处理器芯片敏捷设计方法:问题与挑战
2021-06-17包云岗常轶松韩银和黄立波李华伟罗国杰颖解壁伟喻文健孙凝晖
包云岗 常轶松 韩银和 黄立波 李华伟 梁 云 罗国杰 尚 笠 唐 丹 王 颖解壁伟 喻文健 张 科 孙凝晖
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
2(中国科学院大学计算机科学与技术学院 北京 100049)
3(北京大学高能效计算与应用中心 北京 100871)
4(专用集成电路与系统国家重点实验室(复旦大学) 上海 201203)
5(国防科技大学计算机学院 长沙 410073)
6(清华大学计算机科学与技术系 北京 100084)
(baoyg@ict.ac.cn)
处理器芯片是电子信息产业的驱动引擎,已成为人类社会的数字化、信息化和智能化的基石.互联网、电信、金融、服务业等传统行业以及物联网、车联网、人工智能等新兴领域,都需要各类处理器芯片提供强有力的支撑计算能力.
然而,现有处理器芯片设计方法和体系需要极为复杂的设计描述和实现流程,并结合先进工艺节点下的制造、封装和测试环节,实现处理器芯片性能——频率、面积和功耗的最优设计.这就导致处理器芯片设计具有极长的设计周期,造成极高的设计门槛.
1)传统通用处理器CPU设计愈发复杂
随着工艺技术节点的不断发展,基于现有的处理器设计方法,通用处理器芯片设计规模大幅增长,设计成本日趋高昂.以14 nm工艺节点为例,研发一款通用处理器芯片,需要投入上百人年,耗费上亿美元的研发经费①数据来源:Andreas Olofsson,Intelligent Design of Electronic Assets(IDEA),2017,形成极高的设计门槛.通用处理器芯片流片失败势必会造成巨大的成本浪费,因此只有极少数处理器芯片产业巨头企业才能够承受中高端通用处理器芯片的研发成本.
2)新兴专用处理器XPU亟需大量定制
人类社会正逐步迈入“万物互联”的智能物联网(AIo T)时代.每个物联网设备都需要一颗处理器芯片来实现网络互连和智能计算的功能,从而形成一个极具规模的处理器芯片市场.
然而,与传统互联网和移动互联网时代的应用场景相比,AIo T设备需根据特定的专用应用领域需求,对处理器芯片进行深度定制,通过软硬件协同设计,定制领域应用专用处理器硬件架构及软件程序,以满足特定场景对芯片性能、功耗和面积需求.由于应用场景未来将呈现爆发式增长,势必会造成不同AIo T设备对处理器芯片的设计需求出现极大差异化和碎片化.如继续沿用现有处理器芯片设计方法,至少需要投入2~3年的设计时间,才能完成一款AIo T芯片的研发.过长的芯片研发和上市时间显然无法满足海量的领域专用AIo T芯片及设备的快速定制需要,亟需探索一种敏捷的专用处理器芯片设计方法,以快速应对海量的AIo T芯片碎片化设计需求.
针对上述问题,如何突破现有处理器设计方法的壁垒,在保证性能和可靠性的前提下既可降低通用处理器CPU设计复杂性、成本和设计门槛,又能应对专用处理器XPU场景多样性并缩短设计周期,从而形成以降低时间、成本和复杂度为主要导向的处理器芯片敏捷设计新方法,是破解CPU和XPU处理器芯片设计难题的有效途径.
1 面向对象的处理器体系结构
随着摩尔定律发展速度放缓,芯片内处理单元核心的频率和性能增长几乎停滞.为了保证单核心处理单元继续维持现有计算能力和面积、功耗水平,传统处理器芯片设计方法需要将计算核心作为一个单体(monolithic)设计,流水线前后端各逻辑模块具有极高的耦合度.其中任何一个模块的设计发生变化,都会影响其他模块做出相应修改.同时,为提升处理器芯片整体的计算能力,在单颗芯片内部需要集成更多的处理单元.庞大的处理单元数量使芯片的单体设计架构变得越发复杂,导致处理器芯片的集成度不断提高.
回顾处理器芯片设计发展的历次重大变革(如图1所示)可以看出,每一次将处理器芯片设计解耦,都会促使芯片设计实现新的跨越式发展,并催生一种全新的处理器芯片设计模式.例如,将芯片制造环节与芯片设计环节解耦有效降低处理器设计复杂度,使芯片设计公司专注于架构与电路设计,将生产、封装和测试等环节交给专门的代工厂完成,大幅降低公司的运营成本和设计门槛.与之类似,将处理器芯片内部逻辑架构的处理单元和I/O外设进一步解耦,通过IP核的形式使用户快速复用已有设计构建一个完整的片上系统(system-on-chip,SoC)的方式有利于更多的公司参与处理器芯片设计,形成当下繁荣的芯片设计产业.
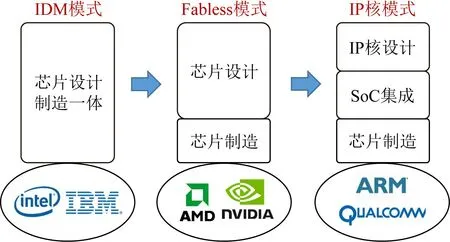
Fig.1 Revolutions in design modes of processor chips图1 历次处理器芯片设计模式的重大变革
如何降低现有处理器的单体设计耦合度,将若干复杂的紧耦合逻辑单元拆解为粒度更细、逻辑规模更小、更易于设计的微小单元或模组,有效降低各单元/模组的设计时间、成本及复杂度,并通过高效的方式实现这些松耦合单元/模组的快速组合,从而在保证性能和可靠性的前提下,以更高的敏捷度构建完整的松耦合处理器芯片架构,是解决现有处理器芯片设计复杂度居高不下的有效手段.
1.1 兼顾性能与敏捷度的处理器设计方法
现有处理器芯片设计方法属于以频率、功耗、面积等性能指标为导向的紧耦合设计方法.本文的目标是实现一种以时间、成本、复杂度等敏捷度指标为导向,并兼顾性能需要的松耦合设计方法.
将紧耦合设计优化为松耦合设计,从整体上降低设计复杂度的数学原理可以从幂次不等式进行解释.对任意a i≥0,当c≥1时,有以下关系成立:

在n相同的情况下,紧耦合的方法在性能上更好,但复杂度代价很高.松耦合的方法可以大幅降低复杂度、开发时间与成本,但拆分、组合、系统级验证的难度变大;同时,要不损失整体性能,必须提高松耦合组件的性能,或者增大n来提升设计扩展性.
1.2 松耦合处理器设计方法总体思路
将单体设计解耦,降低软件设计复杂度的方法在软件工程领域已出现了较多成功案例.传统系统软件往往采用面向过程的单体设计模式,通过自顶向下的编程模型,获得极佳的软件性能.但是随着软件系统规模的增长,面向过程设计(如操作系统内核)复杂度也呈现爆发式增长,用户进行维护和扩展都需要花费大量研发时间和人员投入,大幅降低了软件系统的易用性.为了应对上述问题,软件工程领域提出了面向对象(object-oriented)设计方法,将系统组件功能高度抽象化并封装基础软件类库(class library),通过添加继承和多态性的特性,灵活实现易维护、易复用、易扩展的软件类对象实例化,从总体上降低各功能组件的耦合程度,满足日益增长的软件系统规模发展需要.由于摩尔定律带来的硬件性能持续提升,面向对象软件设计方法更注重提升开发敏捷度,往往忽略开销增大和性能降低等问题,但面向对象设计方法仍使得软件工程领域得到了迅猛发展.
可以看出,从面向过程的紧耦合单体软件系统发展到面向对象的松耦合软件系统的内在驱动力与处理器芯片进行功能解耦的动机极为相似.因此,如何借鉴面向对象的软件设计思想,以敏捷度——开发周期、开发成本和复杂度为目标,提出全新的面向对象体系结构(object-oriented architecture,OOA),通过涵盖新型处理器体系结构和芯片的设计语言、设计模式和设计工具,在保证性能和可靠性的前提下,将传统紧耦合的处理单元结构进一步细粒度解耦并对象化,从而实现易分解、易组合和易扩展的“乐高积木式”处理器芯片敏捷设计方法,如图2所示.
1.3 面向对象处理器体系结构OOA设计
针对CPU和XPU的设计需求,OOA设计将增加新的抽象描述层次,如图3所示,简化现有处理器体系结构的描述难度,主要包括:
1)面向对象的处理器设计范式
范式是一系列规则的集合.面向对象的设计原则是在对象层次进行抽象,通过封装、继承和多态等方法将设计解耦,达到分工开发、测试和复用等敏捷开发目标.因此,面向对象的处理器设计范式是设计一系列规则,用于定义处理器架构的基本描述方法,主要包括:

Fig.2 Main objects of our proposed object-oriented architecture(OOA)图2 面向对象体系结构(OOA)设计目标

Fig.3 Key technical points of OOA design图3 面向对象体系结构(OOA)设计方法技术要点
①组合规则.定义处理器架构中细粒度对象的基本硬件结构,包括从性能和资源开销角度定义对象的粒度,确定对象的接口定义与调用方式,并设计对象接口的约束检查.
②交互规则.定义处理器架构中细粒度对象间的继承和多态等关系,定义满足时序约束的对象间硬件交互接口逻辑与信息传递方式.
③拆解规则.定义处理器架构中细粒度的对象化描述方法,归纳总结处理器必要和可选的对象,定义对象之间的控制流与数据流.
基于上述规则,最终形成通用处理器CPU的快速构建与专用处理器XPU的智能生成.同时,针对两类处理器不同的内在设计特征,面向对象的设计范式设计出发点也有所不同,主要体现在:
①通用处理器CPU.体系结构解耦及对象化描述语言和抽象方法,降低整体复杂度;实现对象级升级,持续迭代优化,提升性能.
②专用处理器XPU.面向现有领域专用的应用开发框架(如深度学习领域的Tensorflow和Caffe等)进行自上而下的设计,通过应用核心算子抽取,实现领域专用处理器架构及编译器快速自动生成;同时设计参数化硬件模板,实现应用-架构的跨层次软硬件协同优化.基于这些方法,用户可在小规模修改XPU对应操作系统设备驱动程序的情况下,使用XPU处理器芯片快速适配现有编程框架,完成领域专用应用场景的深度加速.
2)高抽象层次的芯片描述语言
基于处理器体系结构设计范式,面向处理器体系结构设计需求,提升现有处理器描述语言的抽象层次,兼顾硬件性能和开发效率,并通过连接高层语言和底层硬件的中间表示形式,方便硬件设计的复用与优化,同时通过一系列硬件综合技术和辅助代码调试工具,将体系结构参数传递到设计自动化工具.
3)融合体系结构特征的设计自动化工具
现有处理器设计流程中,底层物理设计是最复杂且耗时最长的一环.现有物理设计过程中无法有效考虑定制化处理器体系结构的特定需求,体系结构设计与物理设计无法有效协同,整个设计链条收敛困难、迭代周期长、无法有效满足定制化处理器核心芯片不断缩短的上市时间要求.
因此需要在现有设计流程中引入敏捷物理设计方法与辅助工具,将对象化的处理器体系结构特征传递到已有芯片设计自动化(EDA)工具.通过针对体系结构特征参数空间进行高效的物理设计搜索寻优,实现在物理设计中融合处理器体系结构信息,支持体系结构设计与物理设计协同优化,快速实现满足处理器设计要求的芯片物理设计实现.
本文后续将针对上述3个技术要点,着重梳理当前各领域的主要技术发展趋势,并探讨现有处理器设计方法向OOA设计目标转化存在的诸多挑战.
1.4 与现有基于IP核设计方法的比较
IP核目前主要用于为设计者提供各类总线设备或针对总线协议的辅助模块.IP核的灵活性建立在总线协议这一低耦合的前提下,且粒度较粗.目前尚不能通过IP核的组装与连接来实现复杂的细粒度控制策略和调度逻辑.
与传统面向SoC集成的IP核设计方法不同,面向对象的处理器设计范式主要针对处理器微体系结构设计场景.处理器微体系结构中各部件间耦合程度较高,不同的设计方案和架构风格兼容性较低,但又需要频繁修改以探索更高性能或更符合需求的微架构实现.面向对象体系结构OOA力图对微架构设计场景进行归纳总结,实现对高于门级及低于或等于基础模块级的硬件对象和微架构中的常见结构进行解耦及封装,为处理器体系结构设计提供清晰直观的抽象模型和开发框架,实现一种灵活的结构定制方法,从而使处理器微体系结构的设计空间探索更加高效且易于维护.
2 处理器体系结构快速构建与智能生成
现有通用处理器和专用处理器设计尚未形成OOA的设计方法,但已有部分工作开始关注处理器体系结构的快速构建与智能生成.
1)通用处理器CPU快速构建
通用处理器自动生成首先在应用定制指令集处理器(application-specific instruction set processors,ASIPs)受到广泛关注和应用,使用户可针对特定的应用定制高度优化的结构参数和定制指令[1].典型的ASIP自动化开发工具包括Tensilica的Xtensa开发工具集(Xplorer,XCC,XPRES,XTMS,XEnergy)[2]、CoWare的Processor Design、University of Campinas的Arch C[3-4]以及新思科技推出的ASIP Designer[5]等.其中ArchC是一种基于SystemC的开源体系结构描述语言,允许用户对新的体系结构进行探索和验证,并生成包括模拟器和协同验证接口在内的软件工具链;而ASIP Designer则是一套针对领域专用处理器的开发流程自动化工具.
其次,现有的通用CPU都是性能为导向的紧耦合设计方法,不同流水线需要提供完全不同的设计.美国加州大学伯克利分校的开源处理器核Rocket-Chip[6]将处理器核按IP粒度进行分解,是一个可自动完成通用处理器核、缓存、互连和完整SoC集成的自动生成框架.然而,Rocket-Chip自动生成框架仅支持顺序单发射流水线.为了实现更为复杂的多发射乱序流水线,加州大学伯克利分校又不得不重新开发了BOOM处理器核及自动生成框架[7].与此同时,北卡罗来纳州立大学在2011年开发了FabScalar[8]项目,将处理器流水级进行了封装.它以一种规范形式设计超标量处理器,使用户可便捷快速地设计出不同超标量宽度、流水线深度及用于提取指令级并行性(ILP)的结构大小的处理器.2018年Zhang等人[9]研发的CMD框架面向通用处理器架构设计,约定了一整套各模块的接口,在内部进行迭代,并在Bluespec综合器指导下修改代码设定转发与竞争端口的优先级.但CMD框架目前仅支持一种流水线设计,尚不能通过灵活配置扩展支持其他复杂流水线结构.
国内在通用处理器CPU自动生成框架的研究尚处于起步阶段.虽然国内学者近年来已设计并实现了众多基于不同指令集架构的通用处理器芯片[10-12],但这些处理器核都基于传统的Verilog硬件描述语言进行开发,尚不能针对实际应用场景进行体系结构的快速构建.中国科学院大学在基于RISC-V指令集架构的处理器核敏捷开发及快速构建领域进行了尝试,使用Chisel语言开发了单发射顺序流水线结构的NutShell处理器核[13],对处理器核的流水线结构的抽象进行了探索.NutShell处理器核在顶层对经典单发射顺序流水线结构进行了抽象,将处理器核的流水线结构进行了封装,并对部分处理器功能部件进行了封装,使得处理器的设计更为直观.但NutShell处理器核仅仅实现了单发射顺序流水线结构[14],尚不能扩展到复杂的处理器流水线结构中.此外,国内学者也尝试面向专用领域计算需求的RISC-V指令集架构扩展及多核架构自动生成等方面的研究工作,支持SHA-3加解密算法[15]及卷积神经网络算法[16-17]的加速.
2)专用处理器XPU智能生成
降低芯片设计门槛并提高芯片设计效率,本质上可以大幅度降低芯片设计成本,有助于芯片设计在更加广阔的领域应用.在这样的愿景驱动下,工业界和学术界都进行了大量的探索[18-19].
理想的XPU敏捷设计要满足至少3个方面的特征:1)大幅度降低领域专用XPU设计门槛,使得领域应用人员能够用高级语言进行XPU的设计,这样才能有更多的领域应用受益于XPU的硬件加速和能效提升[20].2)大幅度提高XPU的设计效率,缩短XPU的设计周期,才能有效地降低研发成本,满足市场的time-to-market需求.3)要保证XPU的设计质量,才能有足够的性能和能效提升.此外,优化的XPU设计才能减少芯片面积开销,降低流片成本.而目前的通用型的敏捷芯片开发技术还远远不能满足这些标准,探索用于领域专用XPU设计的新方法具有重要的意义.
可以发现,领域应用的计算核心通常都已经在通用处理器系统上做了充分的抽象,领域应用的计算核心往往也只有几个有限的计算模式,这些计算模式具有较强的可重用性[21-22].针对领域应用的这些特点,已经有很多专用的XPU设计工作,总体上可以分为3种类型:
1)针对领域应用编程框架的设计方法.其核心思想是重用已有的软件编程框架来进行硬件加速器设计,来保证硬件加速器能够无缝地支持领域应用.典型的如针对深度学习加速的自动综合算法Deep-Burning[23],初步实现了以当前使用较多的Caffe深度学习框架的神经网络模型配置文件为输入,通过算法引擎自动生成FPGA硬件网表,大幅降低了神经网络处理器的设计周期;针对图计算加速的工作如Graphicionado[24],FPGP[25],ForeGraph[26],Accu-Graph[27]等都普遍以软件图计算框架(gather-applyscatter,GAS)为基础来进行硬件优化[28-29].
2)基于可重构硬件模板的加速器设计方法.其核心思想是将应用变换成硬件模板支持的模式,然后重用或者定制可重构加速器模板,实现领域应用的加速.典型的硬件模板有用于矩阵运算或者张量运算的二维脉动阵列[30-31],以及用于Stencil计算的一维计算阵列[32].
3)基于领域专用语言(domain specific language,DSL)的自动化设计方法.本质上类似于高层次综合(high level synthesis,HLS),但是由于应用场景往往更加局限于领域应用,因此可以将领域知识一定程度地显式体现在DSL中,从而使得DSL的描述能够编译成更加高效的硬件.典型工作如HalideCL[33-34],主要是利用Halide语言描述图像类应用,结合图像计算中的多层嵌套循环特点,支持丰富的数据切割和并行优化,以生成更加高效的硬件设计.
在XPU设计过程中,充分利用领域应用知识,根据领域应用的特点如计算模式、访存特点、并行模式等,可以显著影响XPU的设计门槛、设计效率以及设计质量.然而,应用的覆盖上仍然有很大的局限性,Halide并不能支持图计算,基于编程框架的方法也难以应用到图像类应用中去.
从技术发展的角度看,面向领域应用的XPU敏捷设计方法,可以大幅度地降低XPU设计门槛并同时显著提高XPU设计效率.
3 处理器敏捷设计语言与综合工具
目前,硬件开发过程可选择多种描述方式和综合流程,但仍缺乏统一标准,使得处理器设计开发难、复用难.
1)硬件编程语言
为了提高硬件编程效率,学术界提出了多种硬件编程语言.美国加州伯克利大学于2012年基于Scala语言[35]提出了Chisel[36].康奈尔大学于2014年提出Py MTL[37],该语言是基于Python,支持多层面建模和Python3的一些特性.斯坦福大学于2017年提出的Halide-HLS[38]可以将关于图像处理的领域专用语言Halide[39]部署到FPGA上.斯坦福大学与加州大学于2020年提出的Aetherling[40]设计了基于Haskell的DSL,用来针对流处理器设计进行数据并行加速.工业界的现有高层次综合工具大部分试图将现有的C,Java等语言转化为RTL代码,另一部分则是设计新的领域专用语言针对特定情况进行优化,如Mentor Graphics于2004年发布的Catapult-C[41];Cadence提供的Stratus HLS[42]工具;Xilinx公司于2011年收购的Vivado HLS[43]和多伦多大学于2011年开发的Leg Up[44];EPFL于2018年提出的Dynamatic[45];EPFL与帝国理工学院于2020年提出的DSS[46].
SAFL[47]是函数式硬件综合的一个研究实例.另一类函数式硬件设计语言Bluespec最早的原型是Haskell[48]的一个Term-Rewriting-Systems[49]语言扩展,即以纯函数式的范式来描述电路,但是在后续发展中衍生出了独立语言前端,并具有更接近面向对象语言的特征.Handle-C[50]是C语言的一个超集,提供了语句块来描述并行的电路逻辑,相比之下另一个C/C++扩展SystemC主要进行系统级的仿真验证[51].相比基于C语言的扩展,基于C++语言的扩展[52]更能体现面向对象的特征.同时,其他具有面向对象特征的硬件设计语言,如Kuhn等人设计的独立面向对象语言前端[53]、利用Java来进行硬件规格描述的工作[54],都有效提高了硬件电路的描述效率.但是这些工作并没有达到可以综合硬件的程度.Greaves的工作[55]尝试将SAFL,Handle-C和Bluespec的表达特点都整合到Chisel中,但是不可避免有一定程度的语法开销,以及需要手动维护的部分,而且缺少真正的后端支持,比如Bluespec的调度机制仍需要进一步去复原.
2)中间表示形式
中间表示形式(intermediate representation,IR)最初应用于软件编译中.近年来,中间语言的产生常常归因于新编程语言或新编译器的提出.2003年,LLVM[56]编译器被提出,它可以将各类源码统一翻译成内置的LLVM IR.2010年,Mozilla公司提出Rust语言[57]以及MIR的中间表示.2014年,苹果公司提出了Swift语言[58]及SIL中间表示.2002年,清华大学提出一种层次化的控制数据流图[59],作为软硬件协同设计的中间表示.2012年,随着Chisel语言的提出,作为其专用中间表示的FIRRTL[60]也随之开发.
3)硬件综合流程
硬件综合流程将高级语言表示的硬件代码进行编译综合并生成底层RTL硬件代码.硬件综合流程最重要的研究方向之一是高层次综合流程,将行为级算法描述综合成硬件实现.HLS以循环和存储体的推导为主要任务[19],缺少应用面向对象思想的表达能力.HLS的主要步骤有对输入程序的编译、资源分配、指令调度、代码与硬件资源的连接等.其他代表性商业工具有Bambu[61]、Leg Up[44]、Bluespec编译器[62]、CoDeveloper[63]、Synphony C[64]、Catapult-C[41]等.HLS的其他代表性学术工作包括:UCLA于2006年提出的AutoPilot[65];Ganesh等人提出的Conservation Cores[66];IBM Research提出的基于Lime语言的Liquid Metal[67];Vernalde等人在C++的基础上引入类似Open MP的指示原语[52],从而可以从高级语言的描述中推导出硬件结构;Kuhn等人[53]设计了e语言来描述硬件规范.此外还有OO-VHDL[68],一种VHDL的面向对象拓展,其发展潜力可以类比相对有所应用的System Verilog.
基于敏捷硬件设计语言开发基础硬件类库已有一些开源社区的积累性工作,如1994年起步的由商业公司支撑的OpenCores[69]和FOSSi组织主导的LibreCores[70].这些社区也实现了类似高级语言设计的包管理器fusesoc.美国加州大学伯克利分校在处理器敏捷设计语言、基于敏捷设计语言构建通用处理器CPU以及面向对象的通用处理器体系结构的测试和验证方法等方向进行了大量的探索工作,取得了很多先驱性的创新成果[6-7,36,71-72].
4 数据驱动的处理器敏捷物理设计
通过关键参数提取及EDA算法优化,可有效提升处理器芯片物理设计效率,缩短芯片物理版图的生成时间,达到敏捷设计的目标.虽然这些工作目前尚未融合处理器体系结构的特征参数,但仍然对未来EDA工具算法的进一步发展具有借鉴意义.
1)电路建模仿真的寄生参数提取
寄生参数提取是建模仿真的基础,在物理设计多个阶段被调用,例如估算时延、检查时延约束[73]或构建PDN(供电网络)等效电路等.寄生参数提取的主要任务是计算互连线的等效电阻、电容参数,并生成RC网表.随着工艺的发展、电路规模的增大,准确快速计算互连线的电容参数(即电容提取)是寄生参数提取工作面临的主要挑战[74].为此,文献[75]提出一种基于随机行走方法的三维电容场求解器的方法.此方法有很高的准确度,并能够通过大规模并行计算进行有效加速[76-77].然而,该方法只适用于关键路径、关键模块等非全芯片规模的提取任务,其运行时间比模型匹配法慢一两个数量级.文献[78]提出了利用一种宏模型的新型随机行走电容提取技术,在处理重复版图结构时可以取得10倍以上的加速.文献[79]进一步提出了基于有限差分的可靠宏模型建立技术,使得利用宏模型的电容提取准确度更高、更稳定.此外,文献[80]提出了一种基于随机行走电容提取的保证时延计算准确的线网时延计算方法.
2)电路建模仿真的互连线网络分析
大规模电路仿真,无论是大规模供电网络的DC分析还是模拟电路的瞬态分析,都面临着计算量、内存开销、算法可靠性等方面的挑战.对于纳米工艺集成电路,电路节点数可以达到亿级规模,高性能的稀疏矩阵直接解法[81]由于过大的内存需求往往难以胜任,而一般的迭代解法[82]则很可能出现收敛性的问题,因此工业界普遍的做法是采用区域分解法或多重网格法将问题规模变小[83],同时通过并行计算技术进行加速.为减小每个子区域求解的内存开销、提高计算并行度,文献[84]提出一种基于机器学习的矩阵重排序方法,内存消耗可减少30%.文献[85]找到一种排序使得求解过程中产生的非零元数目减少20%.
3)物理设计的贝叶斯优化
贝叶斯优化因其在机器学习算法超参数优化(hyper-parameter optimization)中的成功应用[86-87]而成为近年来机器学习领域的研究热点.文献[88]提出基于贝叶斯优化的模拟电路设计参数优化策略.贝叶斯优化等基于代理模型的优化方法在连续变量的优化领域已经显示出巨大优势[89-91].但是,电路优化等诸多领域存在着大量离散的整数变量,而大部分代理模型无法有效解决此类问题.
4)物理设计的布局布线
作为芯片物理设计的核心环节,国内外专家早在20世纪60年代就开始研究芯片物理布局问题[92].到了20世纪80年代,随机优化方法特别是模拟退火法的提出为高质量的物理布局生成提供了可能[93-95].但上述方法计算代价高昂,无法有效支撑日益复杂的电路设计.20世纪90年代开始兴起的分级区域分解法[96-97]、force-directed方法[98]、非线性优化方法[99-100],以及最近十年兴起的二次优化方法[101-103]与electrostatics-based的方法[104],是物理布局研究工作中比较具有代表性的工作.物理布线过程(全局布线与详细布线)复杂耗时,针对物理布线精准的可布性建模与分析是提升物理设计效率的关键.文献[105]研究基于深度神经网络的可布性分析方法.文献[106]提出一种基于监督学习的可布性预测模型.文献[107]提出一种基于物理布局中逻辑单元管脚密度分布的预测局部布线拥堵热点的方法.
5 开源EDA工具链
如何基于EDA设计优化算法,构建完整的开源EDA工具链是近年来备受关注的研究热点.目前已有4个项目重点关注开源EDA工具链生态:美国的OpenROAD项目[108]依托DARPA的电子复兴计划,目标是研究开源EDA工具链和芯片敏捷开发方法,将芯片的设计周期和成本降低1~2个数量级;Qflow社区项目[109]是起步最早的开源EDA工具链;印度的VSDFlow项目[110]起源于教学项目,是基于Qflow进行改进的开源EDA工具链;学术界广泛参与的DATC RDF项目[111]由EDA领域颇具影响力的组织CEDA(Council on Electronic Design Automation)发起,目标是为EDA技术方案验证提供较好的工具支撑.北京大学高能效计算与应用中心(CECA)联合南京集成电路设计服务产业创新中心、中国科学院计算技术研究所等单位,也于2019年发起OpenBELT开源EDA框架.
开源EDA工具链为处理器芯片敏捷设计提供了必要的工具支持,并可结合面向对象的处理器体系结构设计和组件类库等,支撑处理器芯片从RTL到GDS的全流程设计和流片验证,是保证处理器设计快速迭代和降低芯片设计门槛的重要基础.同时,模块化和可扩展性强的开源EDA工具链也为研究处理器快速构建、处理器敏捷设计语言、综合工具和数据驱动的处理器敏捷物理设计等提供了良好的实验平台支撑.例如,可在芯片体系结构设计中引入部分特性(如指导语句等),以供物理设计工具识别并进行相应优化,并指导物理设计阶段快速达成更优的芯片性能、面积和功耗.最后,以开源EDA为抓手,辅以高质量软件开发流程和开源社区协作方法,可将处理器芯片敏捷设计相关的技术和方法转化到开源EDA工具中,最终形成完整的系统性的芯片敏捷设计解决方案.
因其基础性和平台性,构建开源EDA工具链是一个复杂的系统工程,这体现在问题拆解和抽象、关键问题定义、整体框架设计、具体问题优化和工程实现等多个方面.同时,为提升开源EDA工具链的性能、更好地支持处理器芯片敏捷设计,EDA算法与机器学习、数值计算、运筹优化和高性能计算等方向的交叉和优化,也为开源EDA工具链的整体设计和实现提出了巨大挑战.
6 挑战问题
通过本文的分析可以看出,处理器芯片的设计语言、设计工具和体系结构设计方法虽已取得极大突破,但与最终实现基于面向对象体系结构OOA的敏捷设计方法相比,仍存在较多尚未解决的挑战和关键问题,主要包括:
1)如何实现处理器功能与结构的细粒度解耦?
面向对象体系结构设计方法的核心是将处理器内部功能和结构按设计需求,实现细粒度功能部件解耦,抽象出一系列可分解、可组合与可扩展的体系结构功能组件.
针对通用处理器CPU,需要重点考虑4个问题:①考虑如何把握对象分解的粒度,兼顾各硬件对象的实现复杂度和组合后对性能的影响.②需探索如何实现适应各种不同处理器流水线的通用设计模板,兼顾不同流水线功能和结构差异.③要思考如何根据设计目标和性能及面积约束,有效限制架构组合的搜索边界.④在架构分解的过程中,需充分考虑如何抽取关键体系结构参数及行为,形成面向对象的敏捷形式化验证方法.
针对专用处理器XPU,其性能潜力往往依赖于领域应用中高频操作的划分粒度和划分方式,如何从庞大的任务划分空间中探究专用处理器的性能加速上限,并找到面向应用的自动化任务分割与重用方法是第一个重要科学问题.其次,现有的模板化加速器设计方法往往与领域应用知识紧密耦合,如何对加速器硬件模板进行预设计,平衡硬件模板的专用性与通用性,从而同时满足加速效率与应用覆盖率的要求,是亟待解决的科学问题.最后,领域应用的专业知识和加速器设计存在巨大的鸿沟,缺少高效的协同方法来同时优化加速器设计参数与领域应用的编译选项,针对跨层设计的巨大且离散的设计空间进行自动优化也是一个重要的科学问题.
此外,面向对象的细粒度分解方法也会对现有的处理器开发模式及仿真验证环境产生影响.细粒度解耦方法会产生海量的处理器体系结构模组,并可能由众多研发团队分布式协同开发,从而与互联网软件的开发模式具有极为相似的特征.每个团队搭建私有的开发仿真验证环境会带来维护开销大、设计难以同步、迭代收敛速度慢等问题.因此,如何借鉴现有互联网软件开发的Dev Ops(Development和Operations的组合词)思想,通过构建基于云计算的开发服务平台和公共仿真验证环境,促进不同团队代码开发、合并集成和验证测试管理等多个阶段的沟通、协作与整合,形成面向对象的处理器开发“众包模式”,是应对未来海量细粒度对象模组的潜在有效开发方法.
2)如何实现面向对象的处理器设计高层抽象?
对处理器设计进行抽象依赖于硬件设计语言.但现有硬件描述语言仍无法为处理器设计提供敏捷易用的高层次抽象.①传统硬件描述语言(如Verilog HDL等)、新型硬件构造语言(如Chisel,Py MTL等)以及使用C/C++描述的高层次综合语言由于语义上的鸿沟,尚无法兼顾处理器开发效率与硬件性能.②现有处理器硬件设计语言缺乏统一中间表示形式,还无法成为连接前端处理器设计语言和后端硬件结构的桥梁,不易于硬件设计的复用与优化.③不同层次和行为的硬件描述语言的编译流程千差万别,导致现有硬件综合流程难以兼容不同层次和不同行为的语言,且不易于调试.
3)如何在设计自动化工具中深度融合体系结构特征?
以应用驱动的定制化专用处理器芯片,面临体系结构复杂、电路规模庞大、制造工艺复杂等诸多问题.作为芯片设计过程中最复杂的阶段之一,物理设计耗时、迭代收敛难度巨大.现有处理器芯片设计流程冗长、复杂,上层体系结构的设计与芯片底层物理设计是独立的环节.体系结构设计过程中无法有效考虑体系结构变化所引发的芯片物理实现中性能指标参数的影响,导致芯片设计迭代次数多、收敛难度大.另一方面,由于体系结构特征的缺失,体系结构的变动往往导致物理设计迭代从零开始,无法实现高效的设计迁移,迭代代价巨大.因此如何通过在物理设计中引入体系结构的特征信息是实现敏捷物理设计流程的关键环节.基于本文提出的OOA处理器敏捷设计方法,体系结构设计在对象级的改变,有望传递给后端物理设计进行快速增量式优化;同时,物理设计在对象级的性能参数评估,也可以传递给体系结构做早期的处理器设计空间探索,从而可以驱动体系结构设计与物理设计的协同推进,逐步实现处理器芯片端到端全自动化流程的敏捷设计.
人工智能在集成电路EDA领域的价值与潜力已成为业界的共识.人工智能技术在EDA的各个关键环节,特别是建模仿真与设计优化环节,正在引发颠覆式创新.如何充分利用人工智能方法,是实现体系结构特征与EDA工具深度融合的重要手段.首先,在体系结构与微体系结构特征提取等研究领域,人工智能方法已在处理器设计参数优化、性能预测、编译优化过程中起到重要作用.针对OOA设计方法的特点,在处理器芯片的体系结构设计流程中,使用人工智能技术辅助通用处理器CPU的关键架构特征抽取、缩减OOA体系结构设计探索空间加速设计收敛是实现OOA敏捷设计的关键;同时,如何使用深度增强学习、生成模型以及Auto ML等新兴人工智能技术,实现更为激进的“端到端”体系结构特征提取与设计方法,也成为影响专用处理器芯片XPU设计成败的关键.其次,如何基于人工智能技术,在芯片设计各阶段EDA工具中融合体系结构特征,最终实现“无人参与闭环”的处理器芯片智能设计与敏捷设计,也是未来EDA方法与工具亟待突破的重点.
7 总 结
如何突破现有处理器设计方法的壁垒,在保证性能和可靠性的前提下,降低通用处理器CPU设计复杂性、成本和设计门槛并有效应对专用处理器XPU场景多样性并缩短设计周期,是破解CPU和XPU处理器芯片设计难题的关键.本文提出一种面向对象处理器体系结构OOA,力图形成以降低时间、成本和复杂度为主要导向的处理器芯片敏捷设计新方法.本文针对OOA所涵盖的设计范式、设计语言及设计工具,对目前处理器体系结构快速构建与生成、处理器敏捷设计语言及敏捷EDA设计工具等研究现状进行梳理,并对未来实现OOA设计方法可能面临的技术挑战进行分析.作为一个跨学科问题,处理器芯片能否在新的OOA设计范式之下,大幅降低芯片设计的技术门槛,需要相关领域学者共同探索,一起促进处理器芯片生态的良性发展.
