级联式生成对抗网络图像修复模型
2021-06-01马希涛
何 凯,刘 坤,李 宸,马希涛
级联式生成对抗网络图像修复模型
何 凯,刘 坤,李 宸,马希涛
(天津大学电气自动化与信息工程学院,天津 300072)
为解决现有算法容易产生图像模糊或纹理失真的问题,提出了一种级联式生成对抗网络图像修复模型.该模型由粗化和优化生成子网络串联而成.在粗化生成网络中设计了一种并行卷积模块,由3层卷积通路和1个深层卷积通路并联组成,当网络层数较深时,可解决梯度消失问题;在深层卷积通路中提出了一种特征提取模块,可利用不同大小的卷积核来获取更加丰富的图像信息.此外,在优化生成网络中提出了一种级联残差模块,通过对4个通道的双层卷积进行交叉级联,可有效增强特征复用;将卷积结果与模块输入特征图的元素对应相加,进行局部残差学习,可提高网络的表达能力;同时采用空洞卷积,可以充分利用上下文信息,保留更多的图像底层细节,实现图像的精细修复.仿真实验结果表明,本文算法修复图像视觉效果好,在3个数据集上峰值信噪比(PSNR)分别为18.4532、18.5496、21.5299;结构相似度(SSIM)为0.8972、0.9683、0.8956,量化结果在对比算法中均为最高,实现复杂结构和纹理信息的自动修复.
图像修复;生成对抗网络;特征提取模块;残差模块
图像修复是通过对图像缺损区域进行补全来恢复其原有的视觉效果,它是图像处理领域的研究热点,具有重要的意义和研究价值.当前图像修复算法大致可以分为2大类:传统图像修复算法和基于深度学习的图像修复算法.传统图像修复算法通常采用基于偏微分方程的方法[1]来修复小区域图像,如噪声、划痕去除等;当破损区域较大时,则通常采用基于样本块的纹理合成算法[2],利用图像破损区域周围的信息对缺损区域进行填充;在其基础上,人们提出了许多改进算法,如何凯等[3]在传统SSIM算法的基础上增加了梯度信息,利用样本块亮度、对比度和结构3个模块来确定最优样本块大小,可以获得较好的纹理合成效果.
近年来,随着卷积神经网络(convolutional neural networks,CNN)[4]和生成对抗网络(generative adversarial networks,GAN)[5]技术的快速发展,基于深度学习图像的图像修复算法不断涌现,其中,U-Net网络[6]被广泛用于图像修复领域.Pathak等[7]提出了context-encoder方法,利用卷积神经网络编码器-解码器网络结构和GAN来解决图像修复问题.Iizuka 等[8]在网络中采用全局和局部两个判别器,来评估图像的整体和局部的一致性.Yeh等[9]使用一个由上下文损失和感知损失组成的损失函数来搜索与破损图像最接近的编码,再通过生成模型推断缺失的内容.Liu 等[10]提出了使用部分卷积,通过掩膜的自动更新来获得理想的修复效果.Liao等[11]提出了基于边缘的上下文解码器,利用边缘信息实现破损图像的自动修复.Zeng等[12]基于U-Net结构,提出了金字塔上下文编码网络 PEN-Net,并采用注意力机制进行学习.Xiong等[13]采用一个由3个模块级联而成的网络,先生成边缘信息和粗略的图像内容,再得到最终结果.Yu等[14]提出了门控卷积和频谱归一化鉴别器,利用一个基于补丁的GAN损失函数来获得更高质量的修复效果.Wei等[15]提出了一种前景感知的图像修复系统,通过学习预测前景轮廓来修补缺失区域.Liu等[16]基于深度生成模型,提出了一种具有连贯语义注意层的图像修复方法.Yu等[17]提出了一种基于深度生成模型,通过引入上下文注意力机制,提高图像修复的效果.Xie等[18]引入了可学习的注意力图来用于图像修复,在卷积的过程中能够更有效地传播;进一步提高了图像的视觉质量.Nazeri等[19]提出一种基于边缘补全的图像修复方法,首先利用启发式的生成模型得到了缺失部分的边缘信息,随后将边缘信息作为图像缺失的先验部分和图像一起送入修复网络进行图像修复.
上述方法可有效利用图像的语义信息,提高了图像修复质量,但当图像缺失区域较大、图像内容比较丰富时,容易出现诸如图像模糊、纹理失真、边界伪影等问题.
1 生成对抗网络
生成对抗网络是一种深度学习模型,近年来,在复杂分布无监督学习上得到了广泛的应用,主要由生成器(generator)和判别器(discriminator)组成,如图1所示.
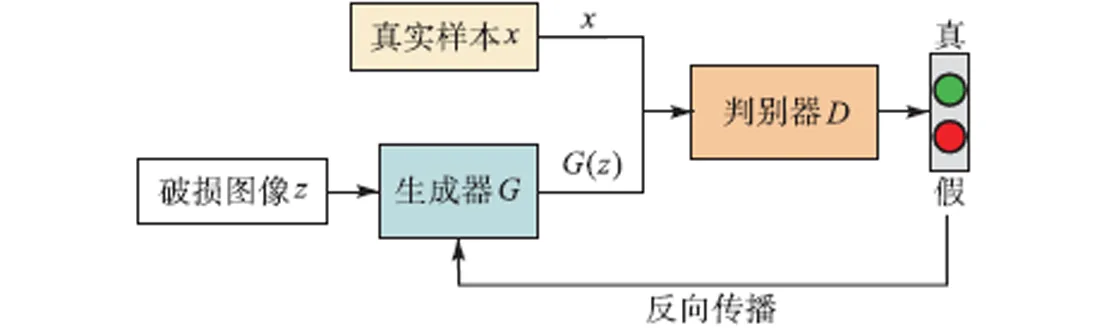
图1 生成对抗网络示意
在图像修复领域,生成器输入为破损图像,输出为修复图像.生成对抗网络的训练处于一种对抗博弈状态,可以不断提升生成器的学习样本分布、生成样本能力,以及判别器区分能力;当判别器无法区分真实样本和生成样本时,即输出最终结果.判别器网络最后一层使用sigmoid函数输出一个(0,1)范围内的概率值.网络采用交叉熵代价函数


网络生成图像与输入背景区域的关联程度会对输出结果产生一定的影响,传统GAN模型感受野较小,卷积核结构单一,对背景区域的特征学习能力不足,输出图像随机性较大;此外,由于网络模型深度不够,输出图像分辨率较低,容易产生细节模糊的 现象.
为解决上述问题,在传统生成对抗网络的基础上,提出了一种新的由粗到精的级联式生成对抗网络模型(C-GAN).具体作法是:在粗化生成网络中设计了一个并行卷积模块,由3层卷积通路和一个深层卷积通路并联组成,利用提出的特征提取模块来提高修复结果与背景区域的相关性.此外,在优化生成网络中提出了级联残差模块,通过对4个通道的双层卷积进行交叉级联,来丰富通道中的图像特征,以提高修复图像的分辨率.
2 C-GAN网络模型
本文C-GAN网络模型采用编码器和解码器架构,利用大量的训练样本来学习从破损图像到完整图像的映射关系,实现破损图像的自动修复.
2.1 粗化生成网络设计
粗化生成网络可以产生粗略的修复结果,本文粗化生成网络结构如图2所示,主要由提出的并行卷积模块、普通卷积层和空洞卷积层组成.其中,绿色模块为本文并行卷积模块.

图2 本文粗化生成网络结构
输入图像数据后,该网络可将图像分解为一些基本元素,如边缘、纹理和形状等.随着图像数据在网络中传播,这些元素会被重新组合,以产生不同的图像特征;同时,该网络会对图像内容进行预测,并根据需要进行调整.为保留更多的图像特征信息,卷积神经网络的深度至关重要,但网络层数的增加会导致梯度消失、训练进程慢等问题,为此,本文设计了一种并行卷积模块,如图3所示.

图3 本文并行卷积模块
输入图像并行经过一个深层卷积网络和一个浅层卷积网络.其中,深层卷积通路由14层卷积层组成,在第4、6、8层各加入一个特征提取模块(用紫色模块表示),最后与空洞卷积相结合,以提取更加丰富的图像特征.特征提取模块具体作法是:首先分别采用1×1和3×3两种大小的卷积核,对输入特征图进行卷积,采用两层并行卷积来替代一层卷积,再重新进行复合,以提取不同感受野的多样化特征信息;复合之后再对输入特征图做一次卷积,并将卷积结果与多尺度结果进行整合,实现了一个残差连接,可以防止网络退化,降维后得到最终的输出特征图.在深层卷积通路进行图像的降维与还原,可以补偿修复图像的细节信息.
并行卷积模块的浅层网络由3层卷积层构成,通过并行一个浅层网络,可以保留图像的主要内容,同时防止梯度消失的现象发生.特征提取模块将不同层次的特征在通道内进行拼接和融合,可以保留更多的图像特征,实现信息交互.上述过程可以表述为



图4 本文特征提取模块
图像修复需要利用图像的完整性信息对破损区域进行预测,因此,较大的感受野对修复结果至关重要.为了增强上、下文之间的联系,捕获更丰富的上、下文信息,同时不增加网络计算量,在网络中间层采用4层空洞卷积来扩大感受野的范围,膨胀系数分别为2、4、8、16,其中第2层空洞卷积与特征提取模块结合,以增加网络输出的表达能力;为了使得更多的图像信息能够在通道中传递,在深层卷积通路中对称加入两个跳跃链接,并将两段网络的输出进行了整合;经卷积神经网络学习后,得到最后的粗略输出.
网络选用破损图像及其二进制掩码图像作为输入,其中,0表示破损区域,1表示完好区域.训练时,随机选取矩形块作为破损区域.除最后一层外,每层卷积后采用Elu激活函数来保证网络训练的稳定性,加快学习速度,增强网络的非线性表达能力.
在粗化生成网络阶段,采用L1重构损失对网络进行训练,以规范修复过程中网络的行为,保持破损区域的修复结果与原图信息一致,结构更加合理.L1重构损失函数为
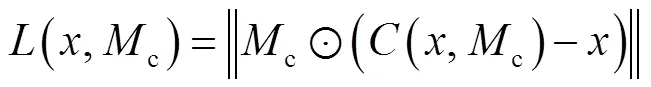
2.2 优化生成网络
优化生成网络以破损图像和粗化网络输出的粗略预测结果作为输入,可进一步获得更加精确的预测结果.为充分保留图像的纹理信息、提取更多的精细化的图像特征,在2层卷积后设计了级联残差模块,如图5所示.
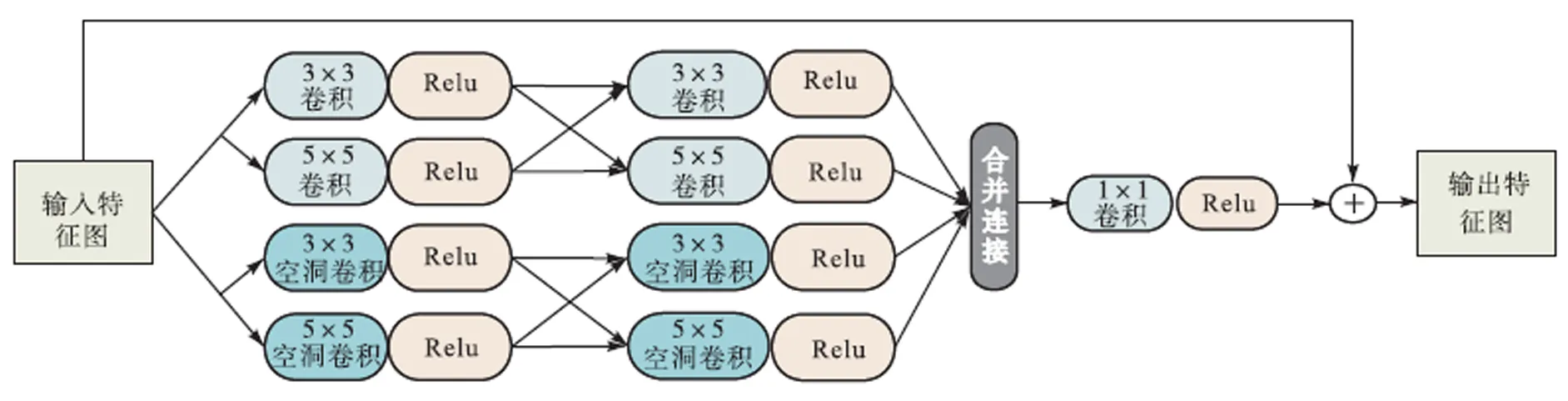
图5 本文级联残差模块
卷积层可以将图像分解成不同的特征,其中每一条神经元都可充当一组过滤器,不同的过滤器关注不同的特征,负责寻找图像中的不同部位和像素值,以找到最佳映射关系.
级联残差模块通过对卷积层进行组合级联,可以保证图片信息在网络中传递时不丢失.该模块由4个通道组成,对输入特征图像分别采取不同尺度的感受野,采用普通卷积和空洞卷积并行的方式来提取图像特征,再将两条支路交叉连接,以获得更加丰富的图像信息,增强网络的信息传播能力;最后采用1×1的卷积进行降维;将卷积结果与模块输入特征图的元素对应相加,进行局部残差学习,以缓解梯度消失问题,提高网络的表达能力,使得网络训练更加容易.此外,引入注意力机制[17],并采用2层空洞卷积,以扩大感受野.在第2层卷积层之后,加入一个跳跃连接,与经过第1次上采样之后的特征向量进行整合,以在通道内保留更多的图像信息.本文优化生成网络结构如图6所示.
优化生成网络也采用Elu作为激活函数,利用L1重构损失来实现缺失区域与上下文在整体结构上保持一致.此外,引入了对抗损失函数,以产生更加真实的图像信息.

图6 本文优化生成网络结构
对抗损失函数为
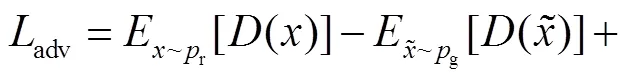

优化网络的总损失函数为
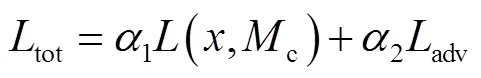
2.3 判别器网络
本文采用全局和局部两个判别器网络,其中,全局判别器用来关注整幅图像的全局特征,由6个卷积层和LeakyRelu层组成;分别采用步长为1和2的卷积块,最后通过全连接层输出判别结果.局部判别器只关注缺失区域的信息,其结构与全局判别器相似,通过增加输出通道数,可以获得更细致的图像特征.
3 实验结果
为了验证本文模型的有效性,分别在3个国际图像修复数据集上,与几种最新的深度学习修复模型算法进行了比较.
3.1 数据集选取
实验选取3个标准的国际图像修复数据集 CelebA、Places2、Pairs StreetView.为保证算法的实用性,实验过程中仅选用相关图像,而不采用其标签或注释.
CelebA是一个大规模人脸数据库;随机选取其中8万张图像进行训练,2000张用于测试.
Places2是一个场景图像数据集,取自400多个不同的场景环境;随机选取其中20万张图片进行训练,图像和掩码均设为256×256,2000张用于测试.
Pairs StreetView包含世界上几个城市的街景图片,总共有15000张图片,选取其中13000张图片进行训练,2000张用于测试.
3.2 实验结果及分析
选用python语言,计算机配置为:CPU处理器Core i9-9900k,主频3.60GHz,内存64.00GB,使用tensorflow实现算法.实验选取规则掩模,在原图像中随机删除矩形区域,破损区域最大尺寸为128×128.训练使用NVIDIA 2080Ti GPU,batchsize设为16,优化算法采用Adam,初始学习率设为0.0001.
3个数据集的中间结果可视化如图7~图9所示.在粗化网络中,由于没有判别器进行判断和纠正,只能生成大体的图像结构,生成部分分辨率较低,图像较为模糊;粗化网络的输出经过优化网络得到最终的输出,从图中可以看出,由于对图像特征进行了进一步的提取,同时加入两个判别器网络进行对抗博弈,可以生成完整的图像结构和更加丰富的纹理信息,图像更加清晰,视觉效果更为理想.

图7 CelebA中间结果可视化

图8 Places2中间结果可视化

图9 Paris StreetView中间结果可视化
为了证明本文提出的各个模块的有效性,进行了消融实验,修复结果如图10~图12所示,其中,GL算法用单一生成网络模型,CA算法使用粗化和优化两个生成模块,CA+FD代表仅在粗化网络中加入特征提取模块,CA+RM代表仅在优化网络中加入级联残差模块.从图中可以看出:CA算法由于比GL结构更加合理,修复效果有所提升,但是依旧存在模糊扭曲等问题;CA+FD在一定程度上提升了图像纹理特征,证明了特征提取模块的有效性;CA+RM的修复结果更加真实,表明了增加级联残差模块的有效性;而同时加入两个模块后(本文模型),可以得到更加合理的结构和更加清晰的纹理信息,修复结果更加真实可信.
此外,分别采取本文模型及5种最新深度学习修复模型算法:globally and locally(GL)[8],contextual attention(CA)[17],gated convolution(GC)[14],learnable bidirectional attention maps(LBAM)[18]和edge connect(EC)[19]进行图像修复,结果如图13~图15所示.从图中可以看出,GL方法修复图像比较模糊,不能产生复杂的纹理,且存在较严重的局部失真情况,如图13第1行中,眼睛部位比较模糊,且存在明显的局部色差.CA方法的修复效果有所提高,细化了纹理信息,但仍然存在修复边界明显和纹理细节损失严重等问题;GC算法进一步提高了修复效果,由于GC算法在粗化网络中采用单一的网络结构,其使用的门控卷积、频谱归一化判别器等,主要针对不规则的自由掩模,对于规则的矩形掩模,容易产生结构不合理、边界缺失等问题;LBAM算法虽然能够产生平滑的纹理和正确的结构信息,但是仍然存在局部色差和纹理模糊等问题;EC算法提高了修复质量,修复内容真实合理,但在Pairs StreetView数据集上产生了纹理模糊现象,且存在明显的边界伪影;本文模型在粗化网络中增加了特征提取模块,同时采用并行卷积,能够更好地学习图像结构,更全面地关注图像上、下文信息;在优化网络中加入了级联残差模块,可以提取更加丰富的图像特征.因此细化了纹理结构,能够获得更加丰富的纹理特征,修复区域基本没有边界伪影和局部色差,结构一致性较好,视觉效果最佳,证明了本文算法的有效性.在CelebA数据集上,本文算法虽然存在瑕疵,但较之其他方法均有提升,有效修复了人物面部和背景区域纹理信息,局部色差问题也得到了明显改善,修复效果更加自然.
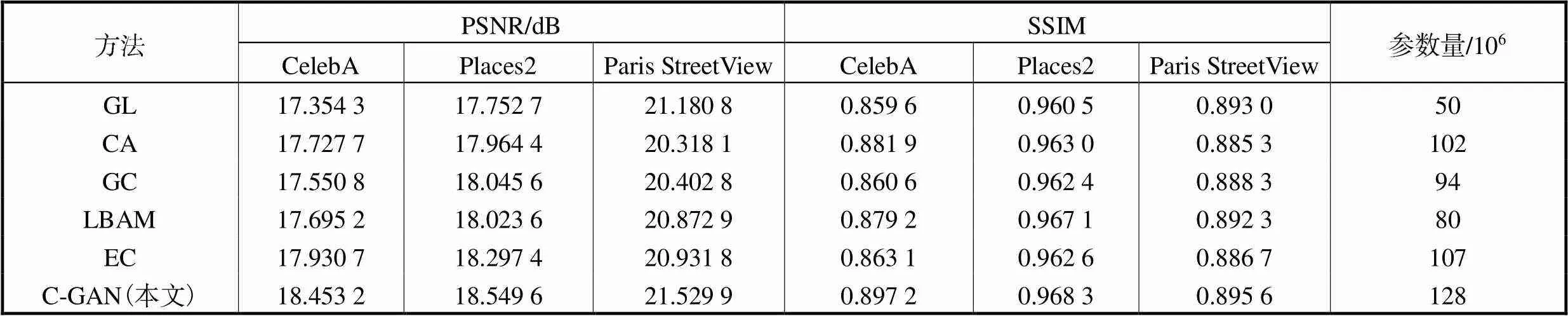
为了对算法性能进行量化评估,随机选取200幅图像,分别利用不同模型算法进行修复,结果如表1所示.采用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为图像修复性能度量指标.其中,PSNR基于修复结果图像和真实图像之间的偏差来计算相似度,值越大,代表修复效果越好;SSIM计算修复结果图像和真实图像亮度、对比度和结构之间的差值,从3个方面度量图像相似性,取值范围[0,1],值越大,代表图像相似性越高.从表中可以看出,本文方法在客观指标量化性能上明显优于其他方法,修复结果更加准确.此外,为了提取更多的特征信息,本文算法增加了部分卷积操作,因此,网络参数量略有增加,但本文算法准确率最高,获得了最佳的修复效果.

图10 CelebA消融实验结果

图11 Places2消融实验结果

图12 Paris StreetView消融实验结果

图13 CelebA数据集修复结果

图14 Places2数据集修复结果
表1 不同算法性能对比
Tab.1 Comparison of the performances of the different inpainting methods
为了进一步验证本文算法的普适性,分别在3个数据集上对不规则形状缺失的图像进行了修复,实验结果如图16~图18所示,从图中可以看出,本文算法可以对不规则的缺失图像进行修复,对于缺失区域较小的不规则区域,可以实现较好的恢复效果,但当破损区域较大时容易出现模糊等的现象,这是由于本文算法采用的全卷积神经网络更适合于规则破损图像的修复;同时,在网络训练时,也选用了规则矩形块破损区域.综上所述,本文算法在规则区域和不规则区域都可以完成图像修复,但对于规则破损区域效果更好.
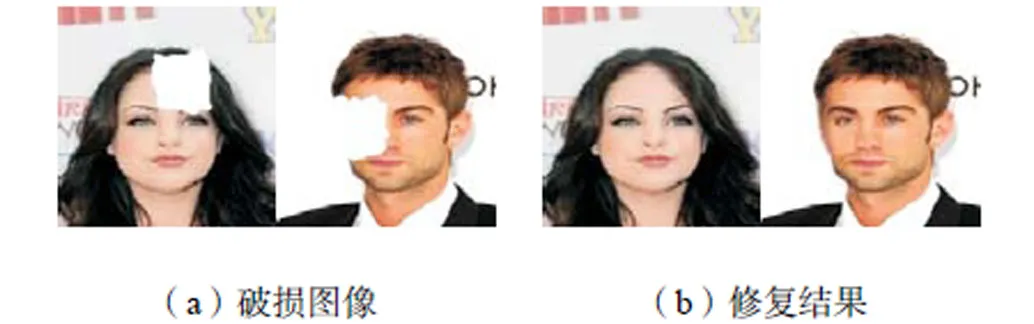
图16 CelebA不规则缺失修复结果

图17 Places2不规则缺失修复结果

图18 Paris StreetView不规则缺失修复结果
4 结 语
本文提出了一种基于生成对抗网络的图像修复模型C-GAN,分两个阶段实现图像修复,在粗化生成网络中设计了一种并行卷积模块,并提出了一种特征提取模块来提高网络的学习能力;在优化生成网络中提出了级联残差模块,通过对4个通道的双层卷积进行交叉级联,实现图像的精细修复.
在3个国际标准数据集上的实验结果表明,与近年来经典深度学习修复模型方法相比,本文模型能获得更有效的纹理细节信息,对于复杂结构和纹理的修复效果更加真实,准确度更高.
[1] Bertalmio M,Sapiro G,Caselles V. Image inpainting[C]//Proceedings of ACM SIGGRAPH 2000. New York,USA,2000:417-424.
[2] Criminisi A,Perez P,Toyama K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing,2004,13 (9):1200-1212.
[3] 何 凯,牛俊慧,沈成南,等. 基于SSIM的自适应样本块图像修复算法[J]. 天津大学学报:自然科学与工程技术版,2018,51(7):763-767.
He Kai,Niu Junhui,Shen Chengnan,et al. Image inpainting algorithm with adaptive patch using SSIM[J]. Journal of Tianjin University:Science and Technology,2018,51(7):763-767(in Chinese).
[4] Zeiler M D,Fergus R. Visualizing and understanding convolutional networks[C]//Proceedings of the European Conference on Computer Vision. Zurich,Switzerland,2014:818-833.
[5] Goodfellow I,Pouget-Abadie J,Mirza M,et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. Montréal,Canada,2014:2672-2680.
[6] Ronneberger O,Fischer P,Brox T. U-net:Convolu-tional networks for biomedical image segmentation [C]// Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich,Germany,2015:234-241.
[7] Pathak D,Krahenbuhl P,Donahue J,et al. Context en-coders:Feature learning by inpainting[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:2536-2544.
[8] Iizuka S,Simo-Serra E,Ishikawa H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics,2017,36(4):1-14.
[9] Yeh R A,Chen C,Yian Lim T,et al. Semantic image inpainting with deep generative models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii,USA,2017:5485-5493.
[10] Liu G,Reda F A,Shih K J,et al. Image inpainting for irregular holes using partial convolutions[C]// Proceedings of the European Conference on Computer Vision. Munich,Germany,2018:85-100.
[11] Liao L,Hu R,Xiao J,et al. Edge-aware context encoder for image inpainting[C]//Proceedings of the International Conference on Acoustics,Speech and Signal Processing. Calgary,Alberta,Canada,2018:3156-3160.
[12] Zeng Y,Fu J,Chao H,et al. Learning pyramid-context encoder network for high-quality image inpainting[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. California,USA,2019:1486-1494.
[13] Xiong W,Yu J,Lin Z,et al. Foreground-aware image inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. California,USA,2019:5840-5848.
[14] Yu J,Lin Z,Yang J,et al. Free-form image inpainting with gated convolution[C]//Proceedings of the IEEE International Conference on Computer Vision. Califor-nia,USA,2019:4471-4480.
[15] Wei X,Yu J,Lin Z,et al. Foreground-aware image inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. California,USA,2019:5833-5841.
[16] Liu H,Jiang B,Xiao Y,et al. Coherent semantic attention for image inpainting[C]//Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:4169-4178.
[17] Yu J,Lin Z,Yang J,et al. Generative image inpainting with contextual attention[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:5505-5514.
[18] Xie C,Liu S,Li C,et al. Image inpainting with learnable bidirectional attention maps[C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:8858-8867.
[19] Nazeri K,Ng E,Joseph T,et al. EdgeConnect:Structure guided image inpainting using edge prediction[C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:3265-3274.
Image Inpainting Model Using Cascaded Generative Adversarial Network
He Kai,Liu Kun,Li Chen,Ma Xitao
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
To solve the problem of image blur or texture distortion in the existing algorithms,this study proposes a new image inpainting model,called the cascaded generative adversarial networks(C-GAN). The model is cascaded by the coarsening and refinement generation of the sub-networks. In the coarsening generation network,a parallel convolution module is designed to solve the gradient disappearance problem of deep network. It is composed of a three-layer convolution path and a deep one in parallel. In the deep convolution path,a feature extraction module is proposed to achieve a richer image information using convolution kernels of different sizes. Additionally,a cascaded residual module is proposed in the refinement generation network to effectively enhance the feature reuse by cross-cascading the double-layer convolution with four channels. Besides,a module input feature map is added to the corresponding elements of the convolution result to improve the expressive ability of the network. Simultaneously,employment of the dilated convolution can fully make use of the context information and retain more rock-bottom image details,which is helpful to achieve a fine restoration. Simulation results demonstrate that the proposed algorithm can achieve better visual effects. For dataset 1,2,and 3,the peak signal-to-noise ratio(PSNR)values are 18.4532,18.5496,and 21.5299 and the structural similarity(SSIM)values are 0.8972,0.9683,and 0.8956 respectively. Highest quantification results are achieved using the comparison algorithm,implying that this algorithm can automatically inpaint some complex structures and texture information.
image inpainting;generative adversarial network;feature extraction module;residual module
TP391.41
A
0493-2137(2021)09-0917-08
10.11784/tdxbz202009074
2020-09-26;
2020-12-21.
何 凯(1972— ),男,博士,副教授.
何 凯,hekai@tju.edu.cn.
天津市自然科学基金资助项目(14JCQNJC01500).
Supported by the Natural Science Foundation of Tianjin,China(No. 14JCQNJC01500).
(责任编辑:孙立华)
