我国信用债个体违约风险测度与防范
——基于LSTM深度学习模型
2021-05-25陈学彬徐明东
陈学彬 武 靖 徐明东
(四川大学 经济学院,成都 610065;复旦大学 金融研究院,上海 200433)
一、 引 言
1992年11月,第一只可转债的发行标志着中国信用债市场的建立。到2019年9月底,其存量规模达到57.34万亿元,占债券市场整体规模的60.74%。中国信用债市场不仅规模巨大,而且结构也在逐步优化,除了金融债和同业存单仍然在信用债市场占比较高外,为非金融企业融资服务的公司债、中期票据、资产支持债、企业债和短期融资券也得到快速发展。随着信用债市场的快速发展,违约风险也快速上升,中国信用债市场的“刚性兑付”状况随着2014年3月“11超日债”未足额兑付而终结,此后违约事件逐步增加。2020年全年违约信用债券规模达1,803亿元,涉及140只信用债券,延续了信用债违约常态化的特点,累计违约率再创新高。在民企违约风险上升势头减缓的同时国企违约风险不断上升,首次违约的高评级主体占比增加。2020年违约的信用债中,多家主体评级和债项评级在违约前仍保持AAA最高评级水平,如永城煤电短融券和华晨汽车私募债等,现有评级未能及时有效揭示其风险。
债券市场的基础设施尚需进一步完善以及债券发行者与投资者之间信息严重不对称是信用债市场违约风险快速上升的主要原因:(1)许多债券发行人是非上市公司,缺乏标准化和定期的财务报表信息披露。如2014年至2019年6月期间违约的348只债券中,只有255只债券有相对完整的财务报告。而发债的上市公司财务报表披露也存在诸多严重失真的情况。(2)大多数债券只有发行评级,缺乏及时和准确的跟踪评级。如上述348只违约债券中,只有77只具有相对完整的评级信息。由于中国债券市场机构投资者对投资标的等级的严格要求,评级稍低的债券将无法发行。发行人为了成功发行,通常通过各种方式提高发行评级。2010年1月至2019年9月,中国信用债市场发行的 AAA级至 A-1级的4种评级债券发行只数和发行金额占信用债发行总量的97.07%和98.81%,其他评级债券仅占2%~3%,发行评级明显虚高。
在债券市场快速发展和市场基础设施逐步完善的过程中,如何结合披露信息以及其他相关“大数据”信息对债券违约风险进行及时、有效分析和预测,对投资者和中国信用债市场的健康发展具有重要意义。
二、 文献回顾
债务违约风险的度量在20世纪中后期逐步出现(Beaver(1)W. H. Beaver, “Financial Ratios as Predictors of Failure,” Journal of Accounting Research 4(1966): 71-111.、 Altman(2)E.I.Altman, “Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy,” The Journal of Finance 23 (1968): 589-609.、 Merton(3)R.C.Merton, “On the Pricing of Corporate Debt: The Risk Structure of Interest Rates,” The Journal of Finance 29 (1974): 449-470.、 Jarrow和Turnbull(4)R.A.Jarrow, and S. M. Turnbull, “Pricing Derivatives on Financial Securities Subject to Credit Risk,” The Journal of Finance 50 (1995): 53-85.等分别提出或改进了评分模型、结构模型和简约模型等经典违约模型)。20世纪90年代,随着海量数据处理和分析技术的应用,信用风险度量研究进入了现代量化分析阶段,学界和实务界提出并广泛应用了如KMV、 Credit Risk+、 Credit Metrics、 Credit Portfolio View等模型体系。21世纪初,业界进一步采用衍生品工具对违约风险进行度量和预测,如穆迪公司提出的信用违约互换隐含信用度量模型等。陈静(5)陈静:《上市公司财务恶化预测的实证分析》,《会计研究》1999年第4期。,吴世农和卢贤义(6)吴世农、卢贤义:《我国上市公司财务困境的预测模型研究》,《经济研究》2001年第6期。,郭斌、戴小敏、曾勇(7)郭斌、戴小敏、曾勇:《我国企业危机预警模型研究——以财务与非财务因素构建》,《金融研究》2006年第2期。,马若微、张微、白宇坤(8)马若微、张微、白宇坤:《我国上市公司动态违约概率KMV模型改进》,《系统工程》2014年第11期。也采用KMV等研究方法和模型对中国债券市场违约问题进行研究,发现财务和非财务因素对企业债务风险均有影响。姚红宇、施展(9)姚红宇、施展:《公司个体特征、地方经济变量与信用债违约预测——基于离散时间风险模型》,《投资研究》2018年第6期。在使用离散时间风险模型研究传统财务指标、公司特征和地方环境指标对信用债券违约的影响时,发现仅用传统财务指标来进行分析,该模型无法解释中国债券违约的状况;而引入企业属性和地方经济环境指标后,则具有更好的预测能力和准确性。
神经网络是机器学习的一类模型,由于其灵活性、强壮性和高预测精度,在金融领域的应用受到学界广泛关注(10)P.Golbayani, I.Florescu, R.Chatterjee, “A Comparative Study of Forecasting Corporate Credit Ratings Using Neural Networks, Support Vector Machines, and Decision Trees,” The North American Journal of Economics and Finance 54(2020): 101251.。在风险管理方面,大部分研究侧重于信用风险和风险预警(11)A.M.Ozbayoglu, M.U.Gudelek, O.B.Sezer, “Deep Learning for Financial Applications: A Survey,” Applied Soft Computing 93 (2020): 106384.。 Luo et al.(12)C.Luo, D.Wu, D.Wu, “A Deep Learning Approach for Credit Scoring Using Credit Default Swaps,” Engineering Applications of Artificial Intelligence 65 (2017): 465-470.使用美国金融危机时期的信用违约互换数据将深度信念网络模型在公司信用评分分类上的表现与传统模型进行比较,发现深度信念网络表现最优。 Yu et al.(13)L.Yu, R.Zhou, L.Tang, et al., “A Dbn- Based Resampling Svm Ensemble Learning Paradigm for Credit Classification with Imbalanced Data,” Applied Soft Computing 69 (2018): 192-202.使用神经网络结合支持向量机的集成学习方法改善了信用评分数据的平衡性并进行分类预测,发现结合神经网络的集成学习方法使用平衡数据时的表现相对非平衡数据得到了有效提高。 Chatzis et al.(14)S.P.Chatzis, V.Siakoulis, A.Petropoulos,et al., “Forecasting Stock Market Crisis Events Using Deep and Statistical Machine Learning Techniques,” Expert Systems with Applications 112 (2018): 353-371.在研究资本市场风险传导途径和预警机制时发现深度神经网络能够极大提升风险预测的准确程度,有效预警风险在股票市场、债券市场和货币市场间的传播。王春峰、万海晖、张维(15)王春峰、万海晖、张维:《基于神经网络技术的商业银行信用风险评估》,《系统工程理论与实践》1999年第9期。在对比研究神经网络技术和传统统计方法(判别分析和Logit回归)在商业银行信用风险评估中的应用时,发现神经网络技术具有更高的预测精度和强壮性。在债券市场的违约风险研究方面,Kim和Han(16)K.S.Kim, and I.Han, “The Cluster- Indexing Method for Case- Based Reasoning Using Self- Organizing Maps and Learning Vector Quantization for Bond Rating Cases,” Expert Systems with Applications 21 (2001): 147-156.使用韩国公司债数据训练神经网络模型并预测、构造了不同评级类型公司聚类(cluster)的中心值,再以此中心值结合案例索引分析与分类机器学习的方式预测了各个公司债的评级,得出了结合神经网络的混合聚类算法比传统聚类算法在最终预测精度上有更好表现的结论,其特征筛选步骤包括从5大类162个财务指标中进行方差分析、因子分析和逐步回归等,最终筛选出13个财务指标。长短期记忆(LSTM)是一种循环神经网络,常用来解决自然语言领域问题,同时在金融时序预测方面也有广泛应用,诸多研究集中在金融资产的价格和收益预测领域(Minami(17)S.Minami, “Predicting Equity Price with Corporate Action Events Using Lstm- Rnn,” Journal of Mathematical Finance 8 (2018): 147-156., Rather et al.(18)A.M.Rather, A.Agarwal, V.Sastry, “Recurrent Neural Network and a Hybrid Model for Prediction of Stock Returns,” Expert Systems with Applications 42 (2015): 3234-3241.)。
从过往研究中发现,使用深度学习方法研究公司信用风险所采用的样本数据多为披露完整、有效的上市公司数据,而本文的研究对象中国信用债则包含大量非上市公司发行的债券。在这种情况下,就要求配合深度学习模型,构造合理的信息规整和处理框架,以发掘有效信息;同时,以往研究所采用的特征因可视为公司财务数据或该类数据的变换,导致使用模型预测时只能进行同频率(季度或更低)的预测,无法达到及时、有效反映风险的要求。不仅如此,部分研究所采用的深度网络结构对时间维度信息处理的能力较弱,而信用债违约风险的金融时序特征明显,需要采用更有效的具备处理时间维度信息能力的深度网络作为模型基础,而这正是本文所致力于解决的问题。
三、 中国信用债违约风险预测模型构建
(一) 研究对象
信用债主要包括金融债和非金融债。金融债主要由商业银行、证券公司或者保险公司发行;非金融债内容繁多,主要包括公司债、企业债、中期票据、非公开定向债务融资工具(PPN)、短期融资券等,它们都存在一定的信用风险,目前违约的信用债主要发生在公司债(占40.18%)、短期融资券(占22.93%)和中期票据(占20.44%)等债券类型。本文研究的对象也将集中在这些类型的信用债,重点讨论在中国信用债市场发行的非政府和非金融债券面临的违约风险,包括除金融债、银行同业存单、政府支持机构债和国际机构债以外的各种非金融机构(包括上市和非上市公司),在不同市场公开和非公开发行的信用债券的违约风险预测分析。
(二) 研究方法和数据
研究方法是由研究对象和任务决定的。由于本文的研究对象包括大量的非上市公司发行的债券,缺乏其发行主体上市交易的信息,无法使用KMV方法有效预测其违约风险;同时由于中国信用债券市场缺少足够的违约统计信息,也无法有效使用 CreditRisk+、 Credit Metrics、 Credit Portfolio View等基于大量违约统计信息的模型。
深度学习神经网络模型具有处理复杂非线性关系的优点。其中 LSTM具有处理时间相关性序列的优点,在金融大数据挖掘方面具有广泛的应用前景。本文试图利用 LSTM方法构建中国信用债券违约风险预测模型,从影响债券违约风险的各种数据中去挖掘影响债券违约风险的有用信息,并形成债券违约风险预测,包括违约概率和评级预测。
除了使用 LSTM方法来构建债券违约风险预测模型外,由于债券违约风险预测的复杂性,本文将采用一系列的辅助方法对影响债券违约风险的众多因素的大量数据进行挖掘和处理。采用贝叶斯变分高斯集合聚类方法、市场指标分析和趋势倒推法相结合进行样本标注;采用专家分析法和综合变量筛选法筛选模型输入变量;采用 Keras深度学习框架来建立、训练和验证神经网络学习预测模型;最后利用信用评级的违约概率分布将违约概率预测转换为信用评级,并与市场已有的债券评级结果进行比较,以判断本文建立的债券违约风险预测模型的可信度。
本文选取我国债券市场2014年1月至2019年9月所有发行和到期信用债券相关数据,包括发行公司的财务数据、债券市场交易数据,以及同期相关的宏观经济金融数据和行业区域类数据共54个具体指标(19)详见本课题研究报告,需要者请与本文作者联系。。通过数据规整,采用2677只债券的188万条日频特征进行数据标记,排除交易数据、财务报表等数据缺乏的债券,采用2579只债券的128万条日频样本进行模型训练。
(三) 数据标记
LSTM模型属于监督学习模型,模型训练和分析需要在包含特征数据和特征数据对应标签的样本集合上进行。中国债券市场由于不存在债券违约概率的日频数据,无法直接用来标记数据。本文采用贝叶斯变分高斯混合模型估计、样本违约概率市场指标估计和概率变动趋势倒推估计这三种估计加权综合的方式来估计日频违约概率,获得的数据标记结合特征数据集形成样本集。
1. 贝叶斯变分高斯混合估计
高斯混合模型(GMM)是一个假设所有样本都生成于有限个带有未知参数的高斯分布所混合的概率模型,包含了数据的协方差结构以及隐高斯模型的中心信息,是K均值聚类算法的扩展。贝叶斯变分推断的优点在于可以自动选择合适的有效分类数量,推断更加稳定且调优简便。
为对应中债评级分类,本文将债券评级分为22类,评级低的代表违约风险较高,评级高的代表违约风险较低。在最大迭代100次的设定下,通过对2677只债券188万条日频的54个特征数据进行贝叶斯变分高斯混合估计,结果显示日频债券评级分级的19级(对应信用评级AA+)和16级(对应信用评级A+)在分类中占比最高,分别达到40.2%和21.8%。同时1级(对应信用评级 D)占比4.0%,也相对较高。这种尖峰厚尾的分布状况,反映了中国信用债总体的信用状况较好, A级及其以上占87.1%,风险较高的 B级占比较低。但一旦出现问题,就会迅速滑向实质性违约(D级)。
图1是信用债估计分级分布和发行分级对比,可看出二者的分布比较接近,总体都呈现尖峰厚尾分布。但发行评级峰度更偏右(数量最多的评级基本上为最高评级),尾部较短,最低评级为BBB+,比重仅占0.08%。这种差异,一方面反映了中国信用债市场的债券信用风险从发行至到期的过程中逐步累积上升,而信用评级逐步下调的过程;另一方面,也说明中国信用债发行评级存在偏高的情况。

图1 中国信用债聚类分级和发行评级比较
虽然采用贝叶斯变分高斯混合聚类方法对中国信用债违约风险的估计总体效果较好,但由于估计的中国信用债违约风险的分布并非正态分布,其估计结果就不是无偏的。另外,估计结果中各分类的数量偏差较大,它表明在具体债券的违约风险的转换是跳跃的,某些违约风险分级预测的时间变动较大(甚至10级以上变动),说明直接单独利用其估计的分类给作为LSTM模型的样本标记是不可行的,有必要结合其他标记方法从而实现稳定、连续、合理的样本标记。
2. 样本违约概率市场指标估计
在市场均衡条件下或没有无风险套利机会的情况下,信用利差实际上包括预期的违约概率信息。通过观测到的信用利差,我们可以估计出无法直接观测到的预期违约概率:
(1)

(2)
即风险资产的期望收益应等于无风险收益。联合式(1)和(2)可得出:
(3)
根据2018年11月5日的违约数据,光大证券(20)光大证券研究报告:《2018年债券违约事件全梳理——债券违约专题研究(3)》(张旭)。计算出违约债券的整体回收率为30.37%,其中,国有企业占55.13%,私营企业占24.18%。中金公司(21)2018年中金证券研究报告:《中国信用债违约后处置全回顾》(雷文斓、许艳、姬江帆)。统计分析了2017年底前违约的公司债券,加权平均回收率为31.2%,其中,国有企业占47.2%,非国有企业占26.2%。根据iFinD的统计数据,本文估计违约金额为353.57亿元,已支付196.65亿元,还款率为11.05%。综合考虑,本文违约回收率采用30%,违约损失率(1-违约回收率)约为常量70%。由于中国债券市场上许多信用债交易不充分,一些债券经常没有交易,其根据交易价格计算的到期收益率和信用利差波动较大,故本文采用5日移动均线来过滤异常波动的影响,同时对据此计算出的违约概率估计值的偏低和偏高值加以过滤:
(4)
(5)
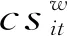
3. 概率变动趋势倒推估计
前述两种方法估计的债券违约概率的共同缺点是波动大、稳定性不足。虽然滤波或移动平均等方法可消除过度波动,但会带来反应滞后和不能反映违约概率变动机制的缺点。利用违约债券和到期债券的违约和到期信息估计信用债违约概率,能够更加合理地反映信用债违约概率的变动特性。因此,根据违约或到期两类债券违约日或到期日以及发行时评级的信息,可以采用倒推法来分析其上市期间的违约概率变动趋势,结合前述方法获得综合违约概率估计。
利用违约信息估计:对于违约债券,其违约日的违约概率达到最大,即100%。在违约日之前,虽然各种信息已经反映该债券将违约(由于债券违约对发债主体的负面影响是巨大的,许多可能违约的发债主体仍然尝试采用各种方法去避免违约),但未形成实质性违约之前,仍存在不确定性。因此,我们可以假设其违约概率在违约日之前遵循一定的分布变动,可根据这种分布来估计其变动趋势。这种趋势是违约债券共同的变动趋势估计,而前面使用贝叶斯变分高斯混合模型和信用价差模型估计的违约概率是每一只债券特有的变动形态估计,所以对于每只违约债券,结合违约类型债券违约概率变动的共同特点和其自身的动态特点,就能够得到较好的样本数据标记。
根据对违约债券已有信用评级的演变趋势分析,大部分违约债的违约概率在前期是比较稳定的,而后期则呈现加速上升的态势,至违约时达到100%。如表1所示,违约债135680.SH(22)135680.SH为债券代码,下同。的违约率变化特征反映了样本中大部分违约债的违约概率变化情况,少量样本体现为136520.SH类似的违约概率变化特征。考虑上述因素,本文采用如式(6)描述违约概率的时间变化特征。

表1 违约债信用评级和违约概率估计示例
资料来源:同花顺iFinD,违约概率为根据笔者计算的信用评级与违约概率对照表估算。

(6)
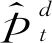
利用到期信息估计:到期债券的违约风险已不再具有不确定性,它们在到期日前没有违约,也不会再违约。2019年9月30日统计到期的5,542只到期债券中,从AA级以上调低到C级的债券有31只,占0.56%,调低到B级的有15只,占0.27%。调低1~2级的占40%左右,维持不变的占50%以上,调升1级的占5%~6%。到期债券的平均违约概率变动在5%~10%之间。据此,我们可以根据债券到期前的最新评级,确定该到期债券违约概率的变动区间,并采用插值法确定其变动趋势。其计算公式为:
(7)

4. 债券违约概率标记
本文采用加权平均的方法将以上三种方法估计的债券违约概率集合为综合违约概率估计,从而能够同时反映债券违约的个体特性和整体特性:
(8)
本文设定wgmm=0.3、wcs=0.3、ws=0.4,经过上述机制获得的部分示例违约债券违约概率标记和到期债券违约概率标记如图2所示。从中可见加权平均违约概率估计既反映了违约债券违约概率变动的一般趋势,又反映了不同债券违约概率自身演变的特点,是在已有数据条件下的一个较优估计,也是作为本文建立的神经网络债券违约概率预测模型训练和验证样本标注的适当指标。

图2 违约债(上)和到期债(下)违约概率估计示例
(四) 特征数据处理和选择

根据经典债务违约理论,债务违约风险是由于债务人不能按期偿还债务而给债权人带来资产损失的风险。影响债务违约的因素,包括债务人自身的财务状况和外部经济、金融环境等因素。参考Golbayani et al.(25)P.G olbayani, I.Florescu, R.Chatterjee, “A Comparative Study of Forecasting Corporate Credit Ratings Using Neural Networks, Support Vector Machines, and Decision Trees,” The North American Journal of Economics and Finance 54(2020): 101251.选取标准并同时考虑数据可获得性,初选指标池包括债券发行公司的财务指标、债券市场指标、债券评级指标、宏观经济环境指标、行业景气指标、地区经济景气指标共六类。
1. 特征预测能力筛选
违约风险模型的预测能力是本文关注的重点,所以首先采用SFI、MDA和MDI三个分析方法结合的方式筛选具有较强预测贡献的特征。各方法在评价特征的样本外预测能力、样本内解释能力,以及特征间的替代效应、排列效应和组合效应等方面各有侧重(26)M.Lopez de Prado, Advances in Financial Machine Learning (John Wiley & Sons, 2018): 113-127.,综合上述方法可以得到较为完备的针对非线性模型的特征筛选结论。本文选取三种方法中表现在均值以上的特征作为形成特征集的来源,我们发现公司财务状况和宏观经济因素在SFI和MDA中占比较高,而资本市场和宏观经济因素在MDI中占比较高。整体上看,如速动比率、利润率、利润水平等反映企业短中期偿债能力和经营能力的指标,以及 PPI、 GDP、物流行业等反映总体宏观和行业运行状况的指标,还有到期收益率等反映资本市场风险定价的指标,对违约概率有相对较优的预测能力。将上述指标取并集,我们得到特征集Fnk=42;同时因为MDA和MDI分析方法都会受到特征间的替代效应影响,从而导致两种方法选取的特征集合在并集之后可能引入特征间的相关性,但SFI则不受替代效应的影响,因此我们将MDA和MDI取交集,再和SFI取并集,得到特征集Fnk=32。
2. 特征稳定性筛选
深度学习网络同样会因多重共线性的存在而影响模型稳定性,考虑到初选指标池中财务等指标的线性相关性较高,本文直接使用方差膨胀因子来衡量和去除高共线性的特征。采用VIF=5的阈值,得到特征集Fnk=29、Fnk=21和Fnk=15这另外三个特征集。为评价违约概率和各特征集的线性关系,本文对6组特征对应样本进行了施加控制效应量为0.35(对应大效应量)(27)J. Cohen, “Things I Have Learned(so Far),” American Psychologist 45(1990): 1304-12.的抽样线性回归。结果表明, GDP、宏观经济景气先行指数、产权比率、营运周期、债券分类违约概率、剩余期限、风险价差等变量在不同值水平(1%、5%、10%)下显著,说明这些变量和违约概率之间的线性解释关系较强;其余变量尽管在线性模型中不显著,但不代表其不具备非线性预测能力,需要在 LSTM模型和对照模型评价时进一步分析。我们通过线性和非线性方法对特征进行了筛选和检验,保证建模使用的样本数据具备线性和非线性的预测性、解释性以及稳定性。
(五) 模型构建
本文债券违约风险预测模型的构建分两个层次:第一层次,利用训练好的模型预测债券违约概率,以此表示债券违约风险预测;第二层次,根据违约概率与信用评级的关系,将债券违约预测转换为债券信用评级。模型违约概率预测是连续的,是模型信用评级调整的依据。信用评级的输出,有利于与债券市场的债券信用评级相衔接和比较,便于投资者使用,同时也避免了违约概率的小幅波动、频繁变动对投资者信心的过度影响。
1. LSTM网络
具有时间或顺序先后关系的序列数据在深度学习领域一般通过循环神经网络(RNN)处理。LSTM是一类特殊的 RNN模型,引入了自循环结构来解决RNN模型无法有效传递历史信息的问题(28)I.Goodfellow, Y.Bengio, A.Courville, Deep Learning(MIT Press, 2016): 373-422.,而历史信息是时间依赖类型问题的一个重要特征和信息来源。 LSTM的内部信息循环分别通过“门”(gate)控制,包括遗忘门、输入门、输出门,即包含概率值的向量,用以控制经变换后的输入状态传递的多少。同时单元之间除隐藏层的状态需传递之外,另外还存在一个单元状态的信息传递。 LSTM单元的信息输入和输出大致可分为五个步骤:(1)遗忘门决定需要遗忘的旧信息的多少;(2)输入门决定需要保留的新信息的多少;(3)更新可传递的单元状态;(4)输出门决定经过单元状态更新输出的信息的多少;(5)更新可传递的隐藏层状态。通过以上设定,循环神经网络的梯度消失及爆炸问题得到了较好解决(29)S.Hochreiter and J.Schmidhuber, “Long Short- Term Memory,” Neural Computation 9(1997): 1735-1780.,可以用来构建具有较大深度的网络以适应金融大数据的特性和建模需求。
2. 模型设计
根据LSTM网络的序列预测性质,本文的预测理论模型可表达为(30)角标trn表示训练集,tst表示测试集。:
(9)
tstcit=T(tstpit)
(10)
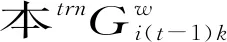
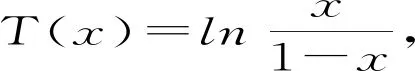
四、 违约概率预测模型训练
根据前文对模型特征数据的处理,我们将对六组样本集Snk=j∈{54,42,32,29,21,15}建立LSTM模型并进行训练结果评价。
(一) 样本集设计和数据处理
本文采用2014年1月至2019年9月的2579只债券的数据,债券品种包括信用债中的公司债、企业债、中期票据、短期融资券,债券类型包括到期和违约两类。选择违约债券样本是因为它们是估计违约概率的最好样本,但由于违约样本数量有限,加上许多违约债缺乏财务数据甚至市场交易数据,并不能完全使用,所以本文增加选择评级在 A以下的债券样本,以增加信用风险较高的样本数量。选择到期债券作为样本,则是因为中国信用债中大多数债券是非违约债券,但在到期前存在较大的不确定性,而到期债券没有违约则已经没有不确定性。这对于训练模型中的非违约样本的标注有利。排除交易数据、财务报表等数据缺乏的债券,最后选择样本为2579只债券,其中违约债141只、 A以下债券74只、到期债券2364只。
因为上述数据包括截面和时序维度,本文按照截面即债券组内根据窗口参数w(本文采用10天)构造维度为i×t×k的三维张量样本。同时,LSTM对时序数据进行建模。划分样本集时需要考虑时间先后关系,否则可能造成信息泄露,导致模型预测能力虚增。在构造训练集、验证集和测试集时,我们仍然在组内按照时间顺序根据80%的比例构造数据集,即样本内和样本外按照80%比例切分;样本内也按照80%比例切分为训练集和验证集,样本外部分作为测试集。然后将上述三组数据分别合并形成训练、验证和测试集。由于数据本身性质,到期债券数量在样本中占比较大,导致违约集中在某些类别上,从而造成模型训练和预测偏差。本文在不损失占比较高的到期债券数据的情况下,使用SMOTE(33)N.V.Chawla, K.W.Bowyer, L.O.Hall, et al., “SMOTE: Synthetic Minority over- Sampling Technique,” Journal of Artificial Intelligence Research 16 (2002): 321-357.上采样方法对训练集的不同违约评级类别的数据进行重采样,使所有类别数据量和占比与最高类别的样本量保持一致,最大限度保留了可获得信息。经过上述处理,我们获得了样本量分别为4,502,832、179,361和230,635的训练集、验证集和测试集样本。
(二) 模型训练

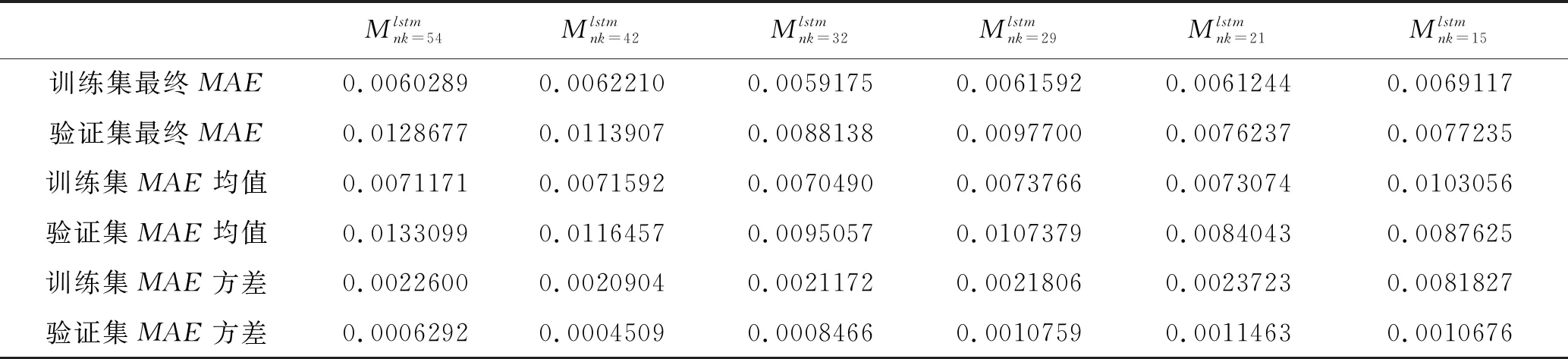
表2 模型训练过程评价指标
五、 模型预测与评价
(一) 模型预测
为保证样本数据间不存在信息泄露而导致模型有效性降低,本文按照前述方法将样本划分为训练集、验证集和测试集三个部分,其中模型训练使用训练和验证集,模型预测和评价在测试集上执行。值得注意的是,本文仅对训练集进行了平衡性处理,即模型预测表现可以反映模型设定和训练的有效性,因为训练集和测试集的数据分布完全不同。模型预测结果如表3所示:
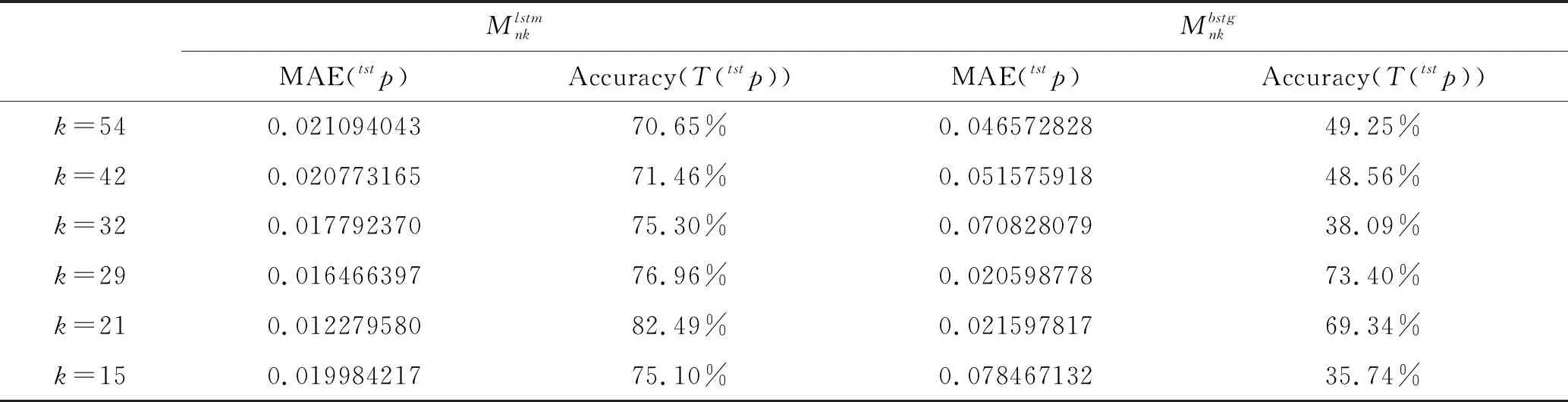
表3 模型预测结果



从各特征集来看,两类模型在k=29和k=21均有较好表现。两个特征集包含:与货币政策联系紧密的CPI、GDP、社会融资规模等指标;体现行业和区域违约情况的债券分类违约概率、区域违约概率等指标;财务类指标则包含体现盈利能力的营业利润率和销售净利率、体现资产负债结构的非流动资产和负债、体现短期偿债能力的流动比率、体现资本结构的有形净值债务率,以及授信余额率、担保授信比等授信指标和成交量等市场指标。由此可以看出,经济增速、行业地域性风险,以及企业的盈利能力、资产负债结构、资本结构和短期流动性是模型解释和预测违约风险的主要考虑方向。
(二) 预测结果评价
本文研究目标信用债的日频违约概率在现实中没有具体数据估计,本文采用贝叶斯变分高斯混合估计法、市场指标法和违约概率倒推法这三种方法综合的方式对违约概率进行估计,并以此作为 LSTM模型的训练目标以形成样本集。本文选择目前市场具有权威性的中债市场隐含评级——债券债项评级数据进行对照分析,以验证违约概率和评级数据估计的合理性以及模型预测结果的合理性。中债市场隐含评级——债券债项评级是中债估值中心从市场价格信号和发行主体披露信息等因素中提炼出的、动态反映市场投资者对债券的信用评价,是目前市场债券评级最全面、调整最及时、在中国信用债市场具有权威影响力的评级。因此,与其比较具有重要意义。本文估计的违约概率标记经转换获得的违约评级数据和中债评级数据的相关性为60.2%,说明违约概率评级和中债评级具有较强的相关性。由于现实中评级持续虚高情况的存在,本文的违约概率评级可能较好地反映了违约概率变化的细节特征,从而体现本文预测结果的意义。

图3 信用债违约概率和评级预测与中债评级对比示例
从结果可看出:(1)本文模型预测的评级结果与中债评级总体趋势和变动一致,说明预测评级能够较好地体现信用债违约的概率水平和评级;(2)预测评级体现的评级调整基本上先于中债评级变动,说明预测模型能够体现其预测能力,如在违约(101759003.IB)和到期单次上调(1380067.IB)中预测评级首次连续下调(上调)早于中债评级首次连续下调(上调)约3个月时间;(3)预测评级水平整体低于中债评级水平,在现实中评级可能存在偏高的情况下,本文的预测评级可能更符合实际;(4)违约概率预测相较违约概率标记在样本内和样本外均体现出较好的预测拟合程度,与该模型82.49%预测准确性吻合,但也存在部分预测在样本外与标记变动总体趋势相符但细节区别较大的情况,如到期连续下调(101767004.IB)和到期不变(122152.SH)中所示,从而可能导致预测评级存在短期受预测概率变化而引起的非必要调整,类似情况可以通过对评级概率进行过滤或引入其他模型结构和数据结构以提高预测有效性;(5)某些持续较长时间的违约概率变化并未在中债评级中体现,如到期单次下调(122181.SH)中,在2018年5月至2018年11月,根据本文估计方法该债券的违约概率约有15%的上升和回落,这可能是由于该发行人在此期间公告流动性补充计划,导致违约概率上升后又因半年报盈利高速增长,从而导致违约概率回落。该种结构因素在中债评级中未体现,但在本文模型中得到刻画。整体测试集预测评级、标记评级和中债评级的数据统计如表4所示:
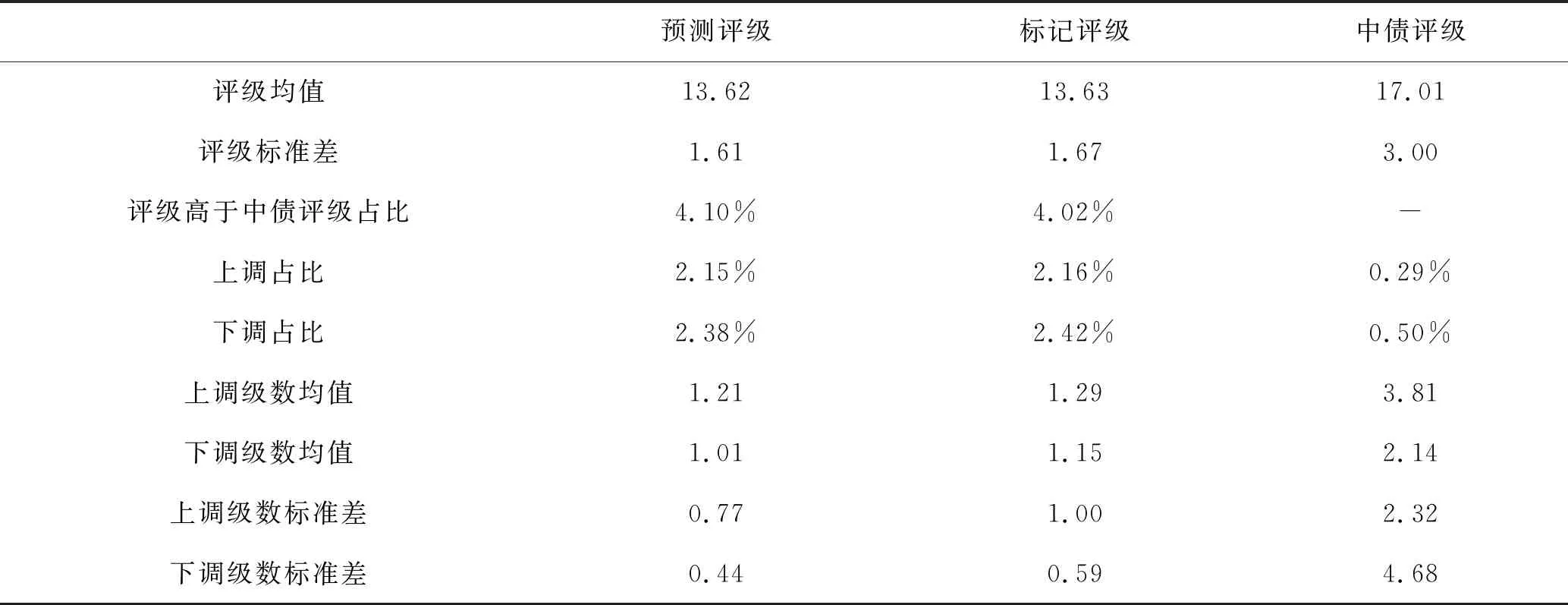
表4 预测评级、标记评级和中债评级对比
预测评级和标记评级比中债评级平均低3级左右,仅有约4%的样本评级高于中债评级。本文模型的评级调整相对中债评级更加频繁,约2%的样本存在预测或标记的评级改变,同时调整方向相对中债评级更加对称,中债评级下调占比明显高于上调占比。另外,中债评级调整的大小和变动范围大于本文标记和预测的评级。在上述数据中,可看出中债评级较高,其调整频率较低,但一旦调整,上调或下调的力度会较大;而本文的违约概率标记和预测结果则以相对更高的频率来调整与更新评级,同时调整幅度也较小。如前文所述,更加频繁的调整,一部分原因是由于模型捕捉到了影响因素的结构变化,另一部分原因可能是由于模型或数据对于噪音的敏感性所致,这可以通过进一步提升模型和改善数据结构来予以避免。
六、 结论及启示
自2014年中国债券市场刚性兑付终结后,信用债违约数量和规模逐步增加。从近期违约主体的违约原因来看,往往是多方因素共同导致突发性违约事件的发生,包括由于宏观及外部因素冲击导致的经营层面问题、投资扩张激进而盈利能力未能显著提升的投资层面问题、公司资产负债结构长期失衡而导致的融资层面问题,以及内控薄弱而引起的实控人侵害公司利益和内外部信息不对称等管理层面问题。
本文的违约风险预测分析的信息来源涵盖了宏观、行业、地域、主体以及市场等多个方面,较为有效地获取了上述问题产生的内在相关因素,并以对面板类海量数据具备良好分析性质的LSTM神经网络深度学习模型为基础,通过合理的样本数据标记以及指标筛选方式使得预测模型具备较好的泛化能力。如于2020年11月违约的永城短融,通过本文模型采用的具备较强解释能力的特征数据来源,如资产净利率、负债总额、筹资活动现金流、GDP增速、到期收益率、剩余期限和风险价差等变量的变化过程,可看出主体在一季度已经出现了较为明显的经营乏力问题,在受疫情影响导致的宏观经济增速下降逐步传导的过程中,能源需求乏力引起的公司营收下降、融资活动活跃以及行业风险上升的现象在2020年下半年开始进一步显现,因而在违约前夕剩余期限、风险价差以及到期收益率等市场变量在风险揭示中的作用提升,整个过程充分反映了本文构拟的方法对其风险演化轨迹的成功捕捉。其核心原因在于:有效信息不能及时、全面和真实披露,从而造成发行人和投资人间的信息不对称,以及发行人付费评级机制造成的评级虚高。在不完全信息的债券市场发展过程中,本文利用可获取的结构化数据,结合LSTM深度学习模型,试图从“大数据”中获得具有预测性的信用债券违约概率和评级数据,从而使投资人能够更加及时、准确地了解信用债的违约概率,进而防范风险。
本文首先采用贝叶斯变分高斯混合估计法、市场指标估计法和违约概率变动趋势倒推估计法这三种方法结合的方式对数据进行标记,以获得能够同时反映债券个体违约风险变动特性和债券市场整体违约风险特征的违约概率估计。然后采用单特征重要性、平均准确率减小、平均不纯度减小以及线性分析这四种方法对六大类指标进行筛选,获得了六个不同特征集,其数据解释能力各有不同。根据使用所得违约概率估计和特征集组合而成的样本集,本文提出了与其数据性质和数据量相匹配的 LSTM模型结构并进行训练和预测,发现使用包含经济增速、行业地域性风险,以及企业的盈利能力、资产负债结构、资本结构和短期流动性特征训练的模型其预测违约评级达到了样本外82.49%的对于金融数据而言较高的准确率。通过上述研究过程,发现本文信用债违约概率和评级的预测结果与目前国内债券市场最全面和及时的中债市场隐含评级——债券债项评级的评级结果总体相当;本文模型的评级结果平均水平略低,波动性大于中债隐含评级,充分验证了我国信用债评级虚高以及跟踪评级未能有效反映发行人信用结构性变化的现实情况。
本文的研究对信用债违约风险研究具有一定的参考意义。首先,在信用债发行人包含大量非上市公司且因债券市场缺乏大量违约样本而无法使用KMV等传统风险计量模型的前提下,本文针对普通投资者可获取的信息范畴提出了信用债日频违约概率的估计量和估计方法,可以作为信用债违约概率和评级估计的参考。其次,本文提出并检验了通过非线性和线性相结合以发现有效预测变量的方式,对于使用高维金融数据进行预测模型的构建之指标筛选过程有一定的启示。再次,本文发现,利用“大数据”学习的 LSTM模型在模型设定合理、数据构造得当的前提下可以获得较好的表现,对于拓展信用债违约风险研究方法提供了思路。最后,通过纳入更多非结构化的“大数据”,可拓展基本 LSTM模型结构,通过集成模型等方式实现更优的信用债违约概率测度。
鉴于评级机构和发行人的利益相关关系、可分析信息有效性的不确定性、风险产生和表征的复杂性,以及传统评级类型的风险发现功能的局限性,监管机构应进一步完善信息披露机制、市场发行机制和约束条款,从而保证在有效信息环境中实现市场发行定价的效率;同时,评级机构不仅需要进一步提高其评级的独立性和客观性,也需要提高其评级的准确性,及时地向市场投资者警示风险,从而避免高评级债项的突然违约对市场的较大冲击。此外,中国信用债市场需要构建更加多元的违约风险分担机制和再融资机制,化解已违约债券对市场和投资者的不良影响,避免债券在短期内集中违约风险对债券市场融资功能带来的实质性冲击;对投资者而言,则应更充分地关注和分析风险积累和演变的过程以及风险揭示贡献因素大小的时变性特点,从而实现及时、有效的风险监控;对于发行人来说,应该不断提高公司治理能力,更加注重在运营、投融资以及抵御外部冲击等企业内在能力方面的提升。
