基于雷达测量的用于炮位侦察的Transformer网络
2021-05-27蔡鑫鹏贾正望刘华军
蔡鑫鹏,贾正望,刘华军
(1.南京理工大学 计算机科学与工程学院,江苏 南京 210014;2.中国电子科技集团公司第二十八研究所,江苏 南京 210007)
侦察雷达通过片段的观测数据可以预测弹丸的发射点(炮位)和落点,但雷达数据具有噪声高、数据量小、非线性和不完整等特点,使得高精度炮位外推难度较大,且在炮弹低射角时,测量误差加大,观测弧段更短,炮位预测面临极大的挑战。传统方法常利用空气动力学模型及优化估计算法,如扩展卡尔曼滤波算法(Extended Kalman filter,EKF)[1],对雷达测量噪声进行滤波来估计弹丸飞行的状态,然后基于动力学模型和数值算法,如龙格-库塔法[2]来外推发射点[3]。它依赖不同的发射条件、复杂的动力学模型[4]和先验假设,且受随机风、大气摄动等不易建模的因素影响,难以满足多变环境下发射点的外推需求。
近年来,深度学习算法建模复杂物理系统的能力越来越强[5],并且数据驱动特性使其不依赖预先建立的动力学模型,因此广泛应用于轨迹预测方向,比如行人轨迹预测[6]、车辆[7]或飞机[8]等交通工具的航迹预测,以及某些运动场景中的各种球类轨迹预测[9]等方向。但目前对雷达数据[10]或者声呐数据等数据源的研究较少。当前基于深度学习的轨迹预测算法大都是基于循环网络模型(Recurrent neural network,RNN)[11]。传统的RNN随着递归深度增加,会出现梯度弥散和梯度爆炸等问题[12],难以捕捉长时间序列之间的关联。长短期记忆(Long short-term memory,LSTM)网络对RNN进行了改进,使其对长序列的记忆能力有较大改善[13],但是无法预测不完整的轨迹。
注意力机制[14]的提出有效改善了循环神经网络模型对长时间序列的记忆能力。该机制通过对不同时间序列的依赖关系进行建模,进而消除输入输出之间距离的影响。该机制通常和LSTM构建的编码器-解码器架构[15]一起使用,因此依然无法预测不完整的轨迹[16]。
Google团队最新提出的Transformer网络[17]是当前自然语言处理领域最先进的技术,它摒弃了循环神经网络模型,完全依赖注意力机制来构建编码器-解码器结构。其改进版基于Transformer的双向编码器表示网络(Bidirectional encoder representations from Transformers,BERT)[18]以及生成式预训练Transformer模型-3(Generative pre-trained Transformers,GPT-3)[19]等模型也都基于Transformer模型构建,并在机器翻译[20]、文本分类[21]、问题回答[22]等任务中取得了最佳结果,目前Transformer网络的跨领域应用成为了当前研究热点之一。
本文提出了一种基于时间戳编码的方法,将其应用于Transformer网络中,使网络能够对雷达轨迹进行建模,并解决高精度炮位侦察问题。本文基于标准的炮弹飞行动力学摄动建模[23],以不同发射点、出膛速度、射角、射向以及不同雷达观测位置和测量精度生成了一个拥有4万多条记录的炮弹轨迹数据集,并将传统炮位侦察方法EKF和LSTM网络[24]与改进的Transformer网络在该数据集上进行对照测试。
1 Transformer模型
Transformer模型是一个经典的自然语言处理模型,如图1所示。Transformer模型不同于传统深度神经网络模型,它没有卷积操作和循环结构,完全利用自注意力机制学习序列信息,非常适合序列建模。用于机器翻译的Transformer模型,首先对输入单词进行输入嵌入和位置编码,然后利用编码器对编码序列进行学习,最后利用自回归机制对要解码的序列循环解码,并输出翻译过的语言序列,整个过程如图1所示。Transformer模型的处理单元包含了编码器和解码器两个模块,模块内部由注意力层、全连接层、连接至前一层的残差连接和归一化层3个部分组成。其中注意力层主要用于特征抽取,全连接层提供非线性变换,而残差连接和归一化层可以防止网络发生梯度爆炸。

图1 图为Transformer网络模型架构
对于机器翻译任务而言,原始输入为句子序列,因此需要量化为可计算的矩阵,这个过程就是图中的输入嵌入(Input embedding)。Transformer主要通过自注意力机制学习输入语言编码的内部特征。图 1中每个注意力层中分别有两个维度为dk的序列query和keys,以及一个维度为dv的序列values,以下分别用Q、K、V代替。通过计算Q和K的点积,并除以一个放缩系数,可以得到Q和K对应的权重信息。使用softmax函数对权重归一化并利用该权重对V进行加权求和,可以得到最终注意力值。整个过程可以表示为
(1)
传统的循环神经网络模型可以利用循环网络机制每次处理一个输入,并以此区分输入序列的先后位置。而Transformer网络由于完全利用注意力机制进行学习,因此需要添加额外的位置编码信息以区分输入嵌入的不同位置,这个过程对应图1中的位置编码(Positional encoding)。该编码过程采用一个频率变化的正余弦函数生成固定的编码信息[17]
PE(pos,2i)=sin(pos/100002i/dmodel)
(2)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
(3)
式中:pos为输入编码的位置,是一个整数,每一个位置的编码都是一个长度为dmodel的向量,i表示该向量中的维度,由于每个单词经过输入嵌入后是一个二维矩阵,因此该位置编码是一个二维矩阵的位置编码。然后将输入嵌入和位置编码相加,并送入编码器和解码器中进行学习和解码。
解码器模块包含一个编码器-解码器注意力层,并且第一个自注意力机制层是带有掩膜的自注意力(Masked self-attention)机制。其中编码器将学习和编码的信息通过编码器-解码器注意力层发送给解码器,为解码器提供记忆能力。该注意力层是一个多头注意力机制层,通过计算多个注意力机制头可以让网络关注不同子空间的信息,可以在一定程度上预防过拟合。掩膜自注意力机制可以将要解码的句子序列中待预测的单词屏蔽掉,然后让网络对其进行预测。Transformer每预测出句子中的一个单词,就将预测出的信息更新至解码器的输入,循环进行下一步的自回归预测过程,直至预测出整个完整的句子。
2 轨迹位置编码的Transformer模型
Transformer模型在语言处理领域取得了最好的结果[17],但将其应用到炮位侦察问题中存在以下问题:(1)输入Transformer网络的雷达测量数据已经是量化过的特征,无需语言处理的输入嵌入环节;(2)直接将发射点坐标作为真值放入模型中训练,仅可预测该发射点的轨迹,泛化能力会比较差;(3)原位置编码方法无法编码雷达三维轨迹坐标及时间戳信息;(4)自回归机制使用t时刻带有误差的预测值来预测t+1时刻的值,会导致误差累积。机器翻译问题使用交叉熵函数作为损失函数,误差累积效应较小,但对炮位外推问题影响较大;(5)炮位外推需输出炮位坐标,机器翻译领域使用的交叉熵损失函数无法直接应用。
针对直接预测发射点带来的泛化能力差的问题,本文使用轨迹的相对位置作为输入,网络输出雷达观测到的第一个轨迹点和发射点之间的相对位置。其中时刻t的相对位置为t时刻的位置与t-1时刻位置的差值
τt=(xt-xt-1)/Δt
(4)
然后,使用Z-score[25]方法对输入数据进行归一化
y=(x-μ)/σ
(5)
式中:x、y分别代表输入归一化前和归一化后的数据,μ为输入数据的均值,σ为输入数据的方差。同时去掉了语言处理模型中的自回归机制,以减少外推的累积误差。
针对雷达探测轨迹具有的时标属性,本文提出了一种正弦调制的时间戳编码机制。时间戳编码pt定义如下
(6)
(7)
式中:t为浮点数表示的每个轨迹点当前的时间戳,该机制允许雷达数据非等间隔采样;D表示编码深度,最终生成的时间戳编码是一个维度为(3,D)的向量,一般取经验值D=512;d代表向量维度,雷达测量数据默认d=3;参数C表示网络最多可处理的序列长度,针对炮位侦察问题,雷达探测的弹丸轨迹都是短弧段,因此C=100。图2展示了对一个长度为50的轨迹进行时间戳编码的结果,编码的深度为512,图中每一行代表着一个轨迹点的位置编码矩阵,从图中可以看出正余弦交替的周期变化使得每一个点的位置编码矩阵都不相同。

图2 对一个长度为50的序列进行时间戳编码,编码深度为512
LSTM每个时间步处理一个轨迹点,处理两个不同位置的轨迹点所需要的操作次数随着时间步增加,这导致LSTM对于长距离轨迹的学习能力下降。同时,按照时间步处理时序序列的方式,网络无法通过并行计算加速训练过程。得益于注意力机制,Transformer模型计算两个不同特征之间的关系按式(1)所示,整个计算过程的时间复杂度为常数[26],并且可以充分利用并行计算加速训练过程,因此Transformer在训练时的学习速度比LSTM更快。
针对炮位侦察问题,本文提出了基于时间戳编码的Transformer炮位侦察网络,如图3所示。网络设置多头注意力机制中头的个数为16,编码层的深度为512,Transformer层数为12。使用均方误差(Mean square error,MSE)作为训练的损失函数,计算公式如下

图3 基于时间戳编码的Transformer炮位侦察网络,其中GT为待预测的炮位位置
(8)

3 实验环境及数据集
3.1 实验环境
本实验所用的网络模型借助了灵活易用的深度学习框架Pytorch实现,其版本为1.6.0,并使用了一块NVIDIA TITAN Xp的GPU进行训练。
3.2 雷达仿真数据集
实验所用的雷达侦测轨迹数据集包含41 217条轨迹数据,每条轨迹的数据率为0.05 s/点。图4是一条低射角的炮弹轨迹示意图,侦察雷达观测到了部分轨迹,并据此外推发射点位置。本实验中使用一个基于动力学摄动模型的软件生成炮弹轨迹,建模时考虑了不同的地理因素,如发射点位置与雷达站位置,发射时的初速度、射角、射向,以及环境因素(风向、风速等)等,然后生成带有噪声雷达观测数据集。图5展示出了该轨迹数据集中一部分发射点的分布情况。其中轨迹生成软件采用的动力学建模公式如下
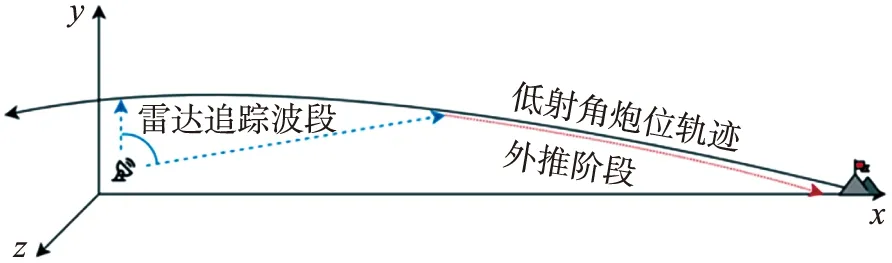
图4 低射角炮弹轨迹及炮位外推示意图

图5 不同发射点的炮弹轨迹及雷达站的位置分布
(9)
式中:vx、vy、vz为弹丸速度在地面坐标系中的分量;wx、wz为风速在地面坐标系中的分量;vr为弹丸相对空气的飞行速度,其对应关系见式(10);H(y)为气重函数,计算方式见式(11),其中ρ0为地面空气密度;G(vr,cs)为阻力定律;t为飞行时间;c为弹道系数。
(10)
(11)
由于生成的轨迹数据参照系是以雷达站为原点的极坐标系,在训练时不易计算误差,因此实验前将其转换到了雷达站为原点的空间直角坐标系,转换公式为

(12)
式中:R、A、E分别代表距离、方位角和俯仰角;x、y、z为空间直角坐标系的坐标。
实验前首先对数据集中每条轨迹的1/6~5/6部分采样,该区间对应雷达正常工作时可观测到的数据区段,然后使用如下方法生成不同条件的数据并执行对应的测试。
(1)向生成的轨迹上添加不同程度的噪声,以测试不同算法在不同噪声数据上的表现;
(2)对轨迹进行非等间隔采样,以比较不同方法在非等间隔采样数据上的表现;
(3)在等间距采样的数据集上随机丢弃一定数量采样点,以测试Transformer网络的不完整轨迹外推能力。
3.3 超参数设置以及检验指标
3.3.1 模型超参数设置
本文中对比试验的LSTM模型是由5层LSTM堆叠而成,其后有5层全连接网络,激活函数为线性整流函数(Rectified linear unit,ReLU),整个网络的损失函数为MSE。为防止过拟合,实验时设置整个网络的参数随机丢失率(dropout)为0.1。Transformer网络中,设置训练窗口大小为256,初始学习率为1×10-3,在热身训练10个轮次后进行衰减,衰减率为0.95,衰减周期为50。使用的优化器为Adam[27],dropout为0.03,训练周期为500。
3.3.2 性能检验指标
计算炮弹预测误差的指标为圆概率误差(Circular error probable,CEP),通常用于衡量炮弹的命中精度。相同条件下射向同一目标的轨迹中,以目标为圆心包含50%弹着点的圆的半径为该炮弹的圆概率误差。半径越小,命中精度越高。本实验中所用的CEP定义如下
(13)
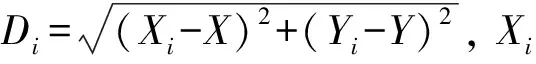
评估炮弹外推性能时,将外推的CEP误差除以炮弹射程L作为外推算法的衡量指标。
4 实验与分析
本节将传统的EKF外推方法以及LSTM方法与Transformer网络在仿真数据集上进行对比。如3.2节所述,实验中使用了不同的方法产生了不同类型的仿真轨迹。
在不同俯仰角数据上进行外推测试。在没有添加误差的雷达数据集上进行模型训练,其中Transformer和LSTM的损失变化及对应的CEP性能变化分别如图6和图7所示。

图6 训练过程中不同算法的损失变化情况

图7 训练过程中不同算法的圆概率误差与射程比值变化情况
从图6和图7可以看出,LSTM模型和Transformer模型的误差都能有效收敛,并且这两种方法外推出的发射点结果都较为理想。但是从图7中可以看出Transformer要比LSTM 收敛更快,这意味着Transformer可以比LSTM更快地学习到输入轨迹的信息。得益于注意力机制和位置嵌入,Transformer可以在确定的操作数内求出任意两个点迹之间的关系,并且不需要LSTM“unroll”的过程。同时,Transformer的CEP/L的变化幅度较小,而LSTM的CEP/L变化幅度较大,这表明前者的外推结果更加稳定。
为了验证不同模型在不同俯仰角下外推的性能,实验时将测试数据按照角度分组,最后测试结果见表1。从表1可以看出相对于LSTM和传统方法,在大批量数据的条件下,Transformer性能优于其他两种方法,并且在低俯仰角(<20°)的数据上表现较好。从表中也可以看出,在无噪声时LSTM方法优于传统EKF方法。

表1 不同射角的外推性能
Transformer和LSTM在结构上差别较大。前者将编码输出与解码序列分离,并使用注意力机制关注输入序列中有联系的部分,而后者将所有的状态都编码到隐藏层状态中,并且每个处理单元在计算时要控制是否记住或遗忘已经计算的内容。这一点有助于解释为什么在长序列预测任务Transformer表现更佳。
在不同噪声数据上进行外推测试。雷达在工作时,所采集到的点具有一定的误差。通过设置不同的噪声方差E来生成不同噪声的数据,以测试不同模型抗噪声干扰的能力,实验结果见表2。
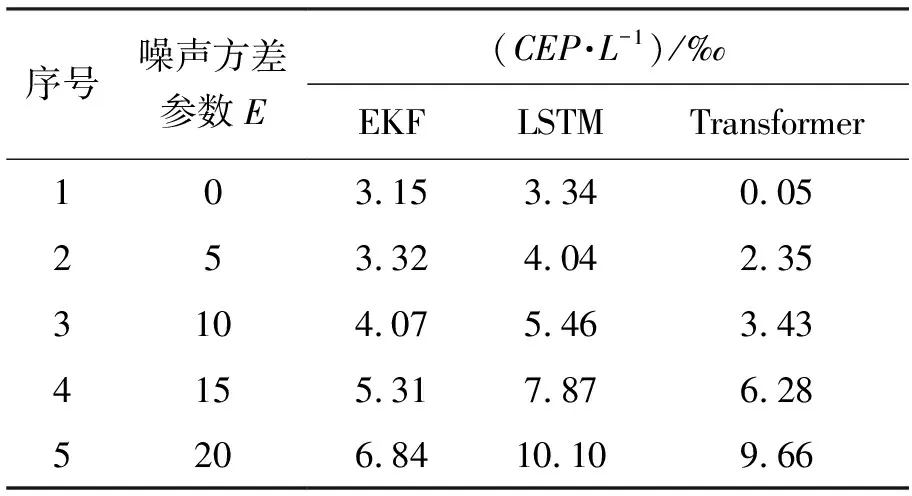
表2 不同测量误差的外推性能
从表2可以看出,这3种方法的外推误差与噪声大小成正比,但是在噪声较大时LSTM模型和Transformer模型外推误差增加较多。这说明在高噪声的情况下,这两个方法都将噪声当做数据固有的特征学习,而传统的EKF方法由于事先建立了数学模型,并通过滤波等手段,可以显著减少噪声带来的影响。
在非等间距采样数据上的外推测试。为了更贴近雷达实际工作场景,对不同模型在非等间距采样的数据进行测试。采样时,自初始点开始每次采样的间隔为1~30,总采样点数为15,实验结果如表3所示。

表3 在非等间隔采样条件下的外推性能
对于传统EKF方法来说,由于事先建立了轨迹的数学模型,因此受随机采样的影响较小。Transformer学习的是输入编码之间的关系,在数据量较大的条件下受到的影响较小。而LSTM由于需要“unroll”过程,在这个过程中将非等间距的采样结果当做了特征来学习,因此外推结果较差。
在不完整轨迹上的外推测试。侦察雷达在工作时可能出现某些目标点无法成功捕捉的情况,导致观测到的数据不完整。Transformer模型可以预测不完整的轨迹数据,即输入的数据维度不必满足模型训练时输入维度的限制,这是循环网络模型无法做到的。本实验中使用完整无误差的数据训练,在生成测试数据时,随机丢弃同一轨迹中指定数目的采样点,结果如表4所示。

表4 不完整轨迹的外推性能
结果表明,即使输入的轨迹不完整,Transformer依然能够进行外推。随着缺失的点数增多,Transformer的外推误差会逐渐增加。对于LSTM而言,如果输入数据存在缺失信息,那么LSTM就无法对该轨迹进行外推,此时只能使用线性插值的方法对轨迹进行填充。Transformer不需要对缺失的数据进行填充;相反,得益于位置编码信息,网络可以通过剩余的预测样本的位置编码信息知道何时可以观察到缺失的轨迹点,因此在不完整轨迹上也可以外推出较理想的效果。
5 结论
本文改进Transformer网络用于解决高精度炮位侦察问题。雷达探测轨迹输入训练后的Transformer网络,可直接输出炮位坐标。
在大规模模拟数据环境下,将传统炮位侦察方法,如EKF方法,LSTM模型算法与Transformer炮位侦察网络分别在数据集上进行训练和测试。训练时,Transformer比LSTM的收敛速度更快。相对于LSTM类的深度学习算法,Transformer的外推的圆概率误差更小,精度更高。在高噪声、不完整轨迹、非等间隔采样等条件下,Transformer也具备更高的外推精度。
