基于趋势单产和干旱指数的河南省冬小麦单产估算
2021-05-25李石波朱秀芳侯陈瑶
李石波,朱秀芳,侯陈瑶,郭 锐,刘 莹
(1.地表过程与资源生态国家重点实验室,北京师范大学,北京 100875;2.土地科学技术学院,中国地质大学(北京),北京 100083;3.地理科学学部遥感科学与工程研究院,北京师范大学,北京 100875)
作物生长发育和产量形成是一个复杂的生理过程,作物产量预测需要考虑气象、土壤、田间管理等多种因素[1-2],因此作物估产一直是农业研究热点和难点。近年来,由于全球气温升高,越发频繁的极端气候严重影响作物生长,国家粮食安全面临极大挑战,因而气候异常情况下及时获取作物产量信息能够为相关部门应对极端气候、保障粮食安全提供决策依据。
几十年来,众多不同领域的学者做了大量相关研究,使传统作物估产技术得到快速发展。目前作物估产模型有上百种,模型的理论基础和特点各不相同。从模型建立的理论角度看,当前主流的作物估产模型可以分为经验统计模型、光能利用率模型、作物生长模拟模型和耦合模型[3]。经验统计模型是建立作物产量与统计数据之间的统计关系来进行作物估产的一类模型,因原理简单、数据容易获取、贯穿整个估产领域的发展过程,在业务化推广应用中发展的最早也最广泛。
基于气象数据的估产模型是经验统计模型的一种。它通过建立气象数据与作物产量之间的关系,并在考虑其他因素的基础上建立统计模型,最终实现作物单产估算。气象估产技术比较成熟,适合业务化运行,且具有一定的生理学基础[4]。基于气象数据的作物估产模型已经在国内外得到了广泛应用[5-7]。基本的气象预测模型的预测模式有三种:第一种,直接建立气象因子和作物产量之间的回归模型[8];第二种,将作物产量分解为由趋势产量和气象产量两部分,前者反映由技术进步(如灌溉、施肥、新品种等)导致的产量长期变化,后者反映由自然气候要素(光照、降水、辐射等)引起的产量短期波动[9-10];第三种,首先计算相邻两年作物产量差和气象因子差,然后建立作物产量差和气象因子差之间的回归模型,进而进行作物产量预测[11]。第一种方法仅仅依靠气象数据进行产量的预测,不能反映趋势产量,因此相比而言后两种方法更科学。
全球气候变化异常,导致自然极端气候越发频繁,给我国农业生产带来了很多新的挑战[12-15]。其中,干旱是各种气象灾害中影响最严重、最频繁、持续时间最长的气象灾害,也是影响作物产量和粮食安全最重要的限制因素[16]。有关统计数据[17]表明,2007-2016年全国农作物旱灾面积均值为1.53×107hm2,粮食损失均值为214.14亿kg,直接经济损失平均占当年GDP的0.21%。目前在已有的估产模式中,针对极端气候条件下作物估产模型的建立研究较少,建模的输入数据多为原始气象因子(比如温度、降水),不能直接反映极端气候对产量波动的影响。鉴于此,本研究引入干旱指数,以干旱指数和趋势产量为输入,以近年来受干旱影响严重的河南省冬小麦为例,采用气象估产的方式,兼顾社会技术与气象因素对小麦生产的影响,利用非参数统计方法进行估产模型构建,选择典型干旱和非干旱年份进行模型精度的验证,以期为提高极端气候条件下的估产精度提供方法参考。
1 材料与方法
1.1 研究区概况
河南省位于北纬31°23′~36°22′,东经110°21′~116°39′之间,东接安徽、山东,北界河北、山西,西连陕西,南临湖北。全省下辖17个地级市和1个省直辖县级市,总面积达16.7万km2,地势西高东低,由平原和盆地、山地、丘陵、水面构成;地跨海河、黄河、淮河、长江四大水系,大部分地处暖温带,南部跨亚热带,属北亚热带向暖温带过渡的大陆性季风气候区。河南省是粮食种植大省,隶属于黄淮海区,是我国冬小麦主要生产地之一,土地肥沃,具有较好的农业生产条件。自20世纪90年代以来河南极端气温处于明显加速变化阶段[18],1994-2014年,河南省极端气温指数的变化速率明显高于中国其他地区2倍之多,农作物种植面临极大挑战。

图1 研究区
1.2 数据准备
本研究所用数据包括来自1991-2016年河南省统计年鉴的1990-2015年各县区的冬小麦播种面积和总产量(http://data.cnki.net)、来自中国科学院资源环境科学数据中心的2000年1 km分辨率的中国土地利用类型空间分布图(http://www.resdc.cn)及来自全球标准化降水蒸散指数(standardized precipitation evapotranspiration index, SPEI)数据库(http://sac.csic.es/spei/database.html)的SPEIbase v2.5数据集。其中,河南各县小麦产量和播种面积数据主要用于各县小麦单产的计算;土地利用类型空间分布图主要用于对河南省耕地空间分布的提取;SPEIbase v2.5数据集提供了全球1901-2015年1~48个月时间尺度的0.5度分辨率的SPEI月值数据,该数据不仅综合考虑了温度与降水对干旱程度的影响,而且具有多种时间尺度。由于干旱对于河南省冬小麦产量影响较大,为了研究小麦生长期各个时间尺度的SPEI对产量的影响,以及提高干旱条件下估产精度,本研究基于该数据集提取了1990-2015年间河南省估产小麦生育期内不同时间尺度(1~3个月尺度)的SPEI数据集,分别记作SPEI-1、SPEI-2和SPEI-3,作为输入变量用于随机森林估产模型构建。
1.3 技术路线
本研究技术路线如图2所示,主要包括如下步骤:1)利用河南县级矢量数据和河南土地利用分类数据对河南省各县耕地范围内平均SPEI值进行计算,得到各县不同时间尺度的SPEI均值;2)结合龚珀兹曲线和自回归移动平均模型(Autoregressive-moving-average model,ARMA)拟合县级趋势单产;3)用随机森林算法建立趋势单产、干旱指数与实际单产的回归模型并进行模型拟合精度验证;4)选择干旱和非干旱年份对小麦单产进行估算并进行精度评价;5)基于随机森林算法进行输入变量重要性评价并进行结果分析。

图2 技术路线
1.3.1 SPEI均值计算
SPEI是目前最常用的气象干旱指数之一,具有多时间尺度的特征。由于SPEI原始数据集与中国耕地空间分布图分辨率不一致,因此首先对SPEI数据进行重采样至1 km×1 km。利用2000年河南省耕地空间分布图提取出河南省耕地范围上的SPEI干旱数据,基于河南省县级矢量对全省各县耕地范围进行提取,并针对每一个县区,找到其耕地范围内的所有SPEI栅格,求其干旱指数的均值,得到县级SPEI均值。
1.3.2 趋势单产拟合
冬小麦单产受多种因素的影响,其中主要包括社会因素、自然因素和一些其他随机因素[19]。一般将由社会因素导致小麦产量发生变化的部分称为趋势单产,主要表现为科技发展和社会投入引起的小麦单产变化;将由气象因素引起的小麦单产波动性变化称为气象单产,主要表现为年际间气象条件的差异造成的小麦单产变化;将由一些其他随机因素造成的小麦单产波动称为随机单产。因此对单产进行模拟时,把作物单产分解为趋势单产、气象单产和随机单产三部分,由于随机单产的不确定性,通常将其忽略不计。因此,实际单产可以分解为趋势单产和气象单产之和(如公式1)。
yi=Yi+Yc
(1)
式中,yi为冬小麦实际单产,Yi为趋势单产,Yc为气象单产。
理论上小麦单产的变化趋势应该符合有限增长上限曲线的趋势模型,其中关于拐点不对称的S形曲线,即龚珀兹曲线(公式2)应用较为广泛。单独应用龚珀兹曲线对趋势单产进行拟合,可能会导致趋势单产和实际单产残差自相关,进而使得拟合结果失真。采用自回归移动平均模型(autoregressive-moving-average model,ARMA)进一步对残差序列进行拟合,将ARMA对残差的拟合结果与龚珀兹曲线得到的趋势单产相加得到最终的趋势单产,能够有效解决上述问题,提高拟合精度[20]。因此,本文采用龚珀兹曲线和自回归移动平均模型(Autoregressive-moving-average model,ARMA)相结合的方式,对河南省县级趋势单产进行拟合。由龚珀兹曲线和ARMA模型构成混合时间序列模型,见公式3和公式4。
Yi=Le-aebt(a>0,b>0)
(2)
u1=Y1+uc
(3)
φ(B)ut=θ(B)εi
(4)
式中,Yt为龚珀兹曲线拟合的趋势单产,e为自然对数,t表示年序,初始值为1,代表1990年,a和b为待估计参数,ut为混合时间序列拟合的趋势单产,uc是龚珀兹拟合残差的趋势改 正值。
φ(B)=1-φ1B-φ2B2-…-φpBp
θ(B)=1-θ1B-θ2B2-…-θqBq
B为滞后算子,εt为白噪声序列。
1.3.3 各市随机森林回归模型建立与精度验证
随机森林方法是一种较新的机器学习算法,具有稳定性好,预测精度高等优点,不需要检查变量的交互作用是否显著,不用做变量选择,在异常值和噪声方面具有较高的容忍度,而且不容易出现过拟合现象。它的主要思想是通过自助法抽样从原始训练集中抽取k个样本,且每个样本的样本容量均与原始训练集的大小一致;然后对每个样本分别进行决策树建模,得到k个建模结果,最后,以每一个棵决策树预测结果的平均值作为最终预测结果。
干旱是影响河南省冬小麦产量的最主要气象灾害,具有缓发性、持续性和复杂性的特点。不同干旱发生的时间和强度对作物产量的影响不同。河南省冬小麦通常于10月上旬播种,次年6月收获,冬小麦在刚播种时期和收获时期需水量一般相对较小。考虑到实际应用与河南省小麦生长期状况,本研究以10月至次年5月为研究时间,以该时间段中各月份1~3个月时间尺度的县级SPEI均值和趋势单产共25个变量作为输入变量,县级实际单产作为输出变量,在去除拟用于模型验证的年份(2011和2015年)的样本后,构建市级随机森林回归模型,用决定系数R2、验证样本的平均绝对值误差(MAE)、均方根误差(RMSE)和平均绝对相对误差(MRE)对模型进行精度评价。
(5)
(6)
(7)
(8)
式中,RSS为残差平方和,TSS为执行回归分析前,输出变量固有的方差。vi和Vi分别表示验证样本中第i个样本的真值和估计值,n表示样本点的个数。
由于受样本数量和随机森林回归模型特性的限制,当建模样本数量较小时随机森林回归模型拟合精度较低,可信度不高,故将样本量过小的市(包括济源市、鹤壁市和漯河市,它们的样本个数分别为25个、50个和50个)按照地理位置最近的原则,合并到周边的其他市中进行模型建立。
1.3.4 典型年份单产预测及验证
近年来,河南省冬小麦产量遭受旱灾影响严重,其中2014年旱灾持续时间长,2000年前后和2011年各发生干旱的整体强度大[20]。结合文献[20]同时参考中国民政统计年鉴和河南省统计年鉴,发现河南省旱灾发生频繁,每年或多或少都会受到旱灾的影响。其中2015年河南全省干旱情况最轻,全省作物受灾面积为33.43 hm2,成灾面积和绝收面积分别只有3.84×103和0.53×103hm2。而2011年受灾情况居中。在2011年旱情中,2010年11月中旬河南省出现旱情,至次年2月份上旬达到高峰,累计降水量比多年同期平均偏少8成以上,4月初全省旱情才得以解除,全省作物受旱灾损失严重,受灾面积、成灾面积、绝收面积分别达到了1 020.4×103、211.3×103和12.9×103hm2。因此,为了进一步验证市级模型在小麦不同生长环境下的估产精度,本研究挑选了2011年作为典型干旱年份和2015年作为典型非干旱年份,对这两个特定年份进行河南各市小麦单产估计,并分别用简单平均估计值与面积加权后估计值进行精度对比。简单平均估计值是将市内各县的趋势单产和平均SPEI带入随机森林回归模型,得到各县的单产估计结果,然后对各县的单产估计值求平均值作为最终的市级小麦单产估计值;面积加权后估计值是将市内各县的趋势单产和平均SPEI带入随机森林回归模型,得到各县的单产估计结果,然后用各县小麦播种面积进行面积加权平均,以此作为最终的市级小麦单产估计值。
1.3.5 小麦单产影响因子重要性评价
随机森林模型可以进行特征变量重要性排序和筛选,其原理是用袋外数据样本得到误差e1,然后给予袋外数据样本某一特征随机误差,重新得到袋外数据误差e2。至此,可以用e1-e2来刻画该特征的重要性。其依据就是,如果一个特征很重要,那么其变动后会非常影响测试误差,如果测试误差没有怎么改变,则说明该特征不重要。在随机森林回归模型中,输入变量的重要性大小意味着该输入变量对输出变量的解释程度。输入变量重要性越大,说明该变量对输出变量的解释能力越强。本文利用随机森林算法对趋势产量和不同时间尺度SPEI月均值,共25个输入变量进行重要性排序,统计分析影响各市小麦产量的重要因素。
2 结果与分析
2.1 随机森林回归模型建立与精度验证结果
全省共18个市,其中鹤壁市、济源市、漯河市因样本量较小,分别合并到安阳市、焦作市、许昌市中,合并后共得到15个市级估产模型。表1 为合并后河南各市随机森林回归模型拟合精度指标。从表1可以看出,全省各市随机森林回归模型拟合精度整体较高,决定系数R2的平均值为0.87,其中三门峡市模型决定系数最小(0.655),商丘市模型决定系数最大(0.966)。各市均方根误差均值为23.45 kg·hm-2,其中周口市均方根误差最大(29.395 kg·hm-2),濮阳市均方根误差最小(17.679 kg·hm-2)。各市平均绝对值误差的均值为17.69 kg·hm-2,其中洛阳市平均绝对误差最大(23.196 kg·hm-2),濮阳市平均绝对误差最小(11.931 kg·hm-2)。各市平均绝对相对误差的平均值为0.07,其中三门峡市平均相对误差最大(0.138 7),焦作市平均相对误差最小(0.034 1)。整体上看,各市模型精度指标较好,模型拟合精度较高。这里要说明一点:各市平均相对误差的均值、平均绝对值误差均值和平均绝对相对误差的均值指的是该市内整个研究时间段内所有县产量估计值的相对误差、绝对值误差和绝对相对误差的平均值。
2.2 各市干旱年份与非干旱年份冬小麦估产精度
从表2和图3可以看出,无论干旱年份(2011)或非干旱年份(2015年),除三门峡市以外,其他市级模型估产精度均达到80%以上,最高估产精度可达到95%以上。三门峡市估产精度最低,2011年其小麦简单平均估产精度和面积加权后估产精度分别为88.05%、88.39%,2015年分别为78.96%、79.46%。从图3可以看出,不管是简单平均估产还是面积加权后估产,2011年小麦估产精度平均值均在95.00%以上,2015年小麦估产精度平均值均在92.00%以上;两个典型年份小麦面积加权估产精度整体高于简单平均估产精度;2011年小麦估产精度整体高于2015年。
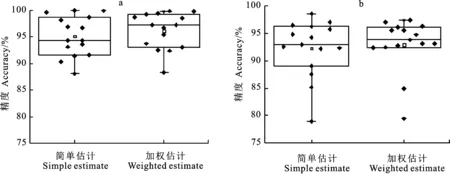
a:2011年小麦单产预测精度; b:2015年小麦单产预测精度。

表2 特定年份各市小麦单产预测结果
2.3 小麦单产影响因子重要性排序结果
合并部分市的样本后,基于随机森林算法计算共得到15个市输入变量重要性的排序结果。为了便于分析,对15个模型各变量重要性排序结果进行统计(图4)。从各输入变量在15个模型重要性排序中的平均排名(图4a)可以看出,排名前6的变量的编号依次为0、22、6、2、3和5,对应的变量分别为趋势单产、3个月时间尺度的4月份的SPEI均值以及1个月时间尺度的4月份、11月份、1月份、3月份的SPEI均值,其平均排名值分别为1、9、9.6、10、10.4和10.5。在各干旱指数中,1个月时间尺度的干旱指数重要性要强于2个月和3个月时间尺度的干旱指数。
图4b为25个输入变量中每一个输入变量在各自模型重要性排序中出现在前5的频数统计结果,不包含频数为0的变量。从图4b可以看出,25个输入变量中有22个变量在排名前5中出现过。趋势单产(编号为0的变量)出现频率最高为15,即在每个模型中均有出现;其次是1个月时间尺度的3月份和4月份的SPEI均值(编号为5和6的变量),出现的频数均为7;接着是3个月尺度的4月的SPEI均值(编号为22的变量)出现过6次;其他编号变量虽在前5出现过,但出现频数较低,均小于5次。

编号为0的变量为趋势单产,编号为1~8的变量依次为1个月时间尺度的10月份到次年5月份的SPEI均值;编号9~16的变量依次为2个月时间尺度的10月份到次年5月份的SPEI均值;编号17~25的变量以此为3个月时间尺度的10月份到次年5月份的SPEI均值。
综上可以看出,趋势单产对估产的精度影响最大;在各干旱指数中1个月时间尺度的干旱指数对单产估算精度的影响大于2个月和3个月时间尺度的干旱指数;在各月份中,4月份(小麦拔节抽穗期)的干旱指数对估产精度影响最大。
3 讨 论
本研究以河南省为研究区,综合考虑影响小麦产量的技术因素和气象因素,以趋势单产和不同时间尺度干旱指数作为输入变量,实际单产作为输出变量,建立了随机森林回归模型并分析讨论了影响小麦单产的重要因素,结果表明,本研究建立的模型具有较高的估产精度,尤其是在干旱年份表现出较好的估产精度,该方法对于受极端气候事件影响的作物单产的估算具有一定的参考价值。随机森林算法是一种非参数统计方法,其优势在于不需要过多考虑特征的选择,模型建立之后能够得到所有特征的重要性,对于处理数量较大的数据集表现出良好的效果,泛化能力较强,但随机森林回归模型对于样本数量有一定的要求。本研究中鹤壁市、济源市和漯河市样本数量过少导致模型拟合精度不高,可信度较低。另外,建模所用基础统计数据存在误差也是导致模型拟合精度不高的原因,例如三门峡市模型拟合精度较低,可能与基础统计数据存在误差有关。
在本研究中,2011年(干旱年份)的估产精度整体高于2015年(非干旱年份)的估产精度,这与模型输入变量类型有关,本研究输入变量为趋势单产和小麦生长期内不同时间尺度的SPEI干旱指数,其中干旱指数在干旱年份能够更好解释小麦产量随气候的波动。另外,简单平均的小麦估计值略低于面积加权后小麦估产值,但无明显差异。考虑其操作简单,无需各县小麦种植面积数据,在实际操作,特别是没有细致的小麦播种面积数据时,可以通过简单平均县级小麦单产估计值来得到市级小麦单产的估计值。
影响河南省小麦单产的主要因素为技术因素,即趋势单产,说明改进趋势单产拟合方法能够提高小麦估产模型拟合精度。在各干旱指数中,整体来看1个月尺度的干旱指数重要性高于2、3个月尺度的干旱指数,说明在河南省短时间尺度的干旱指数更能捕捉到降水对小麦的影响。此外,从时间上看,4月份干旱指数重要性高于其他月份干旱指数,可能的原因是4月份处于河南小麦的拔节抽穗期,这一时期是小麦一生中生长速度最快,生长量最大的时期,需水量较大,对水分敏感。
传统的气象估产方法建模时需要首先筛选出与输出变量相关性较大的特征参与建模,而随机森林回归不需要刻意进行特征选择,能够达到较高拟合精度的同时获取特征重要性排序,不需要考虑输入变量之间的相关性高低,而传统的线性回归还要考虑多重共线性的问题。另外,各种气象因子与产量并不是简单的线性关系,随机森林回归是一种非线性回归方法,相比传统的气象估产模型建立方法更具优势。本研究还存在一些待改进之处,例如只考虑了播种到收获时间内的干旱指数(SPEI),未分析播种前的降水,生育期内的低温冷冻、高温热浪等其他气象灾害对作物产量的影响,未来研究将考虑加入更多的气象因素来参与模型构建,以提高模型在不同条件下的适用性。
4 结 论
兼顾影响小麦产量的社会因素和气象因素,利用随机森林非参数统计的方法建立了小麦估产模型,并在典型的干旱和非干旱年份进行了精度验证。结果显示:1)模型拟合精度较高,在极端气候条件下表现出良好的估产效果;2)用县级小麦播种面积加权得到的市级估产结果相对于简单平均的精度提升并不明显,在实际应用中,可直接通过简单平均的方法获取市级小麦单产的估计值;3)不同月份和不同时间尺度的干旱指数对建模的重要性程度不一样。
