电网多源大数据融合方法的研究与应用*
2021-05-21覃松涛黄超田君杨杨彦韦
覃松涛黄 超田君杨杨 彦韦 恒
(广西电网电力调度控制中心,广西南宁 530023)
随着智能电网的发展和普及应用,电力系统已经进入了大数据时代,由于大电网中含有大量的不相关以及冗余信息,严重降低了关键信息的主导作用,容易导致系统决策出现偏差[1-3]。目前已有的硬件设施和控制技术无法实现对电网大数据的有效分析和精准控制,因此,需要对电网大量冗余数据进行融合及删减[4-6]。
国外内研究学者在电网大数据处理方面展开了大量的研究工作。王德文等[7]提出了一种基于Storm 的状态监测数据流滑动窗口处理方法,通过采集系统节点监听数据源变化并实时收集数据,利用消息订阅模式对数据进行缓冲,既保证了数据的连续计算,又能够满足大电网异常状态检测与用电数据分析等快速处理需要;曲朝阳等[8]提出了一种基于云计算技术的电力大数据预处理属性约简方法,通过剖析粗糙集中相对正域理论的特性,利用MapReduce 模型构建了MP_POSRS 属性约简算法,计算出正域中元素个数,实现对电力大数据预处理属性的约简化处理;孙超等[9]基于混合数据采集模型和采集集群,提出了一种实现异构数据源采集任务的混合调度和管理方法,通过数据置信度标签技术,实现了对原始数据的保留并对数据质量进行标识,能够为后续大数据分析应用提供了便利;叶康等[10]通过引入数据标签技术对数据物理表进行梳理,将业务专家的经验与数据物理表结构融合,实现对数据信息进行高度精炼,方便机器或人对数据的识别。该方法具有指标口径一致、节省计算资源、便于全局优化的特点,能够大幅提高电网监控业务智能化水平;黄彦浩等[11]、彭小圣等[12]分析了大数据、云计算、电力系统三者间关系,给出具有通用性的电力大数据平台总体架构,并从电力大数据的集成管理技术、数据分析技术、数据处理技术、数据展现技术等方面深入探讨符合电力企业发展需求的大数据关键技术的选择。
现有研究充分利用了大数据有效信息,对降低电网大数据的冗余性具有一定参考意义,但所用理论及算法复杂,操作难度较大。为此,对电网大数据的基本特性及现有研究策略进行深入研究,探究来自不同数据源同一对象数据的关联性,充分利用现有大数据资源,提出了一种基于映射的电网大数据融合方法,以实现降低电网大数据冗余度的研究目的。
1 电网大数据的基本特性
大数据是一个庞大而复杂的数据集,具有不同的数据结构,如:非结构化、半结构化和结构化等等,不能在给定的时间内用传统方法进行处理、存储、管理和分析[13]。如图1 所示,电网大数据具有4 项基本特性,分别是:规模性(Volume)、多样性(Variety)、高速性(Velocity)以及有价值性(Value),又称为4 V 特性[14]。
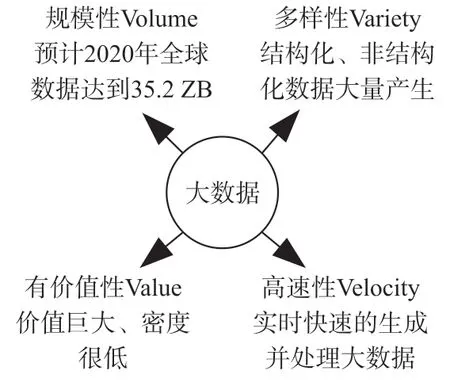
图1 大数据的四项基本特性
(1)规模性:随着电力系统规模的不断扩大,在发电、变电、输电、配电和用电等各个环节产生大量信息数据,将使得电网存储数据容量的级别逐步从PB 向EP 飞跃。
(2)多样性:随着电力系统信息化建设的飞速发展,相比于传统电力系统的单一化信息数据,电网大数据结构及其表现形式开始变得多样化,如:视频、文本、图像等。
(3)高速性:由于电力系统大数据流存在实时性、易失性、无序性等基本特性,且数据之间的关联性错综复杂。因此,需要对电力系统生产、运行期间所产生的数据做出高效处理,以满足电网对电力调度、负荷预测以及故障诊断等问题的快速性要求。
(4)价值大密度低:在海量的监测或检测的数据中隐含着大量的信息。对其进行挖掘分析可以提供给生产、运行、管理、用户等有价值的信息。这些数据不仅仅反映电力行业内部的信息,而且关系到整个经济社会的情况,对国家的经济宏观调控、资源的合理利用、减少污染。大数据中隐藏着巨大经济以及社会价值。
2 电网大数据的融合
2.1 数据融合的层次
电网大数据融合的过程是对数据进行多级处理的过程,包括对数据进行采样、提取、筛选以及合并等等,都是对原始信息的抽象化处理。根据数据处理过程中的抽象化程度,将数据融合又分为:像素级融合、特征级融合以及决策级融合,如图2 所示。
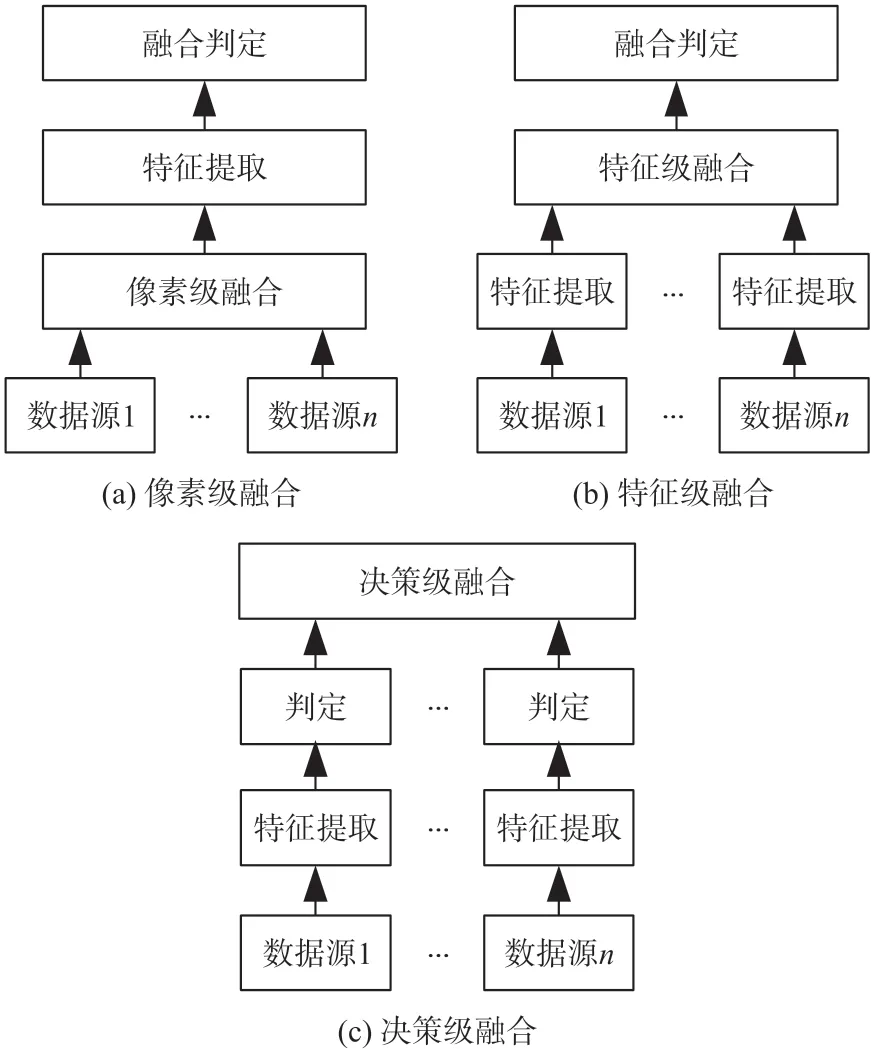
图2 数据融合的不同层次
3 种数据融合层次的优缺点如表1 所示,可以看出:像素级融合,其输入数据为所有的原始数据,信息覆盖面广,但信息处理的计算耗时巨大,通信量大且抗干扰能力差,所以应当对原始数据做预处理。特征级融合,由于其输入数据是经过处理得到的特征向量,仅保留了有需要的重要数据,不可避免地会存在数据流失的情况,造成准确精度下降。决策级融合,在特征级融合的基础上,决策级融合综合了各个数据源的决策信息,具有容错率高、抗扰性强、适应性高以及通信量小的优点,但数据前期处理的花费高且信息损失量大。由此来看,特征级融合是像素级融合和决策级融合的综合。
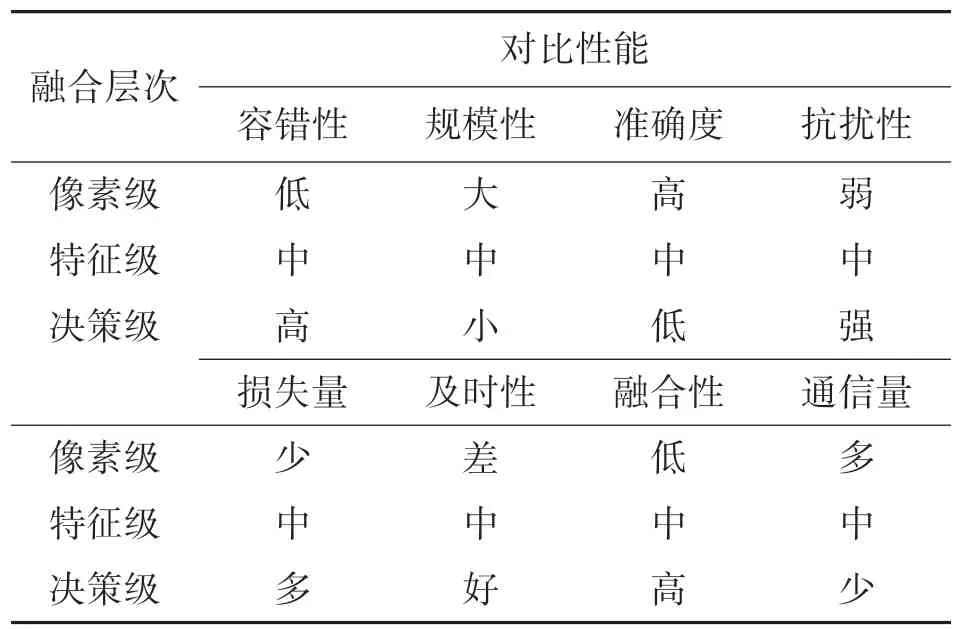
表1 不同融合层次的性能对比
2.2 数据融合的总体框架
大电网中存在许多存储电气设备相关信息的数据源系统,如:广域相量测量系统(Wide Area Measurement System,WAMS)、数据采集与监视控制系统(Supervisory Control And Data Acquisition,SCADA)
以及保护故障信息管理系统(Management System of Relay Protection,RPMS)等,这些电力系统的生产调度、诊断监测系统中的数据具有相互独立且结构各异,数据大量分散、冗余的特点,使得有效信息不能充分挖掘。因此,需要引入信息融合的方法,对电网大数据进行分析、挖掘、提取、融合等一系列操作,从不同层面对大电网数据进行高效化处理,降低电网数据冗余度、提高信息决策的精准性,为电网的信息预测、故障诊断等提供有效辅助决策。
电网大数据融合的总体框架如图3 所示,以SCADA、RPMS、WAMS 等数据源系统提供的基础设备信息作为数据层融合的原始数据输入,经处理后输出特征层需要的输入特征数据,再以特征层融合后的特征数据作为输入,经过处理后输出得到决策,实现以少量的数据信息反映大部分特征的融合目标。
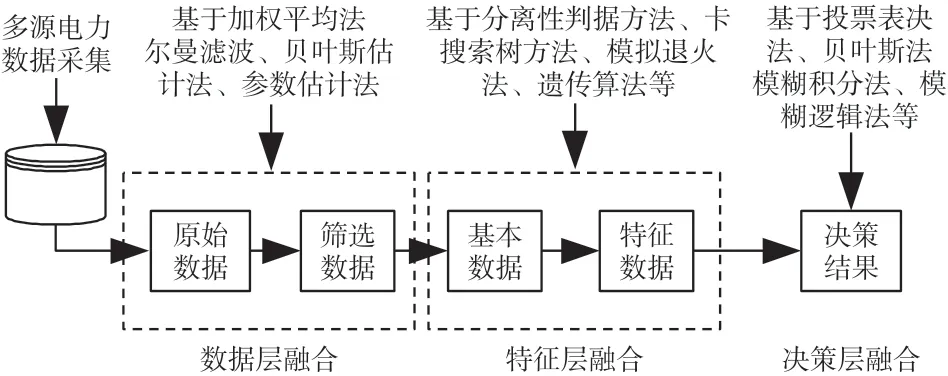
图3 电网大数据融合的总体框架
3 基于映射的多源数据融合方法
如图4 所示,将数据融合当做是原始数据向成熟数据转变的一个映射过程。定义映射F:X→Y,X为原始数据集,Y 融合后的数据集,映射F 为数据融合过程,其具体步骤如下:
步骤1 对不同数据源的信息进行规范化处理;
步骤2 提取各个数据源的特征向量;
步骤3 对各个数据源的特征向量进行检验后进行数据融合,求取综合特征向量。
步骤4 根据求解得到的综合特征向量,再经过还原得到融合后的数据。

图4 基于映射的数据融合方法
本研究主要对具有不同数据源信息的同一对象数据融合方法进行。不同数据源其所存储的设备数据内容各不相同,需要对不同数据源信息进行融合,以实现多源数据的交互与转化,并降低数据的冗余度[15]。通过文章2.2 小节的介绍可知,宜采取特征级融合策略对来自不同数据源的同一对象数据进行融合。
如图5 所示,对来自不同数据源的数据进行特征向量的提取,特征提取是一个信息采集与压缩的过程,每一个数据源都要与之对应的唯一的特征向量Hi(i=1,…,n),且这唯一的特征向量能够充分反映该数据源的重要信息。对这些特征向量进行标准化运算、数据校核修正、融合判断等一系列处理后,求得该研究对象的的标准特征向量H,即能反应该电气设备数据融合后的基本属性。需要说明的是,在特征向量的提取和融合过程中,应遵循以下原则:

图5 特征向量的提取
首先进行数据的校验,若各个特征向量同一基本属性均有内容且不完全相同时,需对该特征向量进行数据校验,若发现数据错误,则进行校正;若数据无误,则进行以下操作步骤:
(1)若各个特征向量具有相重叠的基本属性,则仅保留一份该特征向量对应的数据信息即可;
(2)若各个特征向量同一基本属性不完全相同时,则按照完善程度、优先级别等特性来进行选择,如:更新后的数据信息优先级别高于更新前的数据信息;
(3)若某一特征向量具备其他特征向量没有的基本属性,则保留该特征向量具备的这一基本属性。
4 算例验证
本小节以某220 kV 变电站为例,选取来自生产管理系统(Production Management System,PMS)以及调度自动化系统OMS 2 种不同数据源的变电站数据的数据融合具体过程,以检验本文所提数据融合方法的实用性,各数据源提供的基础数据如表2以及表3 所示。

表2 PMS 中变电站的基本信息

表3 OMS 中变电站的基本信息
从表2、表3 所提供的原始数据来看,对于同一变电站,不同数据源所提供的数据信息既有互相重复的部分,又有相互补充的部分。即使是同一个基本属性,2 种不同数据源的表述方式都各不相同,因此需要对表中的原始数据进行规范化处理,使得变电站基本属性的描述规范,单位统一,数据精度一致,即对数据进行清洗。生产管理系统以及调度自动化系统经规范化处理后得到的数据如表4、表5 所示。

表4 规范化数据处理后的PMS 数据
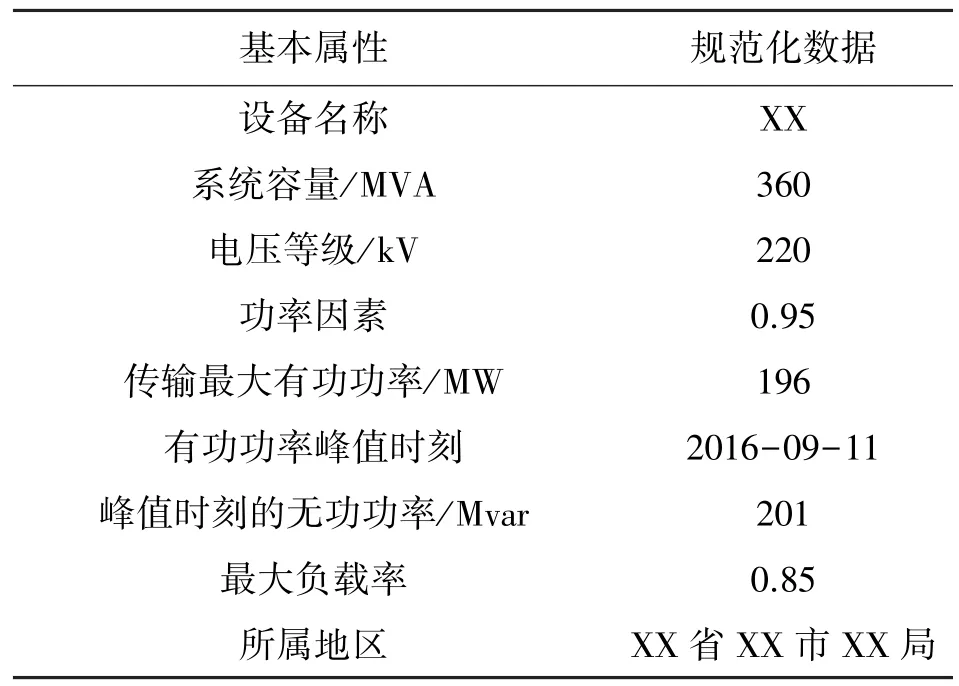
表5 规范化预处理后的OMS 数据
在对数据进行规范化处理后,根据电网业务需要对变电站基本属性提取基本特征向量。基本特征向量的维度可以是一维或是多维,其所包含的数据类型较广,有:字符串、数字等等,当变电站缺失某一基本属性时,其所对应基本特征向量的那一项为0。对该变电站提取基本特征向量列于表6 中,由于该变电站的数据信息较为简单,因此用一维向量即可清晰展示其基本属性。
从表6 中可以看出,特征向量A1是表4 中的“设备所处地理位置”和表5 中的“所属地区”这同一属性规范化后的融合描述结果;还新增了特征向量A18这终期基本属性,使得变电站运行数据库信息更加全面完善,其余特征向量均是表4 和表5 已有基本属性的规范化融合结果。

表6 变电站的基本特征向量
基于表6 所给出的基本特征向量模式,求取PMS 数据的特征向量H1以及OMS 数据的特征向量H2,各特征向量的具体数值为:
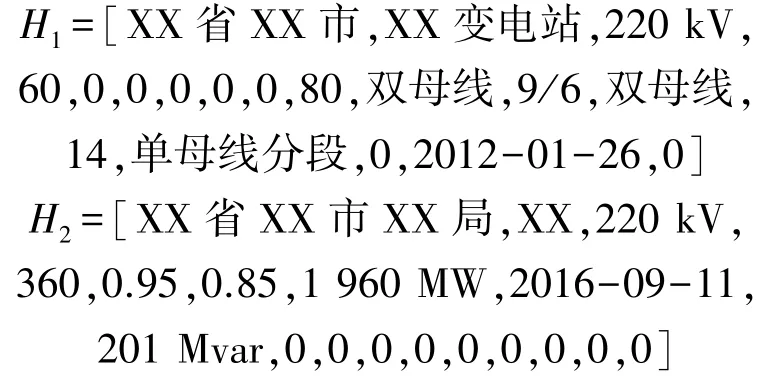
首先,对H1和H22 个特征向量各基本属性进行校验,可以看到对于所属地区和系统容量这2 个基本属性,2 个特征向量均有数据但存储内容不完全相同,经检验后确认H1、H2特征向量的所属地区属性的相关数据无误,仅完善程度不同;而对于系统容量这一基本属性,由工作人员进行核实后证实H1特征向量的该基本属性存在错误,予以更正为360。对于得到校验更正后的特征向量H1、H2为:
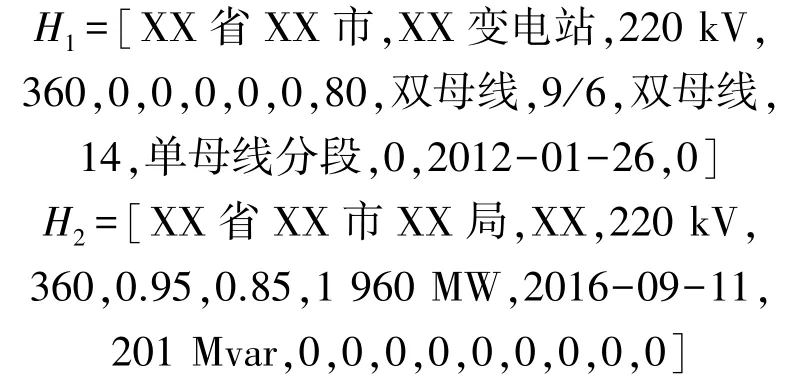
接着,按照本文所提数据融合规则,对特征向量H1、H2求取综合特征向量H为:

最后,以表6 为基准对综合特征向量H做数据还原,还原结果如表7 所示。
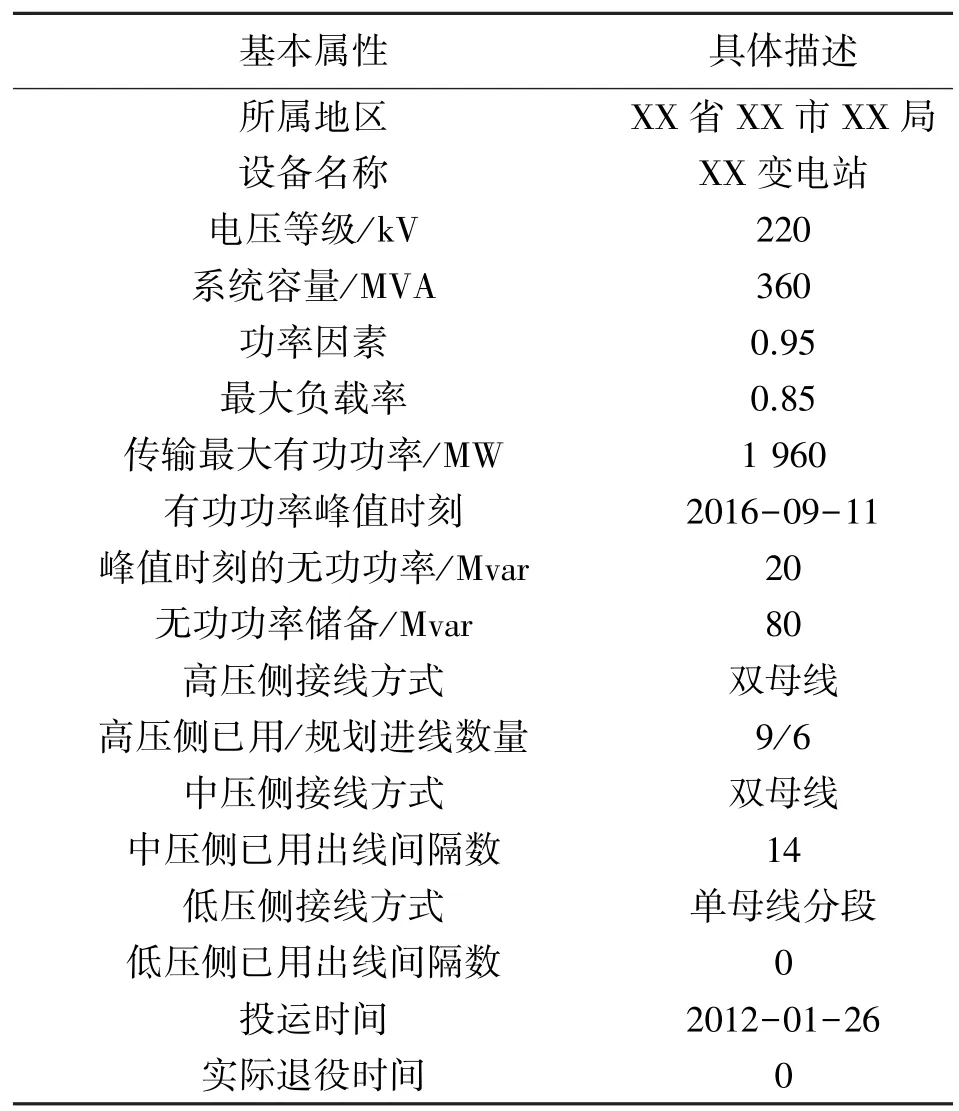
表7 数据融合后的变电站数据
将表7 融合后的数据与表2、表3 的原始数据对比可知,变电站经过数据融合后的信息更加综合、系统、规范,融合后的基本属性含概了所有数据源的基本属性,剔除了各个数据源基本属性中重复冗余的部分,且每个基本属性描述更加规范统一完善。
5 结论
提出了一种基于映射的数据融合方法,通过对来自不同数据源的基本数据属性进行规范化处理、提取特征向量、求取综合特征向量、特征向量还原等操作。从数据融合的结果来看,该方法不仅能够全面反馈各个数据源的重要属性,而且能够降低多源数据的冗余度,融合后的数据信息更加规范、系统、全面,证明了所提数据融合方法对电网数据处理的实用性。
