基于GPU并行计算的X射线动态显微CT的快速重构
2021-06-16谢红兰杜国浩许明伟薛艳玲肖体乔
张 园 谢红兰 杜国浩 许明伟 薛艳玲 肖体乔
1(中国科学院上海应用物理研究所 上海201800)
2(中国科学院大学 北京100049)
3(中国科学院上海高等研究院上海同步辐射光源 上海201204)
X射线动态显微CT成像具有较高穿透性、高空间分辨和快时间分辨的特点,为开展不透明样品三维微观结构演变动力学机制的探究提供了研究平台[1-3],在生物医学、材料科学、考古等领域已有大量应用,如科学家们利用X射线动态显微CT原位观察载荷下材料和结构的动力学过程[4-6]、原位研究昆虫马蛉呼吸过程中的气囊收缩特性[7]、原位分析基拉韦厄峰火山碎屑在不同压力下气泡产生的复杂变化[8]、原位观察超声热浪导致的组织根部断裂和枝晶的断裂和增殖过程[9]等。近年来,随着第三代同步辐射光源的广泛使用,光源通量得到了极大的改善,为实现X射线动态显微CT成像提供了条件[2]。上海光源X射线成像组基于长工作距离显微透镜系统和互补金属氧化物半导体(Complementary Metal-Oxide-Semiconductor,CMOS)数字高速相机开发了快速X射线成像探测器,在弯铁白光下,动态显微CT成像时间分辨率可达25 Hz(每秒采集25套CT数据)[1]。目前X射线成像线站的CT重构采用基于CPU串行重构程序。对于一套800个投影的CT数据,每帧投影大小为1 024×1 024,按目前的重构程序重构需要24 min,一天的用户实验产生的CT数据量(约500套CT)则需要重构200 h,CT重构速度远比原始数据的产生速度要慢。因此,CT重构速度慢造成的原始数据积压问题成为上海光源X射线成像线站遇到的瓶颈,如何实现快速显微CT重构是本文研究的重点。
CT重构属于计算与数据密集型问题,这类问题可以分解成较小的独立单元并并行计算[10]。2010年以前,国内外是通过依靠并行硬件平台来加速CT重构,其中使用广泛的有专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field Programmable Gate Array,FPGA)[11]、数字信号处理器(Digital Signal Processor,DSP)[12]等,但此类方案硬件花费昂贵且软件开发难度大。2010年后,图形处理器(Graphics Processing Unit,GPU)因其多核架构、可大规模并行化的特点,在高性能计算领域得到广泛应用,随后,NVidia的CUDA[13]和Khronos的OpenCL[14]等开发API大大简化了基于GPU并行开发的难度。很多国内外团队借助设备相对低廉的优势,利用开发平台和工具API实现了基于GPU的CT重构[15-17],常用的重构开源框架有TIGRE[18]、TomoPy[19]、ASTRA[20]、UFO[21]、PyHST[22]等。
上海光源随着新建的快速X射线成像线站即将投入使用以及未来X射线成像探测器的升级,动态显微CT成像将产生巨大的数据量,目前基于CPU串行计算的CT重构系统将不能应对海量数据的计算任务。本文借助开源框架UFO[21],基于CUDA编程标准,将滤波反投影(Filtered Back Projection,FBP)的CT重构算法的反投影运算实现了并行化,并在NVDIA RTX2080的GPU上成功实现了CT重构的并行计算。经过系统性能测试和实验验证,相比于CPU串行计算重构,GPU并行计算重构获得了200倍左右的加速比,重构一套CT数据仅需7 s左右,大大减少了用户处理实验数据的时间,且重构结果满足用户实验要求。
1 基于GPU并行计算的CT重构实现方法
CT重构算法包括解析算法和代数迭代算法,当数据完整时,解析算法的重构质量令人满意,且重构速度快,先滤波后反投影的FBP算法是解析算法中知名度最高和最普及的算法,因此本文采用对FBP算法并行化编程实现X射线动态显微CT的快速重构。
在三维的成像系统中,假设z轴代表X射线光束方向,用f(x,y,z)表示物体模型,用θ表示物体的旋转角度,用p(x",y")表示物体旋转θ之后下物体的投影,投影数据由成像探测器采集。二维原始图像f(x,z)的投影p(x")的傅里叶变换P(ω)等于f(x,z)的傅里叶变换F(ωx,ωz)沿与探测器平行的方向过原点的片段。如果当物体在θϵ[0,2π)内旋转,投影P(ω)将覆盖整个二维傅里叶平面,由式(1)知,原始图像f(x,z)可由滤波反投影算法计算得到[23]。
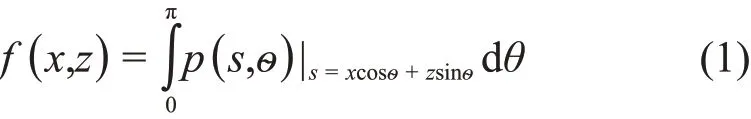
具体地说,FBP算法可按照三个步骤来实现:1)获得投影数据p(x",y"),并对其做傅里叶变换得到F(ωx,ωz);2)对F(ωx,ωz)进行滤波处理;3)对所有旋转角度θ的p(x",y")做反投影,即得到二维原始图像f(x,z)。
如图1所示,沿着y轴方向,物体可看作由很多层切片(即二维原始图像f(x,z))构成,且每一层切片的重构互不干扰,独立执行,这意味着CT重构比较适用GPU的并行设计方案,可以把每个独立的切片当成单个重构任务去执行。反投影是图像重构中最复杂的过程,也是最耗时的过程。但是,重构物体每一个切片之间的重构是独立的,可以通过并行设计有效地减少重构时间。投影数据是按照不同投影方向(不同角度θ)得到的,反投影图像是对不同投影方向并行求和计算得出。

图1 基于GPU并行计算重构的FBP算法中反投影计算过程示意图Fig.1 Schematic diagram of back-projection calculation process in FBP algorithm based on GPU parallel computing reconstruction
本文基于GPU并行计算通过并行化FBP算法反投影过程实现加速。我们借助NVidia的CUDA的API接口开发运行在GPU的反投影内核函数[16]。CUDA是一种统一计算设备架构,它可以使擅长并行计算的GPU和逻辑运算的CPU协同工作。运行在GPU上的程序称为Kernel(内核函数),一个内核函数包含两个层次的并行,即Grid中Block间并行和Block中Thread间并行。每个线程都有自己的BlockID和ThreadID以区别于其他线程,每个线程按照指令顺序执行Kernel函数。本文根据投影图像大小进行Kernel设计,线程任务划分如图2所示。1个Grid网格开启8个Block,每个Block的尺寸是32×32,即每个Block由1 024个线程组成,每个Block负责投影图像128行数据的重构,每行的一个像素点的重构由一个线程负责。

图2 根据投影图像大小对FBP算法中反投影计算过程做并行任务划分示意图Fig.2 Schematic diagram of divided parallel tasks in the back projection process of FBP algorithm according to the size of the projection image
在CT技术中,图像重构算法是决定图像重构质量的关键因素,重构算法的优劣直接影响到图像重构结果的准确性。滤波器的选取对重构图像质量的影响也很明显。反投影算法具有较低的时间复杂度,其重构图像的空间分辨率较高,由于反投影图像是对不同投影方向求和计算得出,原本像素值为0的点的像素值变为非0,因此反投影重构的图像会有伪影[24]。为了消除伪影,需要在重构算法中加入滤波器,常用的滤波器有Hamming滤波器、Shepp-Logan滤波器等。Hamming滤波器的窗函数采用Hamming窗函数,该窗函数主瓣频宽窄,重构图像空间分辨率高,旁瓣幅值小,吉布斯效应弱[25]。对于含有噪声的投影数据,Hamming滤波器的重构图像质量比Shepp-Logan滤波器要好,因此本文中CPU串行重构算法和GPU并行重构算法中均选择Hamming滤波器。
2 基于GPU并行计算的CT重构的性能测试
本节测试基于GPU的FBP重构算法的性能,测试设备为装有CenOS 7系统的DELL T5820工作站,并配备英特尔酷睿i9-9900X处理器(3.5 GHz)和RTX 2080图形处理器(8 GB),内存Kingston DDR4(64 GB)。RTX 2080拥有2 944个流处理器,显存搭配8 GB GDDR6,位宽256 bit,带宽为448 GB·s-1。基于GPU的FBP算法的CT重构流程主要包括以下4个步骤:从硬盘读取投影数据;在CPU上对投影数据p(x")的一维傅里叶变换P(ω)做滤波处理;在GPU上实现反投影运算;写重构数据到硬盘。
测试需要的实验数据来自10 Hz时间分辨率的CT数据采集系统,包括黄粉虫体内气泡CT数据和黄粉虫第一躯干CT数据。把其中一套黄粉虫体内气泡CT数据分成三份进行重构时间的测试,分别是256张、512张和1 024张,数据像素大小为1 024×1 024。基于GPU并行计算的CT重构算法总的重构时间以及各个步骤的重构时间如表1所示。

表1 在不同大小CT数据下基于GPU并行计算重构的FBP算法的总的重构时间以及各个步骤的重构时间Table 1 The total reconstruction time and the reconstruction time of each step of FBP algorithm based on GPU parallel computing reconstruction with different sizes of CT data
相比于投影读取、切片写入和滤波运算,反投影算法的内存、时间、指令消耗较大,导致时间复杂度也很大。当输入规模按照同比例增加时,时间复杂度越大的算法运行时间增长越快。因此,通过表1可以看出,随着投影数据量的增加,反投影耗时占总时间的比重越来越大。投影数进行四倍增长时,反投影所需时间占总的重构时间比例由25.1%增加到49.2%。此外,总的重构时间中,磁盘的读写包括投影读取和切片写入也占用了一半左右的时间。
像素数目为1 024×1 024的投影数据分别利用基于CPU串行和基于GPU并行的FBP算法重构,通过不同大小的CT数据来比较两种方案的重构时间。图3显示了上述两种方案的重构时间随CT数据大小的变化曲线。

图3 在不同大小CT数据下基于CPU串行计算重构和基于GPU并行计算重构的所需时间对比Fig.3 Comparison of reconstruction time based on CPU serial computing and GPU parallel computing with CT data of different sizes
从图3可以看到,基于GPU并行计算的CT重构算法缩短了CT重构的运行时间。当投影数据为800帧时,基于GPU并行计算的重构算法的运行速度比基于CPU串行计算的重构算法提升了近200倍。反投影过程所需时间从基于CPU串行重构的分钟级减少到了基于GPU并行重构的秒级。
对于基于CPU串行程序,数据加载路径是从硬盘到本地内存,对于基于GPU并行程序,数据加载路径额外包括从本地内存到GPU显存。随着数据量的不断增加,CPU读取硬盘数据及本地内存与GPU显存数据传输时间不断增加。对于不同大小的投影数据,基于GPU并行和基于CPU串行的重构时间加速比随CT数据大小的变化曲线如图4所示。
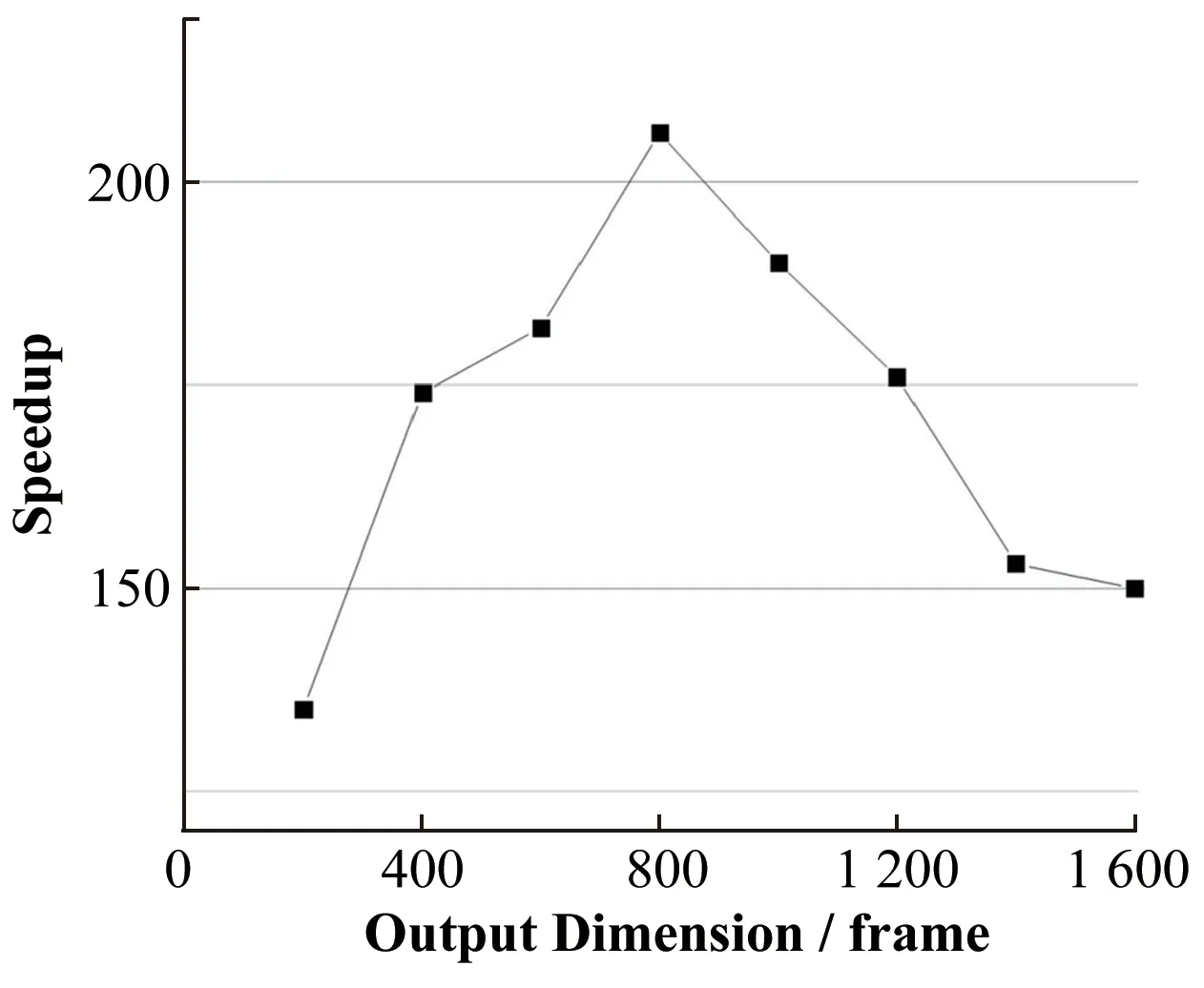
图4 相比于基于CPU串行计算重构,基于GPU并行计算重构获得的加速比随CT数据大小的变化曲线Fig.4 Curve of speedup of GPU based parallel reconstruction compared with CPU based serial reconstruction vs.CT data size
如图4所示,投影数据量当增加到一定规模时,图像重构的加速比将会随着数据量的增加而减少。其主要原因是基于GPU并行计算的CT重构算法在反投影计算部分起到了加速效果,而在投影读取和切片写入部分并没有得到加速,由表1可知,随着投影数据的增加,投影读取和切片写入部分的时间占总重构时间的50%左右,其中,硬盘和本地内存之间的投影读取和切片写入时间占主要部分,这是CT重构总体加速比接近饱和状态的主要原因。提高硬件能够进一步加快CT重构算法中反投影计算部分的速度,但不能改变投影读取和切片写入部分的速度。在重构过程中,提高数据传输速度成为解决问题的关键。
3 基于GPU并行计算的CT重构的实验验证
X射线动态显微CT实验的样品为一只活的黄粉虫,将其置于直径2 mm的聚酰亚胺管中。实验在上海同步辐射光源的BL09B测试线站进行,采用通量较高的弯铁光源白光,输出X射线的光子能量在6 keV以上。在样品前2 m处放置1 mm厚铝箔片以吸收低能X射线光子,降低样品受到的X射线辐射。实验样品以及实验装置如图5所示,实验样品台由三部分组成:从上到下依次是微型位移台(SmarAct SLS-5252,分辨率小于1 nm)、气浮转台(LAB RT150S,最高转速800 rpm)和六轴位移台(PI H-825,最小位移达0.25μm)。微型位移台用于调整样品的旋转中心,气浮转台用于样品的高精度稳定旋转实现CT扫描,六轴六足位移台用于调节视场中样品的位置。上海光源X射线成像组开发了基于长工作距离显微镜头系统和高速CMOS相机的快速X射线成像探测器,通过优化长距离显微镜头系统,增大其数值孔径(8倍镜头的数值孔径为0.5,4倍镜头的数值孔径为0.22),提高了耦合效率,为了匹配镜头数值孔径,闪烁体选择厚度为50μm,可实现最佳成像分辨率和最佳成像衬度。为了达到最优的实验效果,仔细选择了实验参数,光子能量设置为18 keV,样品到探测器的距离设置为46 cm,气浮转台每分钟旋转300圈,相机每秒拍摄8 000帧图片,每套CT数据为800帧,每套CT的采集时间为0.1 s。实验数据来自10 Hz时间分辨率的CT数据采集系统,包括黄粉虫体内气泡CT数据和黄粉虫第一躯干CT数据,黄粉虫体内气泡CT数据用4倍镜头的探测器采集,有效像素5μm,探测器视场为5 mm,实验拍摄时间为5 s。黄粉虫第一躯干CT数据用8倍镜头的探测器采集,有效像素2.5μm,探测器视场为2.5 mm,实验拍摄时间也为5 s。

图5 X射线动态显微CT实验样品(a)以及实验装置图(b)Fig.5 Photographs of X-ray dynamic microscopic CT experimental sample(a)and experimental setup(b)
3.1 基于CPU串行计算和基于GPU并行计算的CT重构图像质量对比
基于CPU串行计算和基于GPU并行计算分别对黄粉虫体内气泡CT数据进行重构,选择同一层CT重构切片做线型分析,结果如图6所示。由于CPU串行重构算法和GPU并行重构算法均采取了Hamming滤波器,重构切片的伪影均得到有效的消除。重构切片中的圈表示线型分析的路径,GPU并行计算重构切片在明暗交界处像素点灰度值的变化明显,其衬度值大于CPU串行计算重构结果。
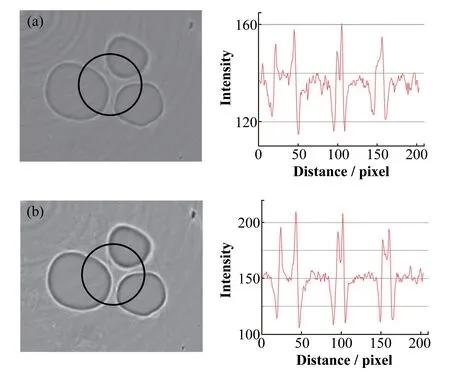
图6 基于CPU串行计算重构(a)和基于GPU并行计算重构(b)得到的黄粉虫体内气泡的CT重构切片及其线型分析比较Fig.6 Comparisons of CT reconstruction slices and line profile analyses of bubbles in the body of the tenebrio molitor sample obtained from CPU serial reconstruction(a)and GPU parallel reconstruction(b)
基于CPU串行计算和基于GPU并行计算分别对黄粉虫第一躯干CT数据进行重构。选择同一层CT重构切片计算其灰度值分布,结果如图7所示。
通过CT重构切片的灰度值可以计算其衬度,衬度是指图像上不同区域间存在的明暗程度差异,数值越大,越易于分辨图像细节。其中衬度值计算公式如下:

式中:C表示衬度值;G表示灰度值。
结合图7和式(2)计算可知,基于CPU串行计算重构结果的衬度值为25.4%,基于GPU并行计算重构结果的衬度值为33.3%。根据衬度值定义,图像衬度值越大,图像明暗变化越大,图像细节信息越明显,从图8可以看出,基于GPU并行计算的三维CT重构结果除了可以看到黄粉虫体内直肠外,黄粉虫的直肠周围细节信息也能清晰的观察到,经测量,直肠直径为47.5μm。
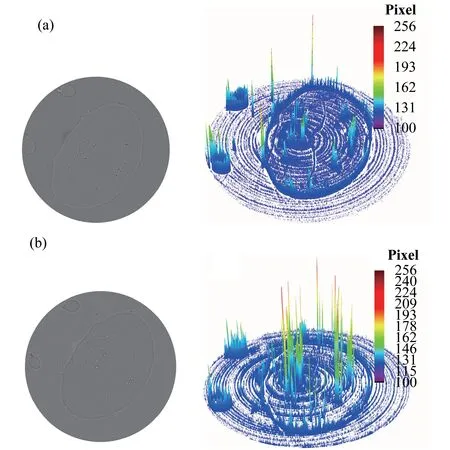
图7 基于CPU串行计算重构(a)和基于GPU并行计算重构(b)得到的黄粉虫第一躯干CT重构切片及灰度值分布图的比较Fig.7 Comparisons of the CT reconstruction slice and the gray-scale value distribution map of the first trunk of the tenebrio molitor sample based on CPU serial computing reconstruction(a)and GPU parallel computing reconstruction(b)

图8 基于CPU串行计算重构(a)和基于GPU并行计算重构(b)获得的黄粉虫第一躯干的三维CT重构结果比较Fig.8 Comparisons of the 3D CT reconstruction results of the first trunk of the tenebrio molitor sample based on CPU serial computing reconstruction(a)and GPU parallel computing reconstruction(b)
基于CPU串行重构算法和基于GPU并行重构算法的像素点灰度值计算方式不同,造成了重构切片衬度值的不同,最终使得样品三维CT重构结果的内部细节信息在观察上存在差异。图像反相算法是指对图像中的像素点做灰度值计算,其计算方法如式(3)所示,重构切片位深为8位,i0为初始像素值,i1为图像反相后的像素值。

对CPU串行计算重构切片做图像反相计算,其衬度值由25.4%提高到31.5%,结果如图9所示。因此在基于CPU串行计算重构中,可以进一步采用图像反相算法来提高重构图像的衬度,增强图像中吸收X射线较弱的信号,这对用户观察和分析样品内部结构中的弱信号有着一定实际意义。

图9 对CPU串行计算重构切片做反相处理得到的黄粉虫第一躯干CT重构切片灰度值分布图(a)以及三维CT重构结果(b)Fig.9 The gray-scale value distribution of CT reconstruction slice(a)and 3D CT reconstruction result(b)of the first trunk of the tenebrio molitor sample obtained by inverse processing of serial calculation reconstruction slice of CPU
3.2 基于GPU并行计算在不同滤波器下CT重构质量的对比
为了比较不同滤波器的性能差异,基于GPU并行计算重构分别选择不同的滤波器处理投影数据。图10(a、c)是采用Shepp-Logan滤波器处理得到的黄粉虫第一躯干的三维CT重构结果的正视图,图10(b、d)采用Hamming滤波器处理得到的黄粉虫第一躯干的三维CT重构结果的俯视图。可以看出,图10(b、d)伪影更少,图像重构质量较好,采用Hamming滤波器的CT重构算法实验效果更好。
3.3 基于GPU并行计算的动态显微CT的快速重构
基于GPU并行计算的CT重构算法大大缩短了CT重构的运行时间,选择Hamming滤波器可以减少反投影计算产生的伪影。最后通过设计动态显微CT实验对基于GPU并行计算和Hamming滤波器的CT重构算法进行了验证。50套黄粉虫体内气泡CT数据完成重构总共耗时5.93 min,而基于CPU串行重构耗时20.4 h。选取不同时间点的气泡CT重构数据,可以在时间维度上观察到气泡的动态变化过程。图11是基于GPU并行计算实现黄粉虫体内气泡在不同时刻的运动过程的三维CT重构结果,CT重构图像没有伪影产生,可以清晰观察到黄粉虫体内气泡在自上而下运动,通过计算,气泡半径为0.624 mm,气泡平均运动速度为1.08 mm·s-1。
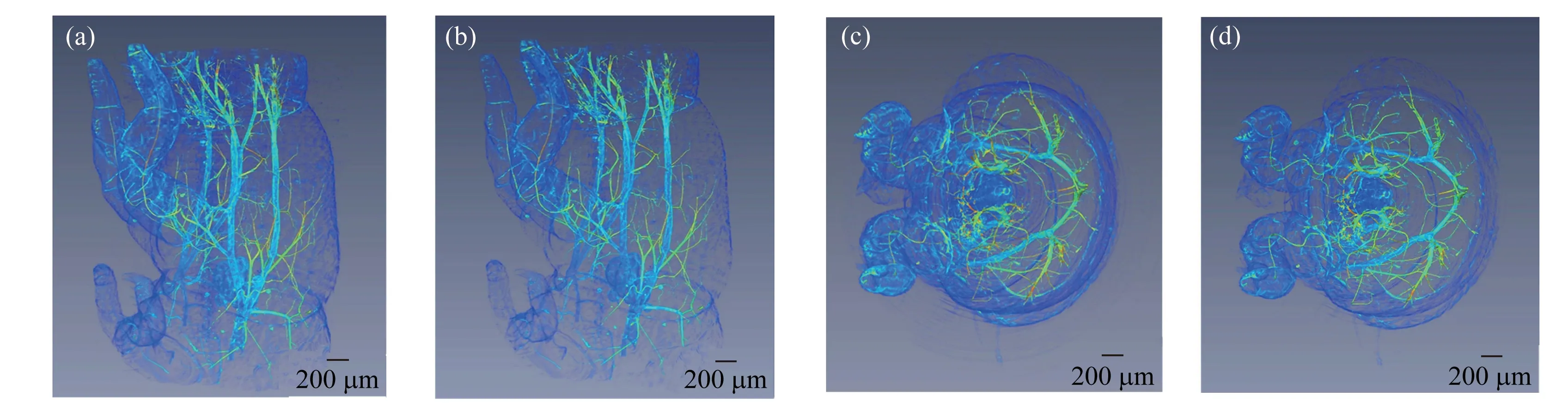
图10 基于GPU并行计算的CT重构中,分别采用Shepp-Logan滤波器和Hamming滤波器获得的黄粉虫第一躯干的三维CT重构结果比较 (a、c)为采用Shepp-Logan滤波器的三维重构结果的正视图和俯视图,(b、d)为采用的Hamming滤波器的三维重构结果的正视图和俯视图Fig.10 Comparisons of the 3D CT reconstruction results of the first trunk of the tenebrio molitor sample using Shepp-Logan filter and Hamming filter in GPU parallel computing reconstruction (a,c)The front view and the top view of the results using Shepp-Logan filter,(b,d)The front view and the top view of the results using Hamming filter

图11 基于GPU并行计算重构实现黄粉虫体内气泡在不同时刻的运动过程的三维CT重构结果Fig.11 The 3D CT reconstruction results of the movement process of bubbles in the body of the tenebrio molitor sample at different times based on GPU parallel computing reconstruction
4 结语
本文基于GPU通过并行化反投影实现了FBP重构算法,借助GPU强大的计算能力可以实现快速显微CT重构,相比于CPU串行重构,GPU并行计算获得了200倍左右的加速比。选择同一层重构切片做X射线线型分析并进行衬度计算,基于GPU并行计算重构结果的衬度值优于基于CPU串行计算重构结果。在基于CPU串行计算重构中,进一步采用图像反相算法可以提高重构图像的衬度。相比Shepp-Logan滤波器,Hamming滤波器能减少重构图像的伪影,改善重构图像的质量。基于GPU并行计算并采用Hamming滤波器,在6 min内实现了50套X射线动态显微CT实验数据的快速重构,并能够清晰地看到黄粉虫体内气泡在不同时刻的运动过程。实验结果表明,基于GPU并行计算并采用Hamming滤波器的CT重构算法能够实现海量CT实验数据的快速重构,将很大程度上解决上海光源X射线成像线站的大量用户实验数据积压的瓶颈问题,显著提升实验效率。
