大数据框架下公共政策实施评估研究
2021-06-08杨志新高翔张庆张狄
杨志新 高翔 张庆 张狄
摘 要: 公共政策涉及到对社会资源的分配和协调,与社会大众的利益密切相关。对公共政策实施进行科学评估有利于提升政府施政能力。传统评估方式存在一定局限,利益相关方参与度不够。本文基于互联网大数据对公共政策实施评估进行了研究。通过对论坛、微博等互联网站点在政策出台后一段时间(如半年)的海量数据,以及部分用户行为数据,进行聚类分析,建立公共政策实施评估指数模型。
关键词: 公共政策; 互联网数据; 聚类分析; 指数模型
中图分类号:TP399 文献标识码:A 文章编号:1006-8228(2021)01-124-04
Research on public policy implementation evaluation with Internet big data
Yang Zhixin1, Gao Xiang2, Zhang Qin2, Zhang Di2
(1. Development research center of Hunan province government, Changsha, Hunan 410011, China; 2.Changsha Tianxinge big data research institute)
Abstract: Public policy is related to the distribution and coordination of social resources, and is closely related to the interests of the public. Scientific evaluation of the implementation of public policies is conducive to improving the governance capacity of the government. There are some limitations in the traditional evaluation methods, and the participation of stakeholders is not enough. This paper studies the public policy implementation evaluation with Internet big data. Based on the massive data of forum, Microblog and other Internet sites in a period of time (such as half a year after the policy was issued), as well as some user behavior data, clustering analysis is carried out to establish the evaluation index model of public policy implementation.
Key words: public policy; Internet data; clustering analysis; index model
0 引言
公共政策從某种意义上说是公共权力机关经由某个法定的程序所制定的为解决公共问题、达成公共目标、实现公共利益,以协调经济社会活动及相互关系的实施方案。公共政策的评估主要从两个方面着力,一是在公共政策出台之前,对政策的可行性进行评估;二是在政策出台之后,对政策的实时效果进行评估,找出与公共政策设计目标的差距。传统的评估方法有两类,一类是现场调研考察。选取与公共政策相关的不同层次的利益相关方,通过深入座谈、问卷调查、文档查看、实地考察、专家打分等方式,形成评估报告。另一类是建立统计分析模型。运用数理经济学、计量经济学和统计学等多种数理经济模型和计量经济模型,对公共政策进行量化评估,通过数据分析对政策实施进行量化评估。
近年来,互联网技术发展迅速,产生了海量的数据,为大数据的应用打下了坚实的基础。据有关文献报道[1,4],国内、外利用互联网大数据对公共政策实施进行评估取得了较好的应用效果。
本文对基于互联网大数据的公共政策实施评估进行了研究,通过对论坛、微博、微信、贴吧、博客、手机APP、平媒、政府网站互动栏目等互联网站点在政策出台后一段时间(如政策出台后半年内)的海量数据,以及部分用户行为数据,进行建模分析,将互联网上的公众意见引入到公共政策的实施效果评估中。
1 公共政策实施评估方法简述[2]
公共政策评估,从评估的范围看,有对公共政策实施效果及价值进行判断的专项评估,也有只对公共政策实施整个过程的分析和评判。从评估的过程看也有广义和狭义之分。广义的政策评估包含事前评估、执行评估和事后评估三种类型,而狭义的政策评估常常指事后评估。从评估的方法看,有定性分析评估和定量分析评估,定性评估在国内现有的评价模式中应用较为广泛。
1.1 定性评估方式
定性评估是基于经验的实证研究,常常采用访问法、观察法、案例研究法等非数字技术方法,依赖于评估方对公共政策实施的了解、调查和感性认识。如通过相关会议上的汇报交流、实地调研座谈、上报材料、媒体报道、内参反映、相关利益方来信/来访等,归纳总结为政策实施评估报告。定性评估方式相对简单,容易实施,速度快、方便、直接,比较受到各级政府的推崇。但定性评估方式易受各类条件的约束,其科学性、客观性难有保障,评估人员的直觉和经验作用明显,评估对象面较窄,利益相关方参与度不够。
1.2 定量评估方式
定量评估是相对定性评估的另一种评估方法,通过数据归集建立统计分析模型,把理论性概念量化成具体数据,通过科学计算,对公共政策实施进行定量评估。定量研究在某些方面相比定性研究方法有优势,能够用数据直观表达评估结果,但也存在不可靠的风险,过多地强调客观性和普遍性,忽略了人的主观性和特殊性。定量分析的方法对于解决常规性问题效果很好,对于非常规性的复杂问题,往往效果不佳。
1.3 互联网大数据评估
随着互联网和自媒体的高速发展,互联网本身的海量数据为基于大数据的公共政策评估带来便利。尽管在数据处理方式上,大数据的分析方法与传统定量分析的建模分析有相通之处,但存在较大差异。大数据评估由于数据采集方式、处理方式的变革,将会带来评估模式革命性的变化。一是数据采集从样本数据转向全数据,使评估更加接近事实本身;二是分析方法上由重视变量之间的因果性转向更加关注相关性,通过分析、揭示公共政策制定、实施与效果之间的相关性,使政策评价更趋于科学、民主和客观;三是参与对象更加广泛,通过大量收集互联网上利益相关者的情感、意愿、评价等信息,更多的了解公共政策实施对象参与的积极性和对公共政策实施效果的看法和评价。
2 互联网大数据评估基础准备
2.1 数据准备
2.1.1 数据采集
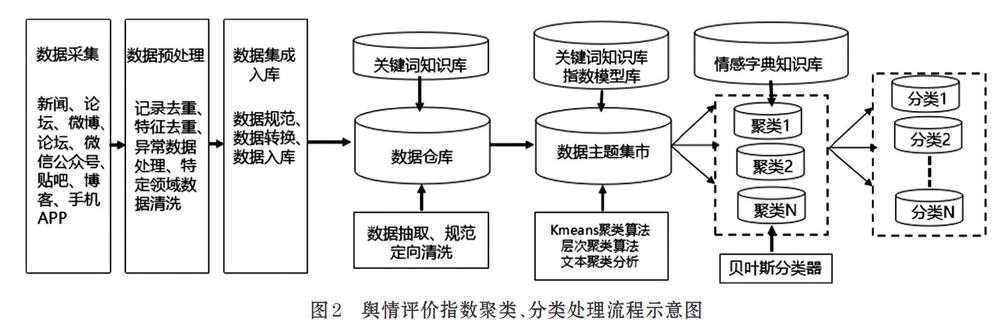
根据行政区划和政策评估有效时间和区间进行限定,采用互联网爬虫技术或以购买服务的方式从互联网爬虫公司采集数据,包括新闻、论坛、微博、微信、贴吧、博客、手机APP、平媒、政府网站互动栏目、综合网站互动栏目等互聯网站点在政策出台后一段时间(如出台后半年内的数据)的数据,构建基于舆情内容的热度、重点、焦点、敏感度、高频词、粘度等用户关注的行为数据,为多维度的舆情分析打基础。
2.1.2 数据预处理
互联网采集的数据与实际建模分析的要求相差甚远,极易受噪声、重复数据、缺失值和不一致数据的侵扰,必须进行预处理,数据预处理主要完成采集数据中的噪声清洗,纠正不一致性。一是检测、剔除重复数据。主要是记录去重和特征去重。考虑到中文处理的复杂性,可以采用特征去重、哈希去重等技术消除重复记录。二是异常数据处理。可以采用统计方法、关联分析、聚类方法进行异常数据处理,如缺失值处理、异常值(离群点)处理、噪音数据处理等。三是特定领域的数据清洗。这种数据清洗方案和算法都是针对特定领域,通过聚集、删除冗余、特征聚类来减少无关数据,实现数据的规范化。在公共政策评估中,可以根据公共政策的关键描述,建立关键词知识库和清洗模型,进行定向采集或定向清洗。四是数据集成入库。完成数据清洗后,通过规范、转换和规整处理,把采集数据规范到可以进行比较分析的某一度量空间,进行数据入库。
2.1.3 评估模型算法
由于互联网汉字文本信息的特点,只能通过语义分析找到文本数据内在的固有属性。基于互联网舆情对公共政策实施效果评估是一种常见的聚类分析评估,通过对海量数据的采集分析,按照舆情特点对公共政策评估进行聚类分析,通过关键词频度和特征表述并进行适度的加权值,实现类似满意、比较满意、一般、不满意的聚类分析。聚类算法是一种典型的无监督学习算法,根据样本之间的相似程度,将样本划分到不同的类别中。聚类分析的主要算法有划分聚类、层次聚类、基于密度的聚类、基于模型的聚类、基于网格的聚类和基于模糊的聚类。
3 基于聚类分析的公共政策模型结构研究
3.1 研究准备
一是建立大数据评估的相关知识库。对已发布的公共政策建立关键词知识库,如公共政策主题(政府文件名称、文号、会议名称、政策主题),关键词,主要内容描述,利益相关对象描述等。二是数据抽取和基本清洗。选取公共政策出台后一段时间(如出台后半年内的数据),选取特定的互联网渠道作为数据采集来源,采用爬虫技术或向第三方数据爬虫公司购买相关数据,经去重、去噪、数据归一化后集成入库。三是数据定向抽取和建模清洗。按照评价模型体系评价指标的要求和聚类分析的数据规范,对单个指数进行数据抽取和规范化建模清洗,形成每个指数聚类分析所需的数据集市。
3.2 评价模型指标体系
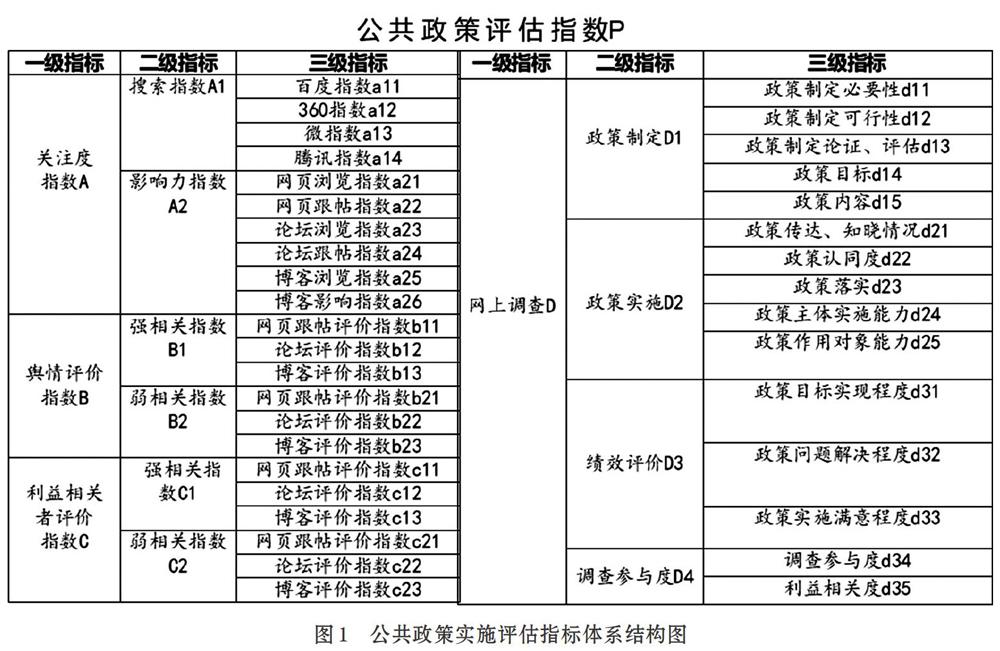
采用传统指数分析与大数据聚类分析相结合的方式建立评价模型指标体系。评价模型为三级指标模型,建立层次化结构的公共政策评估指标体系。一级指标从政策关注度(A)、政策舆情评价(B)、利益相关者评价(C)、网上调查问卷(D)等四个层面反映互联网大数据对公共政策实施评估的主题评价,二级指标是对上一级影响因素的进一步细分,第三级指标通过数据处理和聚类分析,采用可量化的数据对前一级指标的每个方面进行描述。三级指标的数据处理,主要是在对定向数据集进行分词处理、语义分析的基础上,通过聚类分析算法,得出量化评分。
计算公式:P=k1*A+k2*B+k3*C+k4*D;
0 K1-k4为权重,取值范围为0-1,且k1+k2+k3+k4=1; A-D为一级指标取值,通过二级指标加权计算得出,取值范围0-100之间,如A=k11*A1+k12*A2,K11-k12为权重,取值范围为0-1,且k11+k12=1。 二级指标取值通过三级指标加权计算得出,取值范围0-100之间,如A1=k111*a11+k112*a12+k113*a13+k114*a14,K111-k114为权重,取值范围为0-1,且k111+k112+k113+k114=1。 三级指标取值通过聚类分析,统计计算和归一化处理得到。 3.3 评价模型与大数据聚类分析 3.3.1 指标模型 图1为公共政策实施评估指标体系结构图。 ⑴ 关注度指数 关注度指数包括搜索指数和影响力指数。搜索指数和影响力指数的计算也有较为复杂的数据处理、分析建模过程。如百度指数a11的取值计算,以公共政策的发布覆盖范围为基础,围绕政策发布的前后一段时间区间,以网民在百度的搜索量为数据基础,以建立的公共政策知识库关键词为统计对象,分析并计算出各个关键词在百度网页搜索中搜索频次,并进行加权求和。360指数a12、微指数a13、腾讯指数a14都可以用类似的方法确定。 影响力指数主要关注公共政策的发布、转发、浏览、评论情况。通过分析公共政策发布后一段时间,微博、论坛、微信公众号、贴吧、博客、手机APP等关注的程度,包括对关键信息的搜索量、相关网页点击数、转发数、浏览数、评价数、关注数等分析,确定影响力指数[5]。 ⑵ 舆情评价指数 舆情评价指数[3]是一个直接反映网民对政策评估的指标,权重系数高于关注度。强相关主要是采集数据与主题相关程度更加高,如直接对公共政策进行评价或有多关键词同时出现;弱相关主要是有关键词出现,但頻度、数量较少,与主题的相关程度相对较弱。强相关的权重明显要高于弱相关权重。三级指标的处理采用聚类分析和分类分析结合的方法,以论坛评价指数b12、b22为例,首先是语料选择,采用前面叙述的方式,建立关键词知识库,依照知识库关键词,对预处理后的各类论坛原帖及跟帖进行分词处理、智能过滤,形成供分析的语料数据集市。采用基于划分的 Kmeans 聚类算法和基于层次的聚类算法对文本进行聚类,形成评价话题聚类。由于b12、b22指数值在0-100之间取值,取值按照正面评价*权重-负面评价*权重-中性评价*权重得到。其他舆情评价指数的计算类似。图2为舆情评价指数聚类、分类处理流程示意图。 ⑶ 利益相关者评价指数 利益相关者舆情评价指数计算与舆情评价指数基本相同,只是对数据集市的内容进行进一步定向筛选,根据利益相关者知识库关键词,通过IP地址分析、文本分词和语义分析,在已经建立的数据集市中建立子集,子集作为利益相关者舆情分析基本语料数据,进行上述类似建模分析。利益相关者评价指数权重取值更高。 ⑷ 网上调查评价 网上调查由政策发布者来组织,通过政府网站或其他综合网站进行数据收集。网上调查的指标设计可以更加具有针对性,但参与人数、填报数据质量、不真实数据等也要认真考虑。 4 结束语 应用互联网大数据对公共政策实施评估,是新的研究领域,具有直面利益相关者的优点。本文提出的指数模型对公共政策实施大数据评估具有一定参考作用,但是数据采集质量难以保证,各类权重的使用具有随意性。所以,传统定性分析、传统定量分析、基于互联网的大数据分析应当互相融合,取长补短,使公共政策实施的评估更加科学合理。 参考文献(References): [1] 魏航,王建冬,童楠楠.基于大数据的公共政策评估研究:回顾与建议[J].电子政务E-GOVERNMENT,2016.1:11-17 [2] 高峰.政策评估的通用模型研究[J].科技管理研究,2015.24:35-39 [3] 连芷萱,兰月新,夏一雪,刘茉,张双狮.面向大数据的网络舆情多维动态分类与预测模型研究[J].情报杂志,2018.5:123-133 [4] 张达刚,陈海宁,陈华,张光怡.环境评估大数据管理平台初探及技术综述[J].计算机系统应用,2019.28(4):205-211 [5] 文馨,陈能成,肖长江.基于Spark GraphX和社交网络大数据的用户影响力分析[J].计算机应用研究,2018.35(3):830-834 收稿日期:2020-09-14 作者简介:杨志新(1957-),男,湖南娄底人,硕士,研究员级高级工程师,主要研究方向:电子政务,计算机应用。
