一种并行二值图像连通域标记算法∗
2021-06-02甘晓英何晓栋
甘晓英 白 阳 何晓栋 刘 斌
(1.西安铁路职业技术学院电子信息学院 西安 710014)(2.陕西科技大学电子信息与人工智能学院 西安 710021)
1 引言
连通区域一般是指图像中具有相同像素值且相邻的前景像素点组成的图像区域。如果像素点A与B邻接,则A与B连通。所以,如果A与B连通,B与C连通,则A与C连通。相互连通的像素形成了一个区域,而不连通的像素形成了不同的区域。一个所有的像素相互连通像素构成的集合,成为一个连通区域。CCL(Connect Component Label⁃ing)是连通域标记[1]领域的一个常见问题,连通区域分析是一种在图像分析处理的众多应用领域中较为常用和基本的方法。传统的单线程算法主要通过对标记矩阵进行线性扫描,后进行等价类划分,而后通过一定规则合并等价类,最终实现连通域标记的过程。但单线程算法的计算能力极其有限,在处理像素较多的二值图像时,效率相对较低。如果采用单线程的方法处理数量较多的、像素较多的图像时,是十分浪费时间和精力的。
GPU为图像处理器,又称显示核心、视觉处理器、显示芯片,主要被用于计算机中的辅助图形处理,是一种专门在工站、游戏机和一些移动设备上图像运算工作的微处理器,是特意为处理较为复杂的数学几何运算。而GPU本身也是一种多核设备,将一般的数学问题模拟为图像计算问题通过GPU加速处理从而实现CPU并行计算的效果,目前GPU并行计算广泛应用在区块链货币挖矿、气象预测等领域有着广泛的应用[2~3]。本文旨在通过对CCL问题的可并行化进行研究,提出适合于GPU并行处理的标记算法[4],实现并分析算法效率。
2 连通域标记算法目前研究现状
轮 廓 跟 踪 连 通 域 标 记 算 法[5](Fu Chang,Chun-Jen Chen等设计实现)是根据由一次光栅扫描的标记和再次对连通区域进行扫描判断一个连通域,此算法在运用中有优良的线性特性和鲁棒性。混合对象标记算法[6](J.Martin-Herrero设计实现)根据光栅扫描以及队列的优缺点,将二者联合使用,实验效果比较满意。高速组件标记算法[7](T.Goto,MYoshida等设计实现)使用遍历邻接矩阵标的算法记出等价像素。两阶段连接组件标记算法[8](K.Wu,K.Suzuki设计实现)是判断每个等价像素点是否等价并对应一个点,彼此衔接变为环。时至当前,使用CPU单线程方式处理连通域标记算法的效率已经达到一个瓶颈,在目前的基础上再有所提高已经不太可能,或提升的空间十分有限。但基于GPU多线程并行处理的方式已经成为大大提升算法效率的可能,例如重庆大学的覃方涛[9]等通过使用GPU来提升标记算法的效率,但存在一定的缺点,并不是一个十分完整的算法,不能再某些测试样本中使用,而且该算法的实现效率较低。北京科技大学徐正光[10]实现了小于一千像素图像的的连通域标记算法,但时下这样的算法越来越不能满足图像处理需求,适应性较差。此外还有很多学者[11~13]设计的算法,归根结底属于等价标记算法,并无太多创新点,运算速度也没有太大的提升。
3 连通域标记
在数字图像中,图像的最小单位为像素,每一个像素四周都有八个完全不一样的像素,像素的邻接关系为上下左右四个像素为四邻接关系,若包括对角线位置的四个像素,就为八邻接关系,如图1所示。
如图1所示,是二值图像连通域标记中的八连通域结构,八连通域是兼顾当前像素的左上、上、右上、左、右、左下、下、右下等八个方向[14]的连接状况。八连通域则定义为
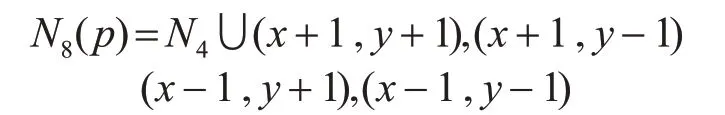

图1 八连通域

图2 光栅扫描
从图像左上角的第一个像素开始向后扫一条水平线,然后快速地回到左边偏下一点像素的位置,再扫描第二天水平线,照此固定的顺序扫描下去,直到最后一条水平线,即完成整个图像的扫描。
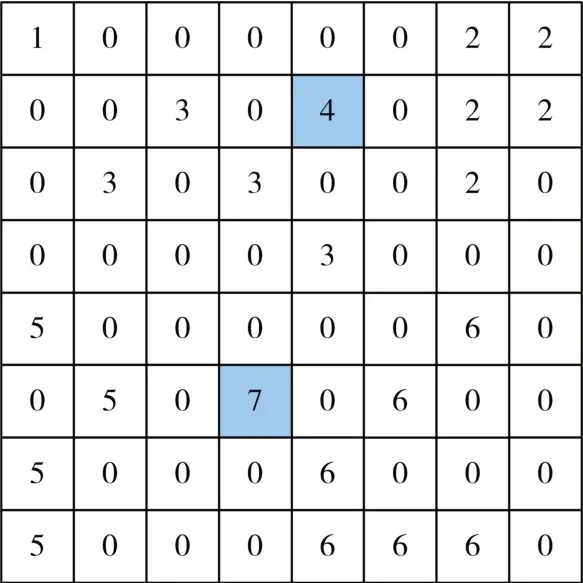
图3 一次扫描的结果
如图3所示,是经过光栅扫描一次后的标记结果,可以发现因为光栅扫描的局限性(只能顺序扫描)会导致在八连接体规则下原本相连的像素之间会有不同的标记,因此一次光栅扫描后还必须进行实际连接标记之间的合并,才能保证连接标记的正确性。
4 连通域标记的并行化
4.1 实际标记合并问题
二值图像连通域快速标记算法是一种效率较高的单线程标记算法,在第二步的等价标记合并时采用集合合并方式有效提升了算法整体处理效率。
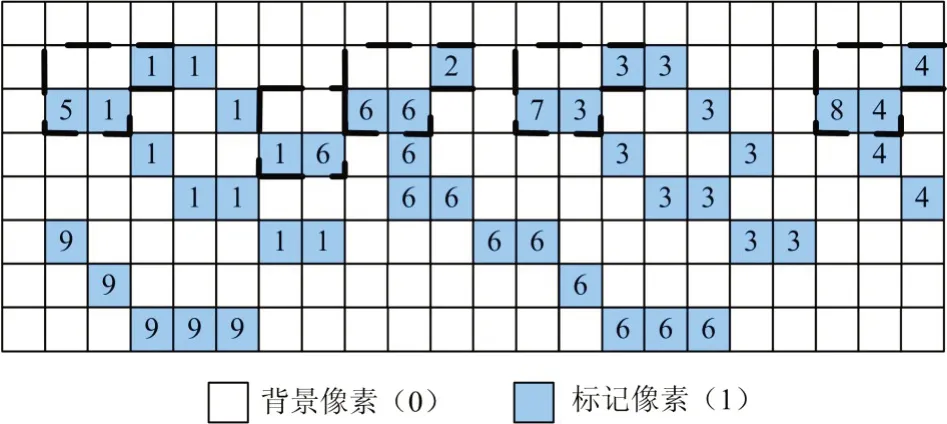
图4 快速标记算法第一次标记结果
连通域快速标记算法标记结果如上图4所示,从图中可知标记像素“5”和“1”,“1”和“6”,“6”和“2”,“7”和“3”以及“8”和“4”等价,算法需要一个快速而有效方式处理等价合并。经对比分析在基于CPU的二值图像连通域标记算法中上述算法效率最高也是最具鲁棒性的,对于各种类型的图像进行的标记实验中都表现为最优。
4.2 基于CPU的算法的效率瓶颈
20世纪末期,GPU刚刚使用时,其浮点运算的能力和当时的CPU并没有太大的差别,但以后的大约10年的时间里,CPU处理器的发展遇到了瓶颈,电路密度由于制造工艺而无法大幅优化,时钟频率由于高功耗也无法进一步提升,多核由于其他方面的小号并未使运算效率线性提升。摩尔定律开始发挥不出应有的功效。由上述可知基于CPU的二值图像连通域标记算法都是单线程运行,而且都需要进行两次光栅扫描。基于CPU的单线程算法由于计算资源限制的原因效率提升空间有限。因此,提出了改变单线程顺序处理的方式,采用硬件支持的多线程并行处理的方式来提升算法的效率[15]。
4.3 可并行化分析
4.3.1 标记溯源
针对某一个二值图像,对所有像素按照像素的位置赋予一个初始标记值,而后对图像中所有的像素点自左向右逐行扫描的顺序进行扫描,并对每个像素根据八连接体规则进行反向推理,即每个像素将获得一个该像素八连接体规则递归邻域内的一个最小标记,即可以被认为是该像素的实际标记,这个最小标记值即这个连通域内部的标记值,即该区域的标记值,而这个值也是一个“顶点”,是递归区域内的“顶点”。下面将着重说明连通域存在“顶点”以及如何有效的寻找一个“顶点”。
如图5所示,在如图所示的连通域中以及八连接体规则下,“31”像素按照溯源规则得到最小标记“22”,“22”像素得到源标记值“13”,最终“13像素”的最小标记为“2”。同理,“3”像素,“11”像素,“12”像素,“20”像素,“21”像素按照光栅扫描的反向顺序最后的最小标记为“2”。
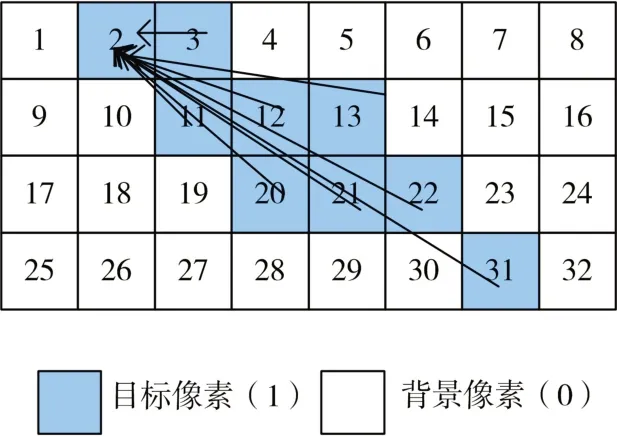
图5 标记溯源
4.3.2 伪溯源
在实际的大多数二值图像中,按照溯源规则寻找其连通域的最小标记,将会得到并不是正确的源标记值。如图6所示,通过寻找顶点的递归方法,找到属于每个像素的实际标记值,然而由于反向推理的标记方式也存在着不足,会存在伪递归的现象,称为“伪溯源”,即“顶点”并非最终标记值,因此还要必须通过一定的方式解决这个问题。伪溯源的本质是溯源的缺陷造成的,为解决这种缺陷就必须在溯源后再进行必要的处理解决这种伪溯源问题。
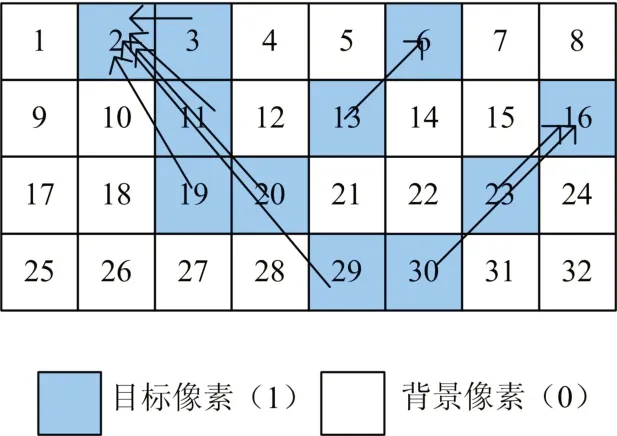
图6 伪溯源
4.3.3 标记合并处理
如图7所示,相邻四个位置上的目标“NW”、“NE”、“SW”、“SE”,这四个位置上的元素总是具有相同的标记,这个原则在八连接体规则下二值图像连通域标记问题中任何情况下都是成立的。
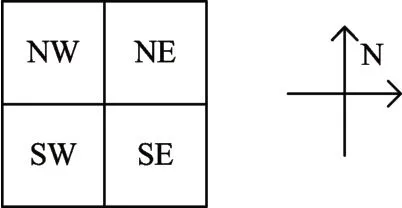
图7 四像素标记一致
如图8所示,以4像素为一整体,将图像像素分为8个区域,分别标记为“1”、“2”、“3”、“4”、“5”、“6”、“7”、“8”,进行溯源标记,结果与单个像素溯源标记的结果一致。如图所示,进行标记合并后本需要开启32个并发线程的溯源过程,只需要开启1/4数量的线程即可得出结果,减少并发量,提高溯源效率。
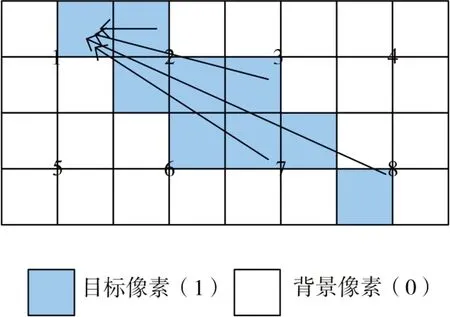
图8 像素一致标记
5 并行算法设计与实现
为了减少并发线程数目,提出了标记合并处理,所以处理的图像必须是4的整数倍像素,因此必须对图像进行必要预处理,以背景像素(0)补充目标的行和列,确保图像像素符合要求。
初始标记。如矩阵A表示,分割后的图9,所有标记值用矩阵元素的形式表示,以4像素为整体,对每个分块依次给予初始标记1,2,…25。
溯源标记。如矩阵B所示,经过溯源标记后得出的结果为矩阵C,其中存在伪溯源的标记情况,因此还需对此结果进行处理,确保标记正确。
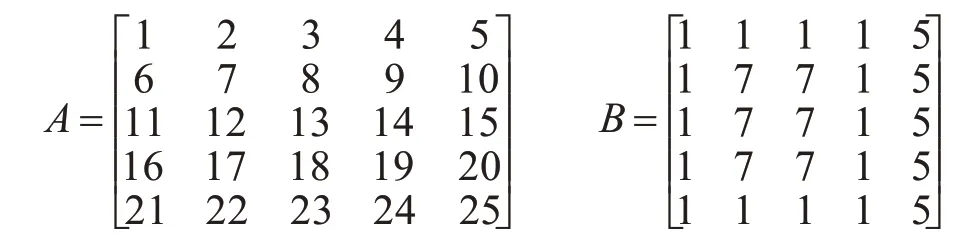
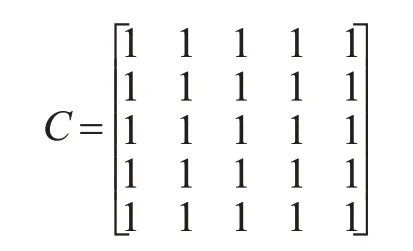

图9 图像预处理
如图10所示,对于伪溯源的情况,在经过一次反向推理的“顶点”标记后,进行循环扫描,即相邻邻域内的标记值是否相等一致,如若不相等一致用较小值覆盖较大值,以此类推直到标记值完全正确。经过实验分析,这种比对至少需要10次,最大需要64次,可能的次数为像素宽*高/16并向上取整的次数。经过实验表明分析,和多次测试结果说明,通过循环查找后最终得到了正确的图像标记值。
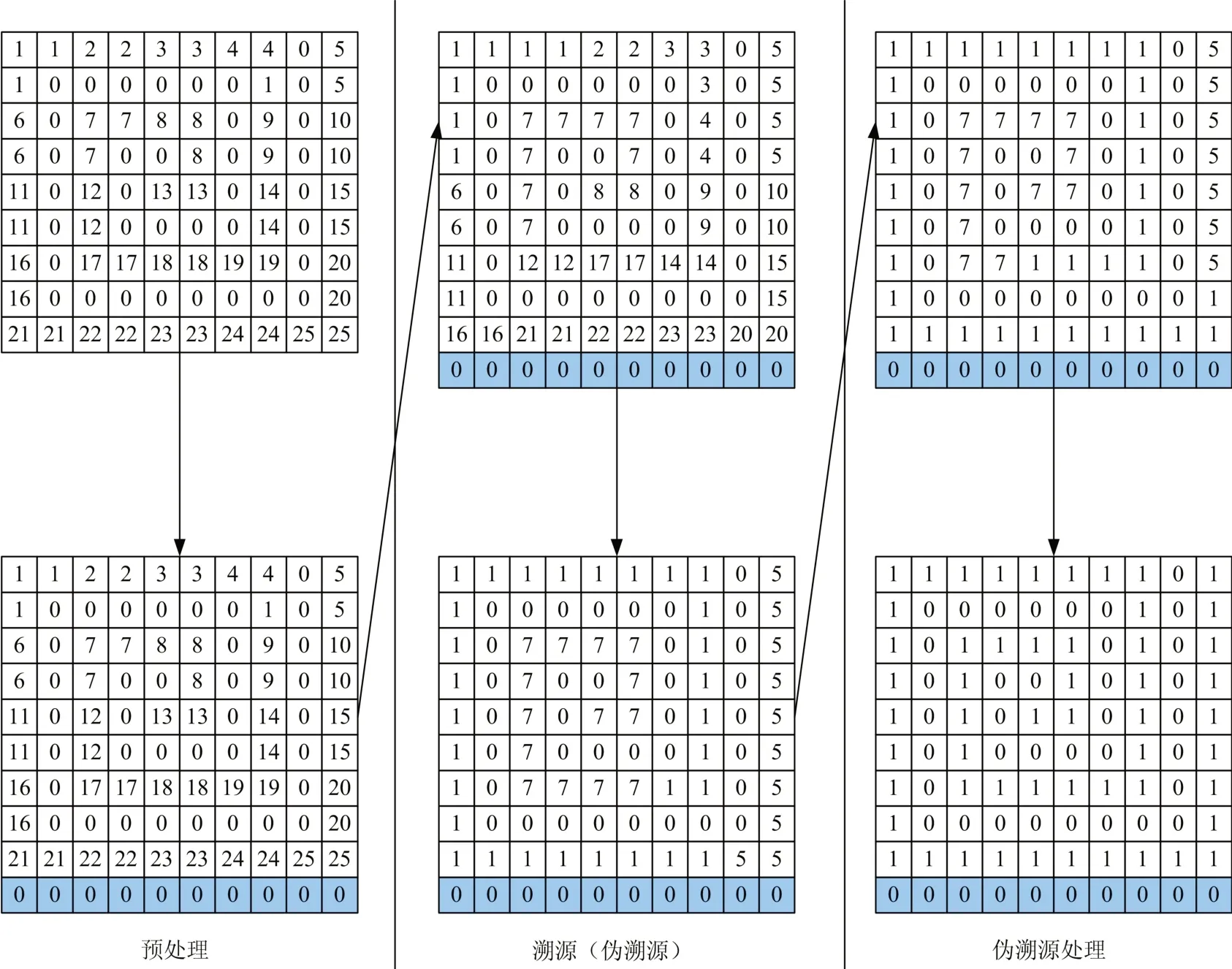
图10 整体处理过程
6 结论
二值图像连通域标记实质上是对图像的像素矩阵进行处理的,得到的标记像素矩阵,且任何算法对二值图像的标记都是一样的。按照软件测试中边界覆盖的要求,本文通过对“螺旋型”,“分叉型”等极端图像以及正常类型的二值图像矩阵进行连通域标记,并将标记结果与Lifeng He等发表的在Pattern Recognition杂志上Fast connected-com⁃ponent labeling文章中所使用的程序的标记结果进行对比,经过对比发现结果完全一致,并通过多种类型的叠加测试,结果均与该算法的标记结果一致,确保了本文所设计的算法的有效性。如下图所示,是具体标记结果的情况。

图11 原始二值图像矩阵
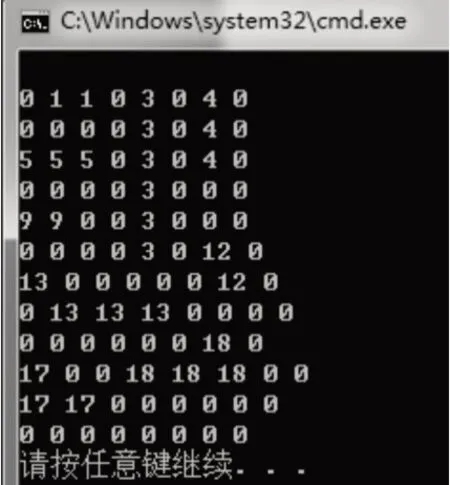
图12 标记结果矩阵
如图11和12所示,图11是标记前的二值图像矩阵,图12是标记后的标记值矩阵,根据二值图像连通域八连接体标记规则,标记结果有效。
为了比较算法采用并行处理和CPU单线程处理的效率,分别将算法在GTM520M_E和K20_E以及CPU进行了实现。GTM520M_E是入门级显卡,也就是低端显卡,性能很一般。K20_E属于高性能计算产品,基于Kepler架构。最终结果如图13所示。
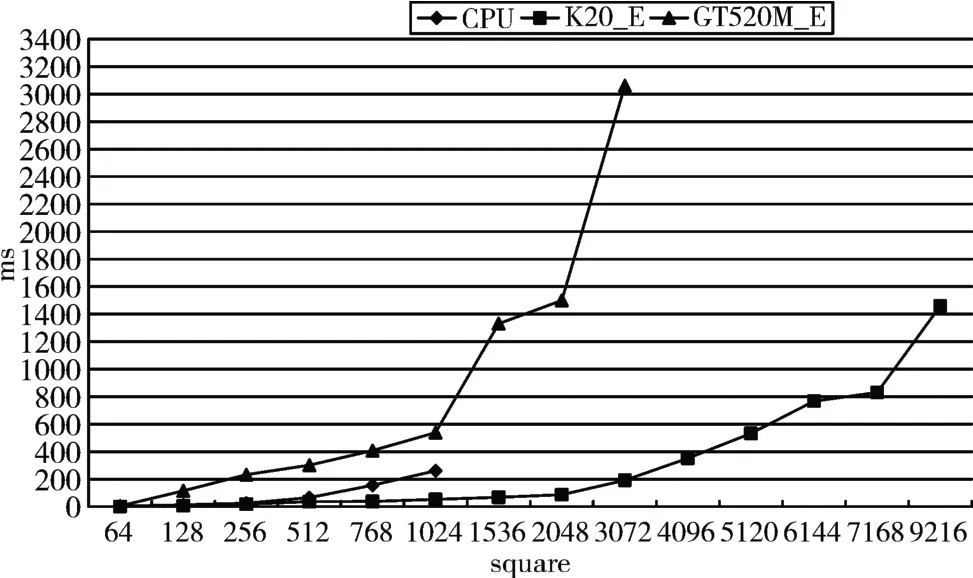
图13 算法效率测试
如图13所示,在像素较少的初始区间,算法在K20_E的计算效率要高于入门级GPU,以及明显优于CPU。在图像像素不断增多后CPU算法效率不断下降,尤其当像素达到一定值时,算法效率几乎呈垂直下降。而并行处理算法效率虽然也会有所下降,但相较于CPU来说,算法在并行处理时,能够处理像素较多的图像,并且效率并不会有非常明显的下降。由于基于单线程CPU算法设计处理极限为1024*1024大小的图像,根据线性回归分析,在图像像素越多,包含的连接体数目越大时并行算法具有明显的优势,甚至入门级的GPU设备效率也会高于单线程CPU算法。另外对并行算法的稳定性也进行了测试,在同一大小图像包含不同数目的连接体时标记的速率差的绝对值在10ms内,所以并行处理算法具有较高的稳定性。
7 结语
通过对现有二值图像标记算法的研究探讨,针对标记算法的缺陷,对连通域标记问题进行了GPU可并行化研究,并根据研究结果设计和实现了算法。最终实验结果表明并行标记算法效率整体高于单线程CPU标记算法,尤其是图像像素不断增多后,效率增加更为明显。但目前算法对略小的图像的应用性不是太好,处理效果不明显,这是今后的改进之处。
