基于改进VGG16的大米加工精度分级方法研究
2021-06-09陈哲琪陈坤杰
戚 超 左 毅 陈哲琪 陈坤杰
(南京农业大学工学院,南京 210031)
0 引言
水稻产量占世界谷物总产量的1/3左右。全世界种植水稻的国家有100多个,全世界约1/3的人口以大米为主食,大米品质对人类生活及健康至关重要[1-3]。
稻谷经清理、砻谷、碾米等工序后制成大米。除与品种、产地、生长气候等因素有关外,大米品质还与加工精度密切相关。市场上销售的大米通常按照GB/T 1354—2018标准进行分级,即大米的加工精度分成3个不同等级。对于按照原标准加工的4级大米则不允许流入市场,但掺入4级大米进入市场的情况非常普遍。由于大米加工精度的准确分级直接影响消费者的利益,因此有必要对4级大米进行检测。中国每年出口大米100万t以上,由于大米品质检测低效、分级精度不高等问题,导致中国大米在国际市场上竞争力不足,落后于美国、日本、泰国等国家。因此,急需一种快速、高效的大米加工精度分级检测方法[4-6]。
机器视觉技术具有非破坏性、成本低、速度快等特点[7-10]。传统的机器视觉分类方法通常根据设定的特征提取规则提取多个特征,并用于训练分类模型,其弊端是对有效信息造成损失。KUO等[11]提出了一种非破坏性的方法,采用图像处理和基于稀疏表示的分类(SRC)来区分30个品种的稻谷。DEVI等[12]提取形态图像特征,并将其输入实时的神经网络系统中,对印度香米进行分级,得到更高的分级准确性。SINGH等[13]提出使用图像处理和机器学习的方法,根据形状和纹理特征对4种不同的稻谷图像进行分类,然后将特征向量反馈到SVM,以进行多类分类。VGG16卷积神经网络是牛津大学视觉几何组提出的深层特征提取网络,通过增加网络深度能够提升网络的最终性能,可直接将原始图像信息作为网络输入,由卷积层训练数据进行特征学习,从而充分提取了有效信息,在图像识别领域获得了广泛应用[14-19]。
本文以大米生产线分级环节中的大米为研究对象,采集4个等级的大米图像信息,提出基于改进VGG16卷积神经网络的大米分级检测方法,对大米加工品质的4个等级进行检测与识别,探究大米加工精度等级检测的可行性。
1 材料和方法
1.1 样本数据
1.1.1试验材料
从南京市六合区远望富硒大米专业合作社采购1、2、3级远望稻花香系列富硒大米各100 kg,采购远望稻花香系列富硒大米的稻谷100 kg作为4级大米,在南京农业大学博远楼A304实验室对稻谷进行砻谷和碾米,碾米机的碾白度设置为最高值9。
1.1.2试验仪器与设备
LGJ4.5型检验砻谷机(浙江省台州市粮仪厂),JNMJ3型检验碾米机(浙江省台州市粮仪厂),维视MV-EM510C型工业相机及4.0 mm焦距镜头(陕西维视数字图像技术有限公司),黑色背景布(娇颖布艺公司),试验台(南京农业大学),MSI便携式计算机(台湾微星科技公司)。
1.1.3图像采集
根据大米图像的采集需求,自主设计了一套图像采集装置,试验装置由试验台、工业相机、计算机、光源、暗箱、黑色背景布等组成。采用MV-EM510C型工业相机及4.0 mm焦距镜头,像素尺寸3.45 μm×2.2 μm,帧率15 f/s,曝光时间为30~5 000 000 μs,以太网与计算机相连,相机通过云台夹固定在暗箱顶端,距离被测物体约30 cm,照明光源采用两个LED 灯;黑色背景布平铺在试验台上,抓取任意数量的1级大米,随机放置在黑色背景布上,进行图像采集工作,将采集完的大米取出放入对应等级的袋子中,黑色背景布上重新放置大米,所有大米图像都采集完记为采集一轮,总共进行13轮。1~4级大米依次操作,有效图像共5 848幅,部分样本图像如图1所示。
1.1.4训练环境配置
操作系统为Windows 10,Python版本为3.6.4,使用pip进行Python包的管理和安装。软件为基于Tensorflow-gpu 1.14.0的Keras 2.2.4。硬件平台使用i7-8700CPU,显卡为NVIDIA公司的Geforce GTX 1070显卡,8GB显存版本。CUDA为10.0版本,对应cudnn为7.6.5.32版本。
1.1.5数据集制作
为了增加样本的多样性,防止训练过程中过拟合现象出现,使用有监督的数据增强方法,对单样本数据进行增强,将分辨率为2 592像素×1 944像素的大米图像裁剪成分辨率为224像素×224像素的RGB三通道彩色图像,为了便于计算,使用机器学习中的OneHot格式进行编码,用4位状态寄存器编码4个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,图像的具体数量和对应编码如表1所示。
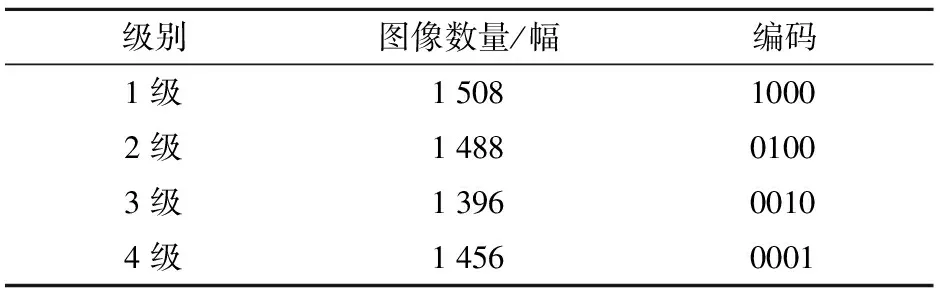
表1 4种级别大米数据图像数量和对应的OneHot编码
本文图像像素尺度为0~255,但种类尺度为0~3,为了方便将所有样本数据放在同一尺度下进行衡量和避免梯度消失或有梯度爆炸问题,需要对数据进行归一化,将所有数据限制在尺度相同的范围内。归一化主要有两种方案,一种为标准归一化,可以将数据更改为均值为0、方差为1的正态分布,大部分数据都集中在-1~1区间内,便于求导求梯度,但这种方法需要对数据的均值和方差预先求值。另一种为最大最小归一化,本文图像像素的最大值为255,最小值为0,因此使用最大最小归一化法。
本文模型利用数据进行学习、调参和测试,其中60%数据(3 509幅大米图像)作为训练集,30%数据(1 755幅大米图像)作为测试集,10%的数据(584幅大米图像)作为验证集。验证集没有参与反向传播过程,不会影响测试集评价的客观性和准确度,仅供进行调参工作,随机均匀地从3个数据集合中抽样,每个数据集的抽样比例都与原数据集相同。
1.2 VGG16网络结构
VGG16网络结构如图2所示,输入分辨率为224像素×224像素的3通道大米图像进入卷积层。在结束卷积操作后,对输入数据批归一化处理,作用是在经过非线性函数映射后,将取值区间向极限饱和区靠拢。强制拉回到均值为0、方差为1的标准正态分布。最后进入池化层,逐渐忽略局部特征信息。循环4轮以上操作,在卷积操作完成后,大米特征信息进入全连接层,将包含有局部信息的特征图,包括特征图的高、宽、通道数全部映射到4 096维度,最后针对本文多分类任务,在输出层使用4个神经元,配合Softmax分类器进行大米加工精度分级。VGG16网络结构中,卷积层均采用3×3卷积核,步长为1,填充方式为SAME,使每一个卷积层与前一层保持相同的宽和高。池化层均采用2×2池化核,填充方式为SAME,激励函数为ReLU。
1.3 改进VGG16卷积神经网络
1.3.1超列技术
本文中将靠近输入的卷积层称为底层卷积层,靠近输出的卷积层称为高层卷积层。在卷积神经网络中,越底层的卷积层包含的特征信息越具体,如大米的空间位置、清晰度、背景亮度等,越高层的卷积层包含的特征信息越抽象。在传统的卷积神经网络中,通常使用最后一层的输出作为特征表示,但是同一种类大米与很多特征明显的物体不同,因为背景图像、米粒形状、颜色等相似,使得高层卷积层的大米特征信息在通道维度中太粗糙,分类效果较差。基于此,本文提出基于超列技术[20]的特征提取方法,如图3所示。VGG16模型中有16层权重层,其中包括13层卷积层和3层全连接层,超列技术针对13层卷积层,最后3层全连接层在VGG16模型中作为分类器,不具备特征提取能力。对于输入图像通道i位置的像素,每一个通道相同位置的像素都对应着大米特征信息,称之为大米特征的超列。将13层卷积层中的所有通道i位置的特征加起来,同时加上全连接神经网络的1 024个深层特征,对5 248(1 024+64×2+128×2+256×3+512×6)个大米特征进行分类。
超列技术是一种掩蔽技术,在原始图像上叠加了从卷积神经网络模型的前13层中获得的有效特征。这使得原始图像更加可见,并增加了特征数量。通过超列技术从1~4级大米图像中获取掩码图像的热力图,如图4所示,超列掩模在卷积神经网络结构中将原始图像的每一个像素作为一系列向量来承载底层的特征。在本研究中,由于在掩蔽步骤中使用了3个主要的彩色通道,因此获得了彩色掩模,目标是产生更有效的特性,因为颜色通道会影响输入图像的深度和分辨率。
1.3.2最大相关-最小冗余特征选择
分类问题中,在相关图像特征中选择有效的特征数据集是非常重要的,选择出好的图像特征具有减少特征数量、减少GPU处理时间、减少噪声、检测到更有特色特征等优点。图像特征在经过卷积、池化、超列等操作后,由于大米图像的特殊性,造成大米特征图像大量相似,产生大量冗余特征,选择传统的特征选择方法往往需要花费大量的时间,故本文使用最大相关-最小冗余(MRMR)特征选择算法[21-22]进行特征选择。
MRMR算法根据特征与类标记的相关性列出特征,旨在使用所选的特征集选择最不相关的特征向量,目的是在存在其他所选特征的情况下通过其冗余来惩罚特征的相关性。MRMR算法原理如下:
MRMR算法通过消除大米特征数据集中的无关特征,计算特征和特征标记之间的相似性,得到互信息M(x,y)。给定两个随机变量x和y,他们的概率密度函数(对应于连续变量)为p(x)、p(y)、p(x,y),则互信息计算公式为
(1)
大米特征集A与类b的相关性由大米特征fi和类b之间的所有互信息值的平均值定义。
(2)
式中D(A,b)——大米特征集A与类b的相关性函数
M(fi;b)——大米特征fi和类b之间的互信息
特征集A中所有特征的冗余是特征fi和特征fj之间的所有互信息值的平均值,计算公式为
(3)
式中R(A)——大米特征集A中所有特征的冗余
M(fi;fj)——特征fi和特征fj之间的互信息
1.3.3极限学习机分类器
传统的一些基于梯度下降的算法,需要在迭代过程中调整所有参数,极大地增加了大米特征的处理速度,而在大米加工应用领域,大米等级判定的速度直接和利益挂钩,所以需要选择一种能够快速分类图像特征的分类器。本文提出使用极限学习机(ELM)分类器[23]进行特征选择后的分类工作,工作原理如图5所示。
ELM是一种快速分类算法,对于单隐层神经网络,ELM可以随机初始化输入权重和偏置并得到相应的输出权重。假设有N个任意样本(xi,ti),其中xi=[xi1xi2…xin]T∈Rn,ti=[ti1ti2…tin]T∈Rm。一个有L个隐含层节点的单隐层神经网络,可以表示为

(j=1,2,…,N)
(4)
式中L——隐含层节点数量
g——激活函数
βi——第i个大米特征的输出权重
Wi——第i个大米特征的输入权重
Xj——大米特征矩阵
bi——第i个隐含层单元的偏置
Oj——第j个大米特征隐含层节点预测输入
单隐层神经网络学习的目标是使输出误差最小,可以表示为
(5)
式中tj——第j个大米特征隐含层节点真实输入
即存在βi、Wi和bi使得
(6)
所以预测输出矩阵为
Hβ=T
(7)
式中H——隐含层节点的输出矩阵
β——输出权重
T——期望输出矩阵
为了能够训练单隐层神经网络,需满足
(8)
式中E——最小化损失函数
在ELM算法中,一旦输入权重Wi和隐含层偏置bi被随机确定,隐含层输出矩阵H就被唯一确定。训练单隐层神经网络可以转化为求解一个线性系统Hβ=T,并且输出权重β可以被确定为
β=H-1T
(9)
1.3.4改进VGG16网络结构
改进VGG16网络结构由3部分组成。首先使用图像增强技术确保数据在类之间均匀分布,以提取出更有效的特征。然后利用平衡数据集上的超列技术,使图像特征更加突出。在VGG16模型中,从前几层得到的特征以向量格式保存在全连接层中,利用MRMR对全连接层的5 248个深层特征进行评价。最后采用极限学习机分类器算法提升大米现实加工问题的泛化性能。改进VGG16网络结构如图6所示。
1.3.5模型训练
本文采用交叉验证的方法来训练模型,对于改进VGG16网络结构,ELM分类器采用ReLU激活函数应用MRMR算法选择最大相关最小相关特征,跳过传统MRMR算法利用增量搜索方法逐步寻找最优特征子集,而是直接对于每一个特征利用式(4)计算其重要性,然后对大米特征的重要性降序排列,分别提取最重要的前100、500、1 000、2 000、3 000、4 000、5 248个特征子集,传递给极限学习机分类器进行比较。
1.3.6评价指标
为对大米加工品质等级分类模型的性能进行评价,选定召回率(Recall,R)、精确度(Precision,P)、F1测度(F1 score,F1)和准确率(Accuracy,A)作为模型预测性能的评价指标。
2 试验结果与分析
2.1 改进VGG16模型性能评估
将MRMR算法应用于5 248个大米特征集合。5 248个特征被划分为7个包含5 248、4 000、3 000、2 000、1 000、500、100个特征的特征集,并映射到ELM分类器,ELM结构中的隐藏节点在训练过程中具有重要作用,采用试差法,选取具有ReLU激活函数的3.5万个隐藏节点作为研究对象。结果如表2所示。
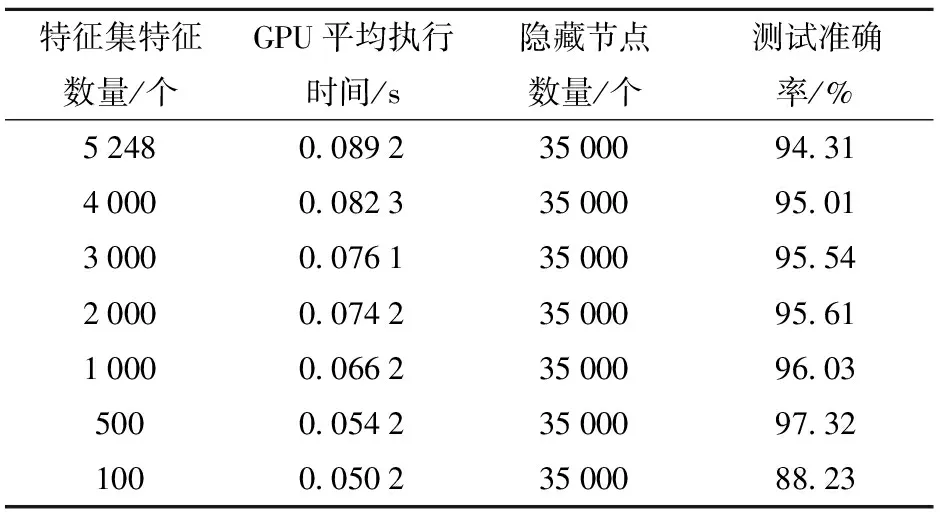
表2 7种不同特征集分类结果
从表2中可以看出,包含500个特征的特征集的分类效果最优,准确率最高为97.32%。为了找出最优特征子集,在500个特征子集中,每100个特征子集进行一次试验,选取包含200、300、400、500、600、700、800、900个特征共8种特征子集进行试验,采用相同训练环境,试验结果如表3所示。
从表3中可以看出,特征集特征数量为500时准确率最高。从试验结果可以看出,特征数量并不总是对分类性能产生积极影响,相反会导致低效特征的增加。为了消除这一影响,需要采用特征选择算法。利用MRMR算法筛选出最优的500个特征,测试准确率为97.32%。
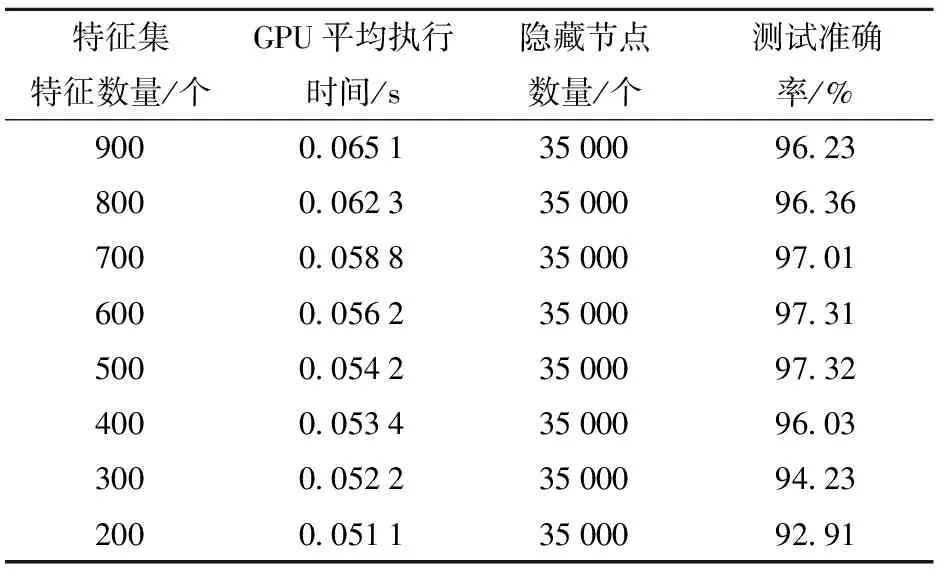
表3 8种特征子集分类结果
根据最优特征选择的500个特征和改进VGG16大米加工精度分级模型对测试集的1 755幅大米测试样本的等级进行预测,其结果如表4所示。由表4可知,基于改进VGG16的大米加工精度分级模型对3级大米的预测召回率最高,达到98.63%,其原因可能是训练集中该类别样本数大于其他3个类别,使得召回率虚高。模型对1级大米的预测召回率次之,为96.82%;对2级大米的预测召回率最低,为96.15%。就模型的总体分类性能而言,基于改进VGG16大米加工精度分级模型对1级大米的总体分类性能最佳(F1测度为97.34%),其原因可能是1级大米的形态特征相较于其他3个类别更易于区分。基于改进VGG16大米加工精度分级模型预测的总体准确率为97.32%,GPU预测单幅图像的平均时间为0.054 2 s,每小时可以完成85 t大米的等级分类。
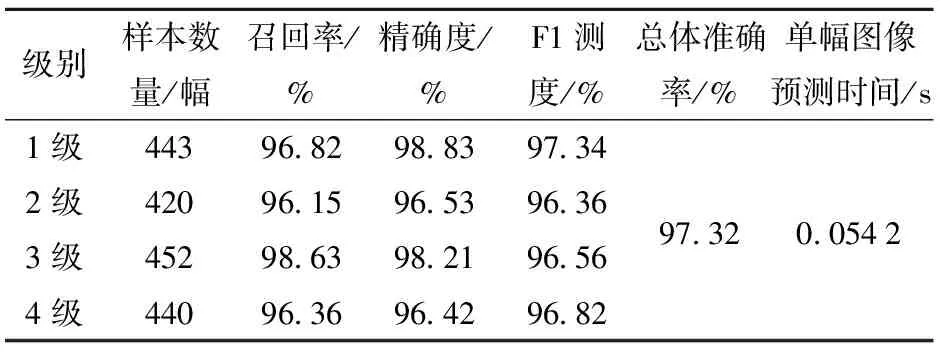
表4 改进的VGG16大米等级分类模型结果
2.2 改进VGG16模型和经典分类模型的对比
为了充分比较改进VGG16模型的性能,本文将ImageNet预训练模型、VGG16模型、ALEXNET模型和BP模型[24]的超参数在原参数值基础上进行反复调参,最优超参数如表5所示。

表5 3种预训练模型的超参数
从keras.optimizers中选取所需的优化器,优化器可以根据得到的导数结果选择合适的优化方向,使用RMS优化器优化,相较于Adam优化器精确度更高,相较于梯度优化器速度更快。学习率代表每次沿梯度方向修改的长度;衰减率用于计算迭代过程中的学习率,能够让学习率越来越小。损失值用于计算模型预测值与真实值的不一致程度;批尺寸表示一次训练所选取的样本数,影响模型的优化程度和速度。
VGG16、ALEXNET、BP 3种分类模型都是在图像分类领域表现优秀的模型,与改进VGG16模型进行分类性能比较,结果如表6所示。
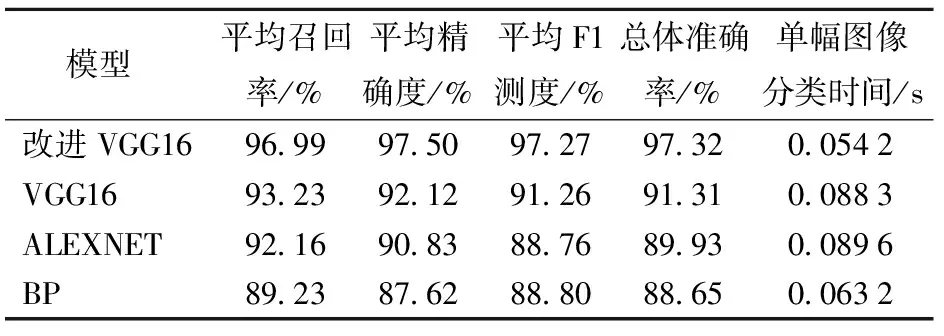
表6 4种模型分类结果对比
从表6可以看出,改进VGG16模型各项性能明显优于VGG16模型,总体准确率比VGG16模型提高了6.01个百分点,平均单幅大米图像分类时间比BP模型缩短了0.009 s,说明改进VGG16模型能够有效地对大米等级进行分类。
3 结束语
提出了用于大米加工精度分类的改进VGG16模型,并进行了试验验证。结果表明,改进VGG16模型的总体准确率达到97.32%,比VGG16模型提高了6.01个百分点。卷积操作产生的冗余大米特征会影响结合了超列技术的改进VGG16模型的分类精度,为此引入MRMR算法,筛选出最有效的500个大米特征。改进VGG16模型在GPU上预测单幅大米图像的分类时间为0.054 2 s,比BP模型缩短了0.009 s,对大米加工精度的分级预测速度高于85 t/h。改进VGG16模型的性能基本满足大米加工生产线精度分级要求,可为后续研制大米加工精度在线分级系统提供理论支持。
