一种高性能超长点数浮点FFT加速器设计
2021-06-17吴铁彬谭弘兵郝子宇李宏亮
王 谛 石 嵩 吴铁彬 刘 亮 谭弘兵 郝子宇 过 锋 李宏亮
(江南计算技术研究所 江苏无锡 214083)
(wangdi_csarch@126.com)
离散傅里叶变换(discrete Fourier transform,DFT)作为时域和频域转换的基本运算,在数字信号处理中占据核心地位[1],应用领域十分广泛.快速傅里叶变换[2](fast Fourier transform,FFT)是DFT的快速算法,FFT的提出促进了数字信号处理的发展,被评选为20世纪科学和工程界最具影响力的十大算法之一[3].随着高速采样和实时信号处理技术的发展,高性能超长点数FFT的需求迅速增长[4].由于FFT的算法复杂度为O(NlgN),FFT和以FFT为基础的各类时-频变换算法的计算占比愈发凸显.例如,在国际大科学工程——平方公里阵列(square kilometer array,SKA)射电望远镜项目中,FFT的计算占比达40%[5].目前已有FFT计算架构的最大吞吐率能达到100 GS/s量级[6],并且吞吐率需求以指数级速度增长,大概每5年增长10倍[7].
数十年来发展出数字信号处理器(digital signal processor,DSP)、现场可编程门阵列(field programmable gate array,FPGA)和专用集成电路(application specific integrated circuit,ASIC)等多种数字信号处理平台.DSP具有强大的运算能力和良好的可编程性,在满足性能需求的条件下,DSP是构建数字信号处理系统的首选器件.但受到指令串行执行和处理器寻址模式的限制,传统DSP的FFT运算能力低于FPGA和ASIC实现[8].
“通用核心+加速器”的结构在获得通用处理器可编程性和灵活性的同时又能提升特定应用的性能与功耗效率,是未来处理器发展的重要方向.为了提高DSP的FFT处理能力,在DSP中集成FFT加速器成为必然选择,已有大量理论研究[9]和实际产品[10]出现.现有研究成果存在2点不足:1)与DSP核心相比,FFT加速器的峰值性能没有体现出明显优势;2)对于超长点数FFT的支持能力有限.
本文针对集成于DSP的FFT加速器开展研究工作.注意到将FFT的2维分解算法推广到多维后,可以将每一维的点数控制在16个点以内,从而能用固定的小点数FFT实现几乎任意长度的FFT,本文在此基础上提出面向超长点数FFT的多维分解算法.针对FFT多维分解算法中的转置和铰链因子生成这2种核心运算开展研究,提出了素数体片上3维转置存储器结构解决访存带宽利用率低的问题,提出了铰链因子递推生成算法解决坐标旋转数字计算机(coordinate rotational digital computer,CORDIC)算法迭代计算周期长的问题.最后,对每一维处理中的小点数FFT进行了精细化电路设计.本文设计的FFT加速器能够实现最长4G点数的单精度浮点FFT计算,运行频率能够达到1 GHz以上,性能达到640 Gflop/s.在点数和性能方面都较已有研究成果取得大幅提升.
1 相关研究
经过数十年的研究,FFT算法发展了许多种类.根据运算形式的不同可以将FFT分为时间抽选(decimation in time,DIT)和频率抽选(decimation in frequency,DIF).根据基本蝶形运算单元的粒度则可以将FFT分为基2、基4、基8、基16、多基和素数基等.与此同时,大量的流水化和并行化FFT实现结构也被提出,例如阵列并行结构、单路延时置换(single-path delay commutator,SDC)结构、单路延时反馈(single-path delay feedback,SDF)结构、多路延时置换(multi-path delay commutator,MDC)结构和多通路延时反馈(multi-path delay feedback,MDF)结构等[9].
许多研究针对基本运算单元进行精细化设计.例如,采用基22算法[1],对偶序号使用基2算法,对奇序号使用基4算法,减少运算量;采用不同实现方式的乘法器[11]获得较小的开销;以CORDIC算法为基础,将复数乘法与旋转因子求值统一到一个迭代运算中[12],减少蝶形运算复杂度;通过运算过程中的动态位宽调整[13],减少资源开销和功耗;采用二项融合点积(fused dot product,FDP)运算和融合加-减(fused add-subtract,FAS)运算[14],实现高效的浮点复数运算.这些研究在小点数FFT计算中普遍取得明显的优势,然而,提升长点数FFT计算效率需要超出基本运算单元的范畴进行考虑.
对于长点数FFT,计算的中间结果无法全部存储在芯片内部.Winograd傅里叶变换算法[15](Winograd Fourier transform algorithm,WFTA)利用旋转因子特性对FFT进行分解,使用规模较小的2维FFT模拟实现规模较大的一维FFT,是一种高效且资源占用相对较少的FFT实现方法.在处理器[16-17]和FPGA[4,18]上对长点数FFT的实现普遍采用了这种2维分解算法.
长点数FFT加速器的研究大多在2维分解算法基础上进行改进.Yang等人[19]采用一种支持基2、基4、基8、基16可重构运算单元,实现FFT运算中蝶形运算单元的灵活配置,达到最佳的能效.Tang等人[20]提出一种基数灵活可配的MDF结构,适用于可变长度多路FFT.Chen等人[21]提出一种基于CORDIC算法的可重构浮点FFT加速器结构,通过旋转方向预测减少硬件开销,通过旋转角度的实时生成节省存储需求.于东等人[22]在FFT处理器中将缓存划分成32个体,通过对缓存的灵活调度实现“乒乓”操作,提高长点数FFT的运算性能.雷元武等人[9]设计了一种基于矩阵转置操作的可变长度FFT加速器结构,提出“乒乓”多体数据存储器、基于基本块的快速矩阵转置算法、结合查表和基于CORDIC算法的混合旋转因子产生策略等优化方法.在这些研究中,运算量的精简、旋转因子高效生成和提高存储访问效率始终是关注的重点.
2 算法分析
2.1 FFT算法介绍
N点序列{x0,x1,…,x n}的DFT定义为

其中,k∈[0,N-1],旋转因子
Cooley-Tukey算法[2]是目前应用最为广泛的FFT算法.根据旋转因子在计算过程中的位置分为DIT和DIF两类.
以基2 DIT算法为例进行简要说明[23].当N为偶数时,令x0,n=x2n,x1,n=x2n+1(0≤n≤N/2-1,n为整数).若X0,k=DFT(x0,n),X1,k=DFT(x1,n),(0≤k≤N/2-1,k为整数),则:

式(2)表明:若将任何一偶数点序列按n的奇偶性分成2个子序列,则原序列的DFT可由2个子序列DFT的线性组合得到.
按照式(1)直接进行N点DFT计算,需要N2次复数乘法和N(N-1)次复数加法,而采用式(2)的蝶形运算方法则只需(NlbN)/2次复数乘法和NlbN次复数加法.FFT算法极大缩减了DFT的运算量.
2.2 多维分解FFT算法
观察式(2)可以发现,每一级蝶形运算的输入数据都是上一级蝶形运算输出数据混洗的结果.而且,随着蝶形运算级数的增加,混洗的范围越来越大.这就导致,当FFT的点数长到无法在加速器内部一次性加载所有输入数据的时候,将会产生大量的非连续访存,这与半导体存储器采用并行总线方式提高带宽的机制不兼容.对于超长点数FFT运算需要找到访存连续性较好的算法.
假设N=L×M,由式(1)得:
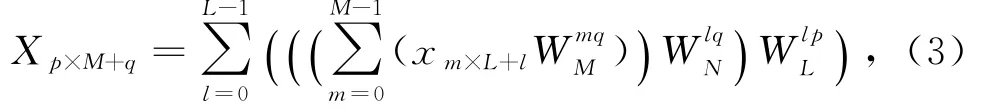
其中,p∈[0,L-1],q∈[0,M-1].
从式(3)可以看出,N点DFT分解为了2维.第1维是独立的L组M点DFT(其结果需要乘以铰链因子W lqN),第2维是独立的M组L点DFT.所以,可以将长点数FFT转化为小点数FFT的2维分解[4]:1)将N点的数据分解为L行M列的矩阵;2)对所有行分别做M点的FFT;3)将所有元素与各自的铰链因子相乘;4)进行矩阵转置,得到M行L列的矩阵;5)对所有行分别做L点的FFT;6)再次进行矩阵转置,得到结果.
将上述2维分解进一步推广.假设N=B d,由式(3)得:

其中,n0,n1,…,n d-1∈[0,B-1];k0,k1,…,k d-1∈[0,B-1].根据式(4)可以得到基础FFT点数为B的d维分解算法.
算法1.FFT的多维分解算法.
FFT_MD(d;x0,x1,…,x B d-1):/∗递归定义,B点FFT作为基本运算,参数d为维度∗/
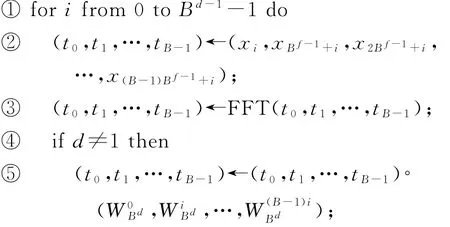

算法1总共进行d轮,每轮完成B d-1组B点FFT.每个元素读、写各d次,参与B点FFT运算d次,乘铰链因子d-1次.
如果存储器的访问粒度为B个点,则算法1中的访存将是“按维连续”的.最基本的运算单元就是B点FFT,每次运算都是在相应的维上连续的B个数据参与运算.采用第3节中将要介绍的3维转置存储器则可以将“按维连续”的访存转换为连续访存,从而解决了超长点数FFT运算的访存连续性问题.
另外,在算法1中计算顺序是按照第d维到第1维进行的,计算第i维(1≤i≤d)的B d-1个B点FFT的过程是相互独立的.当其他维坐标固定时,第i维和第i-1维构成一个B×B的矩阵.如果以这样的矩阵为基本处理单元,则2维处理可以合并,读、写B d-2次B2个元素可以进行B d-2×2B次B点FFT运算.运算次数不变的情况下,读、写次数还能减半.
3 设计实现
考虑到超长点数FFT的精度要求,本文选择单精度浮点作为基本数据表示.在此基础上,选择16点FFT作为基本运算.
3.1 数据流处理
从根本上说,FFT计算过程中需要以2的幂为步长交叉访问数据,这与存储器的连续访问机制不匹配,导致存储带宽利用率低,计算性能无法充分发挥.3维转置运算搭建了连续访问数据与跨步交叉访问数据之间的桥梁.在此基础上,通过2维转置实现算法1中2维处理的合并,进一步减少访存量.
3.1.1 3维转置运算
假设存储器的访问粒度为B个点,则意味着FFT加速器每次必须按第1维的B个点进行读、写.为了存储一个第i维和第i-1维构成的B×B矩阵,需要具备存储B3个点的能力.因为,读入B3个点才能同时得到B个完整的第i维和第i-1维构成的B×B矩阵.此时,如果能够按照第i维或第i-1维同时将B个数据取出,则实现了无带宽损失的3维转置运算.
存储器的访问粒度按照16个点设计,具备存储163=4 096个点的能力,容量为32 KB,使用静态随机访问存储器(static random access memory,SRAM)实现.SRAM无法进行任意方向的读写,即便采用2维SRAM阵列[24](每个存储单元变成了2个端口,增大了SRAM的面积)仍然难以实现3维转置运算.因此,本文采用基于SRAM的无冲突体编址技术实现3维转置运算.
根据高庆狮等人[25]对素数存储系统的研究,对于跨步为2的幂的访问,采用素数个存储体,即可消除存储体访问冲突.假设访问地址为a,a+2r,a+2×2r,…,a+15×2r,采用17个存储体.令2rmod 17=t,则各地址所在的体为amod 17,(a+t)mod 17,(a+2t)mod 17,…,(a+15t)mod 17.如果第i个地址和第j个地址落在同一个体,即(a+it)mod 17=(a+jt)mod 17,则(i-j)tmod 17=0,只有i=j等式才能成立.
3维转置运算的存储体可以存储一个多维张量中按照某3维截取的一个立方体.由于采用17个体在跨步为2的幂访问时不存在体冲突,可以并行读入该立方体,并且对任意2维并行转置读出.作为转置用存储器,每个体需要存储个点,即每个体宽度为64 b(8 B)、深度为241.
按照3维编址进行分析.初始状态下,第1组写入地址为(0,0,0)~(0,0,15),第2组写入地址为(0,1,0)~(0,1,15),依次类推,当写入地址为(15,15,0)~(15,15,15)时,完成全部4 096个点的写入.在完成地址(15,0,0)~(15,0,15)的写入后,即可读出转置后的第1组地址(0,0,0)~(15,0,0).所以,当4 096个点完全写入时,已读出多组数据,下一批4 096个点可以流水写入.
新的4 096个点第1组写入地址为(0,0,0)~(15,0,0),第2组写入地址为(0,1,0)~(15,1,0),依次类推,当写入地址为(0,15,15)~(15,15,15)时,完成全部4 096个点的写入.在完成地址(0,0,15)~(15,0,15)的写入后,即可读出转置后的第1组地址(0,0,0)~(0,0,15).
根据读/写的维序即可计算读/写操作下一拍的3维编址(z,y,x).
根据3维编址得到体地址与体内地址为

并不需要对所有地址进行计算,每次读/写的16个地址,只需要先计算出第1个所在的体地址和体内地址,其余15个可以快速得到.另外,对于以2的幂加1为除数的除法和模运算存在快速硬件实现方法[25].
从式(5)所显示的体地址规律可以看出,第1维和第3维都是连续循环递增的,第2维是连续循环递减的.无论是输入数据还是输出数据,可以根据地址计算出移位位数.分别对输入/输出的16个数据进行顺序和逆序排列之后移位,移位采用2级对数移位器.总体结构如图1所示:

Fig.1 Structure of 3-dimensional transposition operation module图1 3维转置运算模块结构
3.1.2 2维转置运算
2维转置运算采用行向输入、列向输出的存储器阵列实现.需要存储162=256个点,存储容量为2 KB.芯片中容量较小的存储器阵列可以采用触发器、SRAM或锁存器实现.SRAM的面积和功耗开销最小,但是由于2维转置运算对存储器有特殊要求,需要按行写入、按列读出,标准SRAM不支持该功能,因此需要采用定制设计[24],开发周期长且不利于扩展.触发器的面积和功耗开销最大.因此,选择锁存器作为基本存储单元.2维转置运算的存储器如图2所示.
通过2个这样的锁存器阵列来实现转置处理的流水化,如图3所示.读选择信号和写选择信号互为反相,根据读、写次数来进行判断.
3.2 铰链因子处理
对FFT运算点数的支持并不需要无限大,超出主存容量是没有意义的.加速器按照最大支持4G点FFT设计,则存储容量需要32 GB,基本达到当前内存容量的极限.更长点数FFT则依赖于软件方法实现.

Fig.2 Memory for two-dimensional transposition operation图2 2维转置运算的存储器
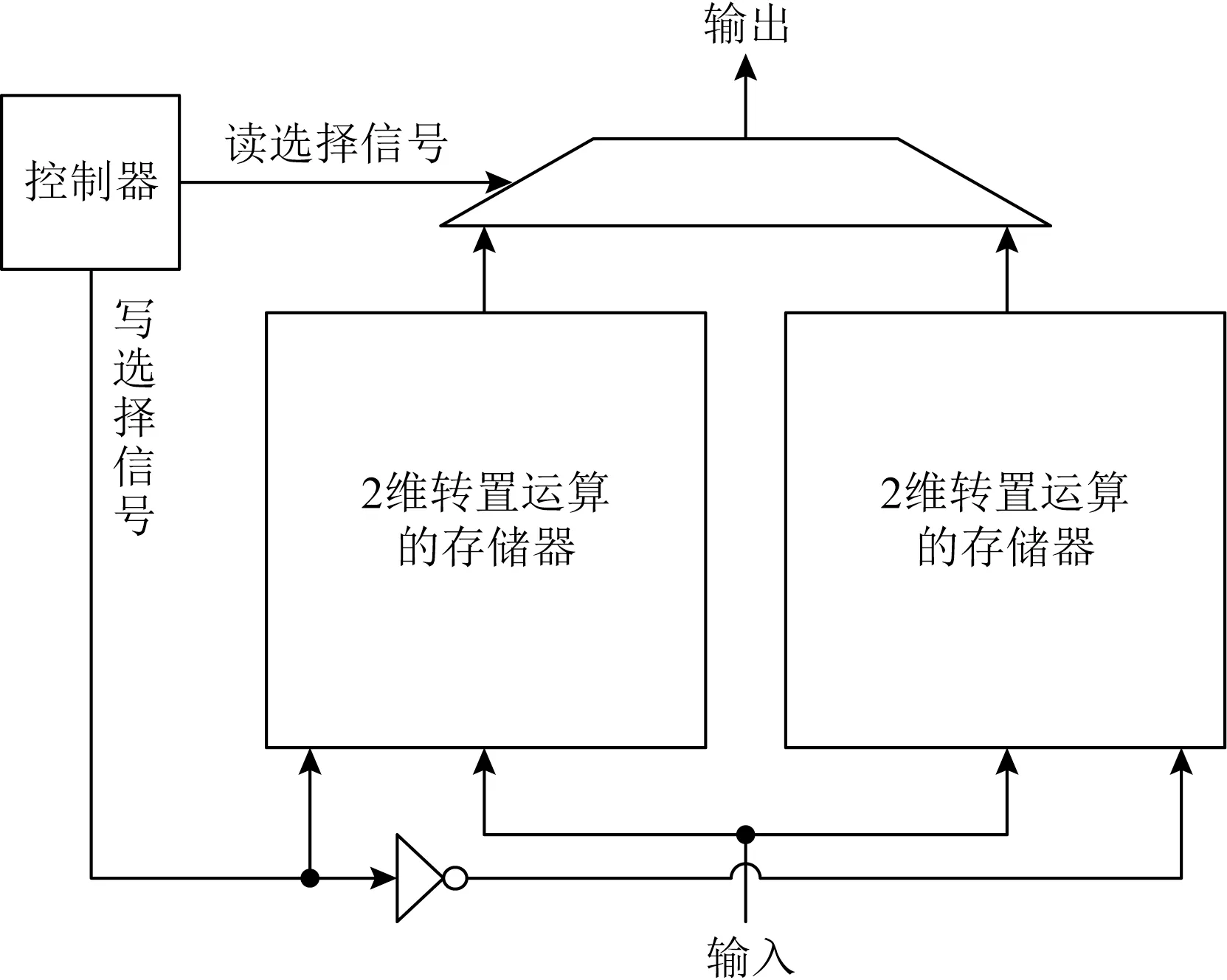
Fig.3 Structure of 2-dimensional transposition operation module图3 2维转置运算模块结构
在许多研究中采用CORDIC算法生成铰链因子,需要进行十几个甚至几十个时钟周期的流水化迭代处理.CORDIC算法可以生成任意角度的坐标值,对于有限集合而言则过于强大.我们注意到,即便对于4G点FFT,也只需要根据算法1进行8维分解,铰链因子是一个有限集合,而且每一组铰链因子与前一组铰链因子存在递推关系,因此,可以使用较为简便的方法实现铰链因子生成.
假设数据组织为8维维序结构,以处理第4维铰链因子为例.x n7,n6,n5,n4,n3,n2,n1,n0需要的铰链因子为.由于同时处理n3=0~15,需要同时生成.在算法1中,处理的第1组点为铰链因子均为处理的第2组点为铰链因子分别为…;处理的第16组点为铰链因子分别为;处理的第17组点为,铰链因子分别为,依次类推.对于同时处理的16个铰链因子中的第k个,可以采用算法2递推生成.
算法2.铰链因子生成算法.
输入:上一个铰链因子Wpre、上一个计数值Cpre、铰链因子的维度d;
输出:铰链因子W、计数值C.
初始状态W=1,C=0;
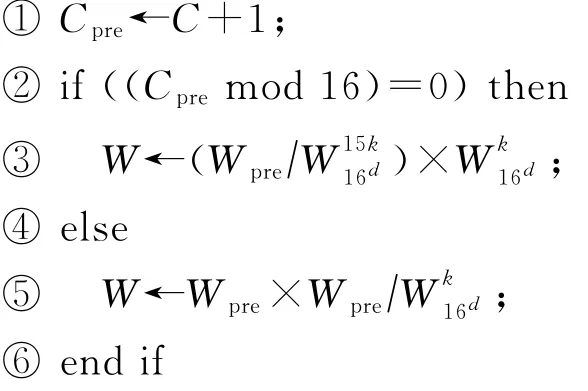
为了并行执行,铰链因子处理需要16个铰链因子生成模块和16个单精度浮点复数乘法器.维度控制逻辑根据FFT命令解析出当前运算的维度,发送给每个铰链因子生成模块.
铰链因子生成模块结构如图4所示.控制逻辑根据处理的维度和计数值生成选择信号.寄存器0用于存储当前的铰链因子,寄存器1用于存储上一个计数值整除16时的铰链因子.控制逻辑根据算法2实现.基础旋转因子包括W k16,W k162,…,W k168为常数,接入固定电平即可.

Fig.4 Twiddle factor generation module图4 铰链因子生成模块
从算法2和图4可以看出,铰链因子生成的延迟与乘法运算的延迟相同,较传统的CORDIC算法有明显优势.但是,该方法也带来了单精度浮点复数乘法器的额外开销.
3.3 基本运算
本文采用IEEE 754-2008标准[26]单精度浮点作为基本数据表示.以Swartzlander等人[14]提出的FDP运算和FAS运算作为基本的浮点运算来构造单精度浮点复数运算.对于复数a=aRe+iaIm和b=bRe+ibIm,其乘积c=cRe+icIm=a×b=(aRe+iaIm)×(bRe+ibIm)=(aRebRe-aImbIm)+i(aRebIm+aImbRe).FDP实现4个单精度浮点数a0,a1,a2,a3的a0a1+a2a3运算或a0a1-a2a3运算.2个FDP(分别配置为加和减)则恰好能够实现一个复数乘法.FAS运算同时完成蝶形运算中的加法和减法运算.
16点FFT运算采用基4 DIT算法实现,总体结构如图5所示,包括3个混洗单元、8个4点蝶形运算单元和8个旋转因子乘法单元.

Fig.5 Sixteen-point FFT operation module图5 16点FFT运算模块
混洗单元内部只有连线,实现地址反序输出,如图6所示:
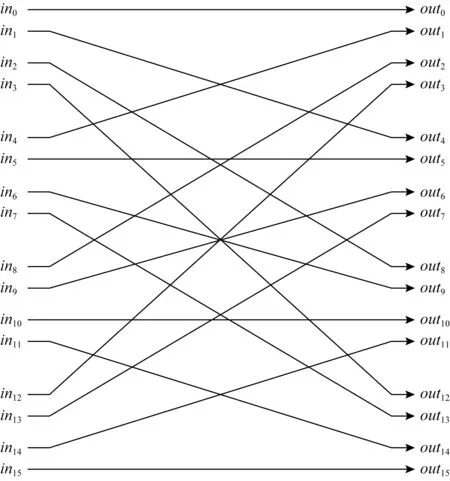
Fig.6 Shuffle unit图6 混洗单元
4点蝶形运算单元完成的运算为

采用图7所示结构实现,其中,Re和Im分别表示一个复数的实部和虚部.

Fig.7 Four-point butterfly unit图7 4点蝶形运算单元
3.4 控制结构
FFT加速器总体结构如图8所示,包括命令队列、读/写控制器、读/写缓冲、3维转置存储器、16点FFT运算模块、铰链因子处理模块和2维转置存储器等.

Fig.8 Overall structure of FFT accelerator图8 FFT加速器总体结构
命令队列从DSP核心的指令流水线接收命令并进行解析,生成各模块控制信号.读/写控制器根据命令队列解析的地址对读/写缓冲和3维转置存储器进行控制.读/写缓冲与存储器交互,用于读/写数据的平滑.
FFT加速器的执行方式为:1)DSP核心通过写特殊存储空间或特殊寄存器方式对FFT加速器进行配置,包括原始数据地址、计算结果地址、计算规模等;2)DSP核心发出异步FFT指令;3)FFT加速器从存储器中读取数据进行FFT计算,并将计算结果写入指定存储器地址中;4)通过中断或回答字机制返回FFT完成信号给DSP核心.
整个FFT加速器通过命令队列和读/写控制器进行管理,工作流程为:1)DSP核心的指令流水线向命令队列发出FFT指令;2)命令队列对FFT指令进行解析,解析出读/写命令;3)读/写控制器生成读/写地址,发送给读/写缓冲;4)读缓冲从存储器中读数据;5)读缓冲将数据发送给输入3维转置存储器;6)输入3维转置存储器根据维序将转置后数据发送给16点FFT运算模块;7)FFT计算后结果经过铰链因子处理,送入2维转置存储器;8)2维转置存储器输出送入另一个16点FFT运算模块;9)FFT计算后结果经过铰链因子处理,送入输出3维转置存储器;10)输出3维转置存储器根据维序将转置后数据发送给写缓冲;11)写缓冲根据写地址将数据写回存储器.
4 实验与分析
4.1 综合结果
本文使用Verilog语言对FFT加速器进行了完整实现.其中,单精度浮点FDP和FAS都采用4级流水线设计.
使用物理信息相关的DCG综合流程[27],对各模块和整个FFT加速器采用TT Corner工艺进行综合,关键路径延时为954 ps(运行频率能够达到1 GHz以上),面积为462 100μm2,功耗为1 210 m W.FFT总体及各模块综合结果如表1所示.
表1中同时列出了一个4级流水的单精度浮点融合乘加(fused multiply-add,FMA)部件的综合结果作为对比.可以看出,整个FFT加速器的面积大致相当于500个单精度浮点FMA部件.本文提出的加速器结构中,4点蝶形运算含有8个FAS,16点FFT运算含有8个4点蝶形运算和8个旋转因子乘法,铰链因子处理中含有32个复数乘法器.可以看出,各子部件单独综合结果与总体综合结果基本吻合.3维转置存储器中使用的每个SRAM存储器的面积为2 500μm2,SRAM的总面积为34×2 500μm2=85 000μm2,占整个FFT加速器的18.39%.
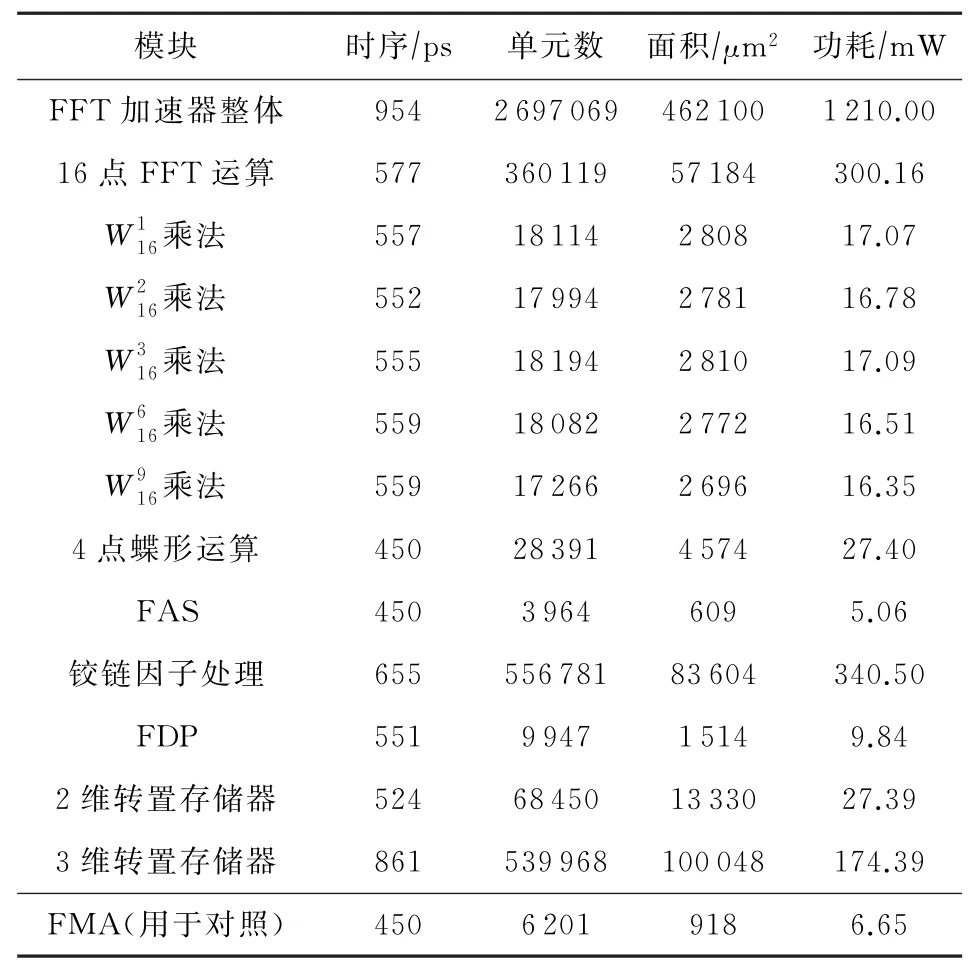
Table 1 Synthesis Result表1 综合结果
本文还对FFT加速器进行了FPGA实现,其中,器件型号为XCVU440-FLGA2892.时钟频率可以达到136.6 MHz,资源消耗情况如表2所示,占用了177 875个REG、657 790个LUT和34个Block RAM.从综合结果来看,本文设计的FFT加速器具有较强的可实现性.

Table 2 FPGA Resources Consumption of Realization表2 FPGA实现资源消耗
4.2 比较与分析
4.2.1 性能与开销
以基2 DIT算法作为性能计算的标准,一个蝶形运算及其完成的基本操作需要4个乘法操作和6个加/减法操作,共10个操作[9].对于N点FFT,总共需要0.5NlbN个蝶形运算,所以总的计算量为5NlbN个操作.
根据综合结果,本文设计的FFT加速器可以运行在1 GHz,内部包含2个16点FFT运算模块,性能能够达到2×5×16×(lb16)flop×1 GHz=640 Gflop/s.

Table 3 Performance Comparison of FFT Accelerator表3 FFT加速器性能与开销对比
表3中对比了若干种长点数FFT加速器的性能和开销.可以看出,采用综合实现方式,本文提出的FFT加速器与现有研究中的浮点FFT加速器相比,能够取得1~2个数量级的性能提升.在与现有研究中的定点FFT加速器比较时,性能上也有优势.得益于多维分解算法的使用,本文将单维处理点数固定为16,从而可以高密度集成16点FFT运算部件.同样得益于多维分解算法的使用,本文设计的FFT加速器能够支持到4G个点,远远超过其他实现方法.
由于不同研究者采用的工艺或FPGA型号不同,难以给出一个统一的开销标准.我们既给出了综合结果,也给出了FPGA实现结果,便于进行开销对比.与其他综合实现的研究相比,本文设计的FFT加速器的面积和功耗开销较高,但是性能面积比和性能功耗比都具有优势.
4.2.2 存储带宽
假设FFT加速器的计算性能为Pcom,基本处理点数为M(对于本文设计的FFT加速器Pcom=640Gflop/s,M=162=256).对于N点FFT(N>M,存储器中能够容纳N个点数据),计算量Acom=5NlbNflop,访存量Amem=16N(lbN/lbM)B.存储器带宽Bmem需满足:
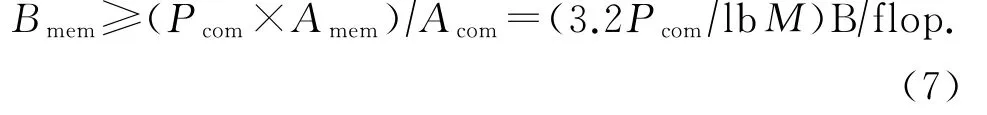
所以,本文设计的FFT加速器,需要的存储器带宽为0.4×640 GB/s=256 GB/s.对于使用DDR存储器的高端处理器,这个带宽是可以满足的.对于使用GDDR和HBM存储器的处理器,存储带宽更高.
对于主存带宽受限的情况(以128 GB/s为例),则可以通过设置缓存的方式来达到对计算能力的支持.缓存的带宽需要满足256 GB/s(对于片上SRAM是容易实现的),缓存能够容纳的点数M∗可以视作主存视角的基本处理点数.则lbM∗≥(3.2×640)/128=16,M∗≥216,即缓存容量需要达到512 KB,对于处理器而言也是容易实现的.
对于主存带宽较低的情况(以32 GB/s为例,假设片上缓存容量为2 MB),点数小于256 K时能够达到峰值计算性能,点数大于256 K时的计算性能
4.2.3 计算效率
本文设计的FFT加速器以256点为基本处理单位,当计算的总点数为256的幂时,性能可以得到充分发挥,其他情况下计算效率难以达到100%.
对256点到4G点FFT的计算效率进行模拟测试,结果如图9所示.可以看出,对于点数不是256幂的情况,点数较小时计算效率降幅较大,而点数较大时计算效率降幅则较小.这是由于,当点数较大时,在大部分情况下都能选择出完整的2个维度进行FFT计算.

Fig.9 Computing efficiency of FFT accelerator图9 FFT加速器的计算效率
在本文设计的FFT加速器中提高小点数FFT的计算效率仍然需要进一步探索.
5 总 结
本文提出一种可集成于DSP的高性能超长点数FFT加速器结构.通过基于素数体的片上3维转置存储器、高效铰链因子生成技术和精细化FFT运算电路设计,实现了超长点数FFT的多维分解算法.对于4G以内点数的单精度浮点FFT计算,能够达到640 Gflop/s的性能,大幅提升了FFT加速器的性能和支持的点数.
