高能物理实验径迹系统流式数据获取框架的研究
2021-06-16章红宇朱科军王之滨陈玛丽祁辉荣
吴 冶 章红宇 朱科军 王之滨 陈玛丽 祁辉荣
1(中国科学院高能物理研究所核探测与核电子学国家重点实验室 北京100049)
2(中国科学院大学 北京100049)
高能物理实验旨在研究基本粒子及其相互作用,通过获取和分析高精度、高统计量的实验数据,发现新粒子或测量已知粒子的特性。随着高亮度加速器和高精度探测器的发展,高能物理实验的规模不断增大,实验数据量急剧增长,海量数据的获取、处理及分析将更具挑战性。中国科学家在2012年9月提出了用于精确测量希格斯粒子特性的环形正负电 子 对 撞 机(Circular Electron Positron Collider,CEPC)方案,其核心探测器由硅像素顶点探测器、内部硅径迹室、时间投影室、外部硅径迹室、量能器和缪子探测器等多个子探测器组成,结构如图1所示。其中,硅像素顶点探测器和时间投影室探测器是通道数最多、产生数据量最大的两个子探测器。

图1 CEPC核心探测器模型Fig.1 CEPC core detector model
根据CEPC概念设计报告[1]中的设计参数计算,当一级触发为100 kHz时,CEPC所有探测器原始读出的数据率约为2 TB·s-1,其中硅像素顶点探测器约有6.90×108个通道,读出数据率约为830 GB·s-1,时间投影室(Time Projection Chamber,TPC)约有2×106个通道,读出数据率约为500 GB·s-1,这两种探测器的数据将占到CEPC数据读出总带宽的65%。
CEPC所需要的硅像素径迹探测器、时间投影室径迹探测器及其激光校正分别获得了科技部重点研发项目和国家自然科学基金重点项目的资助,开展前期预研。作为以上探测器预研课题的一部分,为应对这两种探测器超高数据率的数据采集和处理需求,本文尝试结合目前成熟的大数据技术,进行新型数据获取软件的研究和探索,并在相关课题的原型机实验中进行测试。
数据获取系统(Data Acquisition System,DAQ)是高能物理实验重要的子系统之一,其功能包括探测器电子学数据的高速读出、事例组装、事例筛选及运行控制与监测等。大型高能物理实验的数据获取系统为大规模分布式系统,除了高带宽的数据读出具有挑战性外,对每秒TB量级的数据流进行在线处理也具有相当大的挑战性。
在高能物理实验中,研制超大数据流、高性能、高可用的分布式数据获取软件,往往需要一个团队多年的努力。
近年来,计算机领域中大数据处理技术发展迅速,超大数据流的处理在工业界已逐渐形成一套事实标准,即Hadoop[2]大数据处理框架。Hadoop框架是一个由Apache基金会开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题。Hadoop框架的核心是分布式文件系统(Hadoop Distributed File System,HDFS)[3]和资源管理器(Yet Another Resource Negotiator,YARN)[4]。
作为一种有意义的尝试,本文通过分析高能物理实验数据获取软件各项功能需求的特点,对比研究了大数据框架的各类组件和技术,引入了Hadoop框架中的一些组件,在其基础上研制开发了一套新型的高能物理数据获取软件框架BigDataDAQ(以下简称BDDAQ),成功应用于时间投影室探测器的模型实验,并在实验室的服务器集群上对BDDAQ框架进行了性能测试。
1 BDDAQ软件架构
大型高能物理实验的DAQ系统是一套分布式的软件系统,它通过信息传递使得各个分散的、相互独立的功能模块能够协调工作,完成物理数据的读出、分发/重组和在线数据处理。
ATLAS是欧洲核子中心大型强子对撞机(Large Hadron Collider,LHC)上的4个探测器之一,也是迄今为止世界上最大的探测器,TDAQ[5](Trigger DAQ)是其数据获取系统框架。
TDAQ主要包括两个部分:数据流软件(Data Flow Software)和在线软件(Online Software)。数据流软件包括读出系统模块(Readout System Module)、事例组装模块(Event Building Module)、多级事例筛选模块(Event Filter Module)和数据存储模块(Data Storage Module)。在线软件服务于数据流和整个实验系统的各个方面,提供控制、监测和错误显示等各种服务。
BDDAQ软件在系统整体架构上也遵循TDAQ的设计思路,即同样分为数据流软件和在线软件两部分。但是在技术实现上有所不同。
相比较于TDAQ使用内存做缓冲层,BDDAQ数据流软件在读出模块和事例组装模块之间增加一个消息队列模块,使用内存和硬盘一起作为数据读出和处理的缓冲层,可以承受在超大数据率下网络波动造成的数据累积,更大程度地防止由于内存溢出导致的DAQ软件崩溃。BDDAQ在线软件一部分功能通过Hadoop的相关组件的内置功能实现,减小了在线软件的设计难度。
BDDAQ软件整体的框架设计见图2,其中FEE(Front End Electronics)部分是前端电子学系统。

图2 BDDAQ软件框架Fig.2 BDDAQ software framework
BDDAQ数据流软件参考了高海拔宇宙线观测站(Large High Altitude Air Shower Observatory,LHAASO)实验的在线实时分布式数据处理经验[6],主要功能由读出组件模块(Readout Service Module)、消 息 队 列 组 件 模 块(Message Queue Module)、事例处理任务构建与发布组件模块(Job Construction and Submission Module)、分布式计算引擎模块(Distributed Processing Engine Module)和事例存储模块(Event Storage Module)实现。
BDDAQ在线软件功能由配置模块(Config Service)、信息协调模块(Information Coordination)、资源调度模块(Yarn)、运行控制模块(Run Control Service)和在线可视化模块(Online Visualization)实现。
BDDAQ软件在数据流软件和在线软件两部分都引入了Hadoop框架提供的分布式基础组件,再结合高能物理径迹探测器数据流的特点和需求进行本地化开发。接下来本文将从数据流和在线软件两部分介绍整个BDDAQ软件。
2 BDDAQ数据流软件
数据流软件面向的对象是高能物理实验数据流,主要负责对前端电子学输出数据流进行读出,进而完成事例片段的同步组装、在线数据处理和数据存储等任务。BDDAQ根据以上功能需求设计实现为读出模块、消息队列、事例处理模块和存储模块。
2.1 BDDAQ数据流处理需求分析
探测器电子学输出的是TCP协议数据流,读出模块主要功能是读取数据流并将数据流拆分为一个个单独的数据包,这一步骤也称作读出分片,最后将一个个数据包作为消息发送到消息队列。未来硅径迹探测器和时间投影室产生的数据流可能需要多达近万个连接进行数据读出,需要使用NIO(Nonblocking I/O)模式,在单个线程内轮询处理多个TCP连接。
消息队列用来接收读出模块发送的数据包,并向事例处理模块提供数据,是数据读出与处理之间的缓冲层。
在大数据处理领域,数据流处理模型一般分为批处理和流处理。批处理模型先缓存一批数据再进行计算,适用于实时性要求不高,但对数据的准确性和全面性要求更高的场景。流式处理模型更注重对流式数据的实时分析,数据以流的方式到达,携带了大量信息,经过实时处理之后只有小部分的流式数据被保存在有限的内存中。
高能物理实验对数据流的处理有三种模式:1)数据包映射模式:此模式中输入是单个数据包,根据映射规则输出一个或多个数据包,这一过程不涉及其他数据包的信息,可以看成是一种流处理过程。2)事例组装模式:此模式中输入是满足组装条件的一组数据包,根据组装规则输出一个或多个事例,需要等待所有满足组装规则的数据包到达,可以看成是一种批处理过程。3)事例筛选模式:此模式中输入是一个完整事例,根据物理算法对事例进行计算,输出一个布尔值,根据布尔值来对事例进行过滤,是一种流处理过程。
由于高能物理实验中DAQ的数据流处理既有流处理过程又有批处理过程,因此BDDAQ需要“批流一体式”的数据流处理架构。
2.2 读出模块
BDDAQ的读出模块功能由Readout Service组件实现,整个Readout Service组件主要功能有:处理多个TCP连接;从TCP连接的数据流中解析出单个数据包并验证数据格式的正确性和数据包的完整性;将已验证数据包发送到内存缓冲队列;从内存缓冲队列获取数据发送到消息队列。下文将分别介绍每个功能的实现,最后介绍整个读出模块的系统架构。
2.2.1 处理多TCP连接的网络服务器
BDDAQ软件使用NIO网络通信模式,Java的NIO模式在Linux底层实现是使用epoll[7]不断轮询所负责的已注册socket,当某个socket有数据到达,就通知用户线程进行处理。
Netty[8]是一款基于Java的NIO客户端/服务器编程框架,BDDAQ使用Netty快速开发了高性能、高可靠性的网络服务器,实现了前端电子学的网络数据读出。
BDDAQ采用池化直接内存(Pooled Direct Byte Buffer)作为IO操作的缓冲区,以提高运行效率。池化直接内存的内存管理机制参考了Jemalloc[9],即提前申请一大块内存空间作为预分配内存池,然后将这块内存空间分割为很多相等大小的页(Page)来进行管理,根据申请的内存大小使用不同的分配策略从预分配内存池中分配内存,销毁内存时只是将准备销毁的内存释放回预分配内存池,等待程序运行结束再对预分配内存池统一销毁,大大提高了内存分配效率。
2.2.2 数据流解析验证
高能物理实验中的前端电子学一般都进行数据零压缩,因此发送的数据包都是变长的,且具有事先约定的数据格式。BDDAQ设计实现了解码器父类(Length Field Based Frame Decoder)进行数据包的解码,校验器父类(Frame Validator)对解码出来的数据包进行校验。对于不同的探测器只需要根据探测器数据格式的各自特点继承解码器和校验器,编写新的实现即可。
2.2.3 有界内存缓冲队列
数据流解析验证生成大量通过验证的数据包,这些数据包需要被传送到后续的Kafka[10]集群中。数据流解析验证过程可以被看作是生产者,把数据包发送至Kafka集群的过程可以被看作是消费者,由于这两个过程的数据处理速率可能会产生波动,因此两者之间需要内存缓冲队列作为缓冲层,Java中的阻塞队列性能较低,BDDAQ软件使用了开源无锁的高性能缓冲队列Disruptor[11]。
2.2.4 读出组件的结构说明
读出组件(Readout Service)的系统构成如图3所示,它采用反应器(Reactor)事件驱动模式,注册了一个单独的连接事件处理线程(Reactor Thread)作为TCP连接分发器,一个NIO工作线程池(NIO Work Thread Pool)来处理TCP连接读数据事件,一个Kafka生产者线程池(Kafka Producer Thread Pool)负责发送数据包到Kafka集群。
整个处理流程如下:
1)多个TCP客户端连接注册到Reactor Thread上,此线程只处理TCP连接的accept事件,并将处理完成的TCP连接轮流绑定到NIO工作线程池的某个线程上。
2)NIO工作线程池中的线程按照处理流水线(Channel Pipe Line)的流程运行。首先循环检测绑定到自身的TCP连接是否有读事件,检测到读事件之后,读取数据并将数据传递到解码器解码、校验器验证,最后将验证正确的单独数据包放入Disruptor内存缓冲队列。
3)Kafka生产者线程池中的线程从Disruptor内存缓冲队列读取数据并发送到Kafka集群。
2.3 消息队列模块
BDDAQ软件使用消息队列(Message Queue Module)的主要目的是:平衡电子学数据读取和流式平台数据处理的数据速率波动;作为整个读出模块与事例处理部分的缓冲层;将读出模块与流式事例处理模块解耦。
这种解耦架构的优势是将高能物理数据流的数据包分片阶段和处理阶段拆分成两个互相独立的组件,各自实现自己的处理逻辑,通过消息队列提供的消息写入和消费接口实现对消息的连接处理。这样的设计可以降低系统开发复杂度,提高系统稳定性,有利于之后的扩展升级。

图3 Readout service组件结构Fig.3 Components structure of readout service
BDDAQ软件采用Kafka集群实现分布式消息队列,使数据获取系统具备了如下特点:
高吞吐率:Kafka使用Linux系统提供的零拷贝技术减少消息的网络传输时间,提供端到端的消息压缩传输和磁盘顺序写入,大大提高了写入性能,实现了高吞吐率。
高容错、高可用:允许配置多副本,将副本均匀地分配到不同机器存储,多副本之间有消息同步机制,当集群某个机器进程意外退出后,集群能够自动发现处理,并继续提供读写服务。
可扩展性:能够方便地增减消息队列集群规模。
Exactly-once语义:即使消息发送者重试发送消息,消息消费者也只会消费一次消息。
事务能力:消费者消费时,在一个事务里面,事务执行成功则认为消息被消费,否则事务将回滚,需要重新处理。
2.4 流式事例处理模块
从§2.1的需求分析可知,BDDAQ软件的事例处理模块(Streaming Event Process Module)是“流批一体式”的分布式数据流处理系统。大数据框架中常见的分布式流处理引擎有Storm、Spark Streaming和Flink[12]等。其中Flink是开源社区中一种集高吞吐、低延迟、高性能三者于一身的分布式“流批一体式”数据流处理框架。
Flink将所有的输入数据都视为数据流,其中流式处理代表无界的数据流处理,批处理代表有界的数据流处理。Flink具有如下优点:1)函数式原语;2)支持有状态计算(Stateful Computations);3)支持事件时间(Event Time)概念;4)支持高度灵活的窗口(Window)操作。因此BDDAQ软件选择了Flink作为分布式数据流处理引擎。
2.5 事例处理任务构建与发布模块
事例处理任务构建与发布模块(Job Construction and Submission Module)主要负责根据不同探测器电子学事例处理模块的处理逻辑构建相应的Flink处理流程,并打包成Flink作业上传到Flink计算集群中运行。
通过Flink的函数式原语可以根据不同电子学产生的数据特点方便地编写不同的数据流处理逻辑。
通过Flink有状态计算可以获取流处理过程中的实时统计数据,用于实时在线监测。
BDDAQ软件通过Flink的窗口功能实现了不同的事例组装逻辑。在高能物理的事例组装过程中,组装条件一般分为两种:
1)按触发号组装:对于具有公共触发信号的多个子探测器产生的数据,将所有触发号相同的子探测器数据包组装成完整的事例。BDDAQ软件使用Flink对数据包内的触发信息进行KeyBy分组操作,开启一个指定大小的计数窗口(Count Windows),触发信息相同的数据包被缓存到同一个计数窗口,当这个计数窗口的数据包数量达到指定大小后,对这一批数据包按照提交的运算逻辑进行组装操作,输出一个事例。
2)按时间片组装:将数据包产生的时间线(Time Line)分为很多时间单元,将某个时间单元内的所有数据包组装成事例。BDDAQ软件使用Flink的事件时间(Event Time)概念,将事件时间设为数据包内的时间戳字段,之后开启时间窗口(Time Windows)。对于每一个数据包,根据其时间戳信息划分到相应的时间窗口,并通过Flink的watermark概念来灵活地平衡处理数据的延时和完整性。当时间窗口结束时对本时间窗口的数据包做组装处理。
事例筛选功能是对每一个组装好的完整事例或时间片数据依照物理筛选算法进行计算,决定是否保留该事例或挑选感兴趣的事例,若需要保留,则将该事例传输至后续的存储模块。BDDAQ软件通过Flink的过滤算子实现了事例筛选功能。
2.6 存储模块
BDDAQ的事例存储模块(Event Storage Module)是对事例进行持久化存储。现有的存储方法是将事例以文件形式保存到数据中心的中央存储系统。当需要搜寻历史事例进行事例分析或进行一些可视化绘图操作时,需要从中央存储系统中读取相应文件,再进行分析。通常这类搜寻事例的速度很慢,为此BDDAQ软件在保留现有的存储方法外,增加了分布式存储和分布式数据库两种方式来存储部分事例,在超大数据量下可以通过索引工具迅速搜寻到相应事例。
2.6.1 分布式文件系统
分布式文件系统(Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连;或是若干不同的逻辑磁盘分区或卷标组合在一起而形成的完整的有层次的文件系统。
BDDAQ软件使用了HDFS作为分布式文件系统组件。HDFS是基于流数据模式访问和超大文件处理的需求而开发的,可以运行于廉价的商用服务器上,具有高容错、高可靠性、高可扩展性、高获得性和高吞吐率等特征,为海量数据提供了安全可靠的分布式存储。
2.6.2 分布式数据库
分布式数据库主要用来存储数据流处理过程中的一些中间结果和部分事例,方便在线软件查询实时状态,以及进行历史数据的在线可视化。BDDAQ软件使用的分布式数据库由Hive和Hbase两种组件构成。
Hive[13]是基于Hadoop的一个数据仓库工具,支持结构化查询语句(Structured Query Language,SQL)[14]进行数据关联查询。HBase[15]是一个开源的非关系型分布式数据库,只支持主键数据查询。
如果用户不需要进行大规模的数据关联查询则BDDAQ软件将直接使用Hbase存储事例。反之,先将数据存储成Hive数据仓库表的形式,之后构建SQL语句对Hive表进行关联查询,并将查询结果存储到Hbase表中。
3 在线软件
在线软件(Online Software)是负责对整个数据获取系统进行灵活的运行控制、软硬件配置、在线监控、进程管理和信息共享等的分布式软件系统,为数据流软件提供保障和监控功能,并向外部提供信息查询接口。
BDDAQ在线软件由5个模块构成:
1)配置模块(Config Service Module):此组件提供用户层面的软硬件配置服务和前端电子学的配置服务,并集成到图形化用户界面程序(GUI)中。
2)运行控制模块(Run Control Service Module):此组件对整个数据获取系统各个模块的运行流程进行管理。
3)在线可视化模块(Online Visualization Module):此组件通过读取分布式数据库的数据来发布数据获取流程中的统计直方图、单通道信号波形重建等可视化图形。
4)信 息 协 调 模 块(Information Coordination Module):此组件使用了Hadoop的Zookeeper组件作为信息协调中心,实现了控制信息的传递、运行信息的汇总以及运行状态监控等功能。
5)资源调度模块(Yarn):此组件使用了Hadoop的集群资源框架Yarn来统一向数据流处理过程中的各进程分配资源,开启任务,管理每一个进程,提供进程日志查看,进程终止服务,实现了灵活的资源控制管理、作业调度功能、进程的管理和监控。
4 BDDAQ软件在LTPC实验中的应用
作为径迹探测器的时间投影室(TPC)是一种气体探测器,在建造和运行过程中,其内部结构应力、外部温度、气压的变化等因素均会影响到径迹的精确测量,需要进行实验标定。激光标定是在TPC探测器实验中的一种非常实用和有效的标定方法。LTPC实验[16]是以GEM气体探测器为原型机进行激光标定实验的研究项目,整个原型机的结构如图4所示。
LTPC实验原型机采用266 nm紫外激光束结合高精度微反射镜阵列产生42束窄激光束,设计激光沿Z方向共9层分布,其中横向的6层只有一束激光,纵向的3层中每层12束激光,LTPC原型机激光分布如图5所示。

图4 时间投影室探测器结构Fig.4 TPC detector structure
LTPC读出端盖的通道模型如图6所示。LTPC探测器电子学共有20块数据采集板,每块采集板64个通道,各通道对过阈信号进行40 MHz时钟的波形采样,输出波形数据,电子学系统整体读出速率最大可达100 MB·s-1。
LTPC实验电子学数据流输出构成为:每一次触发信号到达,会先输出一个触发时间包,之后每个有响应的通道输出一个触发采样包,再等待下一个触发信号到达。
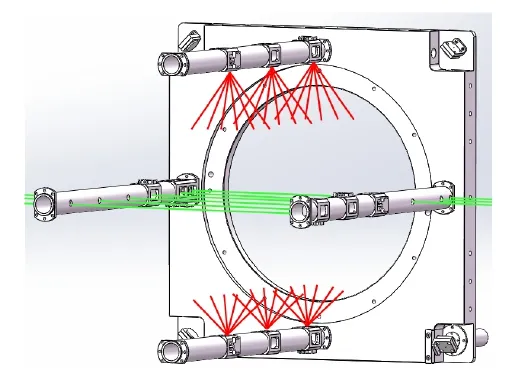
图5 LTPC原型机激光光路分布Fig.5 Laser distribution of LTPC prototype

图6 LTPC读出端盖通道分布模型Fig.6 Distribution model of LTPC read-out end-plate channel
触发采样包的采样点采集过程为:触发信号到来后电子学通道开始等待信号过阈,在信号过阈后开启一定长度的采样时间窗口,一个采样时间窗口内会收集不同平面内平行的激光径迹的采样信号。
图7 、8分别为触发时间包和触发采样包具体数格式。

图7 LTPC触发时间包详细数据格式Fig.7 Detailed data format of LTPC trigger time packet
事例处理流程分为以下三步:1)数据包转换过程:根据数据包格式中特定字段的标识,区分触发时间包和触发采样包。如果是触发时间包则输出时间戳;如果是触发采样包则根据数据包的通道位置将多个平面平行激光径迹上的过阈波形采样点区分为不同组,对于每一组采样点输出一个包含触发号信息、激光径迹信息、本组采样数据的数据包。2)事例组装过程:将同一个触发信号下的同一条径迹的数据包组装为一个事例。3)事例筛选过程:对一个完整事例中各响应通道的信号波形进行寻峰操作,得到每一个响应通道的信号幅值,相邻通道的信号幅值通过重心法计算得到重心位置,再判断这一完整事例中所有重心的分布是否与激光径迹相符合,进行事例筛选。
LTPC模型系统数据获取软件基于BDDAQ软件框架编写,为了方便实验人员操作将参数配置、运行控制以及数据可视化功能都集成到了如图9所示的图形化软件界面。

图8 LTPC触发采样包详细数据格式Fig.8 Detailed data format of LTPC trigger sample packet

图9 LTPC DAQ用户图形控制界面Fig.9 Graphical user control interface of LTPC DAQ
LTPC的事例先存储到Hive数据仓库,之后根据需求进行SQL查询得到结果子集,最后将结果子集存储到Hbase数据库。图10所示的LTPC探测器可视化模型是根据实验原型机读出端盖各通道几何尺寸等比例绘制的视图,图中每一个矩形小块代表一个探测器通道,其颜色深浅表示该通道电子学采样波形的峰值大小。
在可视化模型窗口内点击某个击中通道,会弹出一个窗口,显示该通道的采样信号波形图,如图11所示。
LTPC实验数据可视化功能除以上两种功能外还包括:取数状态监测、数据质量监测报告、多种物理量的统计直方图。由于可视化所需要的事例都存储在分布式数据库,因此搜寻事例的速度快,可视化功能的响应时间都在秒级,性能远远高于读取数据存储文件再进行分析并搜寻事例的传统方法。

图10 LTPC探测器可视化模型Fig.10 Visualization model of LTPC detector

图11 通道采样波形Fig.11 Vaveform of channel sampling
使用分布式数据库存储部分事例可以大大提高事例的查询性能,为抽样数据分析、可视化功能、实时数据监测等需求提供了有力支持。
实验结果不仅表明BDDAQ架构的可用性,也表明结合大数据技术处理高能物理实验数据流的技术路线是可行的。
5 模拟数据源性能测试
由于LTPC原型机通道数较少,实验室进行的激光校准实验事例率较低,无法直接测试出BDDAQ软件的性能指标。因此使用实验室服务器模拟数据源,对BDDAQ软件进行了数据处理性能的测试和评估。
在操作系统为Centos7的15台高密度服务器上部署了BDDAQ集群,其中1个节点作为整个集群的控制节点,不参与实际运算,剩下14个节点作为工作节点,所有节点通过万兆网线或光纤连接到交换机。整个集群由8台型号A和7台型号B的计算机构成,具体硬件参数见图12。

图12 集群计算机硬件参数Fig.12 Computer hardware parameters in the cluster
整个集群的工作节点共560个CPU核。每台服务器保留20%的内存,约38.4 GB自用,剩下的内存分出33.6 GB用于运行Hadoop相关进程,剩下120 GB内存分配给Yarn组件进行管理,整个集群一共1.64 TB内存可用于YARN任务的内存分配。
为了测试整个集群的数据处理速率上限,Kafka和Flink组件部署在全部工作节点上,Flink作业的事例处理流程为读取Kafka集群的消息到内存后,进行简单的数据包映射处理之后存储数据到文件。采用Kafka自带的专用测试工具测试,当消息大小为8 kB时,Kafka集群中单个Kafka节点写入性能极限为每秒76 800条消息,吞吐量达到600 MB·s-1,集群整体写入带宽上限为8.7 GB·s-1。BDDAQ集群的数据处理带宽受制于这一Kafka集群的总写入带宽。
BDDAQ框架性能测试使用的数据包长度为7~8 kB,数据包头带有包长字段。设置Kafka集群消息保存时间1 min,超时之后消息自动删除。在集群中选择1台服务器启动读出模块连接模拟数据源,读出分片线程和Kafka生产者线程数为4:4时,数据包分片和发送速度达到一致,读出模块稳定运行的吞吐率达到2 GB·s-1。
单个模拟数据源在保证每一读出节点带宽稳定在2 GB·s-1左右的情况下,最多可以同时向4个读出节点发送数据。此时整个BDDAQ集群的数据处理带宽达到8 GB·s-1,基本接近Kafka集群写入性能上限。
在上述测试条件下,通过观察Kafka集群中消息的累积速度来判断整个BDDAQ的运行状态,在长达3 h的运行测试实验中,Kafka集群的消息累积量在10万条左右小范围波动,可以通过每条数据大小乘以10万条再除以数据处理带宽,计算出约为100 ms的数据量累积。因此,实验结果证明了BDDAQ系统可以保持在低延时状态长期稳定运行。
目前,由于实验室条件限制,测试实验数据率在GB量级,但是BDDAQ使用大数据集群的优势就是在于可以很方便地通过水平扩展集群规模来提高整个集群的数据获取和处理能力。
6 结语
本文以未来大型高能物理实验径迹探测器的数据获取系统为项目背景与研究目标,为多连接读出和并行处理设计实现了一套分布式数据获取系统BDDAQ。该系统结合Hadoop大数据技术,引入了一些成熟的开源组件,简化了分布式数据获取软件的开发流程,降低了分布式数据获取软件的开发难度,提供了灵活的集群水平扩展能力,实现了简洁直观的WebUI控制界面。
使用BDDAQ软件架构,按照LTPC实验需求编写的DAQ软件,可以充分满足该实验对在线数据处理和快速数据质量检查的需求,大大提高了实验数据处理和可视化的速度,软件部署方便快捷。BDDAQ集群性能测试结果表明:BDDAQ架构下集群中的单台机器数据处理性能接近于Kafka组件的写入能力上限,未来根据实验需求可以通过水平扩展服务器数量来提升整个集群的数据处理带宽。BDDAQ架构作为流式数据获取框架为高能物理实验数据获取系统提供了一种可行的解决方案,也可为未来自行研制流式数据处理架构提供借鉴。
