一种可应用于联盟链的拜占庭容错混合共识机制❋
2021-05-25袁晓伟魏志强翟翌立杜丙瑜朱文印王金龙
周 炜, 袁晓伟, 魏志强, 翟翌立, 王 超, 杜丙瑜, 朱文印, 王金龙
(1.青岛理工大学信息与控制工程学院, 山东 青岛 266100; 2.海尔集团技术研发中心, 山东 青岛 266100;3.中国海洋大学信息科学与工程学院, 山东 青岛 266100)
伴随着区块链的发展,截至目前块链大致可以分为三类:公有链、联盟链、私有链。而不同类型的链会有不同的共识,公有链共识大致可以分为三类:基于算力竞争记账权的POW共识[1]、基于权益证明的POS共识[2]、基于POW共识和POS共识的改进,例如Casper FFG共识[3]、POA共识[4]、POSV共识[5]。联盟链共识大致分为两类:一类是非拜占庭容错共识,这类共识不考虑节点采取恶意攻击行为,只考虑崩溃节点不工作不回应的情况,例如PAXOS共识[6]、RAFT共识[7]。另一类是拜占庭容错共识,这类共识会考虑超时错误、回应错误信息、节点串通攻击等情况,例如PBFT共识。私有链与以上两种链不同,它大部分被使用于组织与集体内部不对外公开,不过共识大部分采用PBFT、PAXOS、RAFT等共识。
目前无论是社会结构还是网络服务结构都是由几个大型组织作为中心,完全去中心化显然不符合目前发展阶段,多个组织合作的联盟链比较符合当下的发展。目前一部分联盟链使用非拜占庭容错共识。非拜占庭共识的优点是交易吞吐量大、延迟低。但是非拜占庭容错共识无法防止节点对系统的恶意攻击,考虑到联盟链是多个组织参与,因此这类共识在实际场景中安全性很低,没有实用价值。考虑到联盟链系统安全性问题,本文针对拜占庭容错算法进行研究,选取目前应用最普遍的PBFT共识[8]。PBFT是一种基于部分异步网络模型的拜占庭容错算法,它通过三阶段提交过程保证了节点之间的一致性,通过节点之间相互传递签名消息保证安全性,通过超时检测和主节点切换保证活性。一致性保证了节点之间确认的消息是一样的,安全性保证了节点可以判断消息是否正确,活性保证了系统不会出现一直等待不工作的状况。
虽然拜占庭容错PBFT共识目前发展的比较成熟,但目前还存在一些问题。首先,虽然节点两两之间相互通信可以保证节点判断消息的正确性,但造成通信复杂度过高((O(n2))。由于消息确认需要两次且随着节点数量变多,通信复杂度会增长过快,进而影响系统可扩展性。其次,虽然PBFT共识采用主从模式保证了交易顺序的一致性,但是导致了通信会集中于主节点,引起主节点通信压力过大。最后,PBFT共识失败率高。采用主节点轮次交换的方式,而在3f+1个节点中,如果有f个拜占庭节点,轮换到错误节点的概率接近1/3,共识失败率较高,会导致主节点切换频繁,共识效率下降。
随着现代计算机和互联网的发展,数据规模不断增长,处理的数据量越来越大,单一节点处 理数据和存储数据压力越来越大,分布式系统在提高数据处理效率同时保证了系统可靠性,缓解节点存储压力。不过分布式系统在多节点合作协调一致性方面存在技术挑战,因此分布式系统中如何保证共识是个经典的技术问题。
共识协议从大的方面可分为自比特币诞生以来产生的POW等中本聪共识协议和拜占庭容错(BFT)类共识协议这两大类协议。其中,在计算机科学的分布式系统研究领域,近年来,越来越多的联盟链平台大部分集中在对BFT类共识协议的研究。由此本文对BFT类协议进行了综述性概览分析,并从改进思路上将现有BFT类共识协议分为三大类:针对无拜占庭错误场景优化的协议、针对拜占庭错误场景优化的协议以及为公链应用而优化的协议。
针对无拜占庭错误场景进行优化又分为基于协约方法的优化,例如Chain协议[9]、Ring协议[10]、BFT-SMaRt协议[11];基于Quorum方法的优化,例如Q/U协议(Query/Update)[12]、HQ协议(Hybrid Quorum)[13]、Quorum协议[14];基于Speculation方法的优化,例如Zyzzyva协议[15]、Zeno协议[16]、ZZ协议[17];基于客户端方法的优化,例如OBFT(Obfuscated BFT)协议[18];基于可信组件方法的优化,例如CheapBFT协议[19];基于拜占庭锁方法的优化,例如Zzyzx协议[20];基于分离一致性与执行请求方法的优化,例如ODRC协议[21]。
上面介绍的一类协议均是针对没有错误的场景对BFT协议进行简化而设计,因此当遇到拜占庭错误时,这类协议的性能一般都会下降比较多,甚至很难保证系统活性。而另一类针对有错误的场景对BFT协议的改进目的是为了有效对拜占庭行为(甚至是一些罕见的行为)进行容错,降低系统在有无拜占庭错误这两种场景下的表现差异。其中比较典型的协议,例如Aardvark协议[22]、Prime协议[23]、Spinning协议[24]、Redundant-BFT协议[25]。
传统PBFT及类似协议,其自身的特性导致应用场景有较多限制,例如消息复杂度随节点数成平方级别上升、主节点容易成为系统性能瓶颈、节点列表需要提前固定且节点间相互已知。所以在分布式账本系统中,更多应用于联盟链或私有链场景中。为了适应公有链场景中的大规模扩展需求,有不少项目进行了有益尝试,具体方式可主要包括与公链共识结合以及基于密码学机制等两大类方式。与公链共识结合的典型协议,例如DPOS+BFT协议[26]、DBFT协议[27]、Tendermint BFT协议[28]、FBA协议[29];基于密码学优化的典型协议,例如基于聚合签名的Zilliqa[30]、基于可验证随机函数的VBFT协议[31]、基于门限签名的HoneyBadger BFT[32]。
通过以上分析发现,区块链共识算法及其变种都集中在PBFT算法上,所以本文选取了部分同步网络模型的PBFT算法作为研究对象。
PBFT算法是一种状态机副本复制算法,所有副本在视图编号v的轮转中运行,视图是连续编号的整数,在同一视图编号下,节点角色被分为客户端、主节点和从节点。客户端是请求的发送方,主节点负责接收客户端的请求,并且按照顺序对请求进行排序,从节点主要是负责检查从主节点接收到的请求,并且通过超时机制检测主节点是否宕机,当发生出节点宕机时,触发视图切换机制。
结合PBFT共识存在拜占庭节点情况下,共识失败率较高,节点数量多主节点通信压力过大,整体共识通信复杂度增长过快的问题,本文提出了一种分组混合共识机制,首先通过概率分组算法找出共识概率达成最高的分组方式,然后所有节点基于可验证随机函数VRF[31]通过两轮消息投票方式确认分组信息,接下来分组内部开始进行拜占庭容错chain-raft共识,按照下文中设计的算法流程在分组内达成共识,最后,分组主节点之间按照PBFT共识流程达成最终共识。分组混合共识机制其中概率分组算法提高共识达成概率,减少主节点切换次数从而提高在存在拜占庭错误情况下共识性能;随机分组过程利用可验证随机函数VRF确保节点之间不能串通,保证了共识的活性与安全性;混合共识算法组内使用拜占庭容错chain-raft共识,引入聚合签名使得通信复杂度为O(n)并且优化了共识流程,缩短了整体共识时间;组间继续使用PBFT共识,保证分组之间拜占庭容错,进一步加强共识安全性。
针对PBFT共识存在的问题,本文提出了一种适合联盟链的分组混合共识机制。之所以适合联盟链,是因为联盟链是准入制可以知道系统中有多少个参与节点,有利于分组构建。之所以分组,是因为节点进行分组,虽然增加了一个分组过程,但是重新分组只会发生在最终共识达成失败的情况,根据本文概率分组算法,共识失败率低于PBFT共识,因此缓解了共识失败主节点切换频繁造成的通信压力,并且此分组过程也保证了系统活性。然后分组之后每组都有主节点,此方式会缓解主从模式主节点作为通信中心的压力。随机分组让拜占庭节点无法预知分组结果进而串通攻击分组,保证了系统安全性。之所以要混合共识,一方面本文拜占庭容错chain-raft算法在拜占庭容错的基础上通信复杂度为(O(n)),并且借鉴HotStuff共识[33]流水线化的共识流程,让先后两笔交易不同阶段同时进行,缩短了上述共识算法的时间。另一方面,考虑到联盟链目前大部分使用PBFT共识,本文设计的共识机制可以作为PBFT共识的一种扩展,这样可以很好的兼容当前的PBFT共识。
本文的贡献在于:一是采用概率分组算法,提高共识达成概率;二是采用随机分组过程,防止拜占庭节点串通,保证共识安全性;三是提出一种新的组内拜占庭容错chain-raft共识,在拜占庭容错的基础上引入共识流程并行化,优化共识流程,组间继续使用PBFT共识算法,保证了分组拜占庭容错和对已有PBFT共识算法的兼容性。
1 分组混合共识机制
本文构建了基于分组混合共识机制,如图1所示其中分为三个阶段,分别进行介绍。

图1 分组混合共识机制架构图
概率分组阶段:PBFT共识算法若有3f+1个节点,最多可容纳f个拜占庭节点,共识失败率最高接近1/3,导致频繁触发viewchange切换主节点拖慢系统性能。根据概率分组可以降低共识失败率提高系统性能。
随机化分组阶段:PBFT共识算法随着节点数量的增加,节点间通信复杂度增长过快,主节点通信压力会越来越大,分组后先组内共识,然后组间共识,降低了通信复杂度同时减缓了通信复杂度增长速度,组内有主节点,组间有主节点,降低了单一主节点通信压力。随机化分组的目的是为了防止拜占庭节点可能会串通攻击一定数量的分组破坏共识达成,因此使用可验证VRF随机函数随机分组让每个节点无法预先判断分到哪个组,从而保证共识活性。
混合共识阶段:如果只是PBFT共识分组,组内还是PBFT共识,通信复杂度为o(n2),因此组内使用拜占庭容错的chain-raft共识,通过聚合签名确认消息,并且并行化共识阶段,共识通信复杂度为o(n),进一步降低了系统通信复杂度,而且组间PBFT共识,保证分组间拜占庭容错和已有PBFT共识算法的兼容性。
1.1 概率分组算法
概率分组算法的步骤:
第一步:先求解出组数满足N>=3f+1和组内节点数满足N>=3f+1的分组方式求解算法如表1。

表1 分组算法
第二步:根据已经求出的分组方式,求出该分组方式的拜占庭容错节点个数,求出该分组方式达成共识的概率,例如总共有16个节点,分为4组,每组有4个节点,该分组方式拜占庭容错节点个数为5个,达成共识的概率为
(1)
第三步:在满足达成共识概率最高和容纳拜占庭节点最多的条件下得出分组方式。
本文概率分组算法不仅提高共识达成概率,还发现在同样的节点数,不同的分组方式会影响达成共识的概率。根据拜占庭容错,N≥3f+1,其中N是节点总数,f是拜占庭节点数。如果有28个节点分为4组,一组为7个节点,这种分组方式若有9个拜占庭节点,达成共识的概率为:
(2)
若分为7组每组4个节点,这种分组方式若为9个拜占庭节点共识达成概率为
(3)
同样节点分组变多会提升共识的达成概率。
1.2 随机分组过程
如果分组按照一定的规则,例如选取分组,分组结果就是可预测的,拜占庭节点非常容易串通破坏共识,例如,有16个节点,分成4组,每组有4个节点,根据拜占庭共识结论,N>=3f+1,所以总体最多可以允许5个拜占庭节点,每个分组只能允许1个拜占庭节点,允许一个分组为拜占庭分组,假如这5个节点串通,分成2和3分别分入两个分组之中,就会导致两个拜占庭分组出现从而导致整体无法达成共识。为此本文提出一种结合可验证随机函数VRF[31]的随机分组过程,分为随机分组信息生成和随机分组信息的确认。
哈希函数其值域是离散的、均匀分布的,给定不同的输入值,其输出值没有规律,随机的洒落、分布在值域区间内,因此,哈希函数的输出值是无法预知的,从而保证分组信息的随机性。VRF是一种结合非对称密钥技术的哈希函数,具体流程:
①证明者计算proof=VRF_PROVE(sk,info),sk是私钥。
②证明者把proof和info公布出去。
③验证者计算True/False=VRF_Verify(proof,info,pk),pk是公钥。

随机分组信息的确认采用二次确认过程,这样保证了部分同步网络模型下节点之间的一致性。
步骤如图2所示:
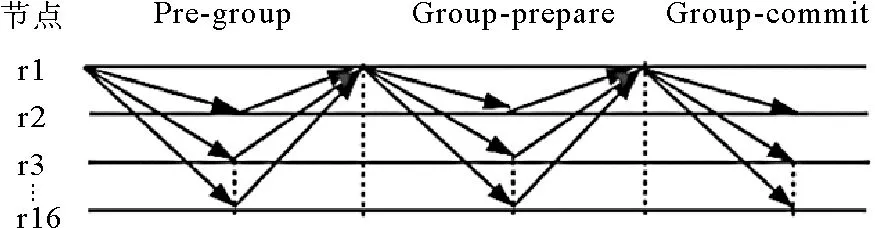
图2 随机分组信息确认流程
第一步:主节点根据自己的私钥sk签名接收到client的信息作为data-sk,当前轮数作为n,分组信息作为VRF_PROVE的info,不断随机info计算出自己这一轮的proof。如果满足抽签阈值,就广播
第二步:副本节点收到验证信息,查看轮数n是否比之前的大,然后验证VRF_Verify(proof,info,pk),如果验证通过就用私钥签名确认信息
第三步:主节点接收到回复,如果收到2f+1的节点签名确认就组合成data-sk-list,然后广播
第四步:主节点收集到2f+1个节点签名确认信息,发送信息到其他副本节点,副本节点通过最终的proof确认对应的分组信息。上述四步消息格式如表2。

表2 发送接受对象之间的消息格式
1.3 mix-raft-pbft混合共识算法
如图3所示,mix-raft-pbft共识流程分为组内共识和组间共识,其中组内共识是拜占庭容错chain-raft算法分为两个阶段保证部分同步网络模型下数据的一致性,其中包含组内预确认阶段和组内确认阶段。组内共识阶段:①组内主节点用私钥签名接收到的client交易数据data,生成交易数据哈希值data-hash保证数据的完整性,为这笔交易数据标记唯一data-ID,组成

图3 mix-raft-pbft共识流程
以上描述的拜占庭容错chain-raft算法共识流程是一笔交易先进行pre-commit阶段,主节点收集签名集合data-sk-list,然后进入commit阶段主节点再次收集签名集合data-sk-list,这个流程交易是一笔交易走完两个阶段然后下一笔交易再次走完这两个阶段,其实当主节点正在进行第一笔交易commit阶段的时候,可以同时发送第二笔交易的pre-commit消息,这样主节点就可以同时收到副本节点第一笔commit-ack回复和第二笔交易的pre-commit-ack回复,优化了共识流程,如图4所示。

图4 chain-raft流程优化图
1.4 共识算法分析
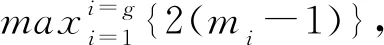
1.4.2 安全性分析 随机分组防止了拜占庭节点之间的串通,分组需要2f+1个节点确认,保证在最多f个拜占庭节点的条件下,分组可以正确完成。
组内chain-raft共识不存在同一个交易ID中不同的交易都能收到足够多投票的情况,保证最终存储的一致性。
证明:假设N=3f+1为节点总数,f为拜占庭节点最大数量,那么当收到2f+1投票为足够多投票。因两个区块都收到至少2f+1,投票总量至少为 2(2f+1)=N+f+1,能看到至少有f+1对同一个交易ID中不同的交易都投了票,与f个拜占庭节点假设矛盾。
1.4.3 活性分析 活性指的是所有好的事情一定发生,就是要在一定时间范围内完成整个共识过程,并保证所有诚实节点提交一致性结果。共识算法活性出现的原因主要是节点之间可能存在的传输延迟,传输延迟会导致节点无法产生一致性结果。
随机分组过程活性主节点必须在一定时间内收集到2/3个节点签名,如果在一定时间内没有收集到足够的签名,其他节点会代替主节点,在N>=3f+1的条件下,一定时间内是可以保障主节点活性。
组内拜占庭chain-raft共识算法中,活性主要体现在随机超时时间t的设立。t∈[T,2T]并且满足T>=randomtime的条件,以避免因为消息延迟而导致的不必要的主节点切换,同时t的设立又可以让系统在有限的时间内产生一个主节点,保证系统的正常运行。
2 仿真实验
本文通过go语言实现PBFT和分组混合共识机制,使用线程监听不同的端口代替节点,线程之间的交互使用TCP协议,模拟分布式系统共识过程。环境中包含RSA信息加解密过程和网络信息传递延迟,如表3所示。

表3 实验环境
2.1 模拟网络信息通信延迟
本文混合共识适用于联盟链,联盟链使用者大部分为企业,因此模拟企业最普遍的网络拓扑结构星型结构,依照此结构计算网络信息传递延迟。
图5为n个节点网络拓扑结构,任意两个节点ni,nj的延迟,若(ni,nj)⊂同一个hub,延迟为30~50 ms,若(ni,nj)⊄同一个hub,若相隔hub个数为k,延迟为30~50 kms。节点延迟是一个包含几个值的集合,这些值用于模拟节点路由到不同节点之间的延迟。

图5 星型网络结构
2.2 共识实验结果
实验从共识时延和吞吐量两个方面对比PBFT与分组混合共识机制,结果如下
图6是在本文算法在100笔交易,随着节点数量增加,共识时间对比。chain-raft共识随着节点数增加,共识时间接近线性增长趋势,而pbft共识接近多项式级平方增长。本文混合共识机制组内使用拜占庭容错chain-raft共识,降低了整体共识的消息复杂度和共识时间,提高了系统性能。

图6 共识时延对比
图7是本文共识在100笔交易分为四组的情况下与PBFT共识在不同节点下的对比,可以看出PBFT随着节点数量增加,共识时间迅速增加,而本文共识由于分组,在分为4组的情况下,组间共识时间基本不变,而组内共识时延增长为线性、组内节点数量增加缓慢并且分组之间共识并行化,最终整体达成共识时间增加缓慢。随着节点的增加与PBFT共识时间的优势会越来越大。

图7 共识时延对比
图8是本文共识算法在10笔交易,100个节点分为不同组数情况下的共识时间。因为组间是PBFT共识,通信复杂度o(n2),所以随着分组变少,共识时间变少,但随着组内节点变多,对整体共识时间影响变大,因此最终分组的确定需要与达成共识概率做一个平衡。
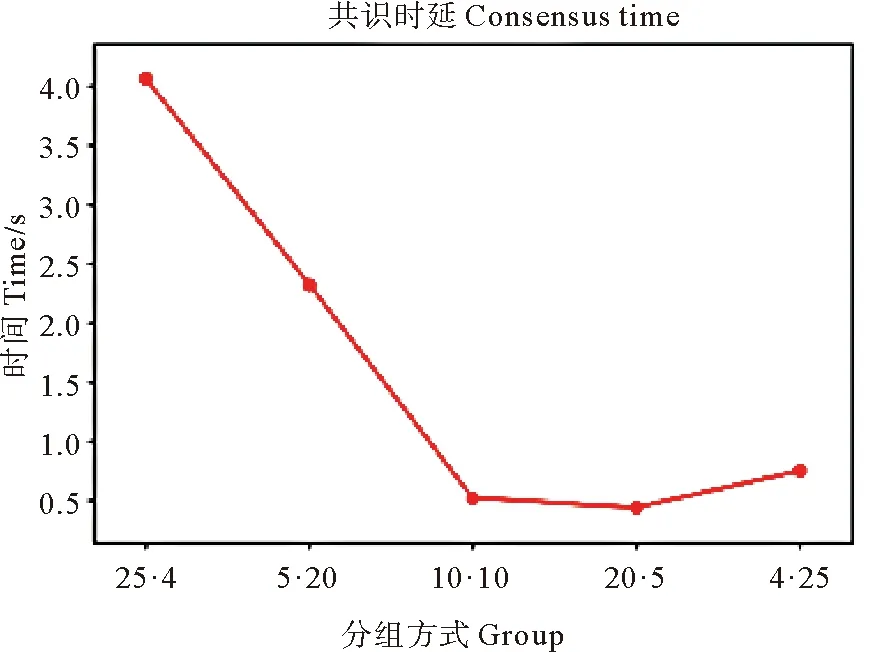
图8 mix-raft-pbft不同分组共识时延
图9是在不同的节点数量分为四组的情况下,mix-raft-pbft与PBFT吞吐量的对比,mix-raft-pbft由于组内节点数量增加导致整体吞吐量下降,不过整体吞吐量容然有较大提升。
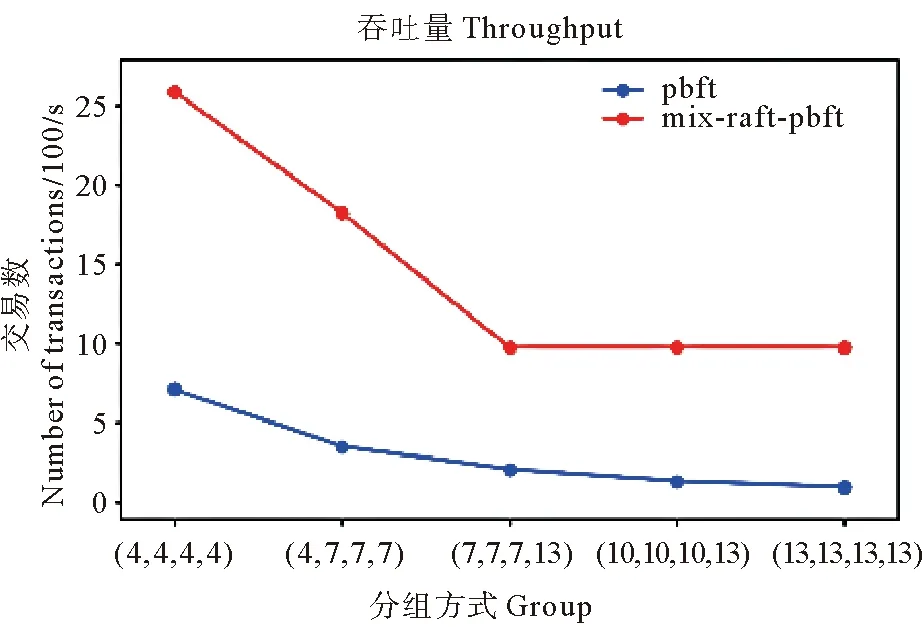
图9 mix-raft-pbft与PBFT吞吐量对比
3 结语
在本文中,简要介绍了PBFT算法。针对PBFT的共识效率,提出了一种基于PBFT的分组混合共识机制来提升效率并且保证了安全性不变。分组混合共识机制包括三个阶段,第一阶段概率分组算法,提升了共识达成概率;第二阶段随机分组,防止拜占庭节点的串通;第三个阶段mix-raft-pbft混合共识算法,组内使用拜占庭容错chain-raft算法,组间使用PBFT算法,因为已经完成分组,所以分组之间可以同时进行共识,最终分组之间完成PBFT算法共识,组内拜占庭容错chain-raft算法降低了通信复杂度,分组减少了最终PBFT算法共识的参与节点同时减小了主节点通信压力,从而大大缩短了整体共识时间。
