一种基于LSTM 的机器阅读理解模型
2021-06-11刘鑫
刘鑫
(武汉邮电科学研究院,湖北 武汉 430074)
机器阅读理解(Machine Reading Comprehension,MRC)的研究目标是让计算机读懂文章,并像人类一样回答与文章相关的问题[1],在需要自动处理和分析大量文本内容的场景下,机器阅读理解都可以节省大量人力和时间,因此,机器阅读理解成为当前人工智能研究中最前沿、最热门的方向之一。该文以百度深度学习研究院(Baidu Research-Institute of Deep Learning,IDL)提出的神经递归序列标注(Neural Recurrent Sequence Labeling,NRSL)模型[2]作为基础模型,对开放域下事实类问答任务进行研究。
原模型通过LSTM+CRF[3]将MRC 转换为序列标注问题,但是面对一段材料多次出现答案的情况,CRF 的表现并不是很好,而且直接对材料中的词进行判断标注,未免对模型太过严苛。针对这些问题,文中采用字词混合Embedding 编码和半指针半标注解码的方式来改善、提升机器阅读理解任务的精度。
1 相关工作
MRC 旨在利用算法使计算机理解文章语义并回答相关问题,当前MRC 主要分成4 个任务:完形填空、单选、跨度提取、自由问答[4],文中研究的是后两者,即抽取式问答。最近几年,由于深度学习的兴起[5],众多优秀的机器阅读理解模型脱颖而出,这些模型在网络架构、模块设计、训练方法等方面实现了创新,大大提高了算法理解文本和问题的能力以及预测答案的准确性。
文献[2]提出的NRSL 模型,文献[4]提出的双向注意力流(Bi-Directional Attention Flow,BiDAF)模型[6]算得上中文机器阅读理解的开山之作,成为了之后众多MRC 模型参照的典范。之后的模型创新大多集中在网络结构的创新及优化,但是对模型的输入编码和输出解码模块优化也是有重要意义的,该文就是在研究前人模型的基础上,重点研究优化编码解码模块来提升模型的精度。
2 模型构建
2.1 模型整体架构
整个模型的架构图如图1 所示,主要由3 个模块组成。首先提取问题特征的LSTM 层,然后是三层LSTM,用来分析证据,最后便是用来解码答案的半指针半标注模块。
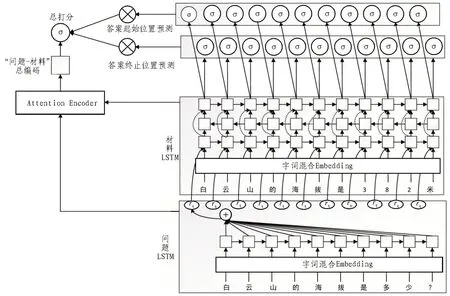
图1 模型整体架构
2.2 字词混合Embedding
词作为最小的能够独立活动的有意义的语言成分,在机器阅读理解模型中被广泛地作为模型的输入,单个字虽然没有具体的语义,但却十分灵活。比如在标注模型中,为了最大程度上避免边界标注错误,使用以字作为基本单位输入比以词作为基本单位输入要好得多,考虑到这一点,若是能综合字和词的各自优势,对模型的提升应该是十分显著的。
为了让模型兼顾字的灵活和词的语义,该文使用字词混合Embedding 作为模型输入,其编码过程如图2 所示,它的原理很简单,就是将词向量通过变换矩阵转换成和字向量相同的维度,再将转换结果和字向量相加,从另一个角度看,也可以认为是通过字向量和变换矩阵对Word2Vec[7]的词向量进行微调。
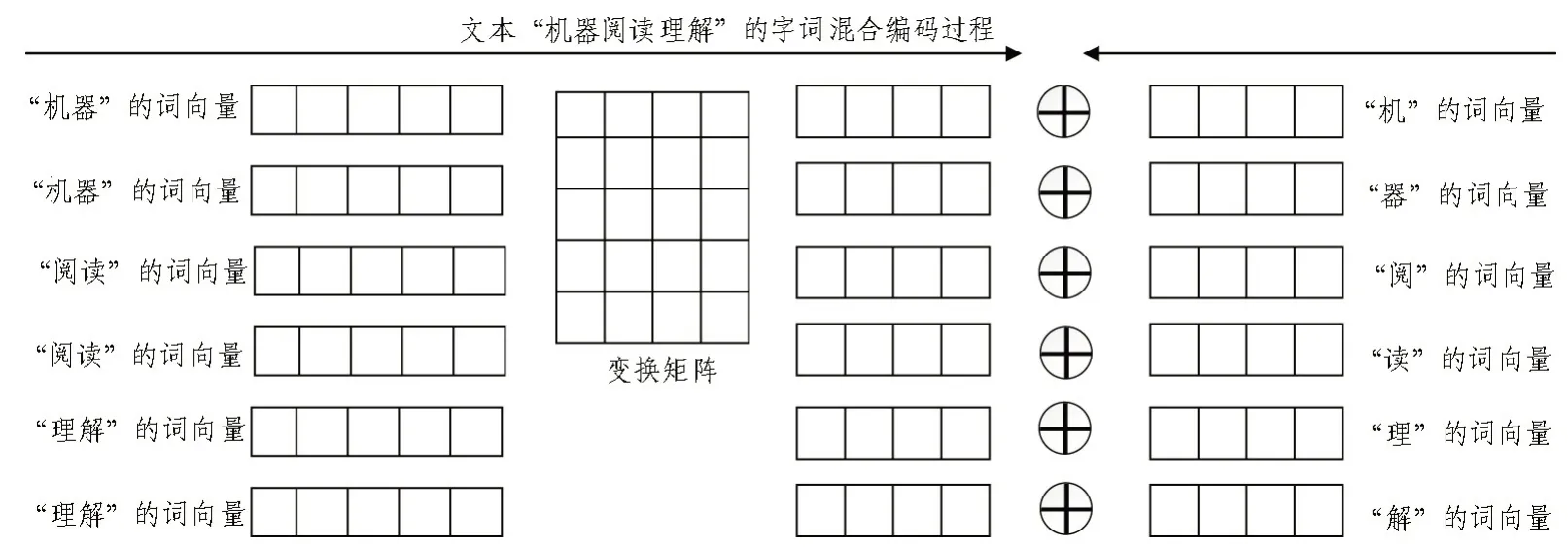
图2 字词混合Embedding原理图
2.3 LSTM模块
长短时记忆网络LSTM 是一种特殊的RNN,是专门设计用来避免长期依赖问题的。LSTM 默认记忆长期信息,而不需要额外的条件。
定义函数(s′,y′)=LSTM(x,s,y)作为LSTM 层的输入和输出的映射,其中,x为经字词混合Embedding 模块编码后的问题向量,s为先前状态,y为输出,s′,y′为当前状态和当前输出,它们的计算方式如式(1):
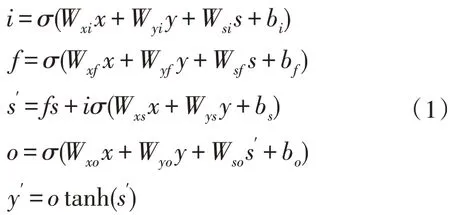
其中,W*∈RH×H为参数矩阵,b*∈RH为偏移量,H为LSTM 层的宽度,σ为sigmoid 函数,i、f、o依次为输入门、遗忘门和输出门,LSTM的原理图如图3所示。
文中模型的问题和证据均用LSTM 进行分析,问题采用一层单向LSTM 分析,然后通过简单的加性注意力[8-9]和材料向量融合作为材料LSTM 分析模块输入,该模块由三层LSTM 组成,第二层LSTM 为反向LSTM,第三层LSTM 接收前两层的输出。
用xq=表示问题向量输入,表示证据向量输入。问题LSTM 为单层LSTM,对xq经LSTM 分析后,生成向量序列q1,q2,…,qN,其映射关系如式(2):
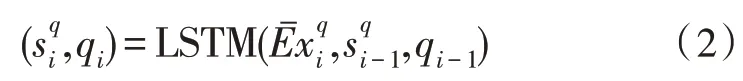
材料LSTM 由三层LSTM 构成,第一层LSTM 的输入为rq和材料的字词混合Embedding 通过加性注意力机制融合的定长向量,第二层LSTM 堆叠于第一层之上,但是以相反的顺序处理它的输入,第三层LSTM 将第一层和第二层的输出作为输入,它的输出将作为答案解码模块的输入,具体的计算方法如式(3)所示:

2.4 半指针-半标注解码
答案解码模块对整个模型精度的影响也是十分大的,文中将原模型中的CRF 替换为半指针-半标注的模式。
既然用到标注,那么理论上最简单的方案是输出一个0/1 序列:直接标注出材料中的每个词是答案(1)或不是答案(0)。然而,这样的效果并不好,因为一个答案可能由连续多个不同的词组成,要让模型将这些不同的词都标上同样的标注结果,还是十分困难的。所以用两次标注的方式,来分别标注答案的开始位置和终止位置,其计算方式如式(4):
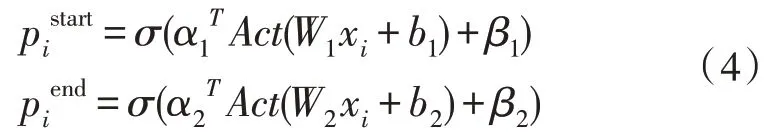
其中,Act为激活函数,这里取sigmoid 函数。为了应对材料中无答案的情况,引入pglobal对整个问题和文档信息编码[10],得到一个全局打分,并把这个打分的结果乘到前面的标注中,即变成式(5):
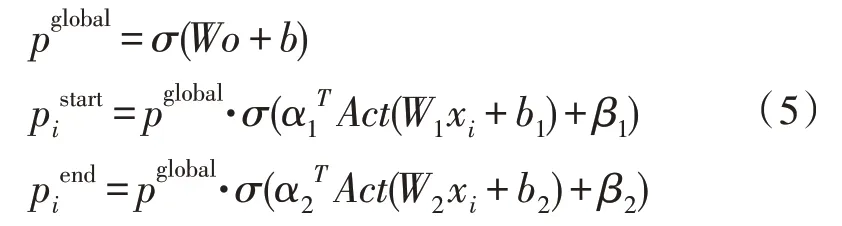
这里的o即为问题和材料的整体向量,当材料中无答案时,即可直接使pglobal=0,不用让每个词的标注都为0。
pstart、pend分别代表了答案起始位置和终止位置的概率,但问题是,用什么指标确定答案区间呢?文中的做法是确定答案的最大长度M,然后遍历材料所有长度不超过M的区间,计算它们起始位置和终止位置的打分的积,然后取最大值。对每段材料都得到了自己的答案的情形,又怎么把这么多段材料的答案投票出最终的答案?比如有5 段材料,每段材料得出的答案和分数依次是(A,0.7)、(B,0.2)、(B,0.2)、(B,0.2)、(B,0.2),那么最终应该输出A还是B呢?
为了综合考虑权重大和答案多的情况,这里将采用取“平方和”的思想,因为“平方”会把高分的样本权重放大,而对小样本将其加一置于分母位置,这样其得分就会降低,其计算方式如式(6):

3 实 验
3.1 数据集简介
该文数据集采用WebQA(百度问答数据集现在已更新为DuReader[11]),WebQA 和DuReader 的实体类问答很类似,答案包含在材料中,该文正是对这类问答进行抽取式阅读理解[12]任务研究。
WebQA 包含42k 个问题,566k 个材料片段,一个数据由问题、证据、答案构成,材料样例如下:
问题:多瑙河注入哪个海?
材料1:多瑙河注入黑海,顿河注入亚速海,莱茵河注入北海
答案:黑海
材料2:泰晤士、莱茵河、易北河注入北海,莱茵河、多瑙河流入黑海,都属于大西洋水系。
答案:黑海
材料3:多瑙河发源于德国西南部山地,向东流经9 个国家,最后在罗马尼亚注入黑海。
答案:黑海
每个问题对应多段材料,每段材料对应一个答案,这个答案可能为空。这些问题均是由真实生活中的用户在日常生活中提出的,因此很有代表性。该文将数据随机均分成8 份,6 份作为训练集,一份作为验证集,一份作为测试集。
该文所用的词向量由WebQA 语料、50 万百度百科条目、100 万百科知道问题用Word2Vec 预训练而成[13]。
3.2 模型训练
模型训练采用交叉验证[14],评估参数为查准率P(Precision)、查全率R(Recall)和P、R的调和平均值F1。
模型的预测值有两个,为答案的起、止位置,该模型使用的损失函数源于交叉熵的思想,其计算方式如式(7):
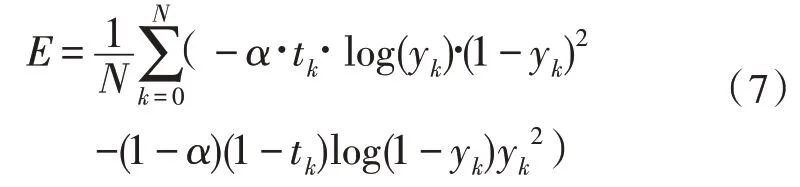
其中,tk为真实值,yk为预测值,模型的整体损失函数取两者之和,即为式(8):

为了降低周期性干扰,训练过程中对权重进行了指数滑动平均,优化器采用了RAdam(Rectified Adam)[15]。此外,模型输入词向量维度为128,材料限制最大输入长度为256,答案最大长度限制为10,模型训练120 epoch。
4 实验结果及分析
使用的评测标准有P、R、F1,该文优化后的模型与原模型及一些经典的模型对比数据如表1 所示。
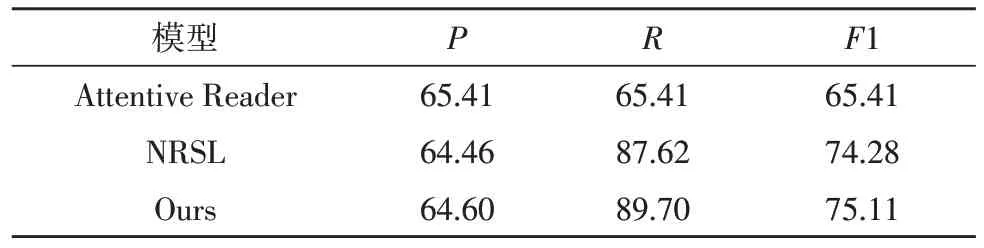
表1 模型实验结果
从表1 可以看出,文中模型相对于原基础模型在准确率和召回率上都有了一定的提升,尤其是召回率R的提升比较明显。
通过字向量对输入的词向量进行微调,兼顾字向量的灵活和词向量的语义,再加上半指针-半标注答案解码模型的引入,在面对答案由多个词组成以及一段材料中多次出现答案的情况,模型对答案起止位置标注的准确率有所提升,最终再通过半指针-半标注及投票的方式抽取出答案,从而提升了模型的精度。
5 结论
该文采用字词混合Embedding 作为MRC 模型的输入编码,参考NRSL 模型结构,使用单层LSTM 对问题进行分析,三层LSTM 对材料进行分析,将CRF标注改进为半指针-半标注的答案解码模块,最终使模型的准确率和召回率都有了一定的提升。虽然该文的改进对模型性能的提升有限,但是也不可忽略对模型的输入编码和输出解码模块进行优化带来的收益,针对不同的网络结构,对编码解码模块进行对应的优化,能最大程度提升模型的整体性能。
随着信息时代的到来,文中的规模呈爆炸式增长[16]。因此,机器阅读理解带来的自动化和智能化恰逢其时,在工业领域和人们生活的方方面面都有着广阔的应用空间。因此深入研究机器阅读理解的原理,从各方面改进模型、提升模型的精度和性能,有着十分重要的价值和意义。
