基于BiLSTM-NFC的地下水埋深预测方法研究
2021-06-16韩宇平刘中培黄会平
刘 鑫,韩宇平,刘中培,黄会平
(1.华北水利水电大学 水利学院,河南 郑州450046;2.华北水利水电大学 测绘与地理信息学院,河南 郑州450046)
1 引 言
地下水埋深的变化受降雨、蒸发及开采量等多种因素的影响。地下水过度开采时,会产生地下水漏斗和地面沉降;当补给量超过开采量时,地下水埋深会变浅。因此,预测地下水埋深的变化情况对区域水资源管理至关重要。而机理模型建模预测地下水埋深容易受到物理环境的影响,存在较多不确定因素,建模时间较长。使用深度学习模型可以不依赖任何物理过程和假设,且深度学习模型具有很强的自组织及自适应能力,对于非线性分布的样本数据有很好的建模能力[1-2],被广泛应用于供水量预测[3]、空间插值[4-5]、降水预报[6-7]、污染源识别[8-9]及水质预测[10-11]等多个领域。
对于地下水埋深的预测是经典的二分类问题,人工神经网络(ANN)可以较好地解决此类问题[12-13],但是ANN学习能力及推广能力有限,容易出现过拟合[14-15],导致泛化能力差,不能很好地描述复杂特征的分布情况,更重要的是ANN没有记忆能力。而长短时记忆循环神经网络(LSTM)[16]控制有记忆单元且不需要大量参数,使预测结果更依赖于过去最近的记忆。LSTM在时间序列问题上的性能优于ANN,但是LSTM在测试集的泛化能力不够理想。LSTM和ANN不能很好地根据已知数据预测未知特征,原因是它们都是单向的(前向的)且都是全连接神经网络(FC)。单向网络只能学习到单侧的信息,而有时时序问题的信息不只是单向有用,双向的信息对预测结果也很关键。FC的神经元是全连接的,会减少网络的随机性。双向长短时记忆循环神经网络(BiLSTM)[17]不仅具有LSTM的功能,而且可以先前向学习,再后向学习,最后将网络两个方向的输出结果合在一起形成网络的最终输出。
本研究以黄河下游人民胜利渠灌区地下水埋深预测为例,构建BiLSTM-NFC深度学习模型,将BiLSTM融合非全连接神经网络(NFC),使得每一次训练按一定的概率丢弃一些神经元,增加网络的随机性,最后与BiLSTM、LSTM-NFC及LSTM的预测结果进行对比分析,以期提高地下水埋深预测的精度。
2 研究区概况与数据预处理
2.1 研究区概况与数据来源
人民胜利渠灌区是新中国成立后黄河下游兴建的大型引黄灌区之一,位于河南省黄河北岸。灌区南起黄河,北至卫河,总面积1 486.84 km2。本研究利用1993—2018年新乡气象站的数据(降水、蒸发、平均气温、平均气压、相对湿度、平均风速和日照时数)、灌区地下水供应量和总开采量(渠灌量和井灌量)进行建模,预测灌区的平均地下水埋深。气象数据来自国家气象局,灌区数据来自人民胜利渠灌溉管理局。
2.2 数据预处理
为了消除量纲的影响,使得不同量纲的数据具有相同的尺度,本研究将数据进行标准化,在测试的时候再将数据进行还原。取消量纲及数值相差较大所引起的误差,不仅可以缩短建模时间,还有助于提高模型精度。
3 模型开发
3.1 双向长短时记忆循环神经网络
LSTM每层输出结果的同时会产生一个记忆输出,因此该网络具有一定的记忆性,同时加入了衰减因子让记忆进行衰减,这样LSTM能够清楚地记得最近的数据而以一定程度遗忘掉很久以前的数据,LSTM的抽象结构如图1所示(X1、X i、X j为不同时刻的输入,Y1、Yi、Y j为不同时刻的输出,NN为神经网络模型)。
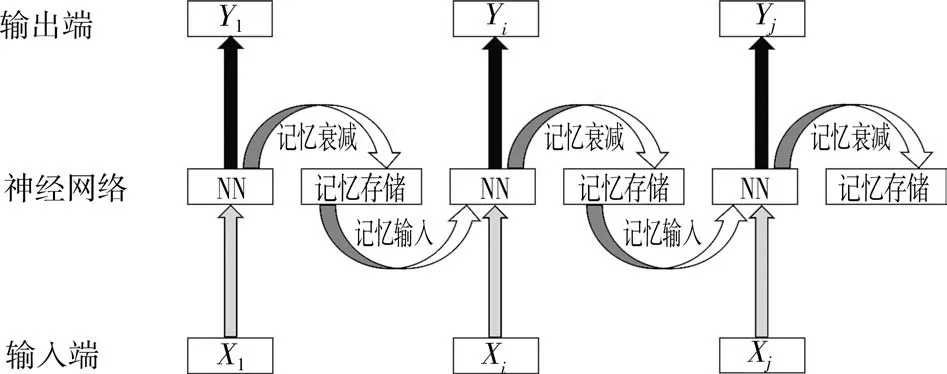
图1 LSTM的抽象结构
LSTM的结构比较复杂,每一层网络在输出结果的同时会产生一个经过衰减的记忆,存储之后再传入下一层网络,输出计算的过程可用公式表达为

式中:f t、f t-1分别为t、t-1时刻的衰减因子;h t、h t-1分别为t、t-1时刻隐藏层的输出;x t为t时刻隐藏层的输入;Wf、Wc、Wo为权重(系数);bf、bc、bo为偏置项;Sigmoid为S激活函数;Tanh为双曲正切激活函数;~C t为新学习的记忆;C t为衰减后的记忆;Ot为输出端的系数;t为时刻。
f t是由t-1时刻隐藏层的输出h t-1和输入x t结合起来,然后作用在线性变换Wf[h t-1,x t]+bf上得到的,通过Sigmoid将结果映射到0~1之间。~C t是由h t-1和x t结合起来,作用在线性变换Wc[h t-1,x t]+bc上,再通过Tanh将输出整流到-1~1之间。C t是由t-1时刻的f t-1乘以C t-1,加上t时刻的f t乘以~C t。O t决定最后输出h t的多少。
BiLSTM是LSTM的双向版本(见图2),由前向LSTM和后向LSTM组合而成,能够挖掘LSTM难以解析的规律,对于复杂的分类和回归问题表现出非常好的性能,可以弥补单向LSTM的缺点。

图2 BiLSTM的抽象结构
BiLSTM分为前向LSTMF和后向LSTMB。前向网络依次输入X1、X2、X i、X j和X n得到前向输出HF1、HF2、HFi、HFj和HFn,后向网络依次输入X n、X j、X i、X2和X1得到后向输出HB1、HB2、HBi、HBj和HBn,将两个方向的输出拼接得到[HF1,HBn]、[HF2,HBj]、[HFi,HBi]、[HFj,HB2]和[HFn,HB1]。以[HF1,HBn]为例,它是由X1在前向网络的输出HF1与X1在后向网络的输出HBn结合在一起形成的最终输出。可以看出,输入序列对于BiLSTM的两个方向神经网络是相反的,因此BiLSTM能够更好地建立数据的关联。
3.2 非全连接神经网络
FC是对第n-1层和第n层而言的,n-1层的任意一个节点都和第n层所有节点有连接。增加训练的次数,模型在训练集的误差虽然可以无限趋近于零,但是在测试集的性能往往较差,网络层数越大、参数越多,在测试集上的性能越差。NFC是对FC的一种优化,其思想是随机切断某两个神经元之间的连接,每层以一定概率P(本研究P取0.3)丢弃一些神经元,每次训练有些神经元是没有建立连接的。NFC示意见图3。
由图3可见,每次训练的时候都有神经元不参与,这样每一次训练相当于生成了一个新的模型,训练结束后被训练的模型可以看成是这些新模型的集成,从而增强网络的泛化能力。
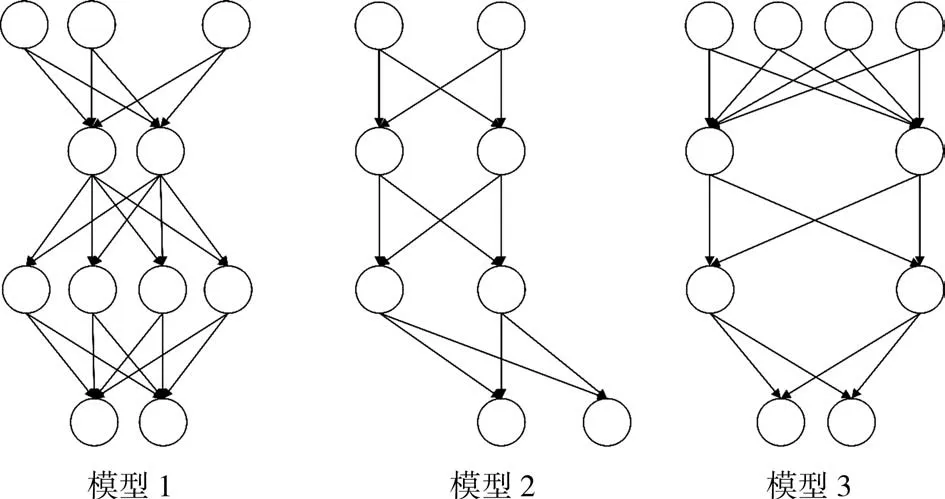
图3 NFC示意
BiLSTM-NFC、BiLSTM、LSTM-NFC和LSTM模型都使用Pytorch框架开发,Pytorch是Python中具有图形处理单元(GPU)并行计算功能的深度学习框架。为了加快建模的速度,本研究使用深度学习的张量来存储数据,一维的张量是向量,超过一维的张量是矩阵。在导入数据时采用批处理的形式,即将一次迭代的数据长度设置为训练集的长度,这样一轮训练只需要进行一次迭代。在训练模型时,将处理单元由中央处理单元(CPU)更改为GPU,将数据从内存调入显存进行并行计算。计算时不再将全部元素按位置逐一迭代计算,而是使用同维度矩阵的运算法则来简化计算过程。
3.3 优化函数
自适应矩估计(Adam)[18]是一种自适应学习率的算法,结合了动量法(Momentum)[19]和均方根支柱(RMSProp)[20]算法的优点。Adam中动量直接并入梯度一阶矩的估计,相比缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置校正,经过偏置校正后,每一次迭代学习率都有确定范围,使得参数比较平稳。Adam能基于训练数据迭代更新神经网络权重,该优化函数适用于处理稀疏梯度及非平稳目标的优化。Adam的表达式为
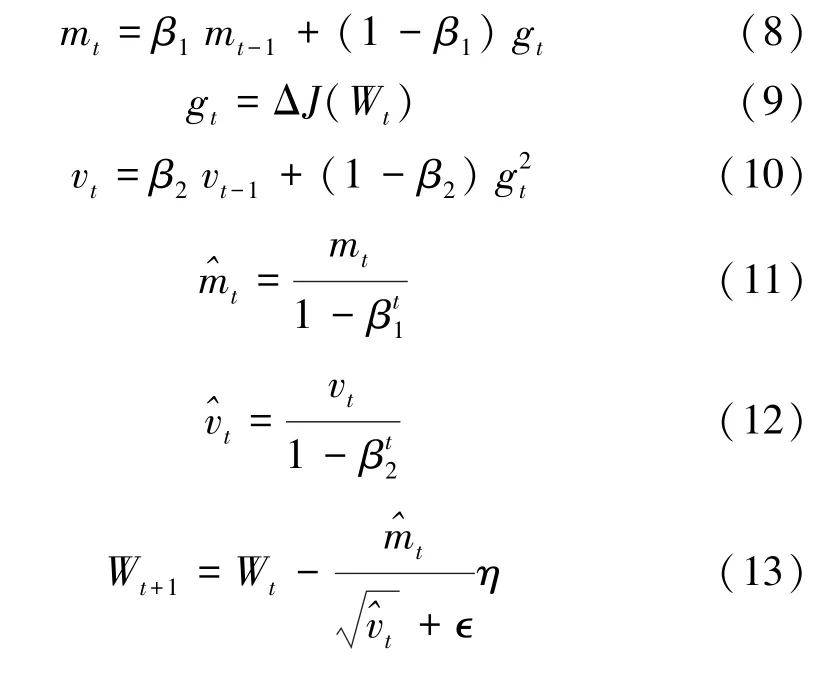
式中:m、v分别为对梯度的一阶矩估计和二阶矩估计;β1、β2分别为m、v的校正因子;g为梯度;^m、^v分别为对m、v的校正;W t+1、W t为模型参数;η为学习率;∈为避免分母为0而取值很小的数,本研究∈取10-8。
每次迭代时,计算mt、v t的移动加权平均进行更新。β1、β2的取值范围在0~1之间,本文分别取0.9和0.999。当迭代次数增加到较大值时βt1、βt2几乎为0,即不会产生任何影响,最后使用修正过的^mt和^vt对学习率η进行动态约束。
3.4 激活函数
激活函数的选择对于模型的收敛起关键性作用。如果模型采用单一激活函数,则可能出现梯度消失或激活效果不好等情况,因此本研究耦合多种激活函数来解决上述问题。
Sigmoid激活函数(见式(2))的输出不是以0为均值的,这将导致经过Sigmoid激活之后的输出作为后面一层网络输入的时候是非0均值的。Tanh激活函数(见式(4))是Sigmoid激活函数的变形,它将输入的数据映射到-1~1之间,输出变成了0均值,这就可以解决Sigmoid激活函数存在的问题,但它仍存在梯度消失的情况。最大逻辑回归(Softmax)激活函数(见式(14))将多个输出值转换成概率值,使每个值都符合概率的定义,范围在0~1之间,且概率之和为1。Softmax对输出值进行处理,它将原来较大的值放大得更大、原来较小的值压缩得更小。Softmax激活函数表达式为
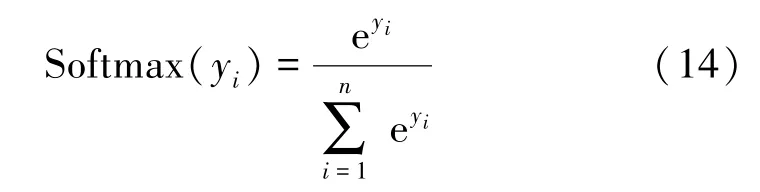
式中:y i为输出矩阵的第i个元素;n为矩阵特定维度的数据个数。
线性整流单元(ReLU)激活函数(见式(15))将大于0的数据保留,将小于0的数据变成0,其计算方法简单,只需要一个阈值过滤而不需要复杂的运算。因此,ReLU能够极大地加速模型的收敛速度,它是线性的且参数更新过程中不存在梯度消失的问题。ReLU激活函数表达式为
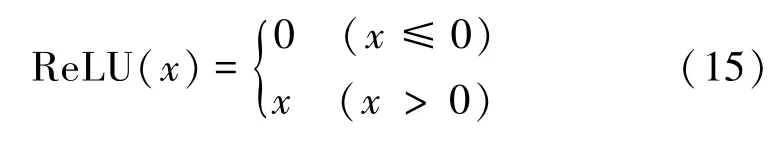
3.5 动态学习率
静态学习率不能很好地适应模型的训练,尤其是模型收敛到一定程度时会出现频繁且周期性的震荡,使得模型不能很好地持续收敛。因此,本研究采用动态学习率,在训练的过程中设定监测机制实时监测模型误差,当模型误差持续减小时不对学习率进行更新,当模型误差出现反弹时,记录之后连续20次训练的误差,如果模型在这期间震荡就将学习率乘以0.9,而后等待10次训练之后重新启动监测机制,一直到连续两次更新后的学习率差值小于10-8时不再更新学习率。
3.6 评价标准
为了避免单一评价标准的局限性,采用均方误差(MSE)、平均相对误差(MRE)、Pearson相关系数(r)及相对误差(RE)4个评价指标检验模型的性能:

4 结果与分析
4.1 拟合结果对比分析
将数据集按照7∶3的样本数量比例进行训练集和测试集划分,即1993—2010年的数据作为训练集,2011—2018年的数据作为测试集,BiLSTM-NFC、BiLSTM、LSTM-NFC和LSTM模型采用相同的训练集和测试集。4个模型的训练与测试结果见图4。
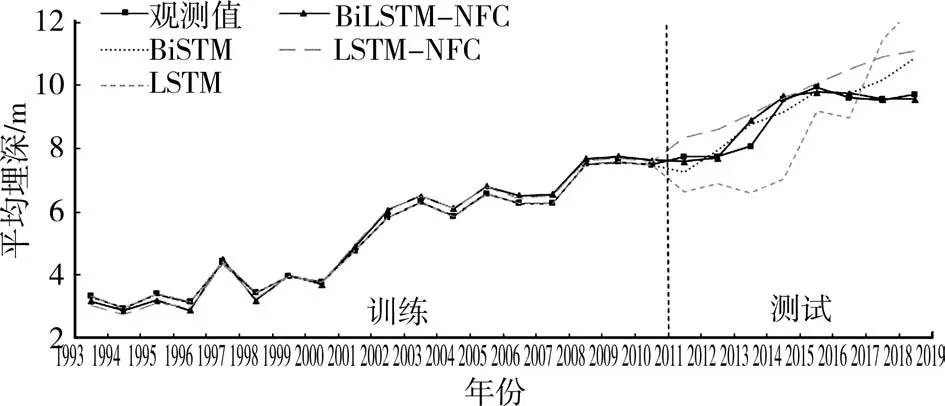
图4 模型的拟合结果
由图4可知,4个模型的拟合效果在训练阶段都较好,但在测试阶段存在较大差别。在测试集上,LSTM和LSTM-NFC模型的偏离程度较大,BiLSTMNFC与BiLSTM的拟合效果较好。BiLSTM曲线与观测曲线前期的拟合效果较好,但后期走势却与观测值有较大偏离。BiLSTM-NFC的预测值与观测值最接近,拟合效果最好,模型最接近无偏估计。4个模型的预测值与观测值对比及绝对误差(AE)见表1。
由表1可以看出:BiLSTM-NFC模型的误差最小,且误差有正有负,拟合程度较高。BiLSTM模型的误差虽然也有正有负,但是误差值较大,误差最大的是LSTM模型。4个模型误差从小到大排序为BiLSTMNFC<BiLSTM<LSTM-NFC<LSTM。
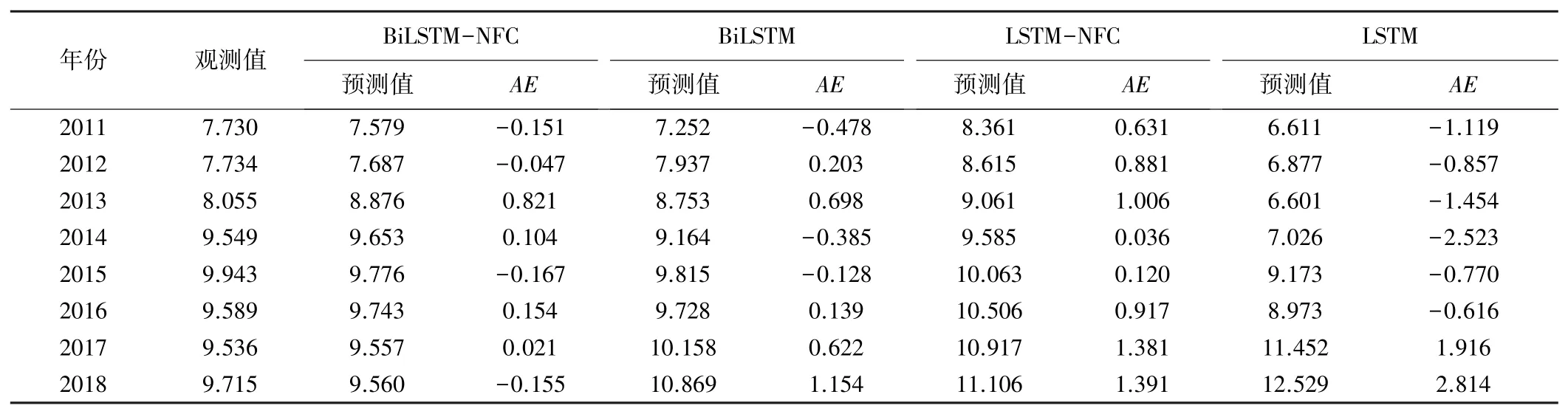
表1 模型预测值与观测值对比 m
4.2 模型性能对比分析
4个模型的训练结果见表2(训练次数为1 000),训练集的MSE越小,说明拟合效果越好,MSE为0表示过度拟合。
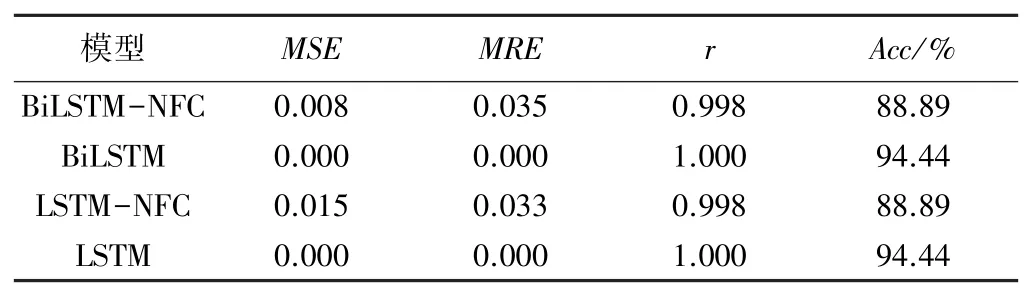
表2 模型的训练结果
从表2可以看出,4个模型在训练结束时,MSE都接近0.000甚至为0.000,符合模型训练的一般规律,但是过度拟合可能导致模型的泛化能力变差。没有融合NFC的2个模型MSE为0,出现过度拟合,因此准确率(Acc)高于融合NFC的2个模型。使用矩阵存储数据再加上批处理,使得模型不需要进行大量训练。训练1 000次时MSE几乎为0,学习率持续减小,但是参数已经停止更新。对4个模型进行测试,结果见表3。
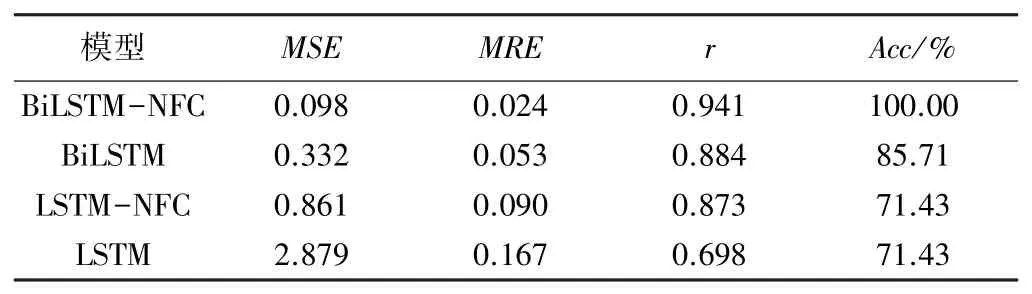
表3 模型的测试结果
由表3可知,BiLSTM的4个评价指标都优于LSTM,BiLSTM-NFC的4个评价指标都优于LSTMNFC,可知双向网络的性能优于单向网络。BiLSTMNFC比BiLSTM的MSE减小了70.48%,LSTM-NFC的MSE比LSTM的MSE减小了70.09%,可知NFC可使模型的MSE明显减小。4个模型的MSE从小到大排序为BiLSTM-NFC<BiLSTM<LSTM-NFC<LSTM,BiLSTM-NFC的MSE最小,比LSTM的MSE减小了96.60%。MR E的排序为BiLSTM-NFC<BiLSTM<LSTM-NFC<LSTM,BiLSTM-NFC的MRE最小,说明BiLSTM-NFC模型的稳定性最强。BiLSTM-NFC的r最大,表明该模型预测值与观测值具有最优的相关关系,r从大到小排序为BiLSTM-NFC>BiLSTM>LSTMNFC>LSTM。BiLSTM的Acc为85.71%,BiLSTM-NFC的Acc为100%,可见NFC可使模型具有更强的自适应能力。而LSTM融合NFC之后,Acc没有增大,原因可能是LSTM的学习能力不足。
泛化能力是模型对未知数据的预测能力,是评价一个模型优劣的重要准则。将4个模型在训练集和测试集上的MSE进行对比,结果见表4。
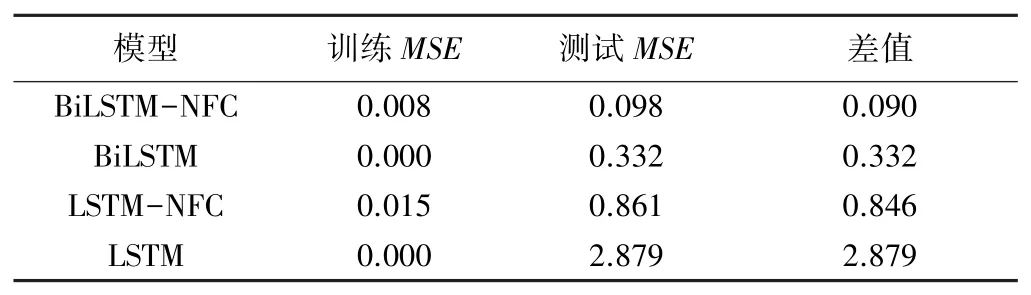
表4 模型训练与测试的MSE对比
4个模型的泛化能力排序为BiLSTM-NFC>BiLSTM>LSTM-NFC>LSTM。在测试集上,LSTM的MSE是最差的,但是LSTM融合NFC之后,模型的MSE明显减小,由2.879减小到0.861,融合NFC的BiLSTM的MSE从0.332减小到0.098,说明NFC能够减小模型在测试集上的误差,增强泛化能力。
由表3可知,BiLSTM-NFC的MRE最小只是训练1 000次以后的结果,如果训练过程中出现频繁的震荡现象,即使误差非常小,也不能说明模型足够稳定可靠。因此,本研究进一步采用式(19)计算每个数据的RE,来最终验证模型的可靠性。4个模型RE的箱图见图5。
由图5可知:在训练集上,BiLSTM和LSTM都过度拟合,相对误差的上限和下限重合,融合了NFC的2个模型没有过度拟合,BiLSTM-NFC的上限小于LSTM-NFC的上限;在测试集上,与其他3个模型相比,BiLSTM-NFC的相对误差较小,表明BiLSTM-NFC模型更加可靠。因此,BiLSTM-NFC模型比其他3个模型具有明显优势。

图5 模型训练集和测试集箱图
Pytorch框架具有强大的GPU加速功能,数据可以在GPU上实现并行计算。4个模型分别通过第八代Intel酷睿处理器和GeForce 930MX,实现CPU和GPU上的1 000次训练,训练时间见表5。

表5 模型在CPU和GPU上训练1 000次所用的时间 s
由表5可知,与CPU相比,BiLSTM-NFC和LSTM-NFC在GPU上的训练时间分别缩短53.50%和48.62%,BiLSTM和LSTM在GPU上的训练时间分别缩短19.13%和15.88%,体现出GPU强大的加速功能。在GPU上,融合了NFC之后,模型训练时间几乎不变;而在CPU上,模型融合NFC之后的训练时间却大幅增加。在GPU上,双向网络的训练时间与单向网络的训练时间几乎一样,而在CPU上却有明显增加,可见GPU具有很强的并行计算能力。对于更高维度的矩阵,在GPU上的训练时间可能更短。
激活函数的选择对于模型的收敛十分关键。一般而言,ReLU激活函数的效果较好,但是仅使用ReLU一个激活函数,数据在层间传递时,激活函数的缺陷会被放大。本研究使用耦合激活函数(Tanh、Softmax及ReLU)来弥补单一激活函数的缺陷,ReLU激活函数与耦合激活函数的对比见表6,由表6可知,使用耦合激活函数的4项评价指标均优于仅使用ReLU激活函数的。

表6 ReLU激活函数与耦合激活函数的对比
5 结 论
深度学习模型具有非常强大的能力,能够很好地描述区域地下水数据间复杂的数量与特征关系。本研究建立4个深度学习模型,对比了4个模型对黄河下游人民胜利渠灌区1993—2018年地下水埋深预测的精度,结果表明BiLSTM-NFC模型的性能最好,并得出以下结论。
(1)使用矩阵运算、批处理及动态学习率,模型可以快速收敛,不需要进行大量训练。
(2)与BiLSTM、LSTM-NFC及LSTM模型相比,BiLSTM-NFC模型学习能力、稳定性、可靠性及泛化能力最强,测试集的MSE、MRE、r及Acc分别为0.098、0.024、0.941及100%,最接近无偏估计。
(3)双向长短时记忆循环神经网络(BiLSTM)的性能优于长短时记忆循环神经网络(LSTM),NFC可以防止过拟合,还能使模型的MSE明显减小。
(4)模型在GPU上的运行时间比在CPU上明显缩短。
(5)合理设置多种激活函数可以解决单一激活函数的弊端。
