一种改进的SRGAN图像超分辨重建算法
2021-06-08乔昕魏延
乔昕 魏延


摘 要: 现存的图像超分辨率重建算法存在模型训练不稳定、参数量多、模型收敛速度慢等缺点。在生成对抗网络的超分辨率算法(SRGAN)基础上,将轻量化的密集连接网络(DenseNet)作为生成对抗网络的生成器,使用WGan对判别器进行优化,利用Wasserstein代替SRGAN的JS散度,使其能够在网络参数更少、计算量更小的基础上实现更优的性能。实验结果表明,在四个公开的数据集上,所提出的模型比较主流重建模型在图像重建质量的峰值信噪比(PSNR)和结构相似性(SSIM)两个客观指标和主观视觉效果上都有所提高。
关键词: 图像重建; 轻量化; 密集连接网络; 生成对抗网络
中图分类号:TP183;TP391.41 文献标识码:A 文章编号:1006-8228(2021)01-72-04
Research on the algorithm of image super-resolution reconstruction with improved SRGAN
Qiao Xin, Wei Yan
(Chongqing Normal University College of Computer and Information Science, Chongqing 401331, China)
Abstract: The existing image super-resolution reconstruction algorithms have the disadvantages of model training instability, large parameter stakes and slow model convergence speed. On the basis of the Super-Resolution Generative Adversarial Networks (SRGAN), the lightweight Densely Connected Convolutional Networks (DenseNet) is used as the generator to generate the GAN, WGan is used to optimize the distinguisher, and the Wasserstein is used instead of JS dispersion of SRGAN, so that it can realize better performance with fewer network parameters and less computation. The experimental results show that, on the four exposed data sets, the proposed model improved the two objective indicators and subjective visual effects of the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) of image reconstruction quality compared with the mainstream reconstruction models.
Key words: image reconstruction; lightweight; Densely Connected Convolutional Networks; Generative Adversarial Networks
0 引言
現如今,图像作为一种极其重要的信息载体,在医学、军民卫星图像和安保视频检测监控等应用领域中对其质量的要求越来越严格,但是图像会由于气象环境和采集设备的影响,易导致采集的图像出现质量低或者细节的纹理信息缺乏等问题。图像超分辨率重建[1](Super-Resolution,SR)就是将低分辨率图像重建为对应的高分辨率图像。如今,图像超分辨率技术也逐渐成为计算机视觉领域的研究热点。
最近,随着深度学习的迅猛发展,深度学习模型开始被应用于图像重建这一领域。如:Dong等人在2014年成功提出了的一种基于卷积神经网络的超分辨率重建算法模型SRCNN[1](Super-Resolution using Convolutional Neural Networks)。2016年,又继续对SRCNN进行了改进,提出FSRCNN[2](Fast Super-Resolution Convolutional Neural Networks),不需要在网络外进行放大图像尺寸,用小卷积代替大卷积,在训练速度和图像质量上均有所提高。同年,有其他学者提出VDSR[3](Very Deep Super-Resolution),该模型发现,随着增加卷积层数的提高,重建之后的图像质量也随之提高。随之而来就有学者提出了如ResNet、DenseNet这些深层卷积神经网络结构,希望以此来提高超分辨率重建的性能。同时,又因为生成对抗网络GAN(Generative Adversarial Networks)在图像生成方面的性能较为优越,在随之到来的2017年,又有Leding率先在超分辨重建领域中使用了生成对抗思想,提出一种基于生成对抗网络的图像超分辨率重建算模型SRGAN[4](Super-Resolution Generative Adversarial Networks),解决了图像经常丢失高频细节这一缺点。
本文在SRGAN的基础上进行改进,将SRGAN的生成器模型改为DenseNet,用WGAN[5]来构造判别器;本文采用深度可分离卷积的思想来改进生成器,减少模型结构的计算量。
1 相关工作
1.1 SRGAN
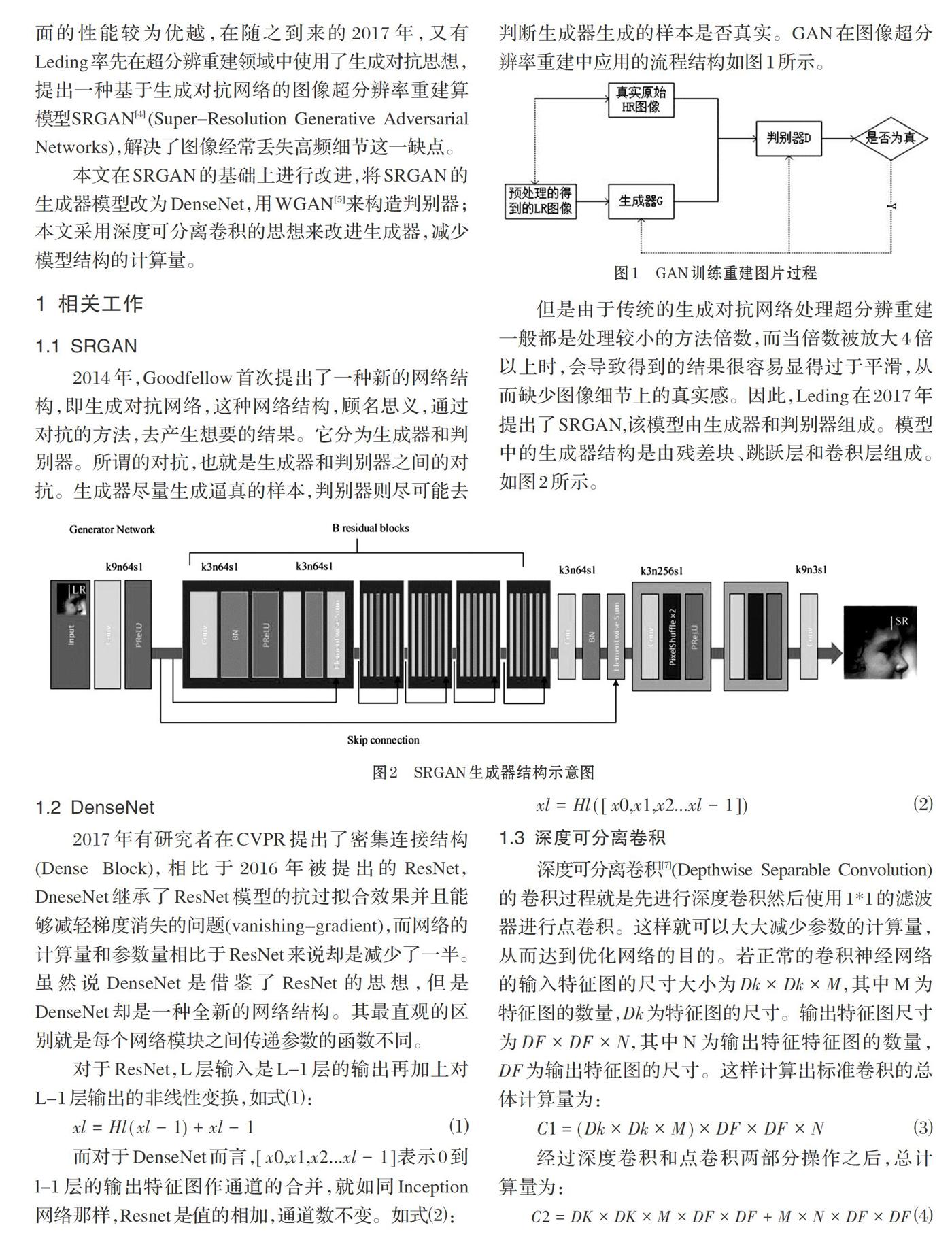
2014年,Goodfellow首次提出了一种新的网络结构,即生成对抗网络,这种网络结构,顾名思义,通过对抗的方法,去产生想要的结果。它分为生成器和判别器。所谓的对抗,也就是生成器和判别器之间的对抗。生成器尽量生成逼真的样本,判别器则尽可能去判断生成器生成的样本是否真实。GAN在图像超分辨率重建中应用的流程结构如图1所示。
但是由于傳统的生成对抗网络处理超分辨重建一般都是处理较小的方法倍数,而当倍数被放大4倍以上时,会导致得到的结果很容易显得过于平滑,从而缺少图像细节上的真实感。因此,Leding在2017年提出了SRGAN,该模型由生成器和判别器组成。模型中的生成器结构是由残差块、跳跃层和卷积层组成。如图2所示。
1.2 DenseNet
2017年有研究者在CVPR提出了密集连接结构(Dense Block),相比于2016年被提出的ResNet,DneseNet继承了ResNet模型的抗过拟合效果并且能够减轻梯度消失的问题(vanishing-gradient),而网络的计算量和参数量相比于ResNet来说却是减少了一半。虽然说DenseNet是借鉴了ResNet的思想,但是DenseNet却是一种全新的网络结构。其最直观的区别就是每个网络模块之间传递参数的函数不同。
对于ResNet,L层输入是L-1层的输出再加上对L-1层输出的非线性变换,如式⑴:
[xl=Hl(xl-1)+xl-1] ⑴
而对于DenseNet而言,[[x0,x1,x2...xl-1]]表示0到l-1层的输出特征图作通道的合并,就如同Inception网络那样,Resnet是值的相加,通道数不变。如式⑵:
[xl=Hl([x0,x1,x2...xl-1])] ⑵
1.3 深度可分离卷积
深度可分离卷积[7](Depthwise Separable Convolution)的卷积过程就是先进行深度卷积然后使用1*1的滤波器进行点卷积。这样就可以大大减少参数的计算量,从而达到优化网络的目的。若正常的卷积神经网络的输入特征图的尺寸大小为[Dk×Dk×M],其中M为特征图的数量,[Dk]为特征图的尺寸。输出特征图尺寸为[DF×DF×N],其中N为输出特征特征图的数量,[DF]为输出特征图的尺寸。这样计算出标准卷积的总体计算量为:
[C1=(Dk×Dk×M)×DF×DF×N] ⑶
经过深度卷积和点卷积两部分操作之后,总计算量为:
[C2=DK×DK×M×DF×DF+M×N×DF×DF] ⑷
与标准卷积相比,计算比例为:
[γ=C2C1=DK×DK×M×DF×DF+M×N×DF×DF(Dk×Dk×M)×DF×DF×N=1N+1D2k ⑸]
1.4 WGAN
传统GAN是基于JS散度进行优化的,这种优化方法会导致GAN模型的训练过程不稳定。针对这一问题,本文使用一种基于Wasserstein距离[6]优化判别器的GAN(WGAN),WGAN可以使用wasserstein距离衡量出真实图片和生成图片之间的距离,使WGAN在训练过程中效果更稳定。Wasserstein距离又叫Earth-Mover(EM)距离,公式如下:
[WPr,Pg=infγ~∏Pr,PgEx,y~γ[||x-y||]] ⑹
其中[Pr]是样本分布,[Pg]是生成器生成分布,[∏(Pr,Pg)]是[Pr]和[Pg]所有可能的分布的集合;x是真实数据,y是生成的数据,x和y都能从分布[γ]中采样得到。
2 本文网络模型
2.1 生成器
本文模型的生成器采用的是DenseNet,其结构为DenseNet-121结构,同时,为了进一步减少计算量,采用深度可分离卷积的思想,将Dense Block中的3*3的卷积替换为1*3和3*1的卷积。
2.2 判别器
SRGAN模型中的判别器采用的是:将Sigmoid作为其损失函数,但是因为Sigmoid一般用于处理二分类问题,而这里的损失函数的作用应该是用来评价生成器生成的高分辨图像具体的情况,不只是单独的分类。所以本模型的判别器将采用WGAN的思想,将SRGAN模型中判别器的最后一层的Sigmoid删除,采用Wasserstein距离最小化损失函数。本文模型的判别器结构如图3所示。
2.3 损失函数
Wasserstein距离是为所有可能的联合分布的集合[∏(Pr,Pg)]中期望值x和y的距离期望值的下限值,与JS散度相比较,无论样本分布和生成分布有没有重叠部分,Wasserstein距离都能够很好地反映出这两种样本的相似性。但是由于在公式⑹中的下确界无法求解,于是通过Lipschitz连续将Wasserstein距离变换为:
[W(Pr,Pg)≈maxθ:||fθ||L≤1Ex~pr[fθ(x)]-Ex~pg[fθ(x)]] ⑺
由于在WGAN中,Wasserstein已经由原来的二分类任务,转换成了回归任务,因此Wasserstein距离的求解已经转变为使式⑺取得最大值,也就是取[fθL=1]时,L表示真实分布和样本分布之间的Wasserstein距离。
[L=Ex~pr[fθ(x)]-Ex~pg[fθ(x)]] ⑻
進而分别可以得到生成器和判别器的损失函数,如公式⑼、公式⑽:
[L(G)=-Ex~pg[fθ(x)]] ⑼
[L(D)=Ex~pr[fθ(x)]-Ex~pg[fθ(x)]] ⑽
本文模型的损失函数方法,由内容损失和对抗损失的加权和组成。其公式定义为:
[lSR=lSRX+10-3lSRGen] ⑾
其中内容损失中,基于像素的MSE损失被定义为:
[lSRMSE=1r2WHx=1rWy=1rH(IHRx,y-GθG(ILR)x,y)2] ⑿
生成对抗损失,就是为了生成让判别器识别不了的图像,对抗损失的公式定义为:
[lSRGen=n=1N-logDθD(GθG(ILR))] ⒀
3 实验与结果分析
3.1 实验环境
本文模型的实验所使用的实验环境:硬件环境配置是显卡GTX1080Ti,处理器为i5-9600K,运行内存32G。
3.2 实验数据集
本文选用了DIV2K的800个高清图像作为训练数据,测试数据采用了Set5,Set14,BSD100和Urban100四个主流数据集。训练时所需要的低分辨率图像是由DIV2K数据集中的高分辨图像进行双三次插值的四倍降质处理得到。
3.3 实验参数
本文模型的训练过程中将Batch_size设置为16;迭代次数为5000次;每迭代500次,就保存一次模型训练结果,同时学习率就衰减一半;初始化学习率为0.0001。
3.4 实验结果与评价
3.4.1 客观量化评价
本文在四个公开数据集上测试了Bicubic、SRCNN、VDSR、FSRCNN、SRGAN以及本文的方法。分别计算在不同数据集上采用不同算法进行上采样4倍时峰值信噪比(Peak Singal-to-Noise Ratio,PSNR)和结构相似性(Structural Similrity index,SSIM)值,结果表1所示。
实验结果表明,本文提出的算法模型相比于几种用于测试的主流图像重建模型,其PSNR和SSIM值均有所提升。
3.4.2 主观评价
本文在Set5数据集中选取一张婴儿高分辨率图像,为了更好地从主观上区分出本文算法模型和其他测试算法模型的优劣,本文将选取的高分辨率图像的婴儿右眼部分进行放大对比,如图4所示。
从图4不难发现,本文算法不仅从整体的清晰程度,还是眉毛处纹理细节特征,都比其他算法模型更接近于原始数据集中的高分辨率图像。
4 结束语
在之前的图像超分辨率重建的方法中,基于深度学习的重建方法又要明显优于其他方法。但是深度学习方法会随着网络层数的增加,出现训练网络模型的过程不稳定、梯度消失、参数量和计算量大等缺点。
本文在原有SRGAN模型的基础上将DenseNet和WGAN都结合到SRGAN模型中去,优化网络结构,加快模型收敛。同时,引入深度可分离卷积思想对生成器进行轻量化,减少生成器的参数量和计算量。实验的结果表明,本文提出的算法在四个图像超分辨率领域的公开数据集上得到的评价指标结果和主观视觉效果,相比于其他重建方法均有所提高。
参考文献(References):
[1] Dong C,Chen C L,He K,et al.Image super-resolution using deep convolutional networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016.38(2):295-307
[2] Dong C, Chen C L, Tang X. Accelerating the Super-Resolution Convolutional Neural Network[C]//European Conference on Computer Vision. Springer,Cham,2016:391-407
[3] Kim J, Kwon Lee J, Mu Lee K. Accurate image super-resolution using very deepconvolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2016:1646-1654
[4] Ledig Christian, Theis Lucas, Huszar Ferenc, et al. Photo-realistic single image super-resolution using a generative adversarial network[J].ResearchGate,2016:105-114
[5] Arjovsky, Martin, Chintala, Soumith, Bottou, Léon.Wasserstein GAN [J]. Computer Vision and Pattern Recognition,2017.12.
[6] 曾庆亮,南方哲,尚迪雅,孙华.基于ResNeXt和WGAN网络的单图像超分辨率重建[J].计算机应用研究,2020.8:1-5
[7] 袁哲明,袁鸿杰,言雨璇,刘双清,谭泗桥.轻量化深度学习模
型的田间昆虫自动识别与分类算法[J].吉林大学学报(工学版),2020.8:1-12
收稿日期:2020-08-21
作者简介:乔昕(1996-),男,江苏连云港人,硕士研究生,主要研究方向:计算机视觉。
通讯作者:魏延(1970-),男,四川泸县人,博士研究生,教授,主要研究方向:机器学习,云计算等。
