基于卷积神经网络的健康大数据智能分析方法研究
2021-06-14白贺伊
白贺伊
(西安广播电视大学,陕西西安 710002)
随着我国医疗卫生事业的不断发展,越来越多的医疗健康数据被存储在数据库中。这些数据具有规模大、增长迅速、结构复杂等特点[1-3]。目前,我国对医疗健康大数据的挖掘与应用正处于起步阶段,医疗数据的深度挖掘与分析关系到全民健康的发展,如何利用人工智能技术对庞大的医疗数据进行智能化分析,挖掘其中有效信息,从而更好地服务于医护人员与广大人民群众,是目前医疗事业发展与数据应用面临的重要挑战[4]。
针对上述所提到的问题,该文基于人工智能深度学习领域中的卷积神经网络技术,提出了一种适用于对医疗健康大数据进行智能化分析的方法。该方法通过词向量训练、CNN特征学习以及疾病风险评估等步骤,完成对各种疾病的风险评估,能够利用不同疾病的训练数据集得到与之匹配的分析模型。实验结果表明,该文提出的方法以及建立的模型能够实现对不同数据集、不同疾病的智能化分析,能更好地适用于常见疾病的风险评估,具有较高实用性与可靠性。随着日益增加的医疗健康大数据处理与分析的需求,该文所提方法具有应用价值,对其进一步的发展与完善也将更有意义。
1 卷积神经网络
卷积神经网络(CNN)是一种建立在传统神经网络上,包含卷积结构的深度学习算法[5]。与传统神经网络相比,卷积神经网络在传统多层神经网络的基础上加入了特征学习部分,利用空间相对关系减少参数数目以此提高算法的训练性能。具体实现方式就是在传统神经网络的全连接层前面增加部分连接的卷积层。卷积神经网络解决了人工智能领域中的一个重要问题就是将复杂问题简化,最大程度减少参数数量,进而大幅提升算法表现性能。
典型的卷积神经网络通常由卷积层(C)、池化层(S)以及全连接层(F)所组成。其结构如图1所示[6-8]。

图1 典型卷积神经网络
其中,卷积层负责提取输入数据的特征;池化层负责对数据进行降维;全连接层则实现最终处理结果的输出。通常在实际使用中,CNN 中包含有若干卷积层与池化层,且采用相互交替的形式进行设计,即卷积层后面连接着池化层,池化层后面又连着卷积层,上述交替循环的结构以池化层结尾,最后再连接至全连接层结束整个网络。卷积层与池化层的堆叠次数越多,CNN 所提取出的特征就越复杂、表达能力就越强,分类效果越明显[9],进而使得利用其所实现的功能和效果就越好。
1)卷积层
卷积层又称之为特征提取层,是卷积神经网络CNN 架构中最为关键的一部分,同时也是区别于传统神经网络最为显著的特征[10]。该层包括多个卷积核滤波器,各卷积核与输入数据或特征图进行卷积运算来实现特征提取的功能。为了降低神经网络的过拟合,卷积层通常采用局部连接的方式。即每个神经元只需连接附近的局部区域,而不需要与特征图中的所有特征点进行连接。同时,为尽可能减少网络运行参数。在卷积运算中,使每个卷积核滤波器的参数实现共享,可使最后得到的结果泛化能力更强。
卷积过程如图2所示。其中,输入的是大小为5×5的数据信息,卷积滤波器的大小为3×3,步长为1,对应的卷积表达式[11]如式(1)所示。
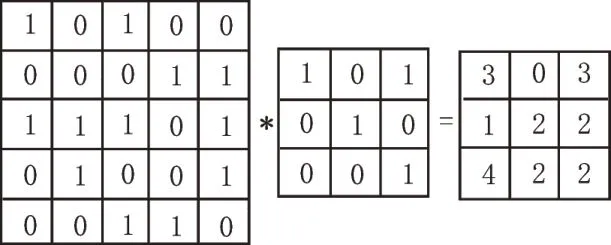
图2 卷积运算过程
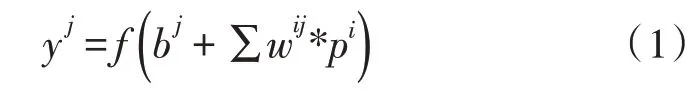
其中,yj表示第j个输出特征图,(f)代表所用到的激活函数,*代表卷积操作,pi为需要进行卷积的第i个特征图,wij为当前卷积核所对应的权值,bj为当前输出特征图的偏置。
2)池化层
池化层也称为下采样层,该层主要是用来对前面卷积层所得到的高维特征进行降维处理,从而大幅减少网络的参数数量,有效提高神经网络的运行速度以及避免数据间过拟合的情况发生。目前,常用的池化方法为最大池化(max-pooling)和平均池化(mean-pooling)[12-14]。
两种池化方式对应的过程如图3 所示。在该示意图中,所需池化的数据大小假设为4×4,池化核为2×2,步长通常与池化核的长或宽相同,设置为2,最后所得到两种分别由最大值与平均值所组成2×2 的池化结果。综合考虑两种方式的优缺点,该文的仿真实验将采用最大池化的方法对数据进行处理。

图3 池化过程示意图
3)全连接层
输入的数据经过多重卷积层与池化层之后,提取出表达能力强且十分抽象的特征表示[15]。全连接层作为整个卷积神经网络的最后一层,其最重要的功能就是将提取到的特征按照一定规则进行整合,同时映射到样本标记空间,形成相应的一维向量,最后经过层内激活函数进行输出。
2 大数据智能分析模型
2.1 健康数据特征学习
1)词向量及文本表示
利用卷积神经网络算法对医疗健康数据进行处理时,首先需要将文本数据中包括的各词利用词向量方法进行数字化处理。
词向量法可以简单理解为通过建立词表将文本数据中各词与词表中向量一一对应的方法[16]。如图4所示,n个词60 维的词向量,这些词向量组合成为一个词表矩阵。
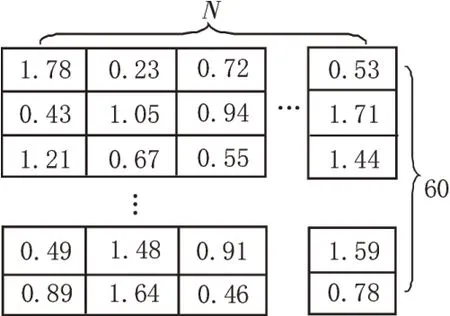
图4 词向量法示意图
目前,词向量法大体可以分为离散表示法和分布式表示法两类。其中,离散表示法是一种基于规则或者统计的简单方法,将每个词表示为一个长向量,并且该向量中有且只有一个维度的值为1,其余值则全部为0。该方法的缺点在于所建立的词表矩阵规模一般较大,而且不能较好地表示各词之间的相对关系,因此不满足该文研究的要求。分布式表示法则是通过训练将各词表示为一个定长的连续稠密向量,图5 所示为利用分布式表示法所建立的词表以及“头疼”“头晕”等词所对应的词向量表示。相较于离散表示法,该方法能够较优地表示文本数据各词之间的相似关系,同时在有限维度下可以包含更多的信息。为此文中使用分布式表示法,对医疗数据中各词进行数字化处理。
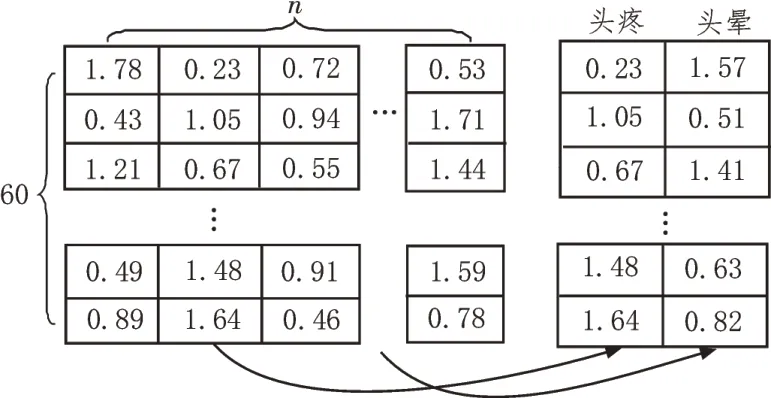
图5 分布式表示法示意图
2)CNN 设计及词向量训练
该文所设计的卷积神经网络共5 层:卷积层1、池化层1、卷积层2、池化层2、全连接层,用来进行医疗健康数据的词向量训练及最后的疾病风险评估。
进行词向量训练时,要求训练的医疗文本数据语料的纯度越高越好,即训练数据应具有较强的专业性。该文用从某三甲医院数据库中提取的近10 年来所有临床记录作为词向量训练的原始数据。在训练过程中,CNN 所有相关参数定义为集合φ,φ中参数首先全部随机初始化,然后利用梯度下降法对参数进行更新,直到最终参数使得所对应的对数似然函数值达到最大为止,所用到的公式如式(2)所示。
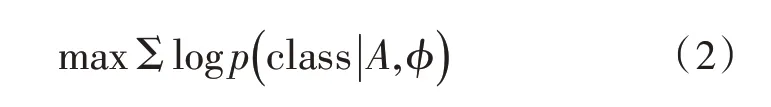
式中,A为训练样本数据集,class 为训练样本数据的正确分类,若用γ代表学习率,则梯度下降法更新参数的公式如式(3)所示。
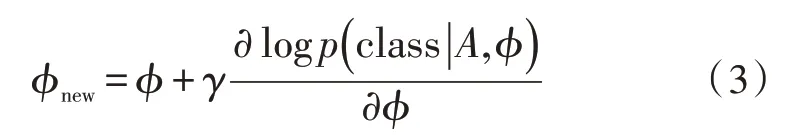
2.2 健康大数据分析模型
该文基于卷积神经网络所建立的健康大数据智能分析模型如图6 所示。
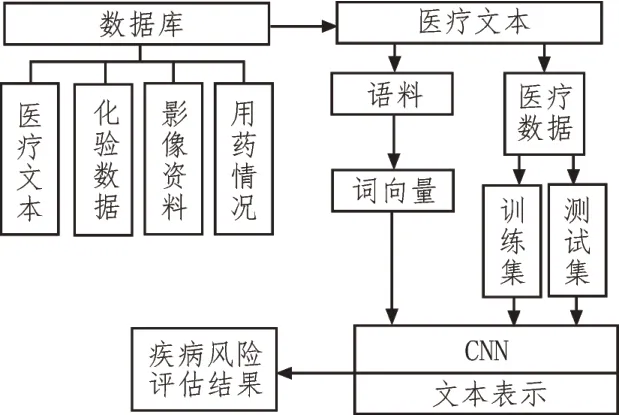
图6 健康大数据分析模型
在该模型里,数据库中保存着医院进行诊治的所有医疗数据。其中,包括患者的自述病情、医生的问诊、体格检查、各项化验检查结果、服用药品、治疗方案以及最终的诊断结果等。该模型利用数据库中的历史医疗文本数据不断进行自学习与优化,最终得到的训练模型用来实现对新传入健康数据的智能分析以及疾病的风险评估。
模型主要由词向量训练、CNN 特征学习以及疾病风险评估3 个模块所组成。词向量训练模块负责将数据库中的专业医疗历史数据进行预处理,并用处理后的数据作为语料进行文本数据的数字化表示及词向量的训练;CNN 特征学习模块负责将训练后的词向量输入到CNN 中,进行分析模型的学习与训练,最后得到效果最优的健康大数据分析模型;疾病风险评估模块则是利用训练好的模型对新输入数据进行健康评估,并输出最终结果。
3 实验测试
3.1 数据集选取
为了验证该文所提方法在医疗健康大数据分析中的有效性,与国内某三甲医院合作,从其中心数据库中选取了近十年该医院冠心病、肺部感染、脑梗死以及高血压等4 种常见慢性疾病的医疗数据,组成以下4 种样本数据集。
A1:该数据集中包含1 457 名患者就诊记录、主述病情、生命体征等医疗数据,其中984 个冠心病患者数据,473 个非冠心病患者数据。随机挑选85%作为模型训练数据,剩下数据用来测试。
A2:该数据集中包含2 083 名患者问诊记录、主述病情等医疗数据,其中1 128 个肺部感染患者数据,955 个非肺部感染患者数据。随机挑选85%作为模型训练数据,剩下数据用来测试。
A3:该数据集中包含1 074 名患者就诊记录、治疗方案、化验结果等医疗数据,其中537 个脑梗死患者数据,537 个非脑梗死患者数据。随机挑选85%作为模型训练数据,剩下数据用来测试。
A4:该数据集中包含1 074 名患者就诊记录、化验结果等医疗数据,其中537 个脑梗死患者数据,537 个高血压患者数据。随机挑选85 %作为模型训练数据,剩下数据用来测试。该数据集为脑梗死与高血压的对比数据集,这样设置的原因在于两者具有相似的发病症状,且大部分脑梗死患者同时伴有高血压,极大增加了疾病风险评估难度。
3.2 实验及结果
进行实验时,首先需要确定CNN 训练卷积滑动窗口的大小,为此,设置窗口大小为2~8,以步长2 进行滑动,分析讨论窗口大小对准确率、召回率等风险评估指标的影响,数据集使用A1与A2集。实验结果如图7 所示。

图7 滑动窗口对评估指标的影响
由图7 可以看出,当窗口大小设置为6 时,两个数据集对应的各项风险评估指标均较优于其他窗口设置。因此,后面的实验也将CNN 滑动窗口大小设置为6。
利用选定的滑动窗口大小与数据集中的训练数据,建立基于卷积神经网络的健康大数据智能分析模型,并用剩余数据作为测试数据,各数据集对应的各项疾病风险评估指标结果,如表1 所示。
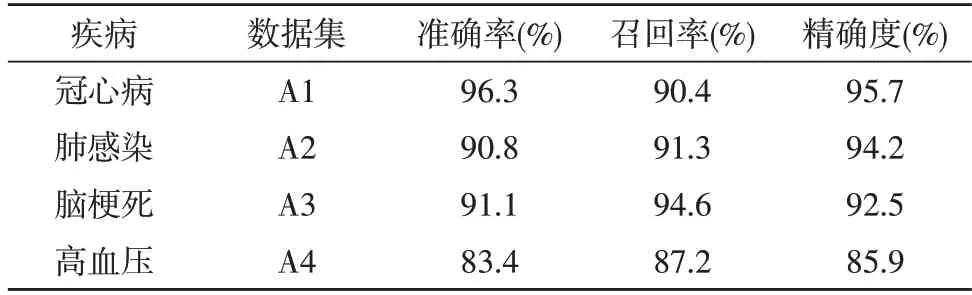
表1 疾病风险评估结果
分析表1 可知,该文所提出的基于卷积神经网络的健康大数据智能分析方法,适用于对多种常见疾病的风险评估。对A1、A2 与A3 数据集的测试实验中,准确率、召回率以及精确度三项评估结果均可达到90 %以上。同时也可以看出,使用A4对比数据集进行的疾病风险评估结果虽略低于其他数据集,但是也可以达到较高的水平。综上所述,各数据集的实验结果充分验证了所提方法的有效性、可靠性及通用性。同时也说明,该方法在分析相关联疾病中已取得较优的效果,但仍有一定的进步空间。
4 结束语
该文通过介绍卷积神经网络CNN 基本理论[7-18],提出了一种医疗健康大数据智能分析方法。该方法将CNN 文本分析技术运用于疾病风险评估中,且不同的疾病特征提取使用相同的方法,保证了所提方法的通用性。不同数据集的实验结果说明,该文的方法能够较优地适用于常见疾病的风险评估,具有较高的可靠性。同时,该方法在进一步研究与分析关联疾病中仍有较大的提升空间。
