二次特征融合的YOLO目标检测算法∗
2021-06-02辛月兰孙可心
朱 杰 辛月兰 孙可心
(青海师范大学计算机学院 西宁 810000)
1 引言
传统的目标检测算法[1~2]经过优化,取得了一定的目标检测效果。但是近年来,随着卷积神经网络在图像方面的广泛应用,基于卷积神经网络的目标检测算法逐渐代替了传统的目标检测算法。例如:预先从图中找出候选区域的R-CNN[3](Regions with CNN feature,R-CNN)算法;结合了空间金子塔[4](Spatial Pyramid Pooling Network,SPP NET)结构的Fast R-CNN算法;使用区域提案网络[5](Re⁃gion Proposal Network,RPN)代替穷举搜索的Faster R-CNN[6]算法。这些算法都是基于卷积神经网络的成熟的目标检测算法,同时有学者指出,将成熟的目标检测算法做改进会得到更高的检测精度[7~9]。
上述的目标检测算法是一种两阶段的目标检测算法。两阶段的目标检测算法的检测速度很低,达不到实时监测的目的。基于这种问题,Redmon[10]提出了单阶段目标检测算法YOLO(You only see once),该算法模型简单,极大地提高了检测的速度,但YOLO的候选框是通过K-MEANS[11]聚类算法得到,检测的精度不如两阶段目标检测算法。YOLOv3使用了DarkNet53主干特征提取网络,并对输出的特征层进行融合,在保证检测速度的基础上提高了检测的精度,并广泛应用于实时目标检测领域。
为了平衡检测速度和检测精度,本文提出了二次特征融合的目标检测算法。首先使用改进的可分离卷积模块来代替YOLOv3主干网络的卷积模块;其次,将原网络模型的残差连接改进为密集连接,极大地提高了感受野;最后,通过一次自上而下的特征融合[12]充分结合了上下层语义信息,提高了特征提取的能力。通过在PASCAL VOC 2007和WiderFace数据集上测试发现,该改进后的算法可以在保证检测速度的基础上,提高了目标检测的精度。
2 YOLOv3
YOLOv3将进行测试的N张图像调节成416×416大小并输入到Darknet-53特征提取网络中,主干网络提取得到13×13、26×26、52×52大小的三个特征层,分别位于主干特征提取网络的底层、中层、上层。每一个网格会有三个先验框,目标物体落在哪个网格则该网格负责物体种类的检测和边框的预测。通过每个网格的预测后得到所有预测框的位置和分类,再对预测框进行非极大抑制[13]并回归得到最终的框。其检测的流程如图1所示。

图1 YOLOv3算法流程
对于YOLOv3的网络结构,首先,主干特征提取网络采用了自上而下的单级网络模型,特征提取的网络模型简单,不能很好地提取图像特征。其次,底层特征层直接将主干网络提取的特征输出,从而导致检测的精度低。
针对上述问题,本文提出了一种改进的二次特征融合的YOLOv3目标检测算法,通过优化主干网络的连接结构和引入二次特征融合来改进YO⁃LOv3。这种方法比YOLOv3精度更高,同时保持检测速度接近YOLOv3。
3 改进的YOLOv3目标检测算法
3.1 改进卷积模块
为减小网络训练的难度,本文考虑使用可分离的轻量化卷积模块对原卷积模块进行改进。对输入N个通道的残差旁路先通过一次1×1、步长为2的卷积块,将通道数变为N/2,再通过一次1×1、步长为2的卷积块,将通道数变为N/4。通过先减小通道数再卷积的方法大大减小了网络规模。将原来的3×3卷积块改进为3×1卷积块和1×3卷积块的可分离卷积模块,在不降低网络提取特征的能力下,进一步减小了网络的训练难度。通过这种方法可以解决卷积核参数冗余的问题,减少神经网络权值参数。改进后的卷积模块如图2所示。
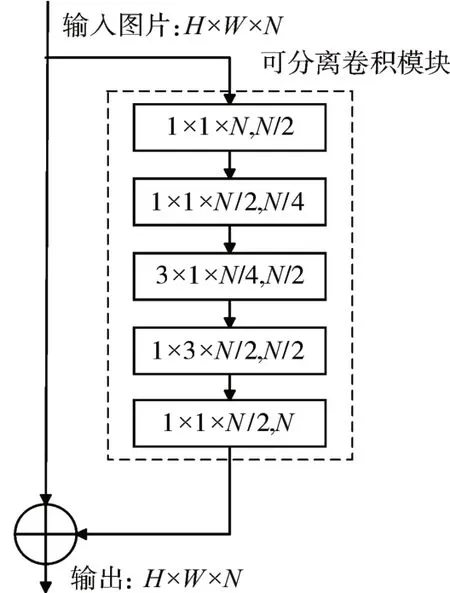
图2 可分离卷积模块
3.2 密集连接的主干网络
对于主干网络提取特征的能力低的问题,本文提出了使用密集连接[14]的思想将主干网络中的残差块连接起来,从而可以充分融合上下文的信息,增强了特征提取的能力。
密集连接结构的每一层得到的特征层都传递给下一层,使得每一层都接收网络上层的所有信息,每一层节点的计算如式(1)所示,x0~xn-1表示输入的n个向量,wn表示第N个向量的权值,bn为第N层向量的偏置。
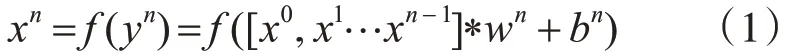
对于第n层的输入就是x0、x1…xn-1,xn输出也会再次结合x0、x1…xn-1传递给xn+1,所以经过密集连接后每一层都有上层的信息,对于最后一个卷积层其包含了整个主干网络的特征融合。考虑到密集连接的卷积层过多会导致网络模型变大、检测速度变慢,所以本文考虑在YOLOv3主干网络中部分使用密集连接块。将第三个残差卷积块以及最后一个残差块使用密集连接,连接方式如图3所示。Sepa⁃rableBlock为上述的可分离卷积模块。
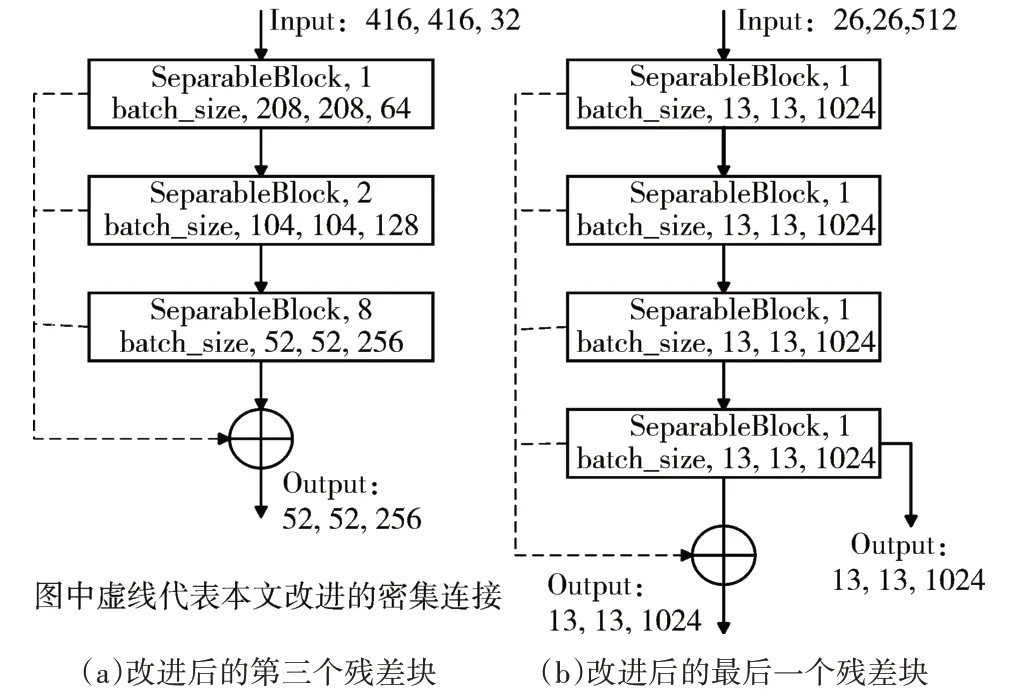
图3 改进后的第三个和最后一个残差块
通过密集连接可以增大52×52特征层的感受野。如图3(b)所示,本文将其进行密集连接可以大幅度的继续增强其特征提取的能力。
3.3 二次特征融合
对于原始特征融合模型,其通过底层信息的卷积和上采样再与上层信息进行融合,最终得到三个大小不同的特征层。在原本的特征融合结构上进行了改进,本文对于第一次自下而上特征融合的底层特征层是上文提到的经过密集连接得到的特征层,通过该方法可以提高特征融合的性能。如图4所示,虚线框内则是本文提出的二次特征融合模块。该模块将得到的三个特征层进行二次处理,52×52的卷积层再次与没有经过密集连接的13×13特征层进行融合,进一步解决大尺度特征层特征提取能力的不足;再对52×52大小的特征层进行下采样与26×26大小的特征层进行融合,同时对26×26的特征层进行通道调整并输出最终的特征层;再将26×26大小的特征层进行卷积和下采样与13×13的特征层进行融合,得到最终的13×13大小的特征层。通过二次特征融合会得到最终输出的特征层,添加了二次特征融合的主干网络结构如图4所示。
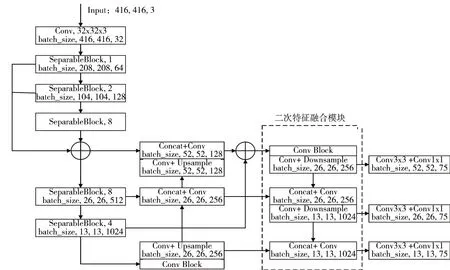
图4 改进后的网络结构
4 实验结果分析
以原始的YOLO算法为基础,训练改进后得到目标检测模型。在训练时,初始化学习率设置为0.001,加速最初的网络收敛,在训练至45000步时,将学习率设置为0.0005,权值衰减系数设置为0.0005对网络进行精修。
4.1 实验环境
本章实验的硬件使用了Intel COREi5-8400处理器、11GB显存的NVIDIA GeForce GTX 1080Ti显卡,并使用了Windows 10 1902操作系统、CU⁃DA8.0、Python3.6、Keras2.2.5、TensorFlow1.14的软件环境。
4.2 基于PASCAL VOC 2007数据集实验结果分析
本文改进的算法在PASCAL VOC 2007测试数据集上的目标检测结果如表1和表2所示。表1显示了改进的算法在PASCAL VOC 2007测试数据集上的详细实验结果,表2比较了改进的算法与最新方法使用的网络及平均检测精度(mean Average Precision,mAP)和检测速度。本实验采用每秒检测图片的数量即fps作为检测速度的衡量标准。当输入图像的大小为416×416像素时,YOLOv3方法表示为YOLOv3 416,并且其他方法也如上所述表示。

表1 本文改进的算法在PASCAL VOC2007、2012测试数据集上的检测结果
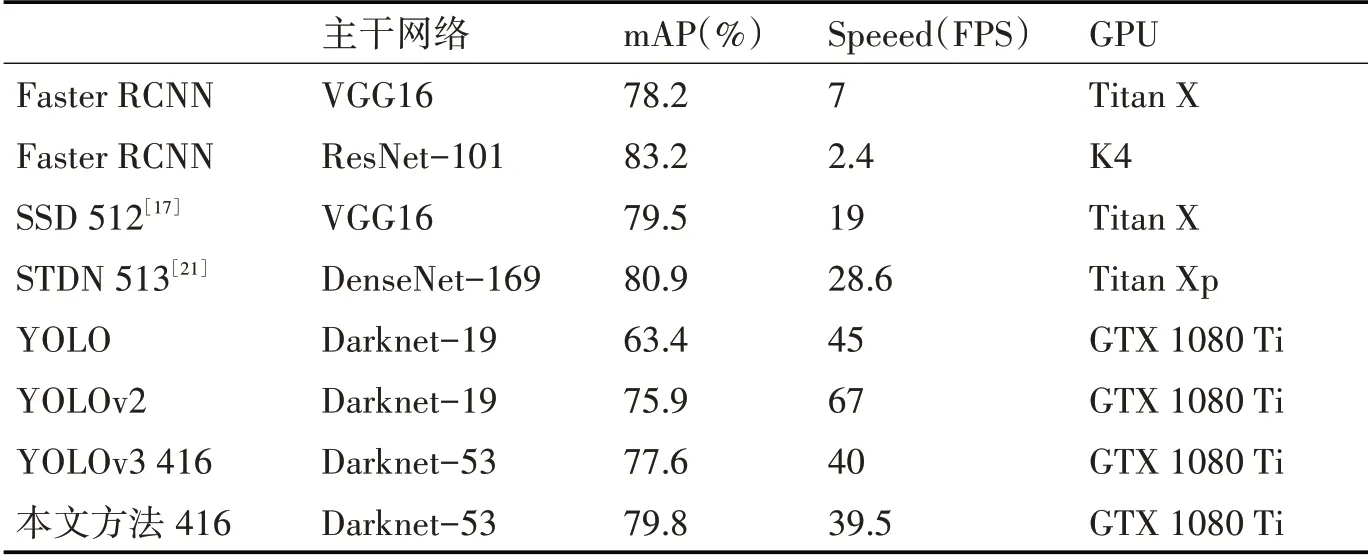
表2 性能对比
本文在同一环境下对改进后的算法进行测试,对比了其他模型在PASCAL VOC 2007数据集上的性能表现。由表1可以看出本文改进的算法对于VOC数据集的检测精度明显要好于YOLOv3。从表2可以看出,本文提出的算法在39.5fps时的平均精度为79.8%,在损失了0.5%的检测速度的基础上,精确度比YOLOv3 416高2.2%。改进后的算法的检测精度的提升是可观的。相比于两阶段的目标检测算法,在检测速度上远远高于两阶段目标检测算法,并且在准确度上也在逼近两阶段算法。
YOLOv3 416与改进后的算法的测试结果如图5所示,图5左边是YOLOv3 416检测结果图,右边是本文的检测结果图。经过比较发现,本文改进的算法在框的得分和精确度上会略高于YOLOv3算法,体现了该算法在精度方面的优势。
5 基于Wider Face数据集实验结果分析
人脸检测是基于计算机视觉的目标检测方法的重要应用之一[15~16]。本文利用WiderFace数据集来对本文提出的算法进行训练和测试。表3总结了各种算法对于该数据集的检测结果。本文采用每张照片的检测时间来代表检测速度,使得数据更直观。

图5 YOLOv3 416检测结果(左)和本文方法检测结果(右)
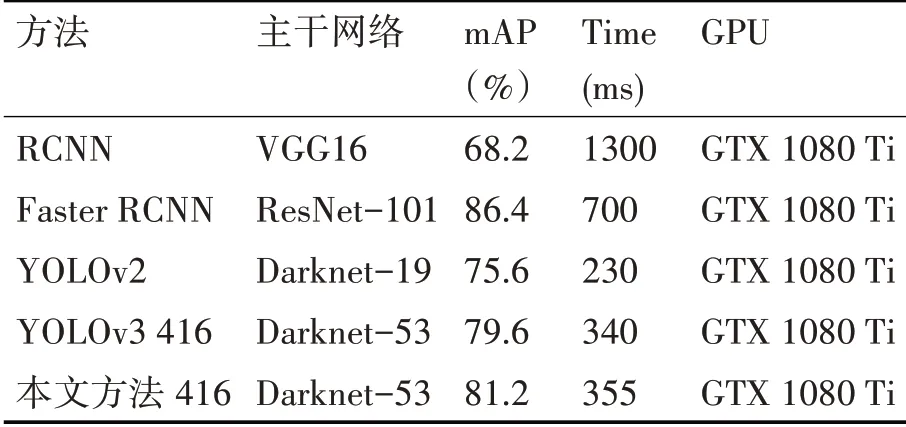
表3 性能对比
与表3中其他方法相比,本文改进的算法在检测速度与YOLOv3 416持平的情况下,平均精度比YOLOv3 416高1.6%;比YOLOv2检测精度高5.6%。相比于两阶段目标算法,本文提出的算法的检测速度要远快于RCNN、Faster RCNN算法,并且在此基础上检测精度逼近Faster RCNN。通过分析可得,本文提出的算法在WiderFace数据集上也有很优秀的表现。
YOLOv3 416与改进后的算法在WiderFace数据集的测试结果如图6所示,图6左边是YOLOv3 416检测结果图,右边是本文的检测结果图。通过对比可以看出,本文提出的算法会对于人脸的框定更加的精细,该算法的检测结果要明显好于YO⁃LOv3 416。

图6 YOLOv3 416检测结果(左)和本文方法检测结果(右)
6 结语
针对YOLO目标检测算法主干网络特征提取能力不足,不能充分融合多尺度特征的问题,本文提出了一种二次特征融合的YOLO目标检测算法。在该算法中,利用可分离卷积代替了原有的卷积模块从而减小了网络的规模;并对第三个和最后一个卷积块进行密集连接;最后,设计并引入了二次特征融合来连接多尺度特征,以保证每个输出特征层都包含有上下文语义信息。在PASCAL VOC数据集上的实验表明,本文改进后的算法在检测速度略有降低的情况下,比YOLOv3的检测精度高2.2%;在WiderFace数据集上的实验表明,对于人脸检测也有着较好的测试结果,从而使得改进后的算法能适用更多领域[17~20]。
