国际数字人文研究的演化路径与热点主题分析
2021-06-07李娜
李 娜
(华南理工大学图书馆 广州 510640)
数字人文(Digital Humanities)是一种将计算机方法与技术融入人文研究,进而提出并回答人文问题的新范式。“数字人文”一词在英美学术界相关期刊陆续出现,相关研究课题层出不穷,其名称和定位也经历了由“人文计算(humanities computing)”到“数字人文”的转变。究其大略,其演进与计算机技术的发展呈正相关关系,20世纪90年代起个人电脑的广泛普及促进了其研究的丰富,近年人工智能技术的兴起,对其发展起到了推波助澜的作用。在这种新技术的强大冲击下,国内外学者积极投身于数字人文理论和实践的研究中,从不同角度探讨数字人文领域存在的问题及其解决方案。本研究采用专业的检索策略,同时进行主题检索、标题检索和期刊检索,依托科技文本挖掘及信息可视化技术,对2001—2020年国际数字人文研究文献进行定量和定性分析,既从微观视域在一定范围内探讨数字人文研究的知识基础,又同时尝试以宏观的视角分析、整理和归纳数字人文领域的研究热点和演化路径,以期为未来我国数字人文理论研究和实践探索提供有价值的参考。
1 数据来源与研究方法
1.1 数据来源
本研究以Web of Science核心合集中的姊妹版数据库组合SCIE数据库和SSCI数据库为数据源。这两个数据库收录的均是经过严格遴选的核心学术期刊中的世界一流学术文献,这样可以最大限度地保证研究样本的权威性和代表性。为了避免样本数据出现漏检和误检的情况,我们将检索词进行不同方式的组合与检索,判读检索结果的合理性,设计和调整出更加有效的检索策略。例如,简单地采用“digital humanities”或者“humanities computing”进行检索,检索结果会出现漏检情况;采用“digital” and“humanities”或者“humanities” and “computing”进行检索,这样的检索范围过大,又会出现数据误检情况。鉴于此,本研究最终确定在检索式中应用位置算符(NEAR),同时解决了漏检和误检问题。表面上看,这样的检索策略是合理的,其实检索结果仍存在很大问题,主要是文献数据过于单一,仅检索到了涉及相关检索词的文献,更多与研究主题相关的深层次数据未能检索出来,所以必须考虑相关领域专业期刊的检索。Literary and Linguistic Computing(《文学与语言计算》)是国际上数字人文领域的主要期刊,该期刊于2008年创刊,2015年更名为Digital Scholarship in the Humanities(《人文领域的数字学术》),作为欧洲数字人文协会的同行评议学术期刊,收录了计算和信息技术应用于艺术和人文研究各个方面的原创性文献。Computers and the Humanities(《计算与人文》)创刊于1966年,旨在刊载将计算机方法应用于人文科学领域的重大研究,但是SCI数据库仅收录了该刊2001—2004年的文献。这两种期刊均有较高的收录标准,具有较强的专业性和时效性,提供的数据也具有较高的质量。本研究将主题检索、标题检索和出版物名称检索相结合,以确保检索结果的合理性和有效性。检索内容与检索结果如表1所示。

表1 研究数据获取方式
1.2 研究方法
本研究利用VOSviewer工具将浩如烟海的文献数据转换成可视化知识图谱。VOSviewer中VOS的含义是visualization of similarities,即相似的可视化。运行VOSviewer生成的可视化图谱为网络图,分析的对象既可以是施引文献也可以是被引文献。首先,选择对被引文献进行分析,国际数字人文研究领域的知识基础演进历程集中展现在共被引(co-citations)分析网络中,作为知识基础的引文节点文献(cited references)根据亲缘关系自动形成聚类。这种引文分析有助于捋清国际数字人文知识的发展脉络,以及在其演变过程中起关键作用的文献。其次,选择对施引文献进行分析,通过共现(co-occurrence)网络分析揭示国际数字人文研究领域的知识单元或知识群之间的网络、结构、互动、交叉等诸多隐含的复杂关系,在VOSviewer中使用节点来表达所分析的知识单元,节点颜色表达所属的不同聚类,每个聚类代表了一个研究主题,进而形成了国际数字人文研究领域的热点主题群。再次,利用CiteSpace软件考察词频的时间分布,选择时区显示功能,生成反映近二十年国际数字人文研究的知识演进的时区图谱,确定国际数字人文研究的前沿领域和发展趋势。
2 知识基础
本研究应用VOSviewer工具,选择科技文献共被引分析功能,默认以引证次数≥20为条件进行数据筛选,从35 137篇参考文献中,选出满足阈值的16篇文献,得到文献共被引分析的可视化结果,如图1所示。在文献共被引分析网络中,自动生成2个聚类知识群,表示从两个角度展示出“数字人文”研究领域的基础文献知识分布情况。节点的大小反映文献被引用总频次的高低,节点的颜色表示所属的聚类,聚类I(红色标识)由9个关键节点组成(即9篇文献),聚类II(绿色标识)由7个关键节点组成(即7篇文献),根据文献的被引频次对16篇文献进行排序,详见表2。
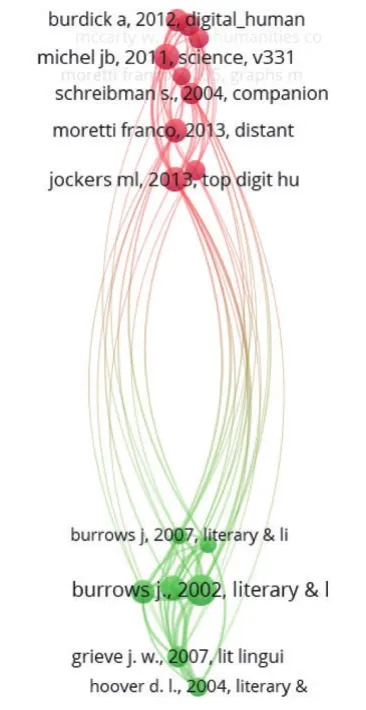
图1 文献共被引分析的可视化结果
高被引文献通常在其研究领域具有较大的影响力,也是学术同行极为关注的文献,具有奠基意义。从表2可以发现,在数字人文的发展过程中,有大批优秀的学者可谓数字人文基础研究的领军人物,例如Burrows J、Jockers M L、Moretti F等学者,在排名前16的高被引文献中每人分别有2篇代表性著作或文献,可见他们不仅仅是数字人文基础研究的高产学者,而且其研究成果及学术思想对后期的学术研究也产生了不容小觑的影响,成为数字人文研究领域的知识基础。笔者结合图1和表2,从学术研究思想的角度对高被引文献两个知识集群进行总体分析。
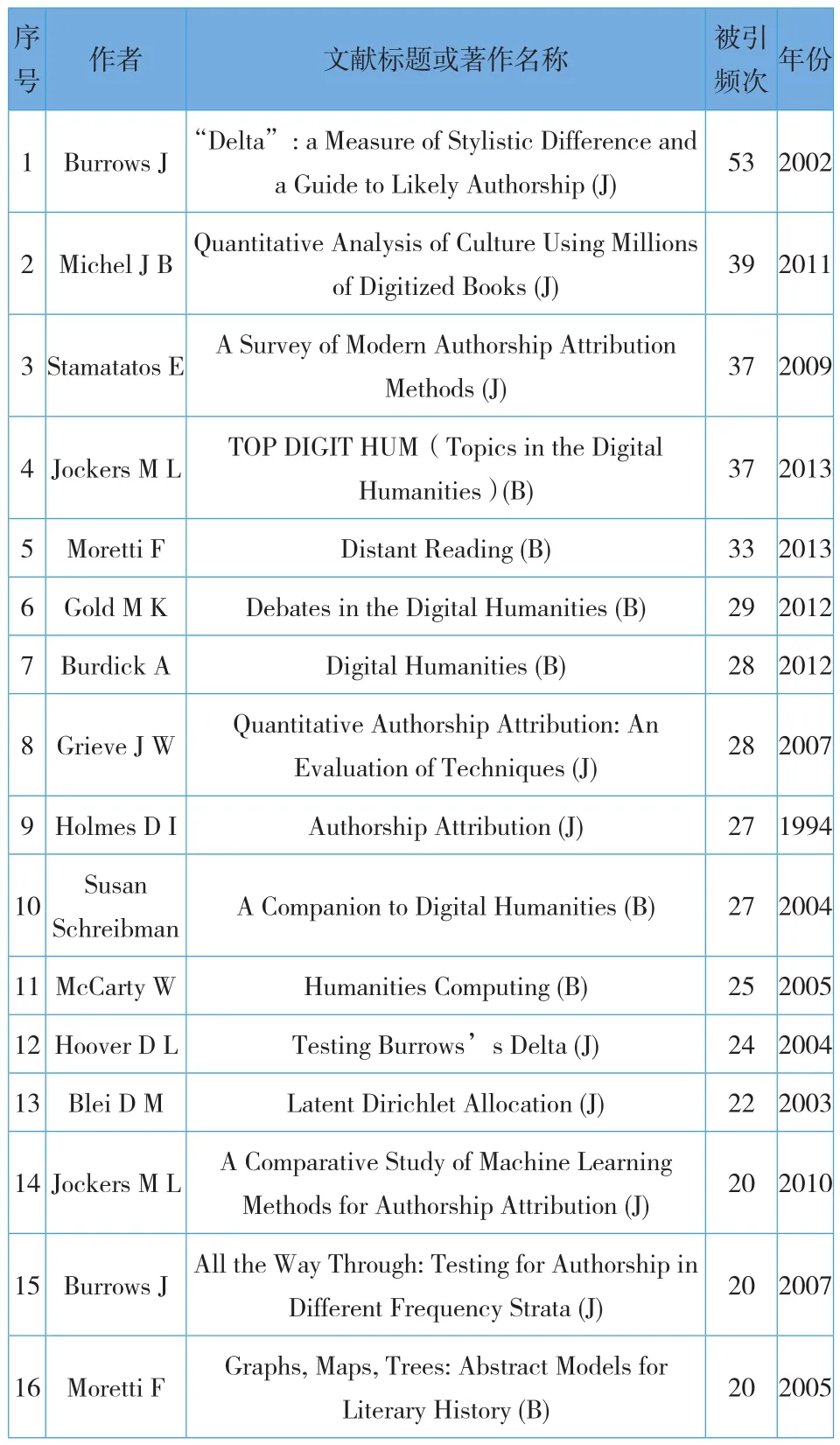
表2 国际数字人文研究领域高被引参考文献统计(Top16)
2.1 作者身份识别
“作者身份识别”研究历史由来已久,1994年英国西英格兰大学学者Holmes D I就开始关注作者身份识别,考虑了文学风格的量化问题,探讨了可作为作家文体“指纹”的几个变量,并将这些变量作为作者风格的识别指标[1],该研究在数字人文研究领域具有开创性意义。澳大利亚纽卡斯尔大学学者Burrows J有两篇经典文献被引频次均排名前列,其中一篇被引频次雄居首位,可谓数字人文研究领域的奠基之作。该学者从计算语言学的视角出发,提出了基于词频受控对比的作者身份识别方法,即Delta,并验证了该检测方法的准确性,在一定程度上有助于深入挖掘科学研究背后的学者身份信息,也有助于拓展语言学研究的视野[2-3]。其后,美国纽约大学学者Hoover D L对Burrows J提出的“Delta”方法进行了检测,明确了该检测方法的有效性和准确性,并指出其在散文和诗歌上的检测效果差不多,以及删除人称代词可以提高Delta检测的准确性[4]。Grieve J对作者身份归属研究中常用的39种不同类型的文本测量结果进行比较,以确定哪些是作者身份的最佳指标,提出了一种更准确的定量化作者身份识别的方法,该方法可以对多种不同文本进行度量分析[5]。希腊爱琴海大学学者Stamatatos E从文本表示和文本分类特征来研究作者身份识别,并进一步讨论作者身份识别研究的评估方法和标准[6]。美国斯坦福大学学者Jockers M L提出了基于机器学习的作者身份识别方法,主要对有争议的论文和通常被认为是共同撰写的论文进行分类。测试过程由两个单独的功能集执行:其一是“原始”功能集,包含所有作者共有的所有单词和单词二元组;其二是“预处理”功能集,将原始功能集简化为包含仅满足最小相对频率阈值的单词,测试结果良好[7]。
2.2 远距离阅读
美国斯坦福大学学者Moretti F有两本关于“远距离阅读”研究的经典著作均跻身被引频次排名前列,可谓数字人文研究领域既高产又高质的学者。Moretti F是最早提出“远距离阅读”这一术语的学者,他认为文学研究是随机的、不是系统的,强调文学学者应该停止阅读书籍,开始计算、绘图和映射,这一举动可能会给学科领域带来新的光彩[8]。他将“远距离阅读”定义为“远远超出作者预期的解读”,提出用Z值、主分量分析和聚类系数等备受争议的文学分析模式,认为这将是非主流文学研究一个正在兴起的领域[9]。2003年,美国加州大学伯克利分校学者Blei D M等提出了潜在狄利克雷分布(LDA)模型,这是一种用于收集离散数据(例如文本语料库)的概率模型,同时还提出了基于变分方法和经验贝叶斯参数估计的EM算法的有效近似推理技术[10]。此后,美国马里兰大学学者Susan Schreibman等研究了计算方法在文学研究中的应用,介绍了人文计算的基本原理、方法和应用以及文本生产、传播和存档的内容,这些均属于人文计算方法的基础性研究[11];英国伦敦国王学院学者McCarty W结合哲学、历史、人种学和批判性观点,阐述了如何通过计算帮助完成人文科学的基本任务,并提出更多具有挑战性的学术问题[12];美国哈佛大学学者Michel JB构建了一个数字化文本语料库,定量分析了1800年至2000年英语数字书籍所反映的语言和文化现象,并为词典编纂、语法演变、集体记忆等领域的研究提供见解[13]。2012年,美国纽约城市大学学者Gold M K撰写的《数字人文学科辩论》的出版,标志着数字人文已经成为一个学科领域。数字人文不仅具有传统学科领域的数字档案、定量分析和工具构建的特征,还涵盖了更广泛的方法和实践内容,即大型图像集的可视化、历史文物的3D建模、“天生数字学位论文、移动创客空间等[14]。同年,美国艺术中心设计学院学者Burdick A回答了“什么是数字人文科学?”这一经典问题,进一步探讨了与传统的人文探究模式所不同的方法和技术,其中包括地理空间分析、数据挖掘、语料库语言学、可视化和模拟[15]。次年,美国斯坦福大学学者Jockers M L基于大规模的文学计算和宏观分析方法,提出一种文学研究的新方法,帮助读者更好地理解文学作品并对其进行情境化[16]。
3 演化路径
本研究利用CiteSpace软件构建国际数字人文研究的共现网络关系,再将其转换成从时间维度来表示知识演进的时区视图,以便清晰地展示出文献的更新和相互关系。将高频关键词定位在一个横轴为时间的二维坐标系中,一个从左到右、自上而下的知识演进图就直观呈现了,可以清晰地描绘出2001—2020年国际数字人文研究的动态演化历程,详见图2。依据关键词分布的亲疏程度,将国际数字人文研究大致划分为3个时期,详细分析如下。

图2 国际数字人文研究演化路径图谱
3.1 初始期(2001—2007)
从图2可以看出,2005—2007年这段时间的关键词明显变少,这是由于期刊Computers and the Humanities被SCIE数据库收录的截止时间是2004年,故时区图谱上显示出一段空白区域。这一时期相对活跃的研究主题是“digital library(数字图书馆)”“database(数据库)”“corpus(语料库)”“corpus linguistics(语料库语言)”“dialectology(方言学)”“dialectometry(方言学)”“dialect(方言)”“language(语言)”“authorship attribution(作者身份识别)”。2002年国际数字人文组织联盟(The Alliance of Digital Humanities Organizations,ADHO)成立,2005年国际数字人文中心网络(Center Net)成立。上述组织的相继成立向全球知识界传递了一个重要信号,明确将着力拓展数字人文研究的深度和广度。随着数字图书馆的不断发展,大规模“语料库”和“数据库”的建设成为现实。“语料库”与“方言学”是相互支撑、相互促进的关系,“语料库”的发展为“方言学”研究提供了得力的手段和工具,“方言学”的发展反过来促进“语料库”的完善。“作者身份识别”与“语料库”之间也存在着内容联系,传统“作者身份识别”研究通常是对特定“语料库”中的文学作品进行作者分析,这些早期研究主要基于一元文体特征,限于长文体的文学作品以及作者人数较少的情况。
3.2 发展期(2008—2013)
与上一时期相比,这一时期的关键词明显骤增,是因为期刊Literary and Llinguistic Computing于2008年创刊,收录了大量数字人文领域的研究成果。这一时期“digital humanities(数字人文)”的主导地位已然无法撼动,充分彰显了其学术影响力。随着数字化技术的迅猛发展,数字人文研究逐渐由表象走向具体,“semantic web(语义网)”“big data(大数据)”“social network(社交网络)”“ontology(本体论)”“digital history(数字历史)”“interdisciplinarity(跨学科)”等热点词汇频繁涌现。语义网、大数据、社交网络的发展开启了数字人文研究的新模式,利用语义技术将分散异构的大数据转换成机器可读、关联共享可理解的优质数据,为人文学者提供庞大的、开放的数字资源。与此同时,数字人文各个分支领域的学者试图显性地勾勒出学科“本体论”的理论轮廓和框架,明确学科研究的基本面貌,还原学科研究之“本”,构建学科研究之“论”。同时,数字人文方法赋予了历史科学全新的空间感和立体感,拓展了历史传播的深度、广度与维度,历史科学与数字人文“跨学科”融合成为已然之实,“数字历史”这一新学科的诞生也是必然之势。
3.3 深化期(2014—2020.9)
当科学技术发生颠覆性创新时都会涌现出大量的研究主题,这种客观规律是符合事物发展方向的,数字人文研究也不例外。“mapping(图像)”“modeling(建模)”“model(模型)”“visualization(可视化)”“cultural heritage(文化遗产)”“crowdsourcing(众包)”“literacy(素养)”“twitter(推特)”代表了这一时期的主题特征。由于GIS技术、网络媒体、人工智能技术等前沿科技的发展,数字人文研究的范式正在发生深刻变革,打破了时间和空间的束缚,实现了由“文本”到“图像”“地图”“模型”的动态的“可视化”转变,散见于世界各地的“文化遗产”实现共建和共享,使研究者和公众有了一个完整的视野来看待相互连接的文化和历史。为了解决海量计算、大规模样本采集、多样性分析等问题,基于群众智慧的“众包”模式将极大地促进数字人文研究的深化和突破。随着数字人文研究的深入,数据“素养”必然会成为关注热点,数字人文快速发展为数据“素养”的深化提供了契机与沃土,两者相互融合与促进。另外,Twitter社交网络平台因其对数据下载的开放和友好,逐渐成为数字人文学术圈(至少是西方学术圈)最受欢迎的社交网络平台,不仅支持学者间的学术交流,还支持学术活动的实时讨论。
另外,纵观上述三个时期的阶段图可以看出,图书馆是贯穿数字人文研究全过程的热点话题。“digital library(数字图书馆)”“library(图书馆)”“academic library(学术图书馆)”这三个关键词分布于不同时段,由“数字图书馆”过渡到“学术图书馆”,体现了图书馆与数字人文研究在共同成长。数字人文与图书馆服务转型有着较强的关联性,这种关联不仅涉及文献保存、信息资源开发、出版发行、学术交流等层面,还引发了学术界人文项目开发等各类议题,包括文本挖掘、图像处理、地理信息系统、数字化存储与检索等项目的展开,数字人文所产生的创新赋能对引导和维护图书馆服务定位起到关键性作用。
4 研究热点
关键词是对文献主题的高度概括和凝练,通过对某学科领域文献高频关键词的提炼分析,可以全面了解和把握文献的内容结构及相互联系,同时还可以推断出大致研究方向和热点主题。本研究利用VOSviewer可视化软件工具对样本数据的关键词进行提取,统计出共现频率阈值为5的有实际意义的高频关键词(共83个),构建出关键词共现分析的可视化网络,根据关键词之间的关联强度自动生成主题聚类,各个聚类的节点和连线以不同颜色加以区分,如图3所示。

图3 国际数字人文高频关键词共现图谱

表3 国际数字人文热点主题归纳
从图3可以看出,国际数字人文关键词主要分为7个知识群,即7个热点聚类。本文分别对每个聚类构建密度视图,根据各个关键词的密度分布情况,归纳出热点主题,详见表3。在密度视图中,主要区域用蓝色和黄色来表示密度分布,蓝色表示低密度区域,黄色代表高密度区域,某个关键词周围的其他关键词越多、权重越大、与其他关键词的距离越近,那么该关键词的密度越大。在分析过程中,笔者刻意忽略一些无特殊意义的关键词,重点关注带有明显学科特征的关键词,再结合对大量“数字人文”相关文献的阅读和理解,对国际数字人文研究的热点主题进行整理与归纳。
4.1 GIS技术
在大数据时代,人文学和社会科学的发展更加注重定量化和空间化。GIS(地理信息科学)与人文学、社会科学进行了深度融合,以其强大的空间数据管理、空间分析和地图可视化功能有效地支撑了人文学和社会科学的研究,并成为数字人文研究的重要组成部分[17]。GIS可以有效地处理空间实体,并提供复杂的建模和分析功能来处理空间问题,有学者基于GIS中的点、线和多边形技术研究语言和文化的表达形式[18]。Zhu Suoling将GIS技术应用于中国古代地方志的开发和利用,以实现有关广东省地方志中分散的历史数据的挖掘和可视化[19]。另外,人文地理信息系统(Humanities GIS)位于艺术与科学的交汇处,Charles Travis讨论了两个HumGIS模型的概念化和可操作性,第一个模型用于执行可视化的地理历史分析,第二个模型将Ulysses整合到社交媒体地图中,以解释全球范围内的数字生态系统空间表现[20]。为了测试GIS是否可以用来绘制主观空间经验的表达所提供的定性数据,David Cooper等使用GIS探索两个英格兰湖区旅行地图中文本说明之间的空间关系[21]。
4.2 文化遗产
文化遗产是人类社会在历史实践中所创造的具有文化价值的财富遗存,具有不可再生性。数字技术的发展,推动了文化遗产数字化传播与保护的进程[22]。A. Marco Fiorucci等学者对机器学习在文化遗产中的应用进行了批判性研究,分析了机器学习、监督、半监督和无监督之间的主要分歧,并对各种算法的广泛应用进行深入思考[23]。Kim Seulah等学者建议使用数字技术促进韩国非物质文化遗产的可持续性发展,提出利用虚拟现实技术创建博物馆的展览内容,以鼓励公众参与和了解非物质文化遗产[24]。Emanuela Grifoni研究了3D多源多波段模型在文化遗产中的应用,采用3D多波段/多光谱重建技术,构建和比较使用常规数码相机(RGB和UV)和多波段相机(IR)获得的3D多波段模型,并对两幅世界名画进行重建绘画[25]。Francesca Tomasi探讨了模型和建模在数字人文科学领域中的作用,并特别关注文化遗产的研究,采用了二维视角将建模视为抽象过程,并使用可由机器处理的语言实现此抽象过程[26]。
4.3 语料库建设
语料库是以电子计算机为载体承载语言知识的基础资源,是需要经过科学取样和加工的大规模电子文本库,人文学者可借助计算机分析工具开展相关语言理论及其应用的研究。ArchiMob是一种基于口述历史访谈而免费提供的通用瑞士德语口语语料库,Scherrer Yves描述了ArchiMob语料库文档如何被转录、分割和与声源对齐,并鼓励将语料库用于一般的数字人文科学,特别是方言学[27]。Aynat Rubinstein描述了第一个开放式多类型现代希伯来语历史语料库的创建,在语料库的管理、编码和分发过程中实施数字人文方法,同时演示了语料库在历史语言研究中的用途[28]。另外,还有西方文学经典著作的语料库(1.0版),Clarence Green描述了该语料库的发展、组织和原始资料形式,证明其在文化学和语料库文体学(分别属于传统人文学科和数字人文学科)两个跨学科领域中的潜在用途[29]。Christopher Donaldson等学者采用一种跨学科的方法调查历史文本语料库,在这项调查中,利用地理信息系统(GIS)分析了美学理论与描述湖泊地区的空间美学术语之间的对应关系,最后探讨了基于地理和语料库的方法如何加强文学、美学和自然地理之间的联系[30]。
4.4 数字档案
档案是人类社会实践活动的原始记录,作为一种具有真实性、原始性、凭证价值与情报价值的固化信息,是数字人文研究的重要对象和信息资源之一。美国废奴主义者莎莉·霍利(Sallie Holley)(1818—1893)演讲语音档案缺失,Pamela VanHaitsma通过数字替代和元数据重建莎莉·霍利的废奴主义言论,这些数字方法不仅可以还原她的职业和演讲时间,还可以揭示她的演讲方式以及公开演讲的性别意义[31]。Robledano-Arillo Jesus等学者基于链接开放数据技术构建了一个概念模型,用于编码和传播与西班牙内战摄影档案有关的数据,该模型促进了用于历史研究的图像数据的传播和检索系统的生成,突破了遗产照片档案内容与上下文信息表示方法方面的一些限制[32]。纽约大学一个跨学科研究团队启动了“艺术家档案计划”,采用数字人文方法构建相关信息库,以展示和保存当代艺术,便于将来处理和重新激活艺术作品[33]。CABDHRP是一个支持中国历史研究的中国古代书籍数字人文研究平台,这项研究采用开放源代码机构存储系统DSpace,作为对归档的图像、元数据和全文进行扫描的数字档案系统,以支持数字人文研究[34]。
4.5 数字图书馆
在所有的学术探索中,数字人文最为生动地重现了古代图书馆的精髓,它追求的是形式多样的信息呈现、知识组织、技术交流与传播,正是这些追求让数字图书馆变得生机勃勃[35]。Biligsaikhan Batjargal基于自动元数据映射为日本人文数字图书馆构建联合搜索系统,其目的是为非日语人文数字图书馆自动执行元数据映射,以及让用户仅使用一个查询输入即可访问多个人文数字图书馆[36]。Mnemosyne是一个开放式数字图书馆,允许对特定馆藏进行数据建模,该项目借助工具Clavy进行开发,该工具是一个丰富的互联网应用程序,能够从数字对象的大数据集合中导入、保存和编辑信息,从而在机构之间建立桥梁和数字存储库,并创建丰富的数字内容的集合[37]。George Buchanan研究了人文学科领域的学者如何利用数字图书馆进行信息查询,以及如何通过更新人文学者的信息搜索技术来提升工作效率,观察了人文学者在查询和术语使用中运用的模式,指出了人文学者在信息搜索技术方面存在的问题[38]。
4.6 数字历史
数字历史是数字技术与历史科学融合的结果,已经在人文科学中得到了广泛应用,主要是对旧内容进行数字分析。Christopher D. Green认为数字历史方法可以有效阐明心理学过去的某些内容,这种成功并不意味着数字历史对传统历史学构成某种威胁,相反,两者可以有效互补[39]。Ivan Flis讨论了数字历史与传统历史之间的关系,指出数字方法不是取代历史学家的工作,而是加以补充并将其转化为新的受众,同时认为数字历史的作用是充当量化学科(如心理学)科学家与非量化学科(如历史)科学家之间的“trading creole”[40]。在加拿大“Trading Consequences”项目中,历史学家、计算语言学家和计算机科学家合作开发了一种文本挖掘系统,该系统从19世纪大量英文版数字化出版物中提取信息,确定事件、地理位置、日期三者之间的文本关系,基于该研究项目,Jim Clifford解释了数字人文技术应用于历史研究的方法、用途和局限性[41]。Jacy L.Young 对早期的两个姊妹刊《美国心理学杂志》和《教育学院》进行了探索性数字分析,揭示了两种期刊的许多特征和关键属性,并指出期刊内容之间的界线是流动的,而不是绝对的[42]。
4.7 主题建模
主题建模是一种结合机器学习和自然语言处理等相关方法的统计技术,其基本思想认为文本是由多个主题混合而成的, 而主题是特征词上的一种概率分布[43]。Zef M.Segal使用主题建模的计算工具研究了19世纪希伯来语报纸HaTzfira中每周和每天时间周期之间的主题差异,分析了周期更改前后的主题情况,显示出期刊主题的不同变化模式[44]。Quintus Van Galen讨论了如何使用主题建模工具来分析历史报纸档案,该案例研究了19世纪大英图书馆报纸档案中对美国的引用,结果表明主题建模通过“远程读取”档案的方式,为传统问题提供了一种潜在的解决方案[45]。Hu Yuening提出了一种向用户发出声音的机制,将用户对主题模型的反馈编码作为主题模型中单词之间的相关性,这个框架是交互式主题建模,它使未经培训的用户可以轻松地、反复地将其编码反馈到主题模型中[46]。Nektaria Potha 系统地研究主题建模在作者验证中的有效性,研究了涵盖主要范式的几种作者验证方法,包括内在和外在方法以及基于概要和基于实例的方法,并与潜在语义索引(LSI)和潜在狄利克雷分配(LDA)这种著名主题建模方法相结合[47]。
5 结论与展望
本文以SCIE数据库和SSCI数据库为数据源,通过对数字人文研究文献的施引文献和关键词进行分析,探讨了国际数字人文研究的知识基础、演化路径和研究热点,对2001—2020年近二十年国际数字人文研究的来龙去脉有了更加清晰的认识。在知识基础方面,数字人文知识来源可分为两大知识集群,一是作者身份识别,二是远距离阅读,这两个知识集群侧重于数字人文学科的研究方法与实践,在数字人文研究领域具有开创性和标志性意义。在演化路径方面,国际数字人文研究经历了初始期、发展期和深化期的发展历程。在初始期,“数字图书馆”“语料库”“作者身份识别”是最为活跃的主题词;进入发展期,“数字历史”、“社交网络”和“本体论”研究表现得较为积极;到了深化期,“文化遗产”、“可视化”、“图像”和“建模”等主题词充分彰显其优势地位。由此可见,数字人文研究逐渐由单一走向多元,由浅层思考趋向深入研究。研究热点主要集中为7个研究主题,分别是 GIS技术、文化遗产、语料库建设、数字档案、数字图书馆、数字历史和主题建模。其中,文化遗产和数字历史是数字人文研究的核心命题;数字档案、数字图书馆和语料库建设是数字人文生态系统良好运行的基础建设;GIS技术和主题建模是数字人文研究强劲的技术支持。
上述国际数字人文的分析结果为我国数字人文研究领域的发展提供了些许启示,具体如下:
一是夯实图书馆的学术地位。图书馆可依托现有的信息技术、数字资源和存储优势,创建专业性的数据集或大规模结构化数据,扩大人文学者的研究样本;图书馆需要转变角色定位,突破辅助支持型服务模式的限制,以研究者身份介入数字人文的科研实践中,开展相关理论研究。图书馆应与人文学者保持密切联系,结合具体的人文教学科研情境,嵌入人文学者的教学和科研过程中,扩大“数字人文”实践的受众范围。
二是加强数字档案资源建设。在理论方面,需要厘清数字人文与档案工作的逻辑关系和相关理论,寻找数字人文和档案管理的内涵契合点,探究数字技术的发展前沿和跨界结合的难点。在实践方面,档案机构可以依托资源优势开发基于档案内容挖掘与知识发现的数字人文项目,促进我国档案领域数字人文项目的资助和认证体系建设,推动档案工作者参与“国家数字人文基础设施建设工程”的规划,助力“数字中国”的建设。
三是注重跨学科交流与合作。在跨学科研究领域中,数字人文是典型的存在,需要人文学科专家、计算机技术专家、数据处理专家或其他专家共同协作研究。这不仅需要跨学科、跨空间甚至跨机构,还要最大程度最高效率地实现交流与合作。国内数字人文的发展需要在继续发展已有研究方向、创新研究方法的同时深入挖掘新的研究领域,将文化遗产和数字历史作为数字人文项目的重点课题,同时加强艺术作品和语料库的数字化建设。
四是构建数字人文学术环境。数字人文研究深入开展,需要大到国家,中到机构,小到个人的全方位重视和关注,从国家政策、机制等方面着手营造数字人文氛围。国家建立了支撑数字人文研究的政策和基金扶持、机构平台搭建、资源提供、技术支持等机制,使得科研人员可以进行跨学科、跨机构、跨地区甚至全球性质的数字人文研究和实践。这对于提高科研效率、促进我国数字人文研究高速发展具有重要意义。
