处理提出了新的要求。
语义分割技术是指给定一张照片,计算机可以识别出照片中所包含的物体实例的种类及位置[2]。现阶段广泛使用的语义分割技术,主要是在FCN[5](Fully Convolutional Networks for Semantic Segmentation,全卷积神经网络)等经典网络的架构上进行改进,从而实现对于图像中包含物体的识别与分类。随着机器视觉、目标检测等技术的不断发展,图像的语义分割技术逐渐应用于无人自动驾驶、临床医疗影像分析等领域,可有效作用于情景理解和多目标间关系推断。同时,随着地理测绘、倾斜摄影等技术的发展,获得分辨率更高的地景图像成为可能,航空倾斜摄影可以在短时间内获得高精度、大数据量的目标区域图像集,对更加高效、快速地建立高精度地物模型[3]提出了新的要求。将语义分割技术应用于高分辨率的地景图像[4],可以对地景图像中所包含的地物进行快速识别和分类,从而服务于后续的地物模型处理与重建。
实际的仿真环境或三维模型搭建中,需要对分割出的地物进行移除、损伤、替换处理,并对处理后的地面纹理进行补充,以达到逼真的效果;而部分倾斜摄影采集的原始地景图像中存在移动的车辆以及妨碍观测和建模的障碍物等,不仅在后续的三维模型中并不需要,甚至会对仿真进程进行干扰。因此,对于分割后冗余地物的移除、替换处理,是地景图像应用于三维模型重建的必要处理环节。
本文旨在基于deeplab-v3+神经网络对地景图像进行语义分割,使用自制的倾斜摄影低空航拍图数据集对预先搭建的deeplab-v3+网络进行训练、测试,然后将训练完成的网络应用于高分辨率地景图像的语义分割,以识别建筑、植被、道路、水域、车辆、背景6类地物。完成地景图像语义分割后,根据不同地物类别的分割结果,对妨碍观测和建模的车辆等地物进行移除、替换处理,并通过图像融合对移除、替换后的地面纹理进行补充,消除冗余地物对后续建模的干扰,从而为后续的三维场景重建等应用快速提供准确数据。
1 地景图像语义分割
地景图像语义分割流程如图1所示,主要包括倾斜摄影数据集制作、语义分割网络搭建、训练与调整,使用训练完成的网络对地景图像进行分割三部分,主要内容为:
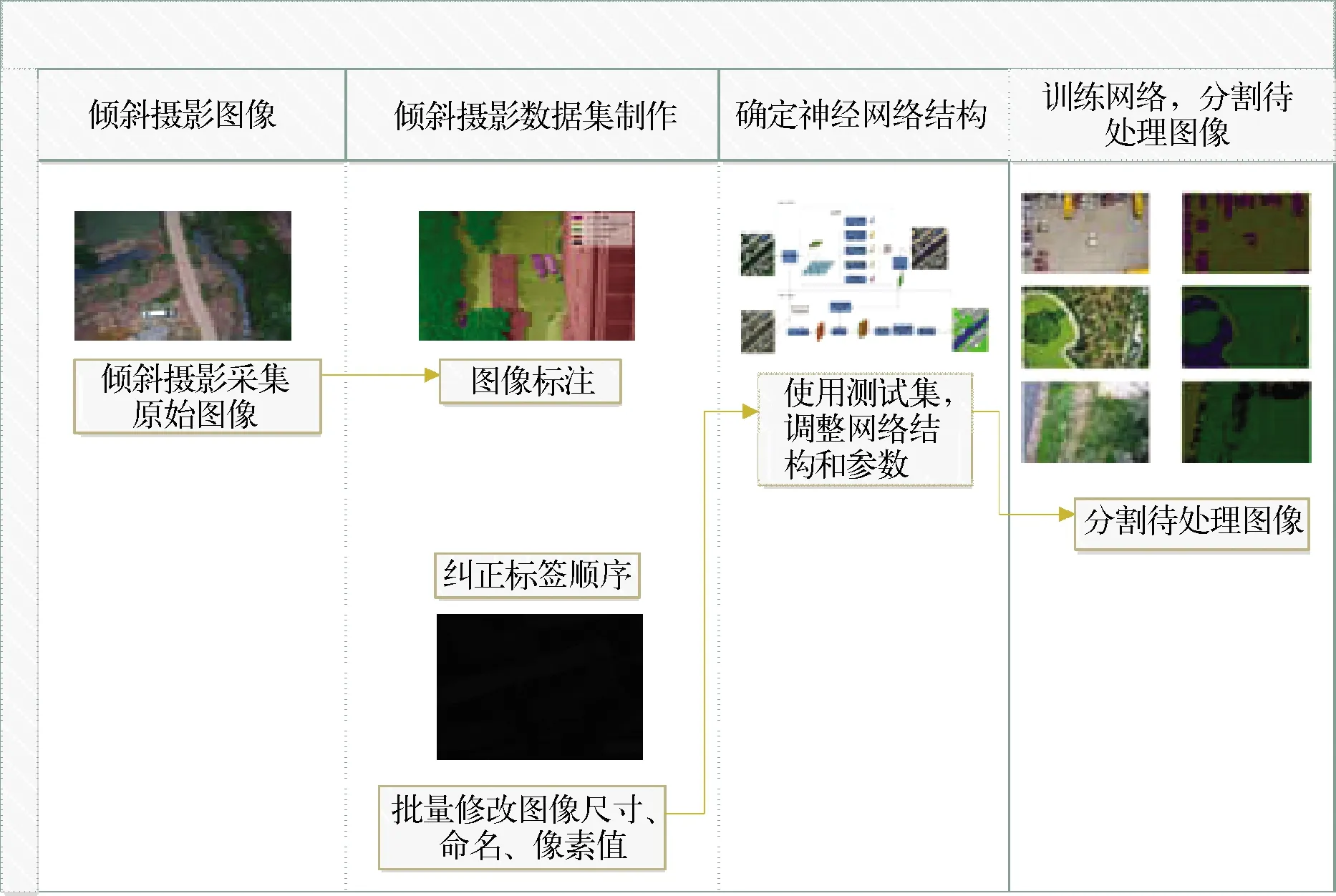
图1 地景图像语义分割处理流程
1)对倾斜摄影采集的低空航拍图进行预处理,包含数据提取、地物标注、纠正部分图像的标注乱序问题、批量更改图像像素及尺寸等,使之适合神经网络的训练;
2)搭建语义分割所使用的神经网络结构,本文选取deeplab-v3+神经网络应用于语义训练与分割,使用经过预处理的倾斜摄影数据集对神经网络进行训练,根据训练效果对网络做出调整与改进,使之更加适用于地景图像的分割,确定神经网络结构;
3)使用训练完毕的神经网络对需要处理的地景图像进行语义分割。
1.1 倾斜摄影数据集制作
无人机搭载倾斜摄影相机拍摄的低空航拍图具有独特的视角和空间结构,要对其实现精确语义分割,需训练适用于这类图像特征的神经网络。
第一,对采集的覆盖不同区域及地物的1946张地景航拍图进行处理,制作语义分割数据集,以应用于后续训练,对采集的原始图像进行处理的流程如图2所示。
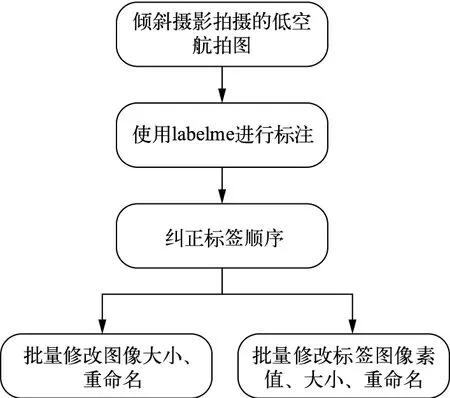
图2 倾斜摄影数据集制作流程
第二,使用labelme对航拍图数据集进行标注。labelme是一个可以手动对图像进行标注的图形界面,由python语言编写,可对地景图像进行点、线段、圆形以及多边形的标注,以应用于图像分割、目标检测等任务。按照背景、建筑、植被、道路、水域、车辆6类地物对地景图片进行标注,并将生成的json文件转化为标签图像,即可获得与原图相对应的标签数据。
第三,由于部分图片中不是完整地含有所有类别的地物,例如,有的航拍图中不含水域,仅包含其他五种地物,而受到labelme软件本身的限制,其进行标注的颜色是按照标注顺序给定的,如此就会产生标注图像中同一类别的地物出现不同的标签颜色的问题。乱序的地物标注会对后续的训练造成干扰,因此需要使用编程统一调整标签顺序,实现标注图像的一致,正确的标注顺序如表1所示。
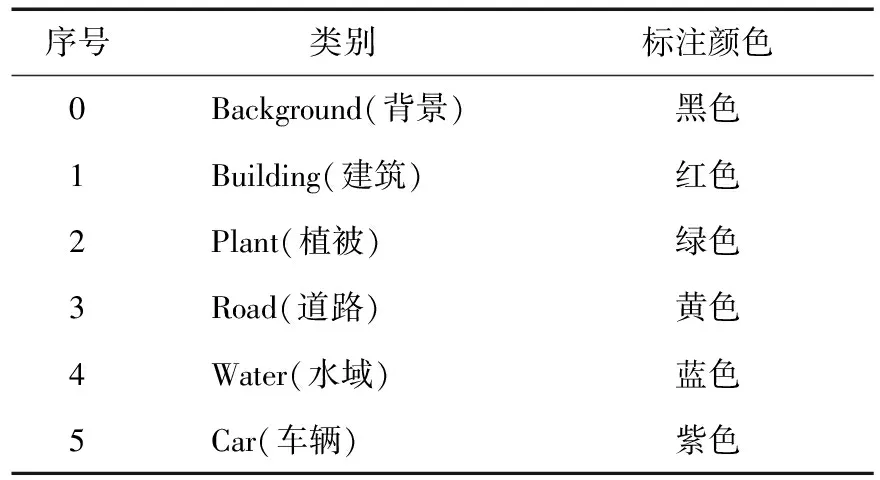
表1 航拍图标注正确顺序
第四,通过编程对标注所生成的json文件进行批量操作,对图像中地物的标签进行遍历,判断其含有的地物类型是否与标签顺序一致,并按照表1中的设定顺序修改乱序地物的标签值,然后将json文件转化为标注图像,对1946份标签文件进行批量处理,可以重新生成包含正确标签顺序的json文件和标注图像,修改后的航拍图标注结果如图3所示。其中,(a)图为原始倾斜摄影图像;(b)图为在原始图像上进行标注的效果,右下角为各个颜色的标签所代表的实际地物种类;(c)图为导出的标注图像。之后即可将该数据集应用于地景图像语义分割网络训练。

图3 倾斜摄影数据集标注结果
第五,航拍图数据集的标注顺序统一后,将航拍图与标注图片的尺寸统一修改为512×512,并按照顺序重命名,减小计算量,方便后续训练;同时,将标注图片的不同类别地物像素修改为0~5,提高后续神经网络的训练速度,修改图像尺寸、像素值的示例如图4所示。完成上述对于低空航拍图的预处理流程后,即可使用该倾斜摄影数据集进行后续语义分割模型的训练。
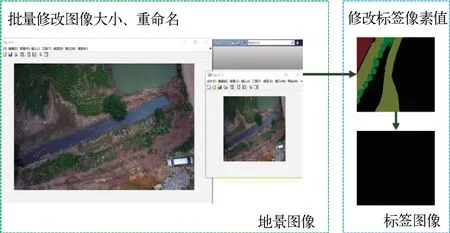
图4 批量修改图像尺寸、像素值
1.2 语义分割网络搭建、训练与测试
Deeplab-v3+[6]是基于DCNN(Deep Convolutional Neural Network, 深度卷积神经网络)进行改进而形成的神经网络结构。DCNN主要包括输入层、输出层、卷积层、池化层、全连接层等结构,可以应用于图像实例的分类并取得较好的效果。deeplab-v3+在DCNN的基础上进行了改进,结合了概率图模型(DenseCRFs),取消了池化层和全连接层,使图像在一系列卷积层中进行传递,以提升语义分割效果。然而,如此改进之后,会使得模型的内存消耗增大、计算复杂度增加,为了解决这个问题,deeplab-v3+将处理过程分为下采样、卷积、上采样三个步骤,以减小计算复杂度。Deeplab-v3+对航拍图进行语义分割的处理流程如图5所示。
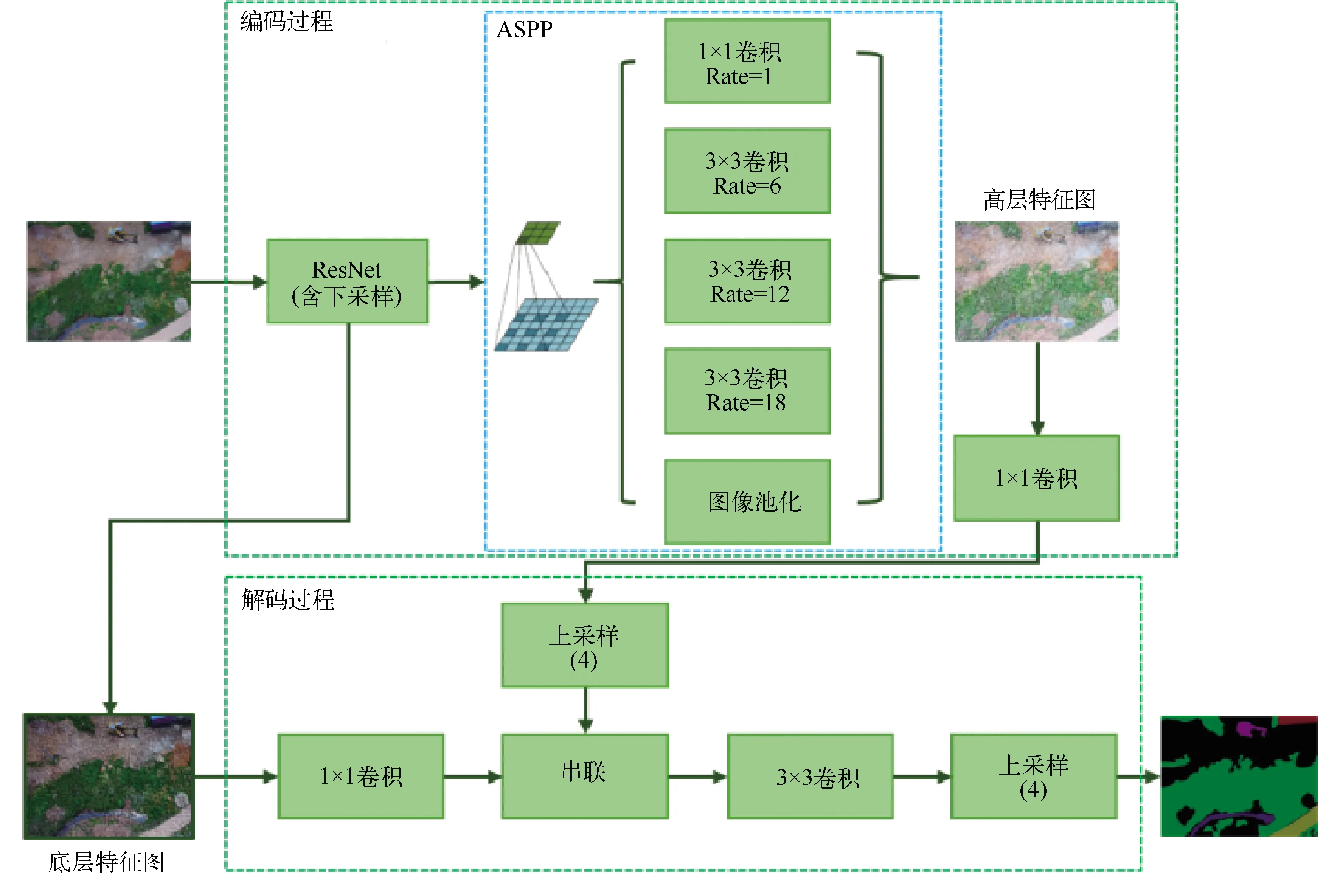
图5 基于deeplab-v3+模型的倾斜摄影图像分割系统框
图5中,deeplab-v3+网络首先对输入的图像进行编码操作,使用ResNet[7]网络提取输入图像的特征信息;然后通过ASPP[8]模块在多比率、多有效视野上提取输入航拍图的特征信息,并通过池化操作编码多尺度上下文信息。由于航拍图的图像状态和独特的空间结构,导致其识别精度较低,而ASPP模块的特点在于同时使用多个维度的滤波器对地景图像进行过滤,这些滤波器可以对彼此的有效视野范围进行补充。因此,可以提供多尺度的有效特征信息,从而更准确地捕捉地物特征。将经ASPP模块处理后输出的高层图像特征信息与底层特征进行串联,对串联后信息进行卷积;最后进行上采样,逐步恢复空间信息,以更加精细地分割地物边界。
在服务器上搭建基于Pytorch的deeplab-v3+神经网络,主要包括上文所介绍的网络的基本架构、用到的编程语言包、使用的数据集和一些相应的可视化辅助模块。根据航拍图的拍摄角度、空间结构特点选择合适的backbone,配置好环境变量和相应模块,采用官方数据集进行测试,确保神经网络可以进行正常训练。
在实际训练中选用DRN[9](Dilated Residual Networks)作为航拍图分割的backbone,以改善网络对地景航拍图的分割效果。DRN在ResNet的基础上进行改进,在其top layers中移除了下采样层,同时引入了多孔卷积。多孔卷积指按照指定的扩张率对原滤波器插入空洞进行扩张,通过插入0值来实现这一目的,以建立对应的稀疏滤波器。插入的0值不会参与后续运算,因此不会提高计算复杂度。使用扩张后的滤波器来进行卷积,既可以保持特征图的空间分辨率,也不会影响后续层接受野的分辨率。
神经网络的训练主要以mIoU、FWIoU和训练过程的损失来对语义分割的精度进行衡量。mIoU[10](mean Intersection over Union)是两个集合之间的运算,取交集和并集比值的平均值,简称为均交并比。在地景图像语义分割测试中,此比值是在建筑、湖泊等每个地物种类上计算其真实值(ground truth)和判断值(predicted segmentation)的交并比,然后对计算的结果求取均值得到。mIoU凭借其直观的代表性和简便的计算方式成为语义分割领域应用最为广泛的度量标准之一,绝大多数进行语义分割试验的研究者都会使用mIoU来验证其分割结果,mIoU的计算公式如下所示:
(1.1)
除了mIoU外,FWIoU[10](Frequency Weighted Intersection over Union,频权交并比)也经常被用于衡量图像语义分割的效果,FWIoU是mIoU的一种提升,其会根据每个类别出现的频率为每个类设置权重,计算公式如下:
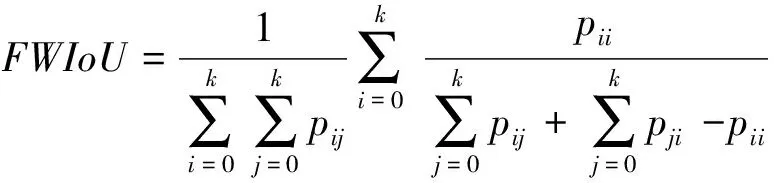
(1.2)
选定语义分割效果衡量指标后,对训练所使用的数据集进行定义,训练使用1946张倾斜摄影图像进行,选用其中的1848张照片进行训练,98张照片用于测试,分割类别为6类,分别为背景、建筑、植被、水域、道路、车辆。根据选用的backbone和定义的数据集,对训练和测试代码进行编写。
设置网络选用的backbone为DRN,自定义数据集和训练方式后,首先使用数据集中的少量样本对语义分割网络进行测试,由测试结果调整、改进网络结构,确认无误后再将全部数据集用于训练。采用4个GPU并行,执行100次epoch,初始学习率lr=0.007,batch size设置为4。训练中采用测试集衡量训练结果,每训练一次对训练指标进行一次计算。使用Tensorboard实现对于训练过程的可视化,训练过程如图6所示。
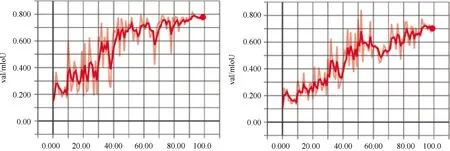
图6 使用倾斜摄影数据集对deeplab-v3+网络进行训练
为了得到更好的训练效果,设定不同的网络架构和训练参数进行多次训练,最终得到的结果如表2所示。

表2 航拍图训练结果
由表2可见,当采用ResNet作为网络的backbone时,最终在测试集上达到了74.34%的mIoU,而改用DRN作为网络的backbone时,分割精度得到进一步提升,相同的参数设置下mIoU提升至84.14%。为了进一步加快训练速度,同时不影响训练精度,将Epoch修改为150,Batch_size修改为4,最终在测试集上达到了mIoU为85.13%的训练精度,训练速度也得到了提升。
1.3 使用神经网络分割地景图像
选择倾斜摄影图像训练过程中表现最好的一组网络,取该网络表现最好的一组权重作为最终的地景语义分割网络,此时mIoU=85.13%,为后续的地物模型处理方法研究和三维场景重建等应用提供语义分割数据。使用该网络对需处理的地景图像进行语义分割,并对分割出的图片进行着色,以应用于后续的地物模型处理,分割效果如图7所示。

图7 使用神经网络模型分割地景图像
2 移除冗余地物并补充纹理
在实际的三维建模等应用场合中,一方面,部分地物模型例如地面障碍物等并不需要出现,而在拍摄过程中连续移动的车辆,还会对后续的建模环节造成干扰;另一方面,在战场环境仿真等应用中,需要根据仿真进程对某些地物进行移除、损伤、替换等处理。将这些对于模型重建不发挥作用、甚至会造成干扰的地物称为冗余地物。对语义分割所识别出的部分冗余地物进行移除,并对移除后的地面纹理进行补充,可以解决以上两方面的问题,在实际的工程应用中有较高价值。以车辆为例,对其进行移除及地面纹理补充的操作流程如图8所示。
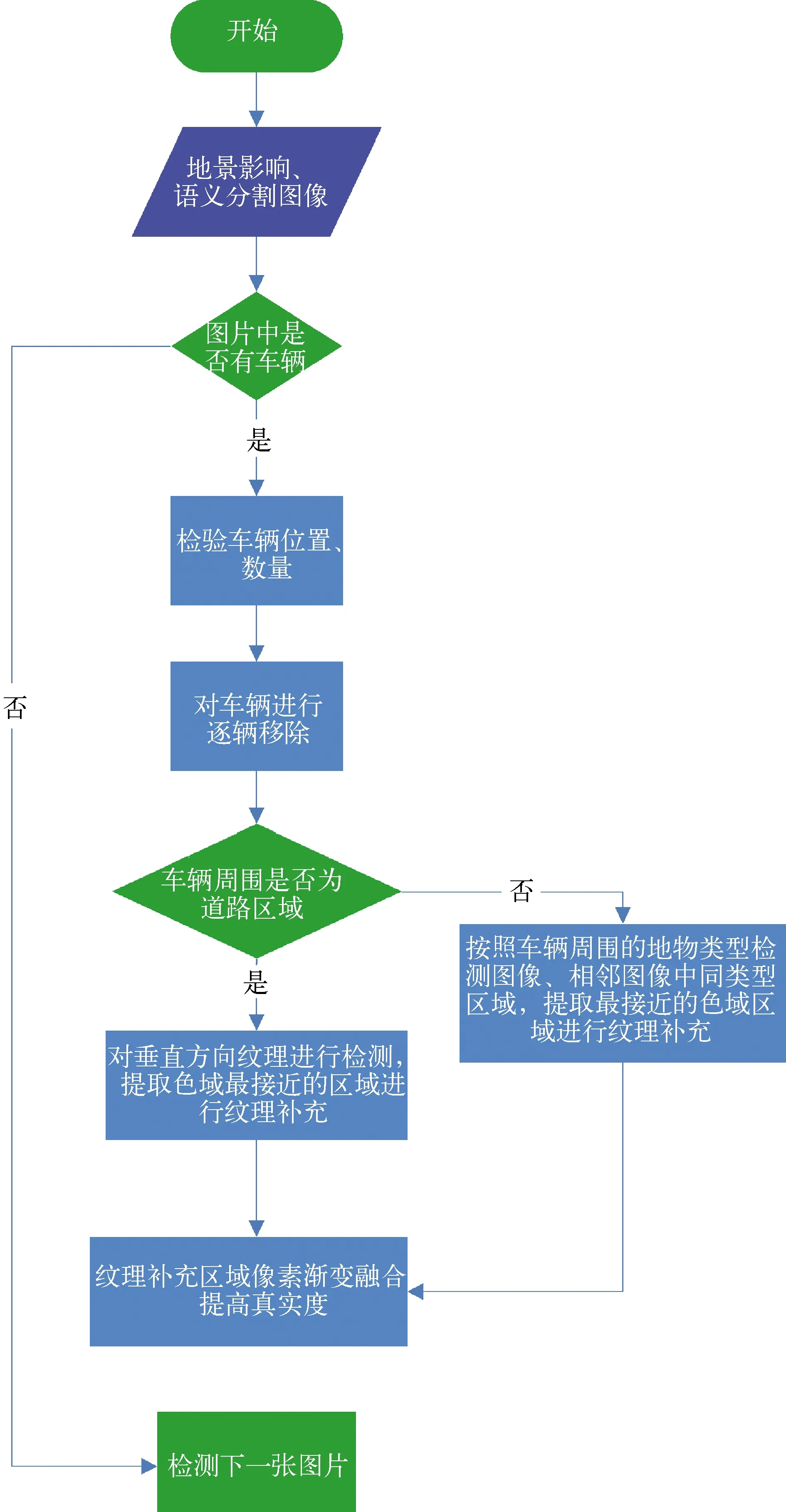
图8 移除冗余地物并补充地面纹理流程图
对于地景图像和其进行地物分割后的图片,首先通过语义分割图像检测其是否存在车辆,对于存在车辆的图像,检测其含有的车辆数量和位置,采取逐辆移除的方式进行处理。以图9为例,地景图像中含有一辆车辆,并对其所在矩形区域进行了标识。

图9 含车辆的地景图像及其语义分割图像
对于图像中存在的车辆,采取逐辆移除的方式,移除处理的重点在于地面纹理的补充,真实的地面纹理是应用于模型重建、环境仿真的基础。首先,对标定的车辆区域进行一定比例的放大,防止纹理无法完全补充而造成视觉漏洞;然后,对移除车辆周围的地物类型进行检测,按照车辆周围地物的不同类型采取不同的纹理贴图方式。若车辆周围为道路,即语义分割显示的黄色区域,则选取车辆垂直方向的纹理进行补充,以最大限度地保证道路上斑马线、行车标识的真实性。在车辆区域所在的垂直方向对地面色域进行检测,选取与移除区域色域最为接近的部分作为补充纹理,将其贴图至车辆区域。
为了提高真实度,对车辆区域进行地面纹理贴图后,使用图像融合方法对选取的补充区域和车辆移除区域进行融合。通过像素级别的图像融合方法来实现这一目的,在包含车辆的矩形区域四边进行融合操作,将地景图像中原车辆区域图像和补充区域图像分别按照颜色通道进行像素融合,以达到观测真实的目的。处理后地面图像无明显纹理贴图痕迹,实现了较为真实的效果。通过图像融合完成对地景图像中车辆移除和地面纹理的补充,对周围环境为道路的地景图像移除效果如图10所示。

图10 移除车辆前后的地景图像
若车辆所在位置的周围区域不是道路,则地面纹理的补充变得更加复杂,此时不可仅考虑垂直方向的地面纹理进行补充。首先,对车辆周围的地物类别进行检测,以图11为例,车辆周围的区域为背景,即非道路、植被之外的其他区域,则对车辆的位置区域按照比例进行放大之后,进一步在原地景图片和相邻的地景图片中的同属性区域检测色域信息,获取与待填充区域色域最为接近的地面纹理,使用其对车辆移除区域进行补充。

图11 含车辆的非道路区域地景图像及其语义分割影像
对于车辆周围非道路的地景图片,要达到较为真实的纹理补充效果,仍然需要对原地景图像移除车辆区域和补充区域进行图像融合,区别于道路的图像融合是规则的由矩形区域的四边渐变融合,非道路区域需要进行不规则多边形融合以尽可能达到真实的地面纹理补充效果。移除之后的效果,如图12所示,可见非道路区域亦可达到相对真实的纹理补充效果。

图12 移除车辆前后的非道路区域地景图像
3 结果展示
为了验证地景图像语义分割以及冗余地物移除方法的效果,对通过倾斜摄影采集的大区域地景图像进行处理,选用对面积为450×400 m2的某住宅区进行倾斜摄影图像采集得到的图像集进行处理,区域内覆盖了建筑、植被、水域、道路、车辆等地物,如图13所示。
使用训练完成的语义分割网络对地景图像进行分割,效果如图14所示。

图14 语义分割效果图
完成图像的语义分割后即可对其所包含的地物进行进一步处理,对场景中妨碍观测和建模的车辆等障碍物进行移除,并对移除后的地面纹理进行补充,以消除不必要的地物对后续三维模型重建造成的影响,移除的效果如图15所示。

图15 移除冗余地物并对地面纹理进行补充
完成语义分割与冗余地物移除的处理后,生成地景图像所对应的正射影像,以便为其配准坐标,矫正图像的拍摄视角。正射影像可以从垂直角度复现大区域场景的俯拍视图,对于后续向实际坐标系的转换和三维模型的建立有重要的过渡作用,其效果如图16、图17所示。可见,语义分割对场景中所包含的地物实现了精确的识别,根据识别结果对主干道路上的车辆以及妨碍观测的地物等进行了移除,达到了相对真实的效果。

图16 大区域地景的正射影像
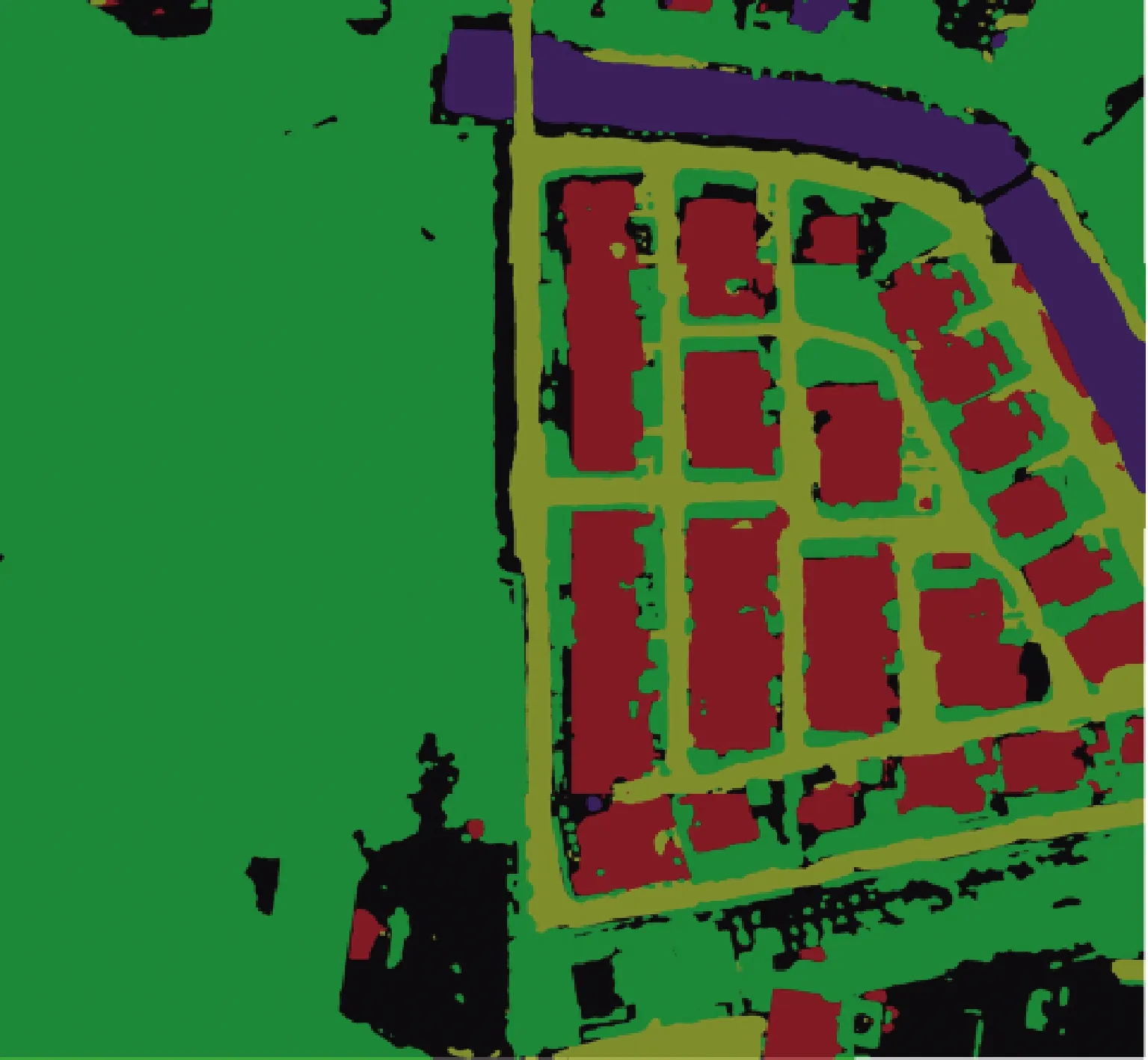
图17 大区域地景的语义分割图像
4 结论
本文研究了利用神经网络对大区域高分辨率地景图像进行语义分割,并对分割后图像中包含的冗余地物进行移除、替换处理,从而实现对地景图像所包含地物快速、精确地识别和处理,为后续模型重建等提供准确数据。通过搭建deeplab-v3+神经网络,使用自制的倾斜摄影数据集进行训练,获得mIoU为85.13%的地景图像语义分割网络,可识别建筑、植被、道路、水域、车辆、背景6种地物;根据语义分割结果,对仿真场景中需进行损伤、替换处理或干扰建模、观测的地物进行移除,并采用图像融合方式对地面纹理进行补充,为后续的三维场景重建提供准确、有效数据。
