基于深度学习网络的舞蹈动作识别方法研究
2021-06-11闫琳
闫琳
(西安航空职业技术学院,陕西西安 710089)
近年来,对于视频技术的研究成为学术界研究的热点之一。在众多视频技术中,视频动作识别对于视频智能化应用有着重要意义,其在较多领域均有着广泛的应用[1-5]。
对于视频信息的提取通常依靠两个步骤,首先提取视频中的相关视觉特征;然后对提取的特征进行学习,生成相应的描述标签。在该技术中,最重要的是有效提取特征,深度学习算法是当前提取视频特征最为高效的方法之一。但传统上基于该方式的提取方法更注重视频上空间域,即视频帧中像素信息的提取,却忽略了视频动作在时间域上动作状态的变化。以人类的认知为例,物体的动作是不断变化的,人除了依靠动作静止时的画面判断动作的类别,还需关注动作从开始到结束变化的全过程。深度学习作为人工智能技术中的重要算法之一,其提取特质的方式与人类几乎一致。因此,文中重点介绍了视频中时域特征的提取方法[6-10]。
1 理论基础
1.1 深度学习算法
卷积神经网络是图像处理领域中最常用的深度学习网络。该网络的结构如图1 所示,主要包括了卷积、池化和全连接运算[11]。
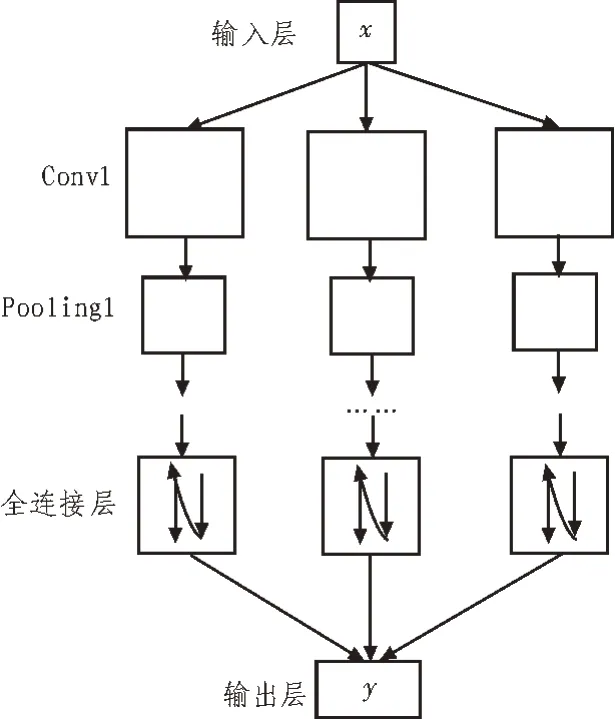
图1 卷积神经网络
1.1.1 卷积层
卷积是一种常见的信息处理领域的数学运算,离散域上的卷积运算方法,如式(1)所示。
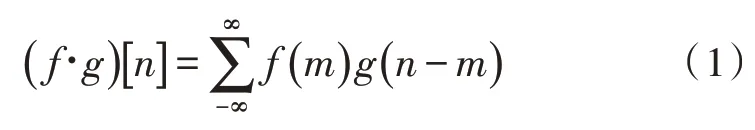
在离散域上的卷积运算需要合理的选择卷积核,卷积核通常是一个n2的矩阵。卷积运算的示意图如图2 所示。
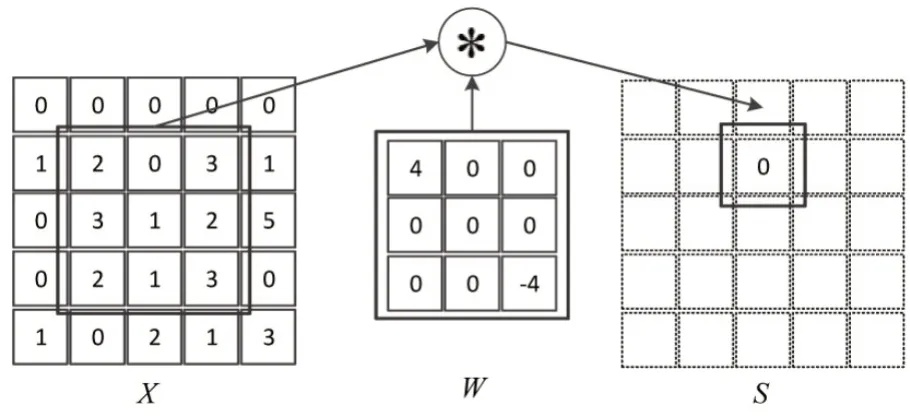
图2 卷积运算示意
在图2 中,W是使用的卷积核,使用的是3×3 的维度。卷积核可对特征的模式进行强化或隐藏,灵活地进行图像特征的提取。
1.1.2 池化层
池化层是指在卷积获得的特征中,选择某一局部区域替代完整区域,池化实现了特征的过滤与选择。常用的池化运算包括最大值池化与均值池化。其中,均值池化的运算方法如图3 所示[12]。
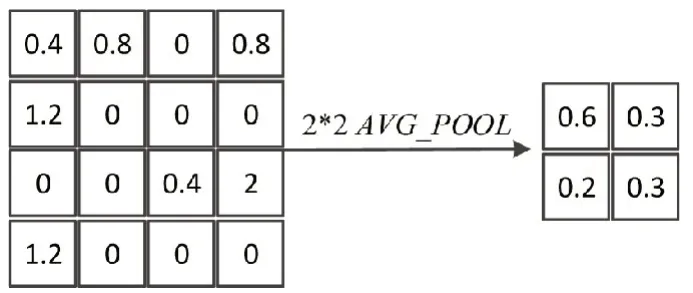
图3 均值池化运算示意图
对于卷积神经网络,池化层的引入实现了图像信息的降采样,可以有效地简化网络结构,防止出现过拟合。
1.1.3 全连接层
卷积神经网络的最末端是全连接层,全连接层对前一层的特征进行综合即可得到网络的分类器。其连接示意图如图4 所示。
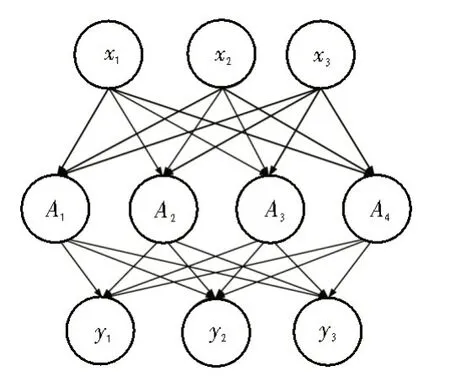
图4 全连接层示意图
全连接层的运算方式与传统单隐藏层的神经网络类似,通过连接权重与偏置连接输入层到隐藏层,以及隐藏层到输出层。其计算方式如式(2)所示。
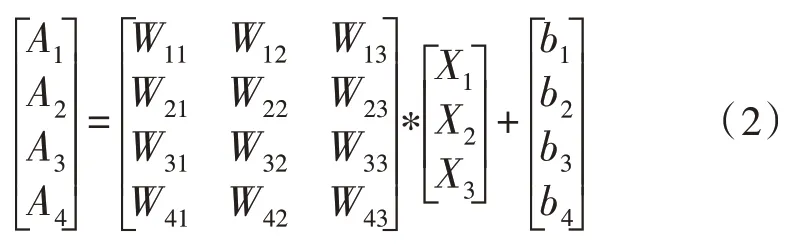
1.1.4 输出层
输出层借助非线性函数将全连接层的输出转化为深度网络的最终输出,对于二分类问题通常选择Logistic 函数。文中选择的是Softmax 交叉熵函数,其形式如式(3)所示。
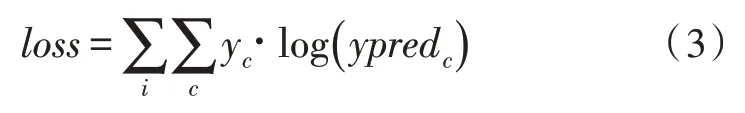
其中,c代表分类的类别,当输出结果与实际的类别一致时,yc=1。
1.2 基于时空域的双卷积神经网络
空间域中的特征提取方法与图像信息的提取方法一致,文中在时间域上的特征借助光流(Optical Flow)进行标识。循环神经网络如图5 所示,光流反映了空间内物体运动状态改变后像素的变化轨迹,在运动检测中有广泛的应用。其获取方法如下:
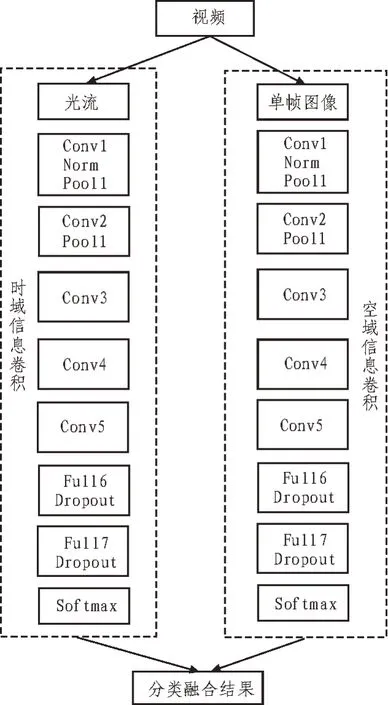
图5 循环神经网络
在时间t下对于空间坐标位置点O(x,y),该点像素亮度为I(x,y,t)。在dt时间内,下一帧内该点移动到新的位置(x+dx,y+dy)。此时,由于时间极短,该点的光亮度存在式(4)中的关系[13-15]。
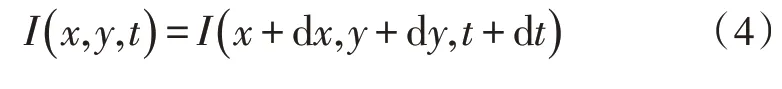
其泰勒展开式如式(5)所示。
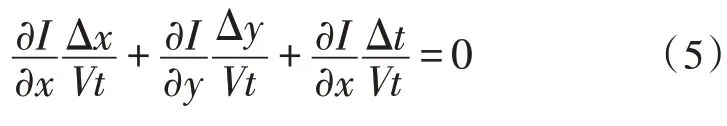
此时,可以得到该点的光流等式,如式(6)所示。
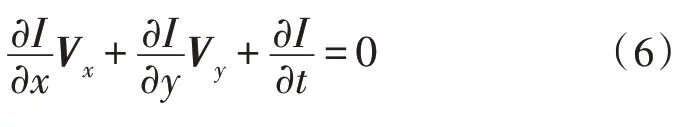
在式(7)中,Vx与Vy是光流矢量。从该微分方程中,求解光流矢量需要引入金字塔(LK)算法。
对于3×3 大小的像素区域,共包含9 个光流轨迹,用矩阵的形式可以表示为式(7)。

其中的变量如式(8)所示。
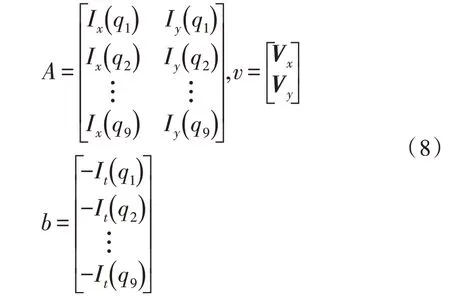
利用式(9)可以求解得式(10)。
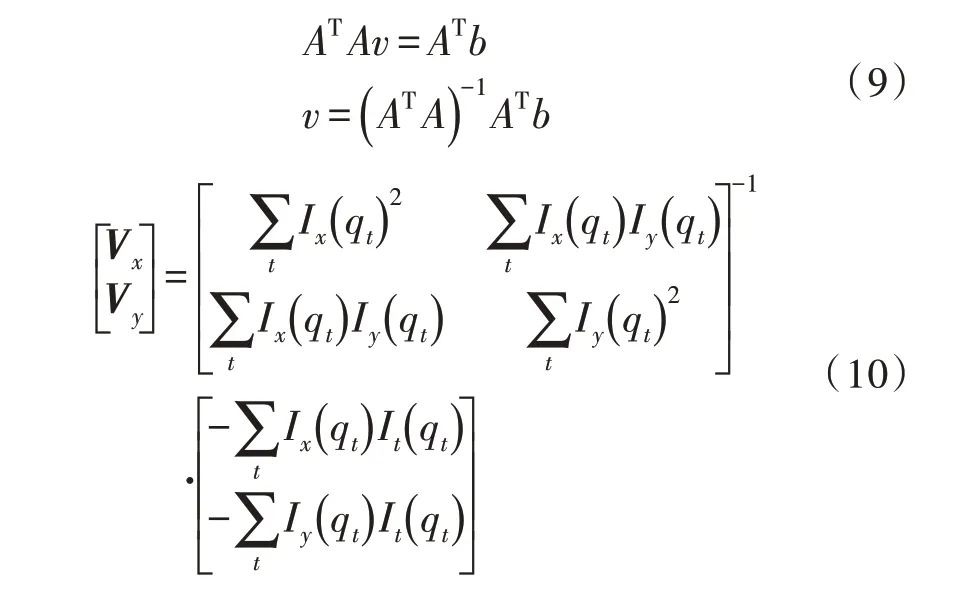
2 方法实现
2.1 实验设计
为了评估模型的有效性,文中在舞蹈视频动作数据集上进行了实验。该数据集的参数,如表1 所示。在该数据集内,存在101 个类别的舞蹈动作,视频的帧数均是25 fps,分辨率均为320×240,视频的时间长度在2.31~67.24 s 之间。部分视频帧如图6所示。

表1 数据集参数

图6 舞蹈动作视频数据集
为了衡量模型对于舞蹈动作的识别精度,文中使用深度学习中常用的评价指标F1 与MSE。这两个指标的定义方式如式(11)~(12)所示。
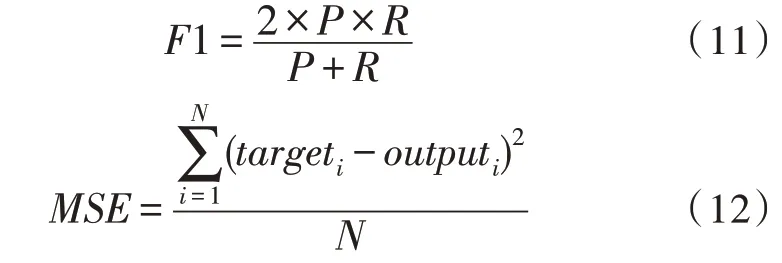
2.2 仿真结果
为了更优地衡量文中模型对于视频中舞蹈动作的识别效果,文中引入了两个已在工业上广泛使用的深度卷积网络:Inception V3 与3D-CNN 网络。其各自的网络参数设置,分别如表3、表4 所示。
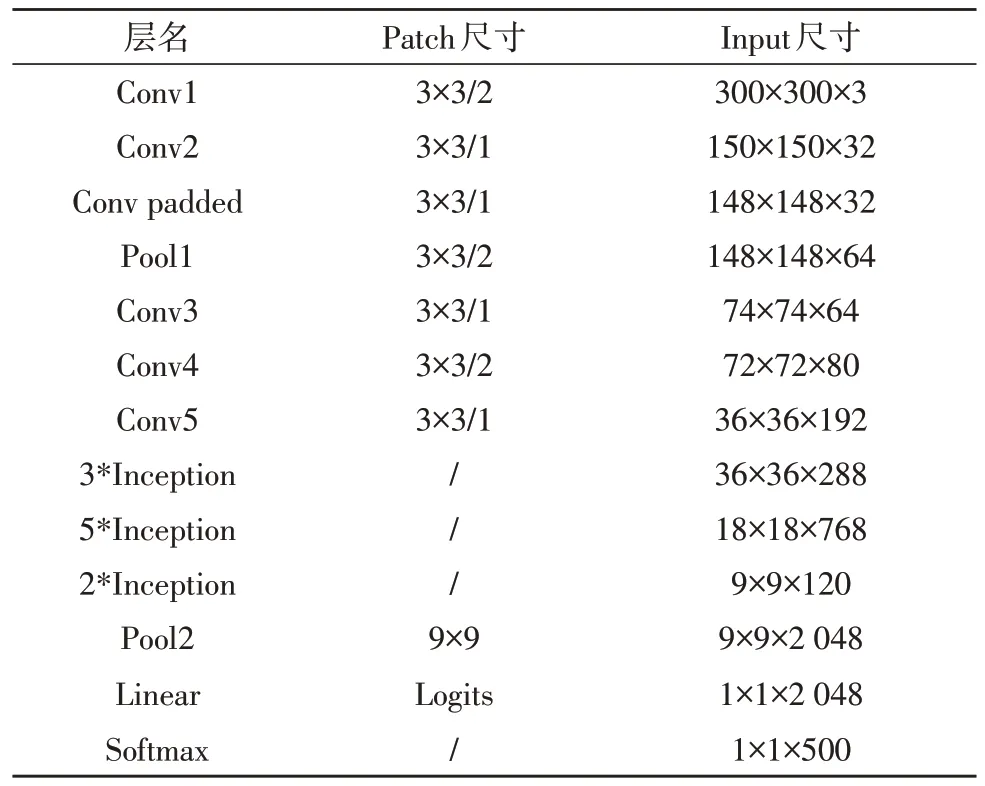
表3 Inception V3参数设置
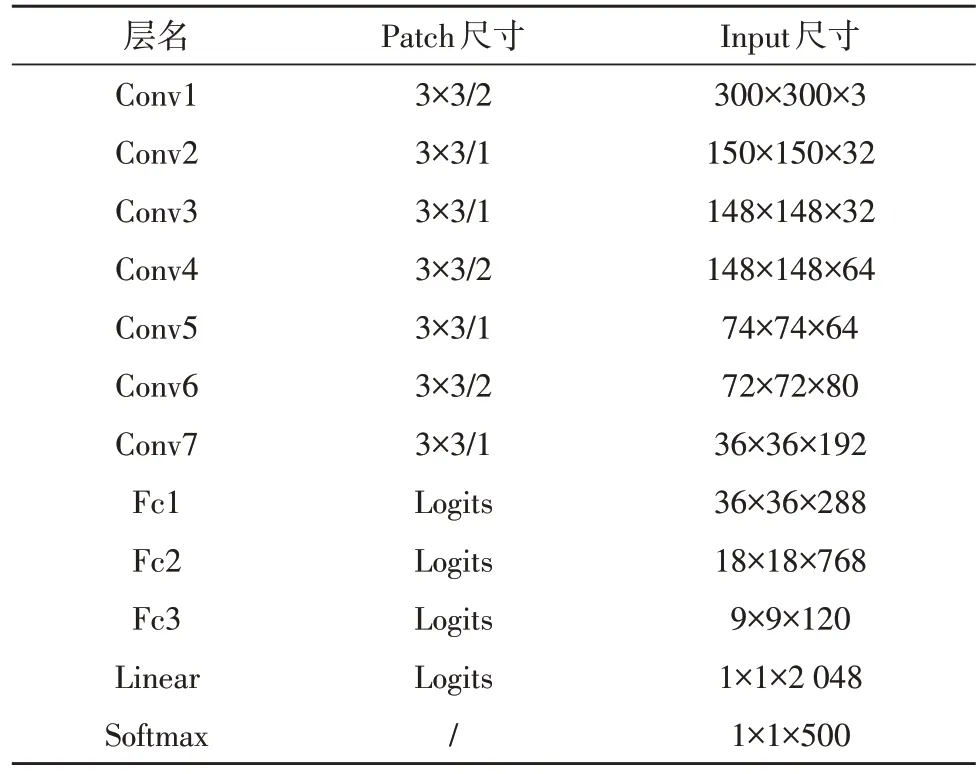
表4 3D-CNN 网络参数设置
表5 给出了文中双路卷积网络的参数设置,其采用两个相同的卷积结构。经过表3~5 的比对可以发现,3 个网络的复杂度基本一致。将表1 给出的视频数据库按照7∶3 的比例划分为训练集与测试集。3 个网络训练完成后,使用测试集进行测试。测试结果如表6 所示。
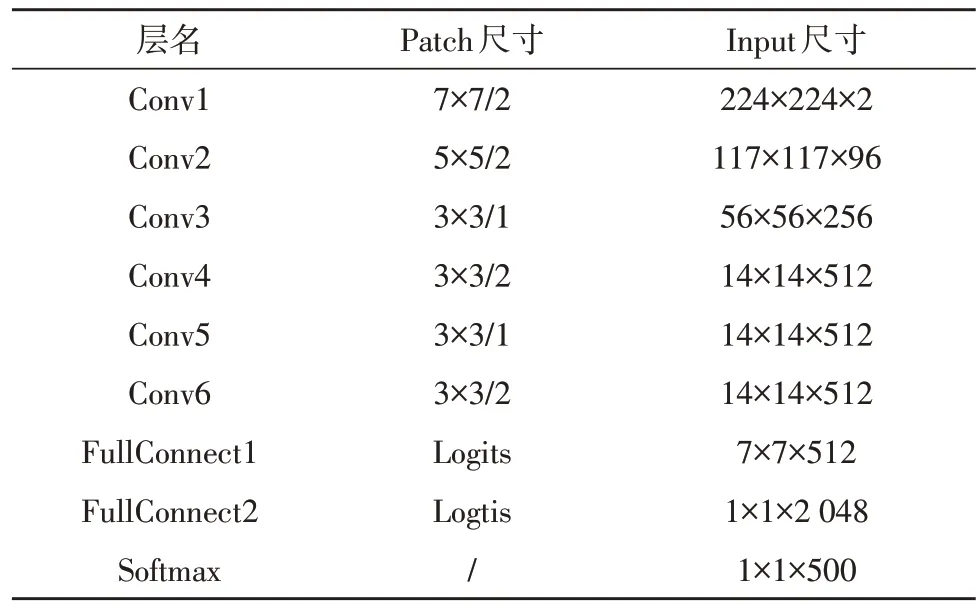
表5 双路卷积网络参数设置
从表6 的测试结果可以看出,在3 个网络中,网络F1 指标最差的是Inception V3 的69.32%,居中的是3D-CNN 网络,最优的是双路卷积网络,其较Inception V3 的F1 提升了10.90%。MSE与F1 是两个相互负相关的指标,表6 的第3 列数据较优地验证了这一数据趋势,证明了测试结果的有效性。从表6中第4 列对于舞蹈动作识别的准确率来看,文中提出的双路CNN 算法由于引入了手工提取的时域光流信息,对于Inception V3 与3D-CNN 网络分别有10.85%与5.27%的提升。
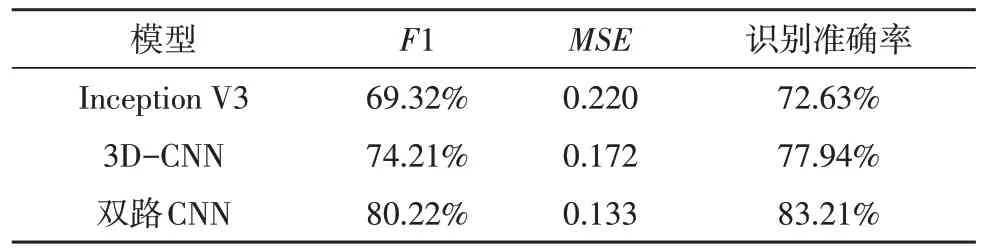
表6 3个网络性能对比
3 结束语
文中对视频动作的识别方法进行了研究,通过对传统的深度卷积网络的调研发现,这些深度网络提取的特征更多是空间维度的信息,缺乏时域信息的提取,影响了动作识别的精度。文中使用光流信息表征时域动作的状态变化,构建了双路卷积网络,大幅度提升了舞蹈动作的识别精度。在后续的研究中,可以继续优化时域卷积网络的结构,提升算法的性能。
