面向多核处理器的可配置缓存一致性协议设计与实现
2021-06-17陈志强周宏伟冯权友邓让钰
陈志强 周宏伟 冯权友 邓让钰
(国防科技大学计算机学院 长沙 410073)
(czq19982016@163.com)
共享主存多核处理器在并行处理中具有很大优势,它维护1块完整的地址空间,处理器核通过load和store指令访问共享主存空间,每个处理器核有单独的私有缓存,都可以缓存数据,1个数据可以拥有多个副本,它们之间可能相同,也可能不同.层次化存储在提高性能的同时必须保证正确性,通用的方案是通过缓存一致性协议来解决数据不一致[1].
根据实现不同,一致性协议可以分为2类,监听协议(snoop-based protocol)和基于目录的协议(directory-based protocol).监听协议将一致性事务直接广播给最后一级缓存(last level cache,LLC)和主存,通常是通过总线结构.这类协议受限于总线有限的带宽以及总线所能挂载的最大负载数量,限制了它的可扩展性,这种特性使它不适用于核数较多的处理器.另一种基于目录的一致性协议[2],每个内存块对应1个目录项,目录项中记录状态信息和共享信息.操作数据时,向拥有数据副本的缓存直接发送请求.当下,包含32及以上核心数目的多核处理器成为主流,相较于基于总线的监听协议,基于目录的一致性协议具有更好的可扩展性.随着处理器核心数量的进一步增加,基于目录的一致性协议优势更加明显[3].
为了避免广播操作,需要知道当前数据副本的位置信息,这些信息记录在目录项中.对数据进行操作时,可以直接根据目录项中的记录,发出点对点的请求通信,避免了低效的广播操作.代价是需要额外的空间来存储目录项,目录项中记录缓存副本的共享信息.在共享主存多核处理器中,一个数据最多有N个副本,N为处理器核数目,目录项中最多需要容纳N个地址空间,同时目录数量和N成正比,因此总的空间开销和N2成正比.这种目录存储方式会造成巨大的存储空间开销.在实际程序运行中,根据程序访问的局部性原理,一段时间内只有部分处理核心共享1个数据块,同时存在N个副本的情况非常罕见,因此提出了有限目录,数据块在缓存中存在的副本数量有限,假设为T(T<N).T最终取决于系统架构,这样就可以解决目录空间过大的问题.
在基于目录的一致性协议中,根据目录的分布方式可以分为集中式目录和分布式目录[4-7].集中式目录用1个中心目录存储所有副本信息,可以提供维持一致性所需的全部信息.这种目录的容量大,查找时间较长,查找共享数据的过程中会有较多的冲突.优势在于架构清晰,易于控制.分布式目录按照一定的分体方式位于多核处理器芯片的不同位置,每个分体较小,可以实现更快的查找速度,不足之处为访问不同目录体时根据片上网络延迟的不同而具有一定的延迟差.随着多核处理器核心数量增加,芯片的面积越来越大,在芯片上实现集中式目录的物理实现难度越来越大,分布式目录成为主流.Knights Landing(KNL)是Intel针对高性能计算发布的架构,使用基于目录的缓存一致性协议MESIF.KNL为了缓解集中式目录的访问瓶颈,采用了分布式目录[8-9].
多核处理器研发周期长、难度大[10],传统上,一致性协议的验证主要通过模拟,通过运行基准测试程序并检查输出结果以验证一致性是否正确.然而测试程序无法有效模拟所有情况,之前的工作表明,即使经过广泛的模拟[11-13],一致性协议仍然可能有缺陷.死锁问题是缓存一致性协议设计中的难题,与多核处理器的体系结构密切相关,一旦出现死锁,可能导致整个芯片设计失败.面向多核处理器的防止缓存一致性协议死锁的方法主要是通过构建多个虚网络,不同类型的报文通过专有的通道.虚通道可以有效解决一致性协议死锁问题,但是会带来较高的功耗与面积开销,在多核处理器中,这种不利影响尤为突出.在DRAIN[14-15]中提出了一种解决这类死锁的方法,通过周期性的操作使报文沿着固定路径前进1跳,从而破除已经存在或潜在的循环依赖关系.这种方法基于死锁产生的概率低,在牺牲部分性能的情况下,取得了较低的功耗与面积开销.
本文面向基于分布式目录的多核处理器体系结构,提出一种动态可配置的缓存一致性协议的设计与实现方案,该方案通过在分体目录控制器中增加微操作机制,实现缓存一致性协议的动态配置,可以增加多核系统的协议容错性,并且能够在芯片流片后解决可能发生的协议死锁问题.
1 动态可配置缓存一致性协议
MSI,MESI和MOESI是常见的一致性协议.MESI在MSI的基础上将独占态E从共享态S中剥离出来,这样对E状态进行修改就可以避免监听操作.MOESI进一步增加了拥有者O状态,O状态是S和修改态M的混合,明确数据的所有权,可以与主存不一致,避免了不必要的写回操作.3种协议各有优缺点:MSI协议支持缓存块的多个副本,将M和S状态进行了区分;不足之处在于存在不必要的作废广播报文等.MESI将E状态进一步区分出来,可以减少不必要的监听操作;不足之处在于M和E状态的冲突等.MOESI进一步增加了O状态,从M转换为S时,避免了不必要的写回操作;不足之处在于在读请求时,每个副本都会发回数据,造成报文拥挤[16-17].
协议的状态越多,状态转换的状态机和协议的处理流程就越复杂[18],设计与验证的难度越大.为了提高缓存一致性协议设计的灵活性,避免由于协议与体系结构适配方面的疏漏导致的一致性协议功能和性能问题,本文提出动态可配置缓存一致性协议的设计思路.核心思想是:协议的状态和一致性处理的流程均可配置,能够适用于不同的多核处理器体系结构.同时,能够根据系统结构对功能和性能的不同需求,实现功能容错和性能调优.
协议状态的转换主要由LLC负责,状态转换的条件除了依赖处理器核的访存请求外,还依赖于来自根节点(home node,HN)目录控制器的监听请求和监听应答报文.
根据不同的系统架构,节点中缓存行的状态转换可以配置,由具体的一致性协议物理实现决定.例如,对于MOESI协议,当M状态遇到获取数据请求(GetS)时,通常是转换为O状态,也可以配置转换为S状态,协议退回到MESI协议:M转换为O,可以避免不必要的写回操作,但是在读失效时需要多个副本共同响应,对片上网络(network on chip,NoC)的报文压力增加;M转换为S,需要在返回数据时进行写回操作,不过可以仅从1个副本获得数据,对片上网络的报文压力小.2种配置对于访存的压力和片上网络的压力各有不同的影响,具体如何配置取决于具体架构实现.
除了协议状态的可配置,一致性处理流程可配置能够进一步提高协议处理的灵活性.优势在于可以针对具体操作做出优化并且极大增加系统的容错性,甚至可以在CPU流片后进行一致性协议的修改与完善.可配置流程的工作过程说明为:
1)写回操作协议流程可配置
图1表示的是2种HN写回(WB)从节点(slave node,SN)操作流程的对比.图1(a)为WB事务处理流程,图1(b)为WBD(WB_Data)事务处理流程.

Fig.1 Comparison on protocol flows between WB and WBD图1 WB和WBD协议流程对比
如图1所示,WB事务需要SN有接收空间,并返回对应的ID号,HN才会发出数据报文,这种协议适用于HN和SN通过NoC网络连接的架构,如果SN没有足够的缓冲空间来容纳报文,多余的报文留存在片上网络中,可能导致死锁.WBD事务直接发出带有数据的报文,这种协议适用于HN和SN直接相连的架构.协议流程的灵活配置增大了对不同架构的适应能力,使其具有良好的可扩展性.
2)LLC写回操作可配置
一致性协议的验证比较困难,特别对于采用不维序片上网络的多核处理器系统.一致性协议存在的缺陷可能导致整个CPU设计的失败,图2展示了Sun公司的可扩展共享主存多处理器S3.mp中存在的一个一致性协议缺陷[12].
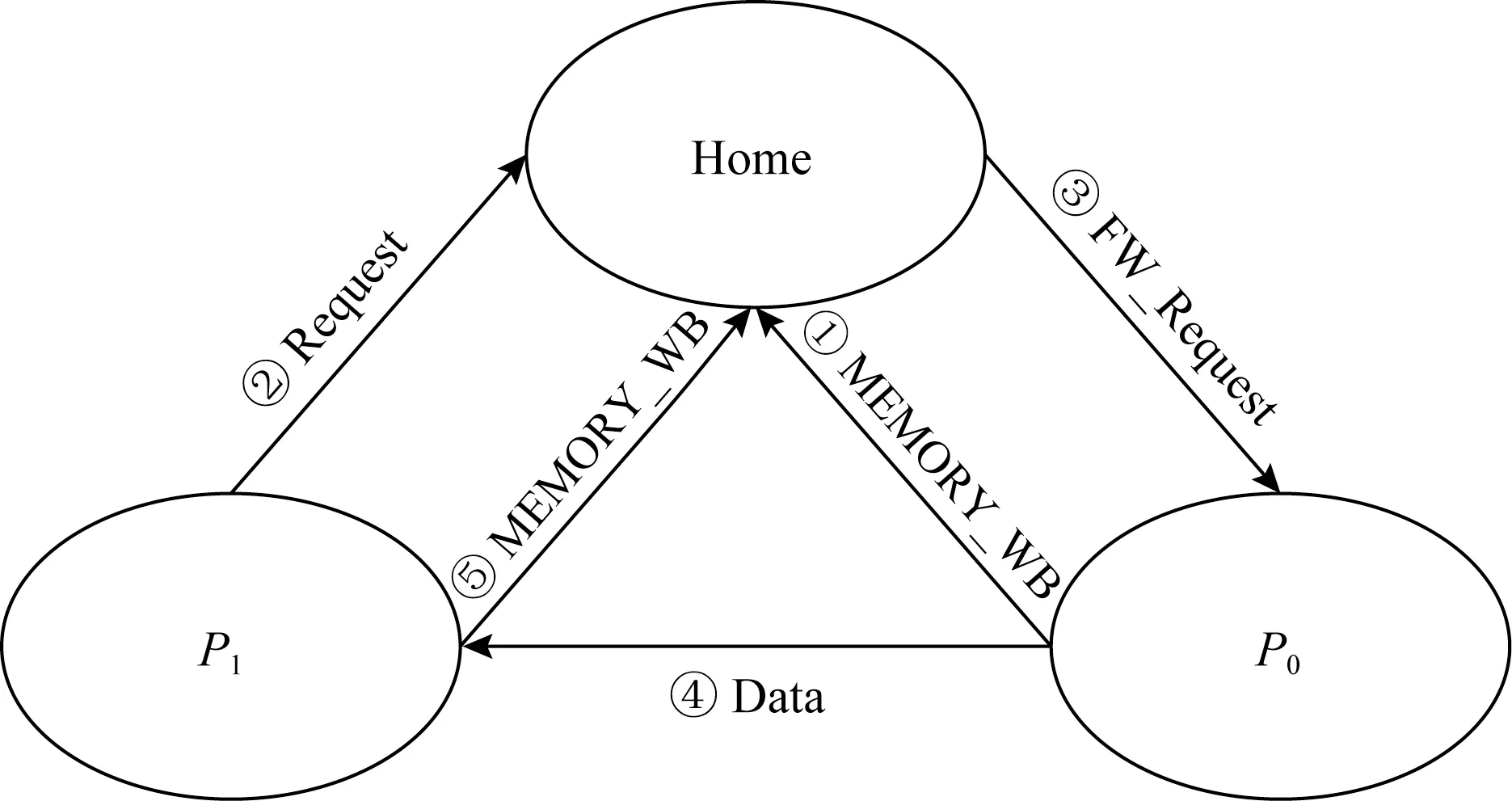
Fig.2 Data inconsistency caused by stale write-back图2 写回竞争导致的数据不一致性
图2中,P0拥有脏数据,写回请求(MEMORY_WB)正在等待根节点(Home)的完成响应,因此P0暂时保留了脏数据.此时P1请求获得缓存行的数据,向Home节点发送请求(Request),Home向P0转发请求(FW_Request),随后P1从P0接收到数据,然后P1重新写数据,接着向Home节点发出写回请求.此时P0和P1发出的写请求就会产生竞争,如果P1的请求获胜,P0接下来的写就会将P1最新的数据覆盖掉.注意到,一系列合法操作,导致最新数据可能被覆盖.这种一致性协议设计不足导致的缺陷,造成了严重的后果.可配置一致性协议通过配置协议处理流程,可以修改为P0具有数据的所有权,其他处理器读取该脏数据后仅仅共享使用,不负责写回.这样就可以避免写回竞争,从而解决设计缺陷.
3)I/O写数据合并可配置
一般情况下,I/O写主存时,如果此时LLC中对应缓存行为脏数据,需要等待LLC的脏数据写回之后,再将I/O的数据写主存,如图3所示:
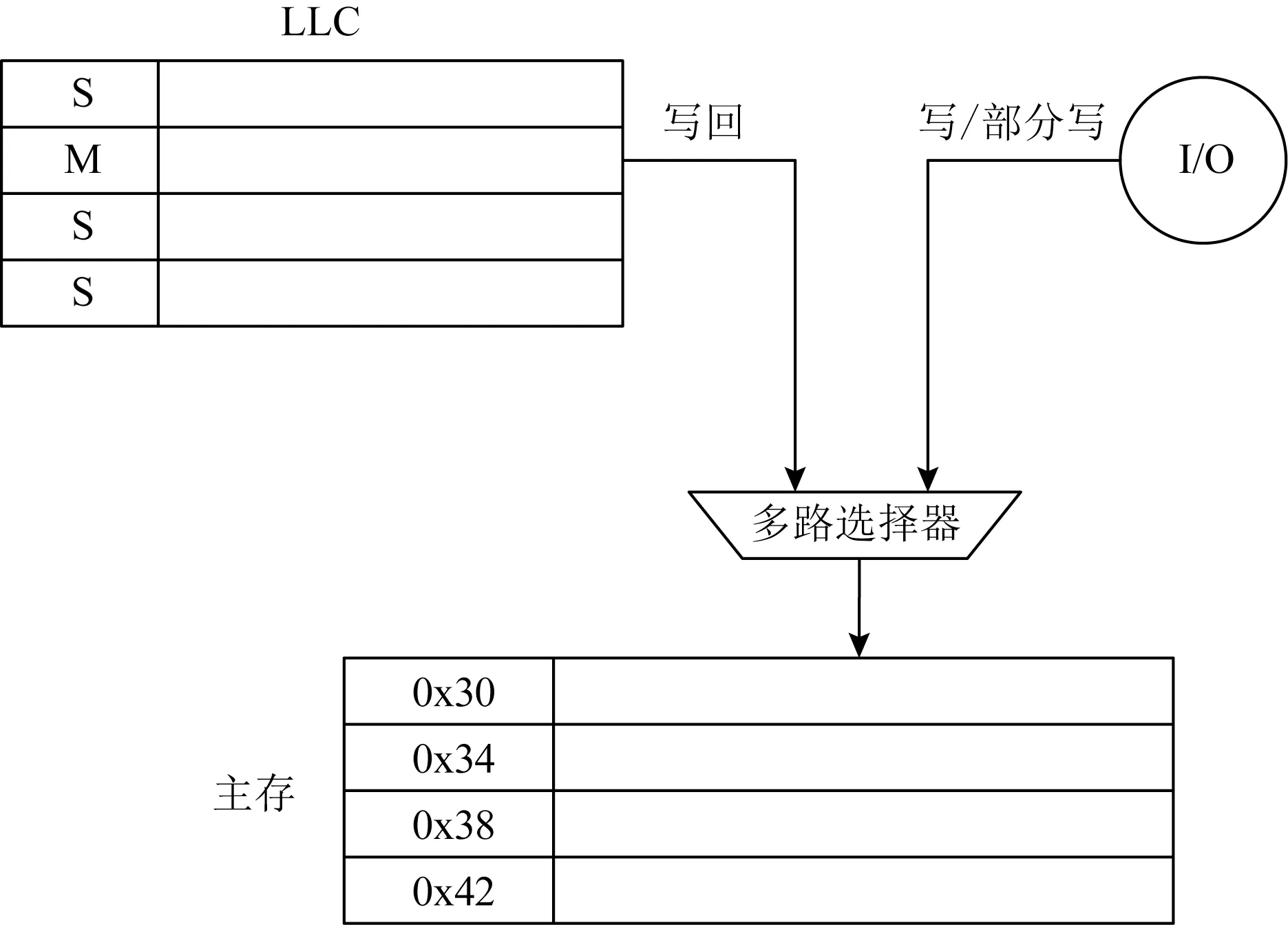
Fig.3 The conflict between I/O and LLC图3 I/O写数据与LLC脏数据的冲突
2次相连的写主存操作会带来较大的访存开销[19],考虑到LLC写入的数据马上被I/O的数据覆盖,如果I/O写与LLC的写回均是缓存行对齐的,那么协议可以配置为将2次写操作合并,直接将I/O的数据写回主存,而之前的LLC的写回操作可以被丢弃,这样就可以减少1次写主存操作.
但是,由于I/O写操作支持对缓存行的部分字节写.因此存在这样的情况:I/O只修改了缓存行中的部分字节,而LLC中M状态下该缓存行保存了I/O部分写的字节以外的最新数据,因此这种情况下LLC的写回操作不能被丢弃,否则会导致部分LLC脏数据没能写回主存,造成数据错误.协议可配置特性可以配置是否进行数据合并协议优化,在保证协议正确前提下提高性能,在协议处理有漏洞的情况下能够回退到LLC和I/O依次写回数据到主存,以确保协议执行的正确性.
以上仅列出了3种协议可配置场景,增强了协议的容错性以及对不同架构的适应能力.
2 可配置协议分布式目录控制器
为了实现可配置协议,我们设计了可配置协议分布式目录控制器(configurable distribute directory unit,CDDU),引入了微操作机制.CDDU的总体结构如图4所示.流水线共8级,分别是:目录查找、目录读出、数据校验、数据纠错、目录比较、目录命中、目录产生和目录写入.目录查找、目录读出、数据校验、数据纠错、目录比较、目录命中等流程和常见的基于目录的一致性协议大致相同,不同之处在于目录产生阶段.一般情况下,目录产生由硬件实现,速度较快,不足之处在于难以修改.引入微操作设计后,可以通过设置微程序来改变使能信号,从而改变目录产生过程,实现一致性协议的可配置.这种设计带来的不足在于微程序表带来的额外开销以及微程序控制相较于硬布线控制的速度较慢.
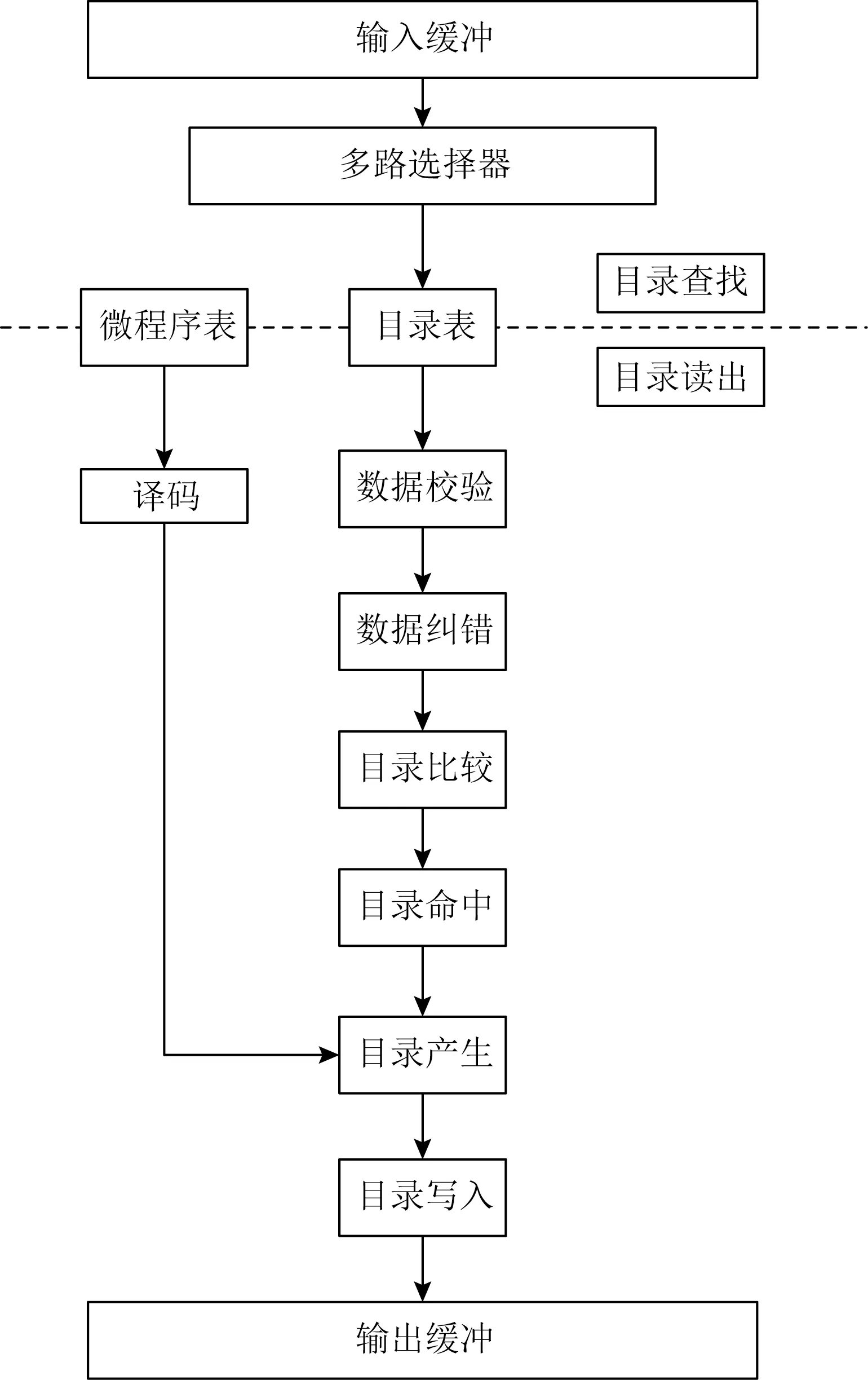
Fig.4 The pipeline structure of CDDU图4 CDDU的总体结构
CDDU的核心功能在于目录表和微操作表.
1)目录表记录缓存中数据副本的使用情况,并且根据当前命令和目录状态进行跟踪与修改,维护LLC的数据一致性.由于目录项空间大小有限,只能存储部分缓存行信息,这就需要进行目录项替换.LLC由多核共享,多个核心可能同时访问1个缓存行,这就涉及到目录项的冲突.目录表需要提供目录项的替换和冲突信息,由多路选择器选择合适的报文进行处理.
2)微操作表用于实现微操作机制.微操作表中保存着用于配置一致性协议流程的微程序代码,是实现微操作设计的重要组件,其详细结构如图5所示.微程序地址空间的组织形式类似于链表,每段微程序执行完毕后,根据微程序地址确定下一段微程序的起始地址,这样的优势在于增加微程序执行的灵活性以及增加微程序的寻址空间.不同微程序会设置不同的使能信号,动态可配置一致性协议的实现就是基于不同使能信号的组合.例如ACK_en使能信号可以控制报文是否需要Ack响应.TAG_en控制标志位的写;FWGETS_en控制是否发出FWGETS请求;GETS_en控制是否发出GETS;DATA_en控制是否返回数据;MEMACK_en控制是否返回MEMACK;INV_en控制INV信号;INVACK_en控制是否返回INVACK;MEMDATA_en控制是否返回MEMDATA.不同使能信号的自由组合就是目录控制器灵活性的来源.
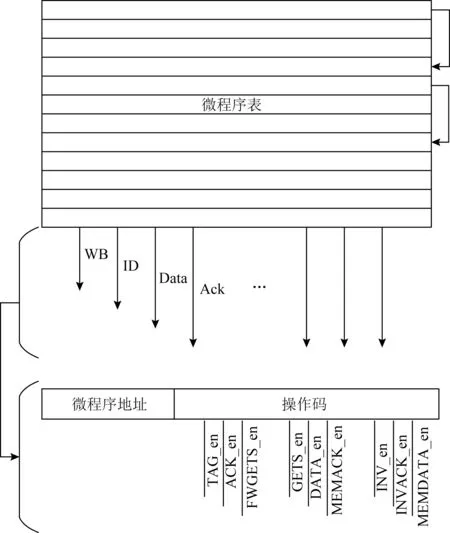
Fig.5 The structure of micro-operation table图5 微操作表的结构
相较于硬布线控制,微程序便于修改的代价是会带来较慢的执行速度.因此我们在CDDU中设计了调试模式,把微操作机制作为冗余设计,希望在保证性能的前提下,实现以空间代价换取较高的容错性.一致性事务在执行前会判断是否进入调试模式,判断依据可以根据不同架构进行定制设计.
3 微操作机制解决协议级死锁
死锁问题是多核处理器片上网络和一致性协议设计的关键.死锁的原因是形成了循环依赖,而一致性协议的事务处理流程中本身存在依赖关系,更容易产生死锁.由于NoC网络的延迟,一致性协议的报文并不总能按序到达,这就导致可能请求报文先于响应报文到达目录,从而堵塞响应报文导致死锁.
微操作机制为协议实现提供了更好的灵活性,能够用于协议性能优化和容错.特别是为解决协议级死锁提供了一种新的方式.下面介绍通过微操作机制在防死锁方面的重要功能.
传统的解决死锁的方法包括转弯模型(turn model)、逃逸虚通道(escape virtual channel)等[20-21],但是由于一致性报文之间的依赖关系,这些方法并不适用于解决协议级别的死锁.目前通用的方法是构建多个虚网络,从根源上避免了死锁.虚网络由不相交的虚通道组成,每个虚网络只能被一种类型的报文使用,因此不同类型的报文不可能形成闭环.构建多个虚网络的代价是需要大量的缓冲区,造成较高的面积与功耗开销.在DRAIN[14-15]中提出了一种低代价的死锁解决方案,该方案基于死锁产生的概率低,应该以较低的代价来解决小概率问题,因此省去了复杂的死锁避免以及死锁检测机制,而是以周期性的循环操作来破除潜在的死锁依赖关系.动态可配置缓存一致性协议设计可以灵活配置一致性协议,用于解决死锁问题.如图1中WBD是一种优化实现,这种优化方案可以有效降低延迟,提高性能.这种优化方案取得良好效果的同时,也带来了死锁隐患.
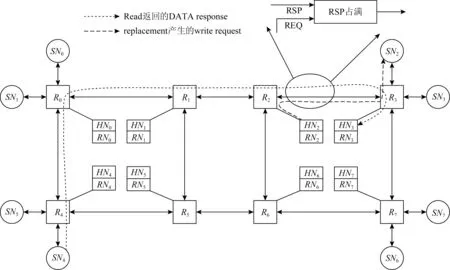
Fig.6 Deadlock caused by shared response channel图6 由共享响应通道引起的死锁
图6为我们在飞腾64核处理器研发过程中在芯片流片前验证时发现的一种死锁场景.该处理器的体系结构抽象为:8个路由器(router,R)、8个HN,8个SN.由于布局原因,SN2与SN3均与R3连接,SN4与SN5均与R4连接.H N2访问SN2以及H N5访问SN5需要通过片上网络的路由器之间的链路访问.根据第1节的分析,为了提高替换操作协议性能,希望能够采用WBD.由于WBD事务中写回请求携带数据,因此必须分配使用能携带数据的通道,在具体实现过程中,写回请求通过HN到SN响应(RSP)通道发送写回请求.例如,H N2到SN2的写回请求走RSP通道.由于该处理器支持SN直接将数据推送(Forward)到请求节点(RN),因此存在通道共享情况:例如SN4推送读响应报文到RN3,也使用R2到R3的(RSP)通道.通道共享存在死锁可能,在芯片仿真验证时的确发现了死锁.
由于WB事务流程具有握手与重传机制,不会堵塞链路,因此,HN2到SN2以及H N5到SN5应该采用WB以避免死锁.考虑到该死锁仅与SN3与SN5有关,所有的HN与SN间的写回采用WB无法获得WBD的性能,因此可以仅对H N3与H N5配置为WB.另外,还可以采用全部配置为协议WBD,同时利用协议死锁检查与微操作机制,在发现死锁时进行解锁.我们对后者也进行了设计与分析.
使用WBD流程,在如图6所示的架构中,H N2到SN2的WB请求进入响应通道,需要通过R2和R3,到达SN2.SN4到H N3的响应Response进入响应通道,经过R4,R0,R1,R2,R3,到达H N3.2种报文共用了R2和R3之间的物理链路,根据虚网络构建的原则,不同类型的报文共享通道会形成死锁.死锁形成的过程分析为:H N2向SN2的多个请求报文占满缓冲区,导致SN4到H N3的响应报文无法通过链路1返回H N3,在H N3中响应报文无法返回意味着原有的一致性事务无法释放,这就导致了死锁.
短时间大量请求报文堵塞了物理通道,导致响应报文无法返回,一致性事务得不到释放导致死锁.这种短时间内的大量报文并非程序运行的常态,出现概率低.针对这种出现概率较小的情况,通过配置一致性协议来实现一种代价较小的死锁解决方案.
我们的防死锁机制工作为:通过监控HN到SN的读写事务的等待时间,能够判断是否已经出现死锁.HN到SN之间的协议默认为WBD,以实现更优的性能.如果等待时间超过一定阈值,则说明HN到SN的链路已经堵死,可能产生了死锁.目录控制器会进入调试模式,将HN到SN的协议从WBD切换到WB,启动重传机制,逐渐排空阻塞的链路.经过一段时间,死锁解除后,再回复到正常模式和WBD,以高性能方式执行.采用2种一致性协议交替工作的方式,WB采用信用和重传机制,不会导致物理链路的堵塞,WBD可以实现更低的延迟,但有可能堵塞链路.2种协议交替工作,可以在保持性能的同时避免死锁.
4 实验结果与分析
我们使用Gem5来搭建模拟环境[22],一些关键参数如表1所示.Gem5支持对一致性协议的修改,在原有的MESI协议基础上,我们进行了部分修改,在Mesh网络不同规模下(2×2,2×4,3×3)进行了系统性能评估.为了更明显体现WBD经由路由网络写回主存对系统性能的影响,采用了128 MB共享主存,4个目录表分布在Mesh网络的4个顶点.采用了XY路由策略,在2×2,2×4,3×3网络中,每个路由节点到达目录控制器的最大跳数分别为2,4,4.

Table 1 Configuration of System表1 系统参数配置
图7展示了2×2 Mesh网络的架构,4个分布式目录位于Mesh网络的4个顶点,二级缓存通过路由节点连接到网络,DMA控制器连接到0号路由节点.3×3和2×4网络的架构和图7类似.

Fig.7 The structure of 2×2 Mesh图7 2×2 Mesh网络架构
实验分为3部分:1)验证在WB和WBD不同协议配置下,对系统性能的影响;2)验证第3节提出的微操作机制解决协议级死锁的正确性与性能影响;3)对微操作机制的功耗与开销进行分析.
1)WB和WBD的性能比较
图8为在不同数据规模和网络规模下WB和WBD的性能对比,横坐标是片上网络规模,分别对应2×2,2×4,3×3 Mesh网络;纵坐标是程序的平均执行时间(运行周期数);图8(a)(d)对应0.64 M数据规模,图8(b)(e)对应1.28 M数据规模,图8(c)(f)对应2.56 M数据规模.我们模拟了2种协议下一致性事务的平均完成周期数,使用的是类似流拷贝(stream copy)的应用负载,在程序稳态时该程序对存储器的访问特性为两读一写,写是由缓存替换触发.图8(a)~(c)中,在相同数据规模下,随着网络规模增加,WBD的性能提升更加明显;在相同网络规模下,随着数据规模的增加,WBD的性能提升更加明显.
分析原因如下:WB需要4次通过NoC网络,包含发送替换请求(Replacement)、返回ID、发送数据(DATA)和返回Ack共4个一致性流程;而WBD只需要2次通过NoC网络,仅包含替换请求与数据(ReplacementData)和返回Ack,通过NoC的次数更少.在2×2,2×4,3×3网络中,每个路由节点到达目录控制器的最大跳数分别为2,4,4.随着网络规模的增加,最大跳步数增加,相应延迟也增加.LLC容量不变,数据规模增加,替换请求的次数也随之增加,WBD的性能提升更加明显.图9为在同一网络规模和不同数据规模下,分别在访存密集型负载(即流拷贝(stream copy))和计算密集型(Leibniz定理求π)负载下,WBD相较于WB性能提升对比.结果表明,随着负载规模的增加,访存密集型负载和计算密集型负载的性能提升趋势相同,说明协议性能的提升效果适用于多种类型的负载.
在大规模网络和高负载下,WBD相较于WB的优化效果更加明显,在实际运行中,性能提升会随着网络规模和负载的增加而增加.
2)微操作机制正确性与性能影响
微操作机制在解决死锁问题的同时,会对系统性能产生影响.理论上,不同网络和数据规模下,微操作相较于WB都会有部分性能损失.然而在图8(d)~(f)中,相对于WBD对WB的提升,引入微操作机制对于WBD的性能损失非常微小.微操作避免了WB可能导致的协议死锁,实现了以较低的性能损失来解决死锁问题.

Fig.8 Comparison of execution time under different load and network图8 不同数据和网络规模下程序执行时间对比
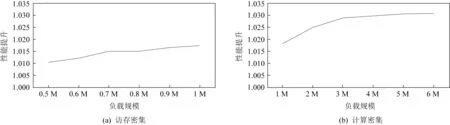
Fig.9 Comparison of performance improvement under two kinds of workload图9 2类负载下性能提升对比
3)功耗与开销
微操作机制的硬件开销主要来源于微操作表和控制逻辑.微操作控制逻辑门数占比总逻辑门数约为2%,微操作表的SRAM占整个目录SRAM容量的1.54%.目录控制中主要的面积来源为存放目录信息的SRAM,微操作机制额外带来的面积开销不到2%.功耗方面,可以通过开关配置微操作机制的使用,闲置时关闭以降低功耗.在实际运行中,微操作机制的功耗几乎可以忽略.微操作机制作为引入的冗余机制,在正常情况下并不直接参与一致性协议的运转,该机制在协议发生问题,例如死锁时介入,等待问题解除后退出,增加协议的容错性.
根据以上实验结论,我们可以在缓存一致性设计中,对于由于替换操作引发的写回事务的流程,采用WBD以提高性能,而潜在的死锁风险通过基于微操作的防死锁机制来避免,依然获得比仅采用WB更好的性能.可配置协议防死锁没有引入额外的虚通道,仅仅利用了可配置的微操作机制,面积和功耗开销就是微操作表的开销.其他传统的防死锁机制需要较为复杂的机制的硬件资源,如额外的虚通道、全局监控和解除死锁网络等.目前我们只在模拟环境中评估了相应的性能,下一步会在物理实现中进一步评估硬件资源和功耗.通过上面的实验,验证了协议配置的必要性和有效性,以及基于微操作机制解决协议级死锁的正确性和性能提升效果.下一步将研究在不同核心数以及不同路由网络下的性能情况.对于防死锁机制中HN到SN读写事务的等待时间的阈值变化对防死锁机制性能影响,也是我们需要在下一步进行研究和优化的方向.
5 总 结
本文提出了一种面向多核处理器的可配置缓存一致性协议,可以通过微操作来实现一致性协议的动态配置,包括协议状态转换的配置和协议流程的配置.这种灵活的设计可以极大提升系统的灵活性,能够针对不同架构,提高一致性协议的执行效率,优化系统性能;另外,还可以通过微操作机制解决协议级死锁,提高系统的容错性,以应对CPU设计中可能存在的缺陷.通过模拟测试,结果表明缓存一致性协议在不同的配置下的性能不同,死锁的风险也不同,可配置的缓存一致性协议以及CDDU模块能够在实现协议配置灵活性的同时降低系统死锁风险,在保证一致性协议正确性的基础上,提供更多的协议优化和容错的空间,降低了芯片研发的风险.本文思想在自主飞腾64核处理器中进行了实现,为确保处理器的协议正确性发挥了重要作用,同时在该芯片的多路扩展实现过程中提高了协议的鲁棒性,消除了潜在的死锁,具有非常重要的工程实现意义.
