基于Word2vec和改进TF-IDF算法的深度学习模型研究∗
2021-06-02徐瑞龙
石 琳 徐瑞龙
(江苏科技大学计算机学院 镇江 212003)
1 引言
随着电子商务的发展,网上购物已经逐渐成为人们主要的消费方式,随之催生了大量物流产业,而物流服务的好坏直接影响了客户对网购的满意度。因此对物流评论数据进行挖掘分析,不仅可以帮助商家更好地了解物流情况,选择合适的合作厂家,还可以为物流业改进服务提供参考。因此,对物流评论进行情感分析具有重要的研究意义和实用价值。
目前用于文本情感分析的方法主要有:1)基于情感词典的文本情感分析法;2)基于机器学习的文本情感分析方法。基于情感词典[1]的情感分类方法是指提前建立好词典,以情感词典作为判断情感倾向的依据,通过计算得分判断最终极性。但是情感词典的质量和覆盖度直接影响其分类结果,同时构造情感词典的和判断规则又会耗费大量的人力,所以推广能力较差。然而,基于机器学习的分类方法的性能主要取决于数据集的标注质量,但是数据的标注需要投入大量的人工成本[2]。
随着深度学习的兴起,深度神经网络在自然语言处理领域也获得了革命性的突破。在中文文本情感倾向方面,周咏梅等[3]提出了一种基于HowNet和SentiWordNet的汉语情感词典构建方法,将单词的情感强度分解为多个语义单元,自动计算出单词的情感强度,并采用词典校对技术优化了单词的情感强度值。阳爱民等[4]根据Turney的思想,结合种子词和其他词语在搜索引擎中的回馈值,并通过计算词语SO-PMI值,判断词语情感极性。杨力月等[5]在传统情感词典的基础上通过优化语气词权重计算方法和词典的构造方法,改进了情感词典中的微博情感词典。首先利用开源情感词典、网络情感词典等构造出基础情感词典,然后在此词典的基础上结合中文语法规则,利用句间和句型关系计算句子的情感倾向,以此提高微博文本情感分类的准确性。张成功等[6]提出了一种以极性词典为基础改进的情感分析算法。主要做法是构建一个相对完备、高效的词典,其中包含了基础情感词典、领域词典、修饰词典和网格词典等,把情感倾向词和情感修饰词放在一起构建成极性短语,利用构建好的词典进行情感倾向分析。杨超等[7]基于现有的词典,提出了一种新的情感词典并开发了一个自动舆情分析系统。
2003年,Ducharme等[8]利用神经网络训练词向量来表示文本。词向量不仅能够有效地得到语义信息[9],而且还解决了数据稀疏性问题。利用词向量描述文本,并且结合深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)等进行分类可以得到比传统机器学习方法更好的效果。Sahar Sohan⁃gir[10]认为大数据对于研究至关重要,而使用深度学习最大的优势就是分析大数据,这也使得深度学习成为研究大数据的工具。深度学习可以提取其中隐藏的信息,所以该文通过应用多种神经网络模型例如长短期记忆网络(Long Short-Term Memory,LSTM)、Doc2vec和CNN模型对股票市场观点进行情感分析,结果表明深度学习方法可以有效地应用于金融情感分析。Kim等[11]通过改进的一维卷积神经网络得到句子的特征,并在进行情感分析研究中,不断调整参数和加入词向量,在不同数据集上测试分类性能。文献[12]利用LSTM把评论语句转化成词语序列进行情感分析。
论文利用Word2vec模型进行词向量转换,结合物流关键词库进行改进TF-IDF优化加权,最后把加权后的词向量输入LSTM进行训练,自动提取评价中隐含的特征,完成对物流评价的准确预测。
2 相关模型介绍
2.1 TF-IDF模型
TF-IDF是一种加权技术。它主要采用一种统计的方法,根据关键的词语在某个文档中出现的频率和在所有语料库中出现的频率来计算该词语在整个语料中的重要程度。词语的重要性会因为在文本中出现次数多而变高,同时也会因为在整个语料库中出现次数过多而降低[13]。
TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency)。所以在一篇文章中如果某个词出现的频率(TF)很高,并且在其他文章中(IDF)很少出现,则说明这个词具有较好的类别能力。[14]
计算公式:
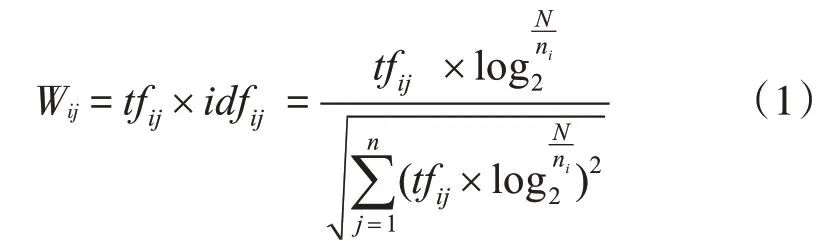
2.2 Word2vec模型
Word2vec是Google在2013年开源的一款将文本表示为数值向量的工具,主要的模型有CBOW和Skip-Gram两种[15]。Word2vec通过训练,把一些文本内容转换为机器能够理解地K维向量进行空间向量运算,而且向量空间上的相似度恰好可以表示文本语义上的相似度。[16]
本文采用的是Skip-Gram模型,Skip-Gram是依据已有的内容来预测上下文的,本模型有输入层、投影层、输出层三层,如图1所示。
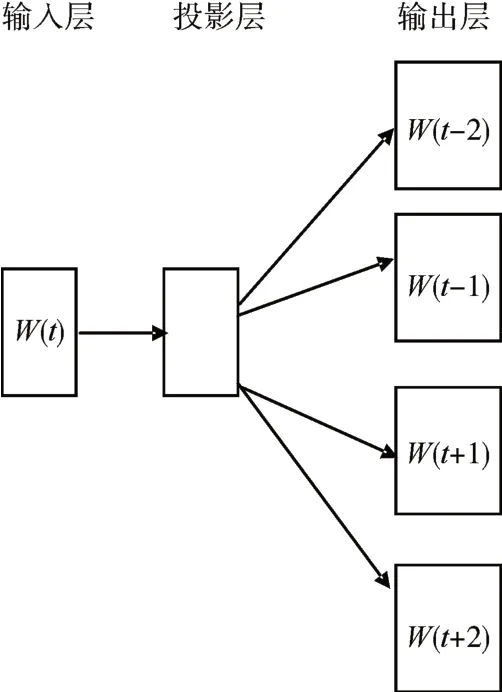
图1 Skip-Gram模型
Skip-Gram模型的训练目的就是如何让式(2)中的值尽可能地变大:
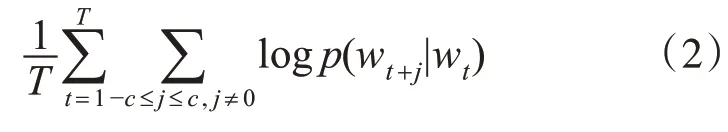
式中,c>0表示的是窗口的大小,T是训练文本的大小。基本的Skip-gram模型计算条件概率如式(3)。

其中,vw和分别是词w的输入和输出向量。
2.3 LSTM模型
长短期记忆(LSTM)网络是由RNN扩展而来,主要是在RNN中添加了一个可以判别信息是否有用的cell,通过设计其结构来删除或者增加信息。
LSTM实际上也是一种特殊的循环神经网络,所以它也包含链状结构。然而与循环神经网络重复模块不同的是,它包含四层神经网络层,每个网络层之间用着特殊的方式相互作用,并不是单个简单的神经网络层[17]。网络示意图如图2所示。
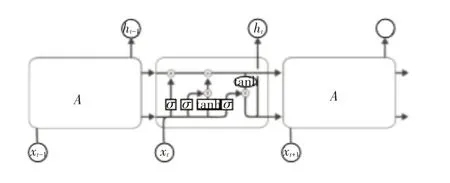
图2 LSTM网络结构
首先,LSTM要确定我们从细胞状态中抛弃什么信息。这个是由一个称为“遗忘门”的Sigmoid层控制的[18]。第一步是先获取上一层输出的ht-1和当层的xt,使用Sigmoid函数计算得到一个0-1的数[19]。其中,0代表“完全舍弃”,1代表“完全保留”。其计算公式为
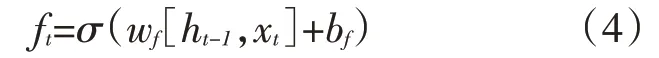
其中,代表的是Sigmoid函数,wf代表的是遗忘门的权重,bf代表的是遗忘门的偏置。
输入门主要是决定记忆单元中要存放哪些信息。它包括两部分,第一部分是输入门的Sigmoid层断定需要变更的信息[20];第二部分是经过Tanh层构造一个新候选向量,计算公式如下:
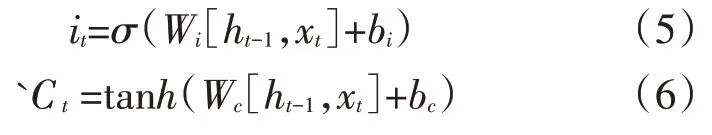
其中,σ为Sigmoid函数,wi表示的是更新门权重,bi表示的是更新门偏置,tanh双曲正切函数,wc更新候选值,bc更新候选值偏置,Ct候选值。
最终用旧状态乘以ft,决定要丢掉的部分,和新的候选信息相加合成了细胞状态的更新,计算公式如下:
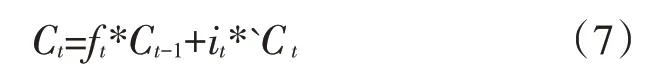
其中,Ct表示新状态。最后,将该输出结果与Sigmoid函数的输出值做乘积处理,以此获取最后的分类结果。具体计算公式如下:
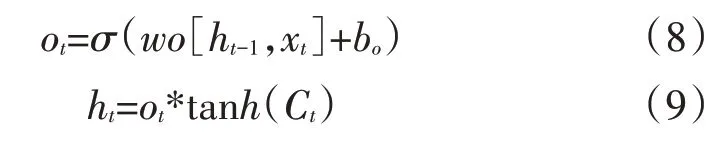
其中,wo更新输出值的权重,bc更新输出值偏置,ht最终确定输出的那部分[21]。
3 物流模型构建
3.1 改进TFIDF模型
由于传统的TFIDF方法单纯以“词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。于是我们调整TFIDF对特征项的权重计算,结合物流关键词库进行优化权重计算。
首先,利用正则表达式进行特征匹配,对于匹配的词加入特征权值的计算。改进后的计算公式如下:
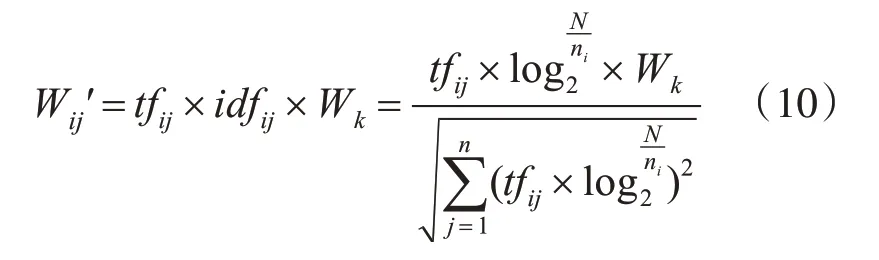
其中,Wk是结合物流关键词库匹配到的关键词的权重。
3.2 物流模型的构建
1)Word2vec词向量库的构建
首先使用天猫某品牌服装有关物流评价数据作为基础语料进行模型训练。其中包含了训练样本和测试样本,神经网络隐藏层的神经元个数即词向量维数设置为200,利用negative sampling负采样提高训练速度改善词向量的质量。
2)文本的向量表示
上文通过Word2vec把分词后的评论已经变成低维的数值向量,这让原本难以处理的高纬度高稀疏的数据变成容易读取的矩阵数据表示。同时也节省了人工进行特征选取的巨大工作量。但是因为Word2vec无法量化关键词语对评论的重要性,所以我们采用改进后的TF-IDF进行权重计算。
3)物流评价模型的构造
由于购物评价大部分是短文本,并且文本中会有数字、语气词等,所以在进行文本分类前首先进行文本预处理,去除一些没有实际意义的词语。然后将预处理后的文本作为输入,通过Word2vec把文本转换成词向量,再通过改进的TF-IDF将优化权重,最后经过LSTM网络进行分类预测。具体流程如图3所示。
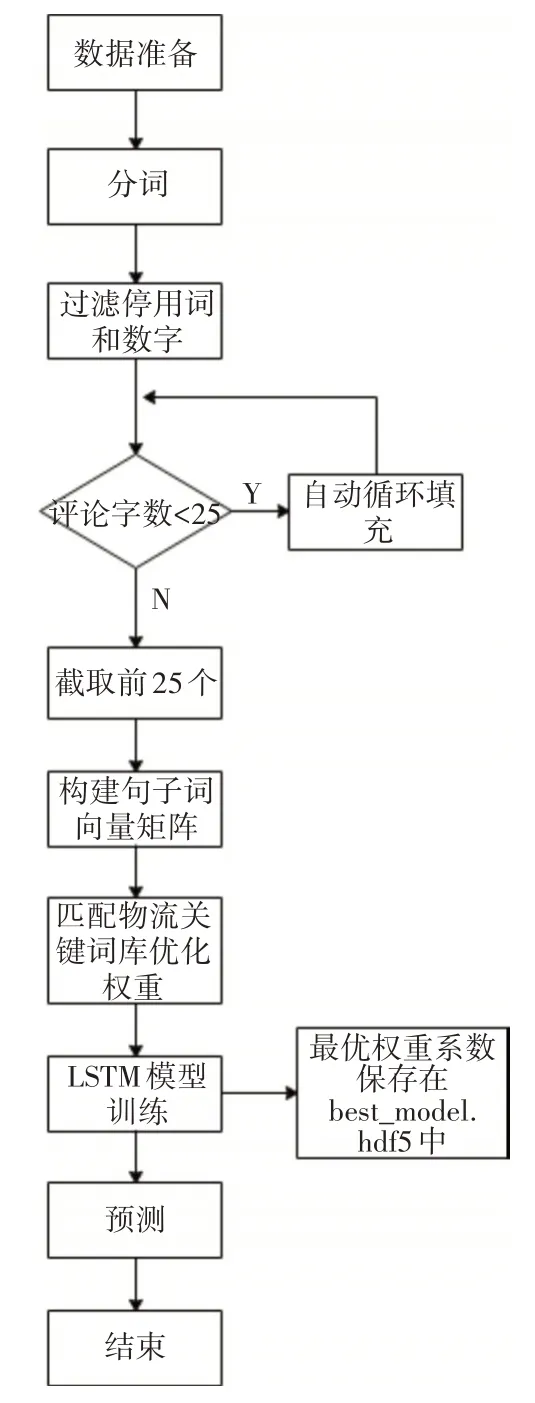
图3 物流模型构造流程
4 实验
论文实验环境为Windows10操作系统,采用Python编程语言,利用Python中的Keras库进行搭建LSTM。实验中使用的硬件环境是联想笔记本,具 体 配 置 为Intel(R)Core(TM)i5-6200U@2.30GHz,8G内存。
4.1 实验参数设置
论文研究实验软件环境主要是基于Keras与Theano搭建的深度学习平台,具体实验参数如表1所示。
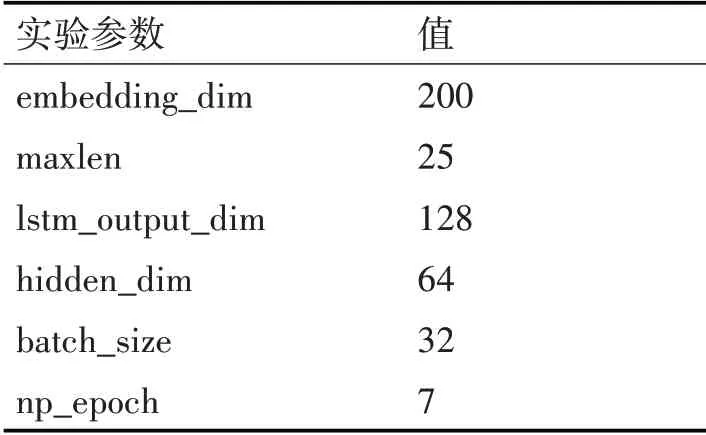
表1 实验参数
4.2 实验对比
论文采用Word2vec将评论进行词向量训练,接着利用改进的TF-IDF进行加权优化,最后通过LSTM进行预测得到结果并和其他单个模型及结合进行比较。
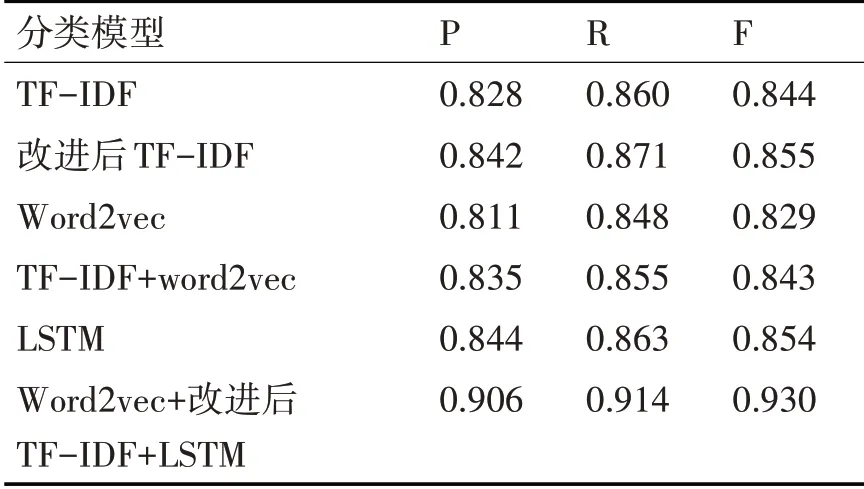
表2 不同模型实验结果对比
从表2中可以看出,对权值进行优化后的TF-IDF要比一般TF-IDF预测效果好。因为Word2vec无法量化权重,所以把TF-IDF与Word2vec结合进行预测,要比两个模型独立预测效果要好。LSTM作为深度神经网络,通过Word2vec生成词向量并且用TF-IDF量化权重最后利用LSTM进行预测,准确度在原有的基础上得到了6%的提高。
5 结语
本文的工作是利用Word2vec表示了高维的词向量,克服了传统情感词典方法的局限性。利用改进的TF-IDF对物流好差评关键词进行了加权。和传统的机器学习方法不同的是,基于LSTM模型可以不用人为的特征提取,减少了训练的时间。为商家对店铺进行及时的物流分析和改进服务提供了有效的帮助。
