基于深度强化学习的燃料电池混合动力汽车能量管理策略研究
2021-06-03郑春花许德州
李 卫 郑春花 许德州
1(中国科学院深圳先进技术研究院 深圳 518055)
2(中国科学院大学 北京 100049)
3(中国矿业大学 徐州 221116)
1 引 言
在环境污染和化石能源危机的大背景下,世界各国相继针对燃油车颁布了严苛的排放法规,与此同时也促进了新能源汽车产业的发展。其中,燃料电池混合动力汽车(Fuel Cell Hybrid Vehicles,FCHVs)以其高效率、零排放的优点,成为许多厂商和科研机构的重点研发对象[1-2]。由于燃料电池系统(Fuel Cell System,FCS)动态响应较慢,一般使用电池或超级电容作为辅助动力,以适应剧烈变化的工况。为了合理分配不同动力源的输出功率,提升整车的燃油经济性,设计合理的能量管理策略尤为重要[3]。
常见的能量管理策略主要分为基于规则和基于优化两类[4]。前者针对动力源工作特性和驾驶工况设计控制规则,简单实用,但是不具备最优性,控制效果依赖于专家经验[5]。后者以动态规划[6]为代表,在已知工况下遍历所有可行解,获得指定性能指标下的最优控制,由于要求工况全局已知,难以实时应用,一般作为燃油经济性的比较基准。其他基于优化的能量管理策略,如基于庞特里亚金极小值原理[7-8]、等效燃油消耗最小[9]等,工况适应性较差,限制了算法的应用。近年来,随着人工智能技术的发展,基于学习的策略成为新的研究热点。该方法主要分为 3 类:基于神经网络、基于强化学习(Reinforcement Learning,RL)和基于深度强化学习(Deep Reinforcement Learning,DRL)。基于神经网络的策略利用神经网络进行工况分类[10]、速度预测[11-12]、参数优化[13]等。而与把神经网络作为数据处理工具不同,强化学习利用试错机制,直接从历史状态中学习得到优化控制策略[14-18]。Liu 等[19]针对混合动力履带式车辆,设计了基于强化学习的能量管理策略,结果显示,相比随机动态规划策略,该策略具有较好的燃油经济性。Lin等[20]在基于强化学习的能量管理策略中,提出根据余弦相似度来判断两个概率转移矩阵的差异,当超过阈值时,更新当前矩阵,实时选择最适合当前工况的策略,提高了整车经济性。基于强化学习的策略结合了基于规则和基于优化的特点,具有较好的工况适应性,但算法需要离散状态变量和动作变量,随着离散程度的增加,算法复杂度呈指数级别上升,影响其收敛性和稳定性[21]。
为此,一些研究结合神经网络和强化学习,将 DRL 引入到混合动力汽车的能量管理领域,利用神经网络拟合值函数,避免了状态离散化[21-24]。Han 等[25]在基于 DRL 的能量管理策略中应用双层网络[26]的方法,避免算法在离线训练中陷入局部最优,在控制性能方面相比其他基于学习的策略具有一定优势。Wu 等[21]针对混合动力公交,提出一种基于 DRL 的能量管理策略,在固定路线和工况下进行的训练和应用结果显示,所提出的策略比传统强化学习具有更好的收敛性和燃油经济性。但对于非公交类车型,行驶工况多变,需要在典型工况下训练,并在未知工况下验证控制效果。上述基于 DRL 的能量策略,控制对象均为油电式混合动力汽车,而对于FCHV 来说,策略除了提高燃油经济性和维持电池 SOC 以外,还应该考虑提升燃料电池寿命,降低整车成本。
本研究针对 FCHV 提出一种基于 DRL 的能量管理策略,通过在奖励信号中加入寿命因子,限制 FCS 输出功率的波动,起到延长系统寿命的作用;同时,通过限制动作区间的方法,使FCS 工作在高效率区间,提高整体效率。在算法角度,利用目标值网络等技巧加快算法收敛,提高泛化性能。所提出的策略在 UDDS、WLTC 和Japan1015 等标准工况下进行了离线训练,并在NEDC 工况上进行了实时应用。仿真结果表明,所提出的策略可以得到接近动态规划的最优燃油经济性,大大减小了功率波动,具有较好的燃料电池寿命增强效果。在验证工况下,所提出的策略在燃油经济性、平均效率和平均功率波动方面的表现都超过了基于强化学习的策略,表现出较好的工况适应性。
2 控制模型的建立
本文使用的燃料电池混合动力汽车动力传动系统结构如图 1 所示,主要由 FCS、电池、DC/DC转换器和电机等组成。整车和动力系统的主要参数如表 1 所示。
2.1 燃料电池混合动力汽车的需求功率
当工况已知,可以根据车辆的动力学平衡方程计算出总需求功率Preq:
(1)其中,f为滚动阻力系数;M为整车质量;g为重力加速度;α为坡度;ρa为空气密度;A为迎风面积;CD为空气阻力系数;v为车速;δ为质量系数;a为车辆加速度。车辆的功率平衡方程为:
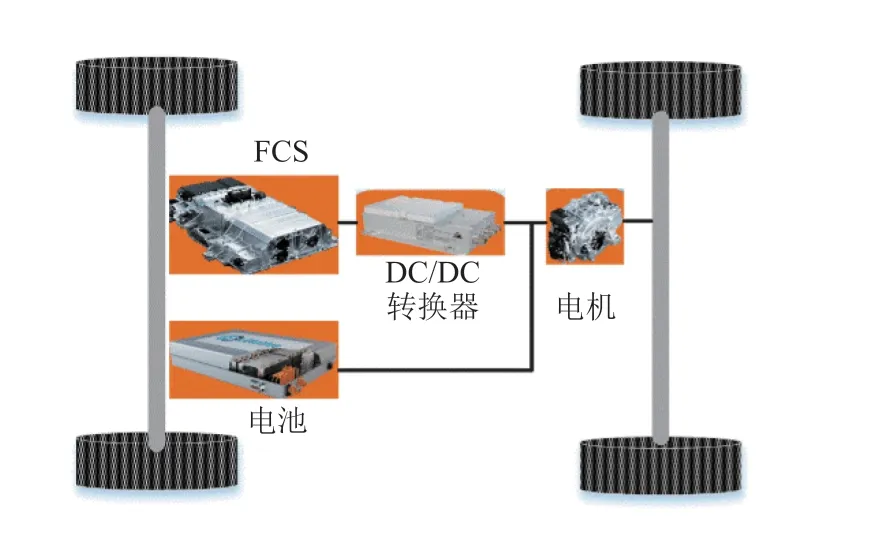
图1 燃料电池混合动力汽车动力系统结构Fig. 1 Powertrain configuration of fuel cell hybrid vehicle
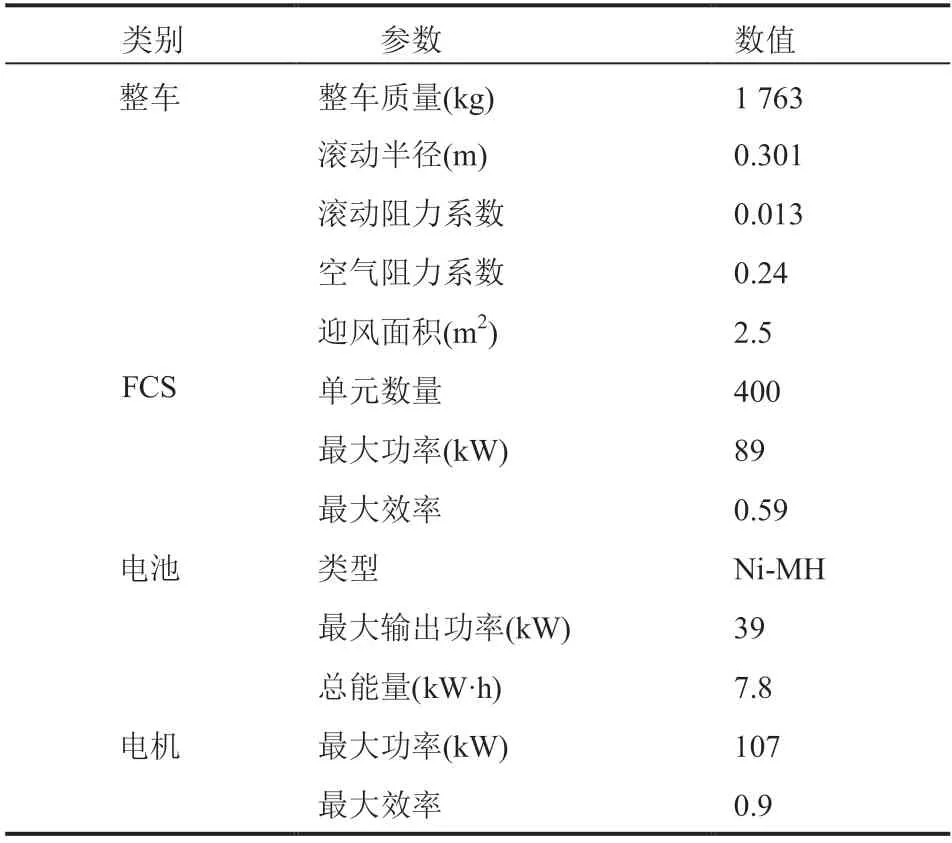
表1 整车主要参数Table 1 Fuel cell hybrid vehicle data

2.2 燃料电池混合动力汽车的部件模型
2.2.1 燃料电池系统模型
作为 FCHV 的主要动力源,FCS 将氢气和氧气反应的化学能转换为电能,其效率和燃料消耗率均与功率相关,关系曲线如图 2 所示。由于能量管理策略不涉及 FCS 的其他内部参数,因此不对模型细节进行讨论。
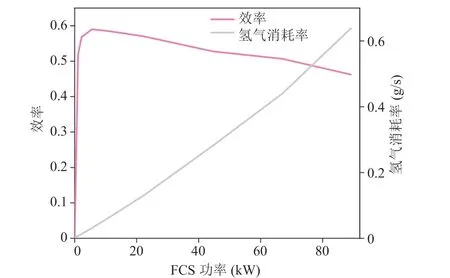
图2 燃料电池系统(FCS)氢气消耗率和效率曲线Fig. 2 Efficiency and hydrogen consumption rate of the FCS

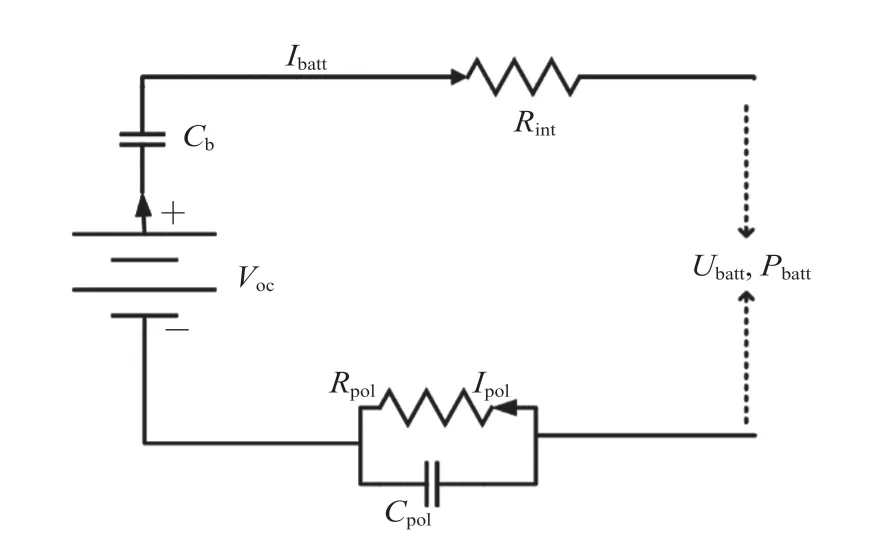
图3 电池的 PNGV 模型Fig. 3 Equivalent circuit of the PNGV battery model

2.2.3 电机模型

3 基于强化学习的能量管理策略
3.1 算法概述
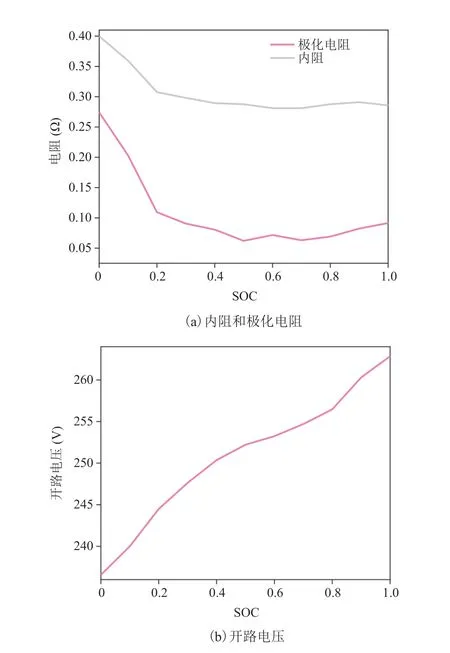
图4 电池 SOC 和电池参数的关系曲线Fig. 4 Influences of the battery SOC on different battery parameters
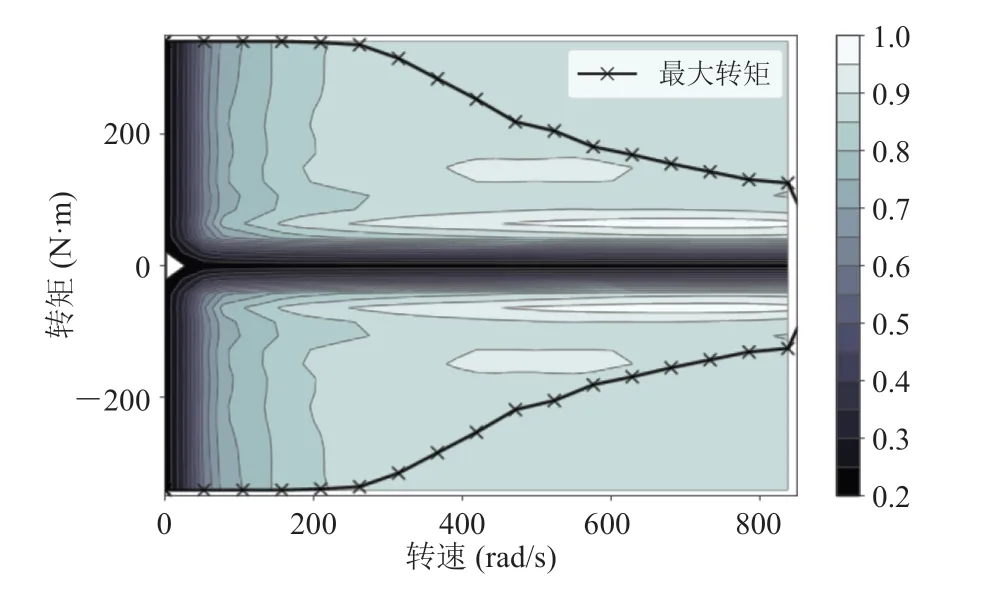
图5 电机效率图和最大转矩曲线Fig. 5 Motor efficiency map and maximum torque curves
强化学习主要包含智能体、环境、状态、动作和奖励函数等要素,其核心思想是智能体发出动作,通过与环境交互不断地试错,而环境根据反馈的奖励信号更新状态,改善策略直到收敛。由于车辆工况的随机性导致需求功率随机变化,故为了简化模型,一般将工况作为一阶马尔科夫过程,计算出对应工况下的概率转移矩阵,而策略在学习过程中根据该矩阵更新状态。基于强化学习的能量管理策略框架如图 6 所示。
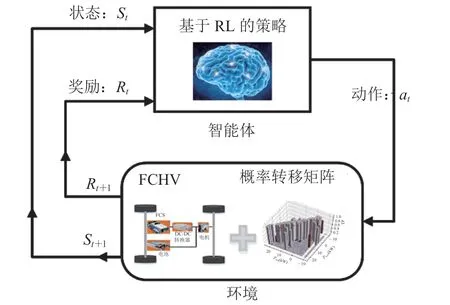
图6 基于强化学习的能量管理策略框架Fig. 6 Schematic diagram of reinforcement learning-based energy management strategy
基于强化学习的能量管理策略作为智能体,接收当前状态St和奖励Rt,产生动作at作用于环境,并根据概率转移矩阵更新状态和奖励函数,不断循环直到策略收敛。常用的强化学习算法是 Q 学习算法,算法目标是最大化智能体从环境中获得的累计奖励的期望,利用贝尔曼方程可以计算:

实际应用中会维护一个表格来保存每个状态-动作对的Q值,这个表格称为Q表。但对于高维状态和连续状态来说,状态离散化后Q表会迅速增大,计算负担呈指数级别增加,算法难以收敛。而利用神经网络等函数近似方法拟合Q值函数,设计基于 DRL 的能量管理策略,避免对状态的离散化,可以大大提高策略对高维状态的处理能力。本文使用深度 Q 学习算法,利用参数为θ的深度 Q 网络来拟合值函数,避免状态的离散化。

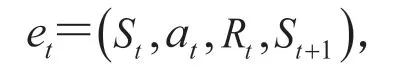
3.2 基于深度强化学习的能量管理策略
3.2.1 关键概念
在基于 DRL 算法的能量管理策略中,系统状态、动作空间和奖励信号等关键参数分别设置如下。
系统状态如公式(11)所示,将车辆当前速度、加速度、电池 SOC 作为系统状态。加速度可由相邻时刻工况车速计算,根据电路平衡关系可以计算出SOC值。

动作空间:输出动作设置为 FCS 输出功率。为了提高学习效率,同时使 FCS 在高效率区间工作,根据图 3 所示的效率数据,限制动作输出区间在[2 kW, 40 kW],并以 1 kW 作为间隔,离散化表示为:
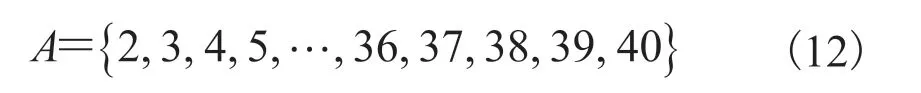
奖励信号:奖励函数用于评估向环境施加动作后,环境给予智能体的反馈,协助调整网络参数。一般将奖励设置为瞬时燃油消耗和电池SOC 相关的函数。为了最大化奖励,算法会倾向于减小燃油消耗,并尽量维持 SOC,防止电池过充或过放,以提高电池寿命。但在 FCHV中,FCS 成本较高,故能量管理策略应考虑提升系统寿命。为此,在奖励信号中引入寿命因子,奖励信号设置如下:

3.2.2 算法设计
本文基于 DRL 的能量管理策略算法如表 2所示。
评价网络和目标网络具有相同的结构,均由3 个隐含层组成,其中激活函数采用线性激活单元,每一层由 200 个整流单元全连接组成。算法主要参数设置如表 3 所示。
本文提出的基于 DRL 的能量管理策略框架如图 7 所示。策略分为离线训练和在线应用两部分。首先使用标准工况训练神经网络,将学习后的参数拷贝到车载控制器中;在现实工况中,控制器根据车速等状态直接输出动作,实现在线应用。新产生的驾驶数据会不断地进入训练工况,参与网络训练,进一步提高工况适应性。

表2 基于 DRL 的能量管理策略流程Table 2 Steps of DRL-based energy management strategy
表3 DRL 算法参数设置Table 3 Parameters setting of DRL algorithm
4 仿真结果
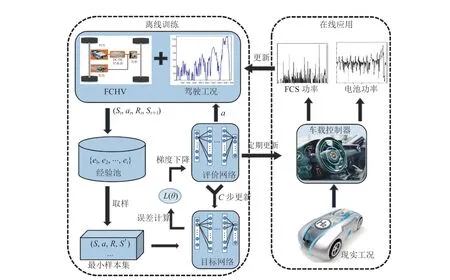
图7 基于 DRL 的能量管理策略框图Fig. 7 Schematic diagram of DRL-based energy management strategy

图8 不同工况的车速曲线Fig. 8 Velocity curves of different driving cycles
在 UDDS、WLTC 和 Japan1015 三个标准工况下对基于 DRL 的策略进行离线训练,并实时应用到 NEDC 工况,4 种工况曲线如图 8 所示。为了衡量策略的控制效果,分别实现了基于动态规划、基于 DRL(无寿命因子)、基于 RL 的策略,并从收敛性、燃油经济性、寿命增强作用、工况适应性等方面对策略性能进行评价。
4.1 收敛性
为了评估算法的学习效果,得到稳定的控制效果,需要对 DRL 的收敛性进行验证。通过对每轮循环的总奖励进行累加,并根据工况长度计算平均奖励,绘制 3 个离线训练工况下的平均奖励曲线,如图 9 所示。可以看出,本文算法在不同工况下训练到 400 轮左右时,单轮平均奖励基本稳定,表明算法具有较好的收敛性。
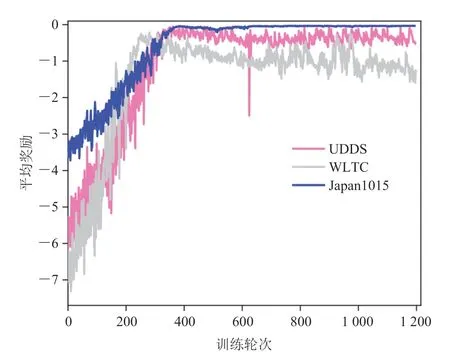
图9 DRL 算法在训练工况下的平均奖励Fig. 9 Average reward of DRL algorithm in training cycles
4.2 燃油经济性
离线训练中,将提出的策略与基于动态规划和基于 RL 的策略进行对比,FCS 输出功率和电池输出功率如图 10~12 所示,SOC 曲线如图 13所示。在相同工况下,不同策略对两个动力源的分配不同,进而产生了不同的控制效果。如基于RL 的策略倾向于更大幅度地使用两个动力源,SOC 曲线波动最大;基于动态规划的策略则更加平滑地分配动力,使 SOC 保持在一个较高的水平;而基于 DRL 的策略控制特性介于前两者之间,限制 FCS 的功率在高效率区间,其平均效率较高,有利于提升燃油经济性和燃料电池寿命。由于在同一工况下不同策略的最终 SOC存在差异,需要对 SOC 进行修正,将最终电力消耗等效为氢耗。表 4 为 3 种策略的等效燃油经济性结果。在 UDDS、WLTC 和 Japan1015工况下,基于 DRL 的策略与基于动态规划策略在燃油经济性上的差异分别为 5.58%、3.03%和 4.65%,达到了接近最优的结果;在基于 RL的策略基础上,分别提升了 4.46%、7.26% 和5.35%。以上结果表明,基于 DRL 的策略在提高燃油经济性和维持电池 SOC 方面具有较好的效果。
4.3 寿命增强作用
将基于 DRL 和基于 DRL(无寿命因子)的策略对应的平均功率波动大小进行比较,结果如表 5 所示。在 3 个训练工况下,与无寿命因子的策略相比,本文提出的策略分别将功率波动降低了 10.27%、47.95% 和 10.85%,其他性能如平均效率、燃油经济性基本相当甚至略有提升。这表明在典型工况下,考虑寿命增强的策略将平均功率波动均降低了10% 以上,有利于提升燃料电池的寿命。
4.4 工况适应性分析
基于 DRL 的策略离线训练好后,在线应用于未知的 NEDC 工况,验证其工况适应性。将仿真结果与基于动态规划和基于 RL 的策略进行比较。其中,基于动态规划将 NEDC 作为已知工况计算最优燃油经济性;基于 RL 的策略在 3 个训练工况下离线训练,在验证工况下根据Q表实时控制。验证工况下,FCS 和电池输出功率如图 14 所示,SOC 曲线如图 15 所示,等效燃油经济性如表 6 所示。在验证工况下,与基于 RL 的策略相比,本文提出的策略将燃油经济性提高了3.39%,与最优燃油经济性差异在 10% 左右,具有明显的效率优势和减小功率波动的作用,表明该策略对工况的适应性。
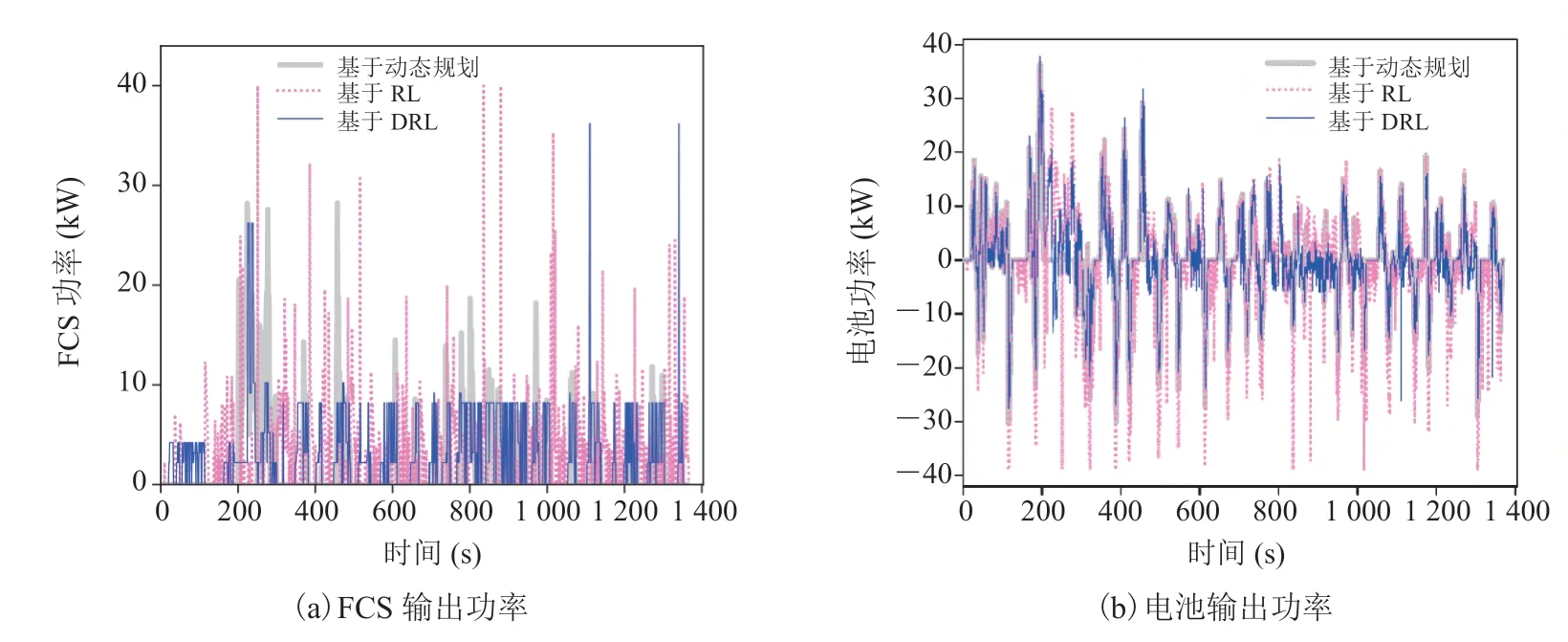
图10 UDDS 工况下的功率输出Fig. 10 Power output under UDDS
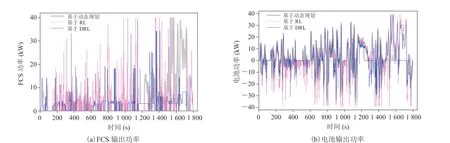
图11 WLTC 工况下的功率输出Fig. 11 Power output under WLTC
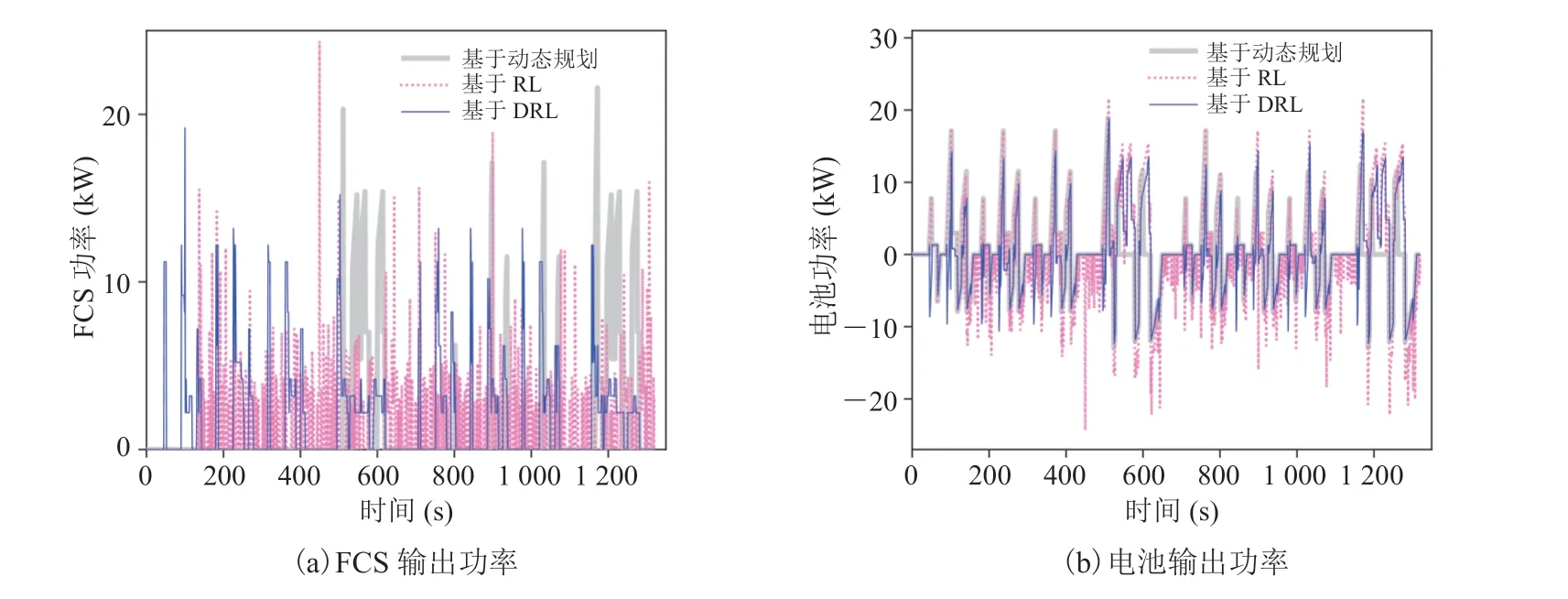
图12 Japan1015 工况下的功率输出Fig. 12 Power output under Japan1015
5 讨论与分析

图13 训练工况下不同策略的 SOC 曲线Fig. 13 SOC curves of different strategies under training cycles
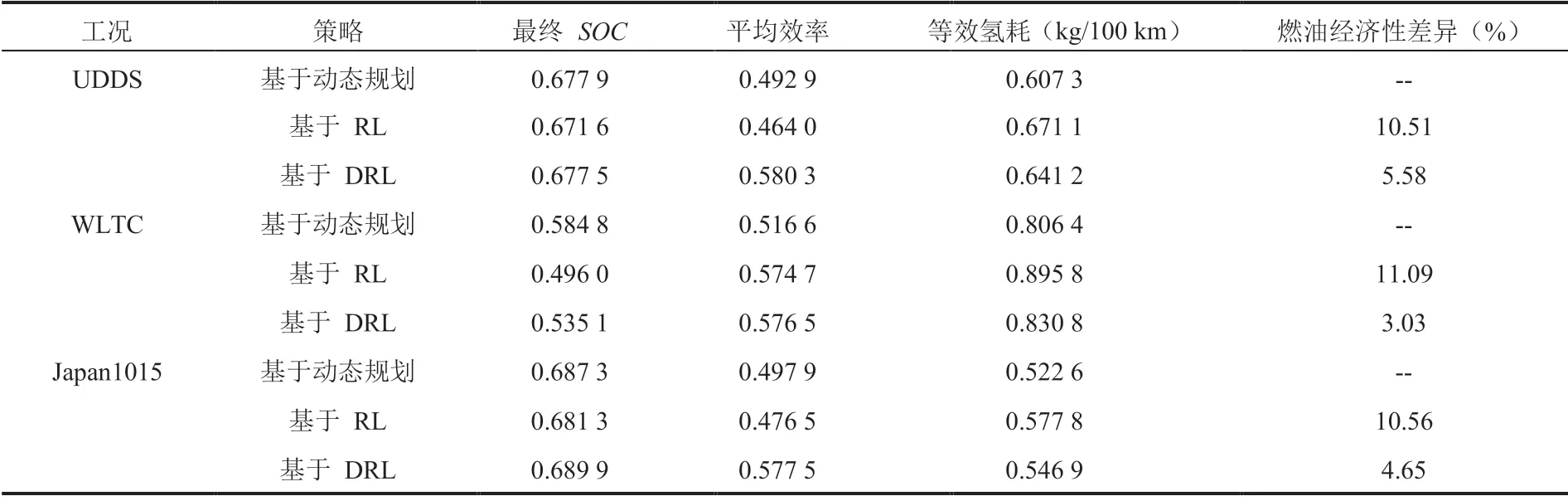
表4 训练工况下不同策略的燃油经济性比较Table 4 Fuel economy of different strategies under training cycles
表5 训练工况下的平均功率波动Table 5 Average power fluctuation under training cycles
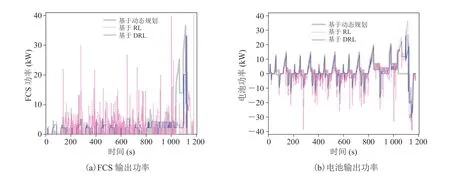
图14 验证工况下的功率输出Fig. 14 Power output under validation cycle

表6 验证工况下的燃油经济性比较Table 6 Fuel economy of different strategies under validation cycle
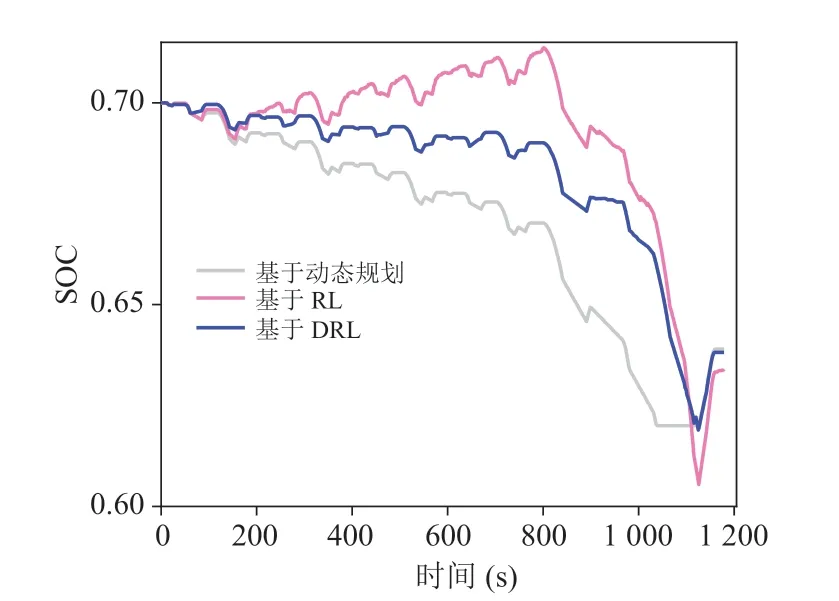
图15 验证工况下的 SOC 曲线Fig. 15 SOC curves of different strategies under validation cycle
目前基于 DRL 的混合动力汽车能量管理策略,控制对象主要是油电式混合动力汽车,以减少氢气消耗和维持电池 SOC 为控制目标[21,33-35]。对于 FCHV 来说,燃料电池成本较高,故提高其寿命对降低整车成本具有重要意义[28]。本文针对 FCHV 设计了一种基于 DRL 的燃料电池寿命增强型能量管理策略。仿真结果显示,该策略在收敛性、燃油经济性、寿命增强作用和工况适应性上都具有较好的性能。得益于目标值网络等技巧,相比已有研究[22],所提出的策略奖励信号收敛更加稳定。燃油经济性方面,所提出的策略达到了基于动态规划的 95% 左右,相比之下,Wu 等[21]离线训练时经济性仅达到了基于动态规划的 89%,Han 等[25]的研究结果则为 93%。分析原因:主要是本研究设计了合理的奖励信号权重因子,并使用了经验回放等技巧。另外,本策略使用动作区间约束来提高整车效率。Lian 等[35]在油电式混合动力汽车上也采用类似的方法,针对发动机设置了最优工作曲线,最终平均燃油经济性达到基于动态规划的 94% 左右。本文的创新点主要体现在:通过在 DRL 的奖励信号中加入燃料电池寿命因子,有效降低了燃料电池功率波动,提升了其使用寿命;限制 FCS 动作输出在高效率区间,提升了整车效率;策略离线训练后在线应用到未知工况的结果表明,所提出的策略具有较好的适应性。未来的研究内容将主要集中在两方面:(1)设计连续控制的 DRL 能量管理策略,避免控制动作的离散化误差;(2)使用硬件在环或实车试验对策略进行验证,以更加贴近真实环境。
6 结 论
本文针对 FCHV,设计了基于 DRL 的寿命增强型能量管理策略,在奖励信号中加入寿命因子,降低 FCS 功率波动,并且限制燃料电池输出功率在高效率区间,提高整车效率。仿真结果显示,所提出的策略在不同工况均能收敛,表明其具有较好的稳定性。在 3 个训练工况下,其燃油经济性接近动态规划的最优燃油经济性,比基于 RL 的策略分别提升了 4.46%、7.26% 和5.35%,并将功率波动降低了 10% 以上。实时应用中,所提出的策略在燃油经济性、寿命增强效果、平均效率方面均优于基于 RL 的策略,表明本文策略具有较好的工况适应性。
