基于K-Medoide聚类的黑客画像预警模型
2021-05-20廖光忠
洪 飞,廖光忠
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430081;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430081)
0 引 言
网络技术的快速发展[1]带来了新的安全挑战,网络安全是网络空间中正常运行的基石,通过数据挖掘方法从大量的安全日志数据中分析研究黑客的攻击行为及其画像成为当下研究热点。一方面在网络日志分析上取得一定的成果,其中李刚等设计了一套基于日志分析的电力网络安全预警系统[2],张胜等指出了现有日志分析存在的问题,并改进了分析方法[3],王琴琴等通过恶意代码的传播日志发现分区后Mirai网络中域名资源具有明显的差异性和相似性[4],赵春晔等提出一种基于用户行为日志分析的云安全审计解决方案[5]。另一方面用户画像技术也在众多领域取得了不俗的成果,主要应用于社交视频领域以及推荐系统等方面,通过分析各个群体之间的特征,以达到商业营销或科研的目的。尽管用户画像在许多领域已经有了较为成熟的应用与实践,但是在分析黑客行为上的研究成果仍相当有限。
因此本文通过对安全日志数据进行数据挖掘和特征分析,提取合适维度构建黑客画像,使用K-Means算法改进后的K-Means++算法和K-Medoide算法进行聚类,选取合适的算法和簇数构建黑客群体画像,同时分析每个簇的主要特征,并根据攻击手段给出相应的预防措施,最后设计一套基于黑客群体画像的预警模型,以此针对网络攻击事件提供可行性预防建议。
1 基于黑客画像的安全预警模型设计
常见的网络安全预警模型是基于策略型的预警模型,通过对网络攻击数据进行处理分析,提取攻击特征,分析攻击手段,评估威胁程度,匹配相应的响应模块,输出预警策略,如图1所示。
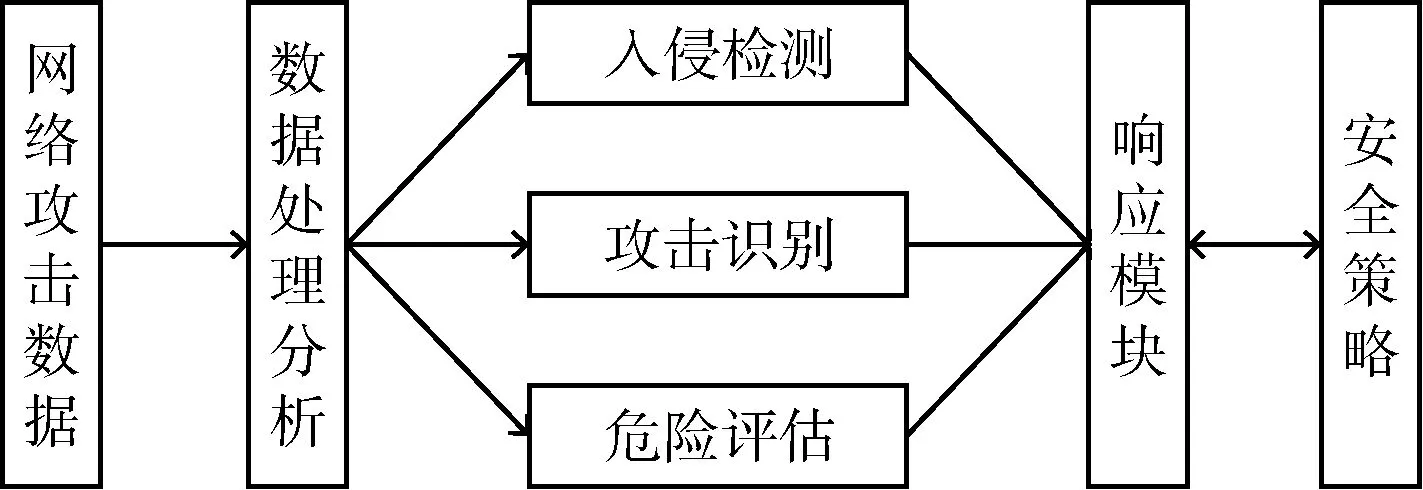
图1 网络安全预警模型
其网络安全预警模型,主要是针对网络安全事件本身的特征进行分析,并没有充分考虑到网络攻击行为背后黑客的具体特征对我们预警策略的影响。
本文主要是基于黑客群体画像构建网络安全预警模型,该模型是通过分析黑客的具体特征来进行预警,它是现有网络安全预警模型的一个很好的补充,对完善预警策略具有一定意义,图2为模型的具体结构。

图2 预警模型
(1)黑客群体画像的构建是在黑客画像的基础上面聚类得到的,黑客画像是通过分析武汉军运会期间某网站的130 497条安全日志数据,从中提取出攻击者IP共1628个,然后以攻击者IP为主键,将每个攻击事件的攻击时间、攻击目标、攻击行为记录到同样以攻击者IP为主键的表中,选择每个攻击者IP主要的攻击时间段、攻击目标、攻击手段构成黑客画像,然后对黑客画像进行数据的归一化处理和聚类分析,将其分成若干个簇,构建黑客群体画像,逐个分析每个簇的主要特征,然后根据每个簇的攻击方式,给出预防手段。
(2)攻击事件画像是通过对网络攻击事件进行攻击时间段标签、攻击目标标签、攻击手段标签进行提取得到的。
(3)工作流程:网络攻击事件出现时,通过提取事件的时间维度、攻击目标维度以及攻击手段维度,构建攻击事件画像,然后让攻击事件画像与安全日志数据构成的黑客群体画像中的每个簇的中心点进行相似度的计算,判断该攻击事件属于哪一个簇,输出这个簇的主要攻击时间、攻击目标、攻击手段以及响应措施。
通过此模型可以更加全面、高效应对网络安全事件,提高系统的安全性能。
构建上述模型主要的难点是黑客画像维度特征的获取以及黑客群体画像聚类算法的选择,由于本文的数据集是基于网络安全日志数据,因此本文将以网络攻击事件中的攻击者IP为主键,提取每个攻击事件中的攻击时间段、攻击目标以及攻击方式,构成黑客画像的攻击时间维度、攻击目标维度和攻击方式维度。对于聚类算法的选择,本文使用K-Means算法改进后的K-Means++算法和K-Medoide算法分别对黑客画像进行聚类,通过轮廓系数法判断聚类效果,从而选取合适的算法与簇的个数构建黑客群体画像。
2 黑客画像的构建
本节主要内容是构建基于安全日志数据的黑客群体画像,其内容主要分为3个步骤:数据的采集和处理、黑客画像构建、黑客群体画像构建。
2.1 数据的采集和处理
本文是通过syslog日志系统来采集安全设备的相关日志数据的,数据集是军运会期间,9月15日到11月5日某网站被攻击的安全日志信息,一共130 497条攻击记录,其中攻击者IP个数1628个,攻击方式一共12种,对于部分数据存在奇异值或者缺失的情况,需要根据实际情况对数据进行补全或者删除,日志数据整理后结构见表1。

表1 日志数据结构
2.2 黑客画像构建
在大数据时代背景下,用户画像可以理解成是海量数据的标签化,通过提取用户的网络行为特征,形成特定的标签,从而构成一个人在网络空间上的虚拟画像。用户画像是用户建模的直观体现,分为定量画像和定性画像两种,定性画像包括基本属性特征、兴趣偏好特征以及网络行为特征等,定量画像则是一系列可量化的数据特征,同时用户画像的构建需要满足特定的业务需求,因此用户画像构建时的侧重点有所不同,例如在电子商务领域用户画像侧重于顾客的消费习惯,而本文则侧重于黑客行为中的攻击时间、攻击目标和攻击手段。
将预处理后的安全日志数据导入数据库Statistic表中,同时建立时间段表(Time)、攻击目标表(Attack)、攻击手段表(Means)以及汇总表(End)。其中汇总表的属性包括ID、攻击者IP(ip)、主要攻击时间段(time)、主要攻击目标IP(attack)和主要攻击方式(means)。
2.2.1 时间特征维度的提取
通过观察Statistic表中的数据,将攻击事件按照攻击时间进行归类,统计攻击者的攻击时间,将一天划分为8个时间段,其中0点和24点表示同一点,见表2。

表2 攻击时间段
SQL语句连接Statistic表和Time表,按顺序选择 Statistic表中的一条数据,当这条数据对应的攻击者IP与Time表中的攻击者IP相等时,那么这条数据处于哪个时间段就将Time表中相同IP对应时间段下的数据加1。
2.2.2 攻击目标维度的提取
通过分析Statistic表中的数据,将攻击事件按照攻击目标进行归类,统计攻击者的攻击目标,本数据集中黑客的攻击目标主要是5个门户网站,见表3。

表3 攻击目标网站
SQL语句连接Statistic和Attack表,按顺序选择 Statistic表中的一条数据,当这条数据对应的攻击者IP与Attack表中的攻击者IP相等时,那么这条数据的攻击目标是什么就将Attack表中相同IP对应的攻击目标下的数据加1。
2.2.3 攻击方式维度的提取
通过观察Statistic表中的数据,将攻击事件按照攻击方式进行归类,统计攻击者的攻击方式,一共发现了12种攻击方式,表4列出了8种主要攻击方式。

表4 攻击方式
SQL语句连接Statistic表和Means表, 按顺序选择 Statistic表中的一条数据,当这条数据对应的攻击者IP与Means表中的攻击者IP相等时,那么这条数据的攻击手段是什么就将Means表中相同IP对应的攻击手段下的数据加1。
2.2.4 黑客画像
将Time表、Attack表和Means表中的数据以攻击者IP为唯一标识,把数据导入End表中,对于3个表中一个攻击者IP对应多个数据的现象,我们取其中的最大值,例如:Time表中一个攻击者IP有两个时间段都存在值,其中time_1的值为100,time_2的值为10,那么在相同攻击者IP情况下,End表中time的值就是time_1,以攻击次数最多的时间段代表此攻击者IP的攻击时间段特征,同理Attack表和Means表中的数据也按照这样的规则填入End表的attack和means属性中,如表5所示部分数据。

表5 单用户画像
2.3 黑客群体画像的构建
黑客群体画像是在黑客画像基础上通过聚类得到的,本节主要包括4个部分:数据的规范化、相似度计算公式、聚类算法步骤、评估算法。其中数据规范化使用的序列类型规范化公式,相似度算法采用的是欧式距离来计算相似度,由于本文的数据集是纯数据类型,对于此类数据的用户画像聚类最常用的聚类算法是K-Means算法,其优点包括原理简单、容易实现和解释性较强等,缺点也十分明显,首先是聚类簇数的选择没有明确方法,其次是样本噪音点和异常点对聚类结果影响较大,最后是样本必须是纯数据样本,聚类效果依赖于聚类中心的初始化,对于非凸数据集聚类效果不好,会产生局部最佳。因此本文将使用K-Means++算法和K-Medoide算法对数据集进行聚类,再用轮廓系数法判断聚类效果好坏,最后聚类模型是用准确率进行效果评估。
2.3.1 数据的规范化
本文采用的是序列类型规范化方法,取值具有一定的顺序性,以本文数据集为例,时间段可以分为8类,攻击目标网站可以分成5类,攻击方式可以分为12类,从而转化为[0,1]之间的离散型数值,如式(1)所示
x=(2i-1)/2n
(1)
根据式(1),当n为5时的规范化值分别是0.1000、0.3000、0.5000、0.7000以及0.9000,因此得到表6。
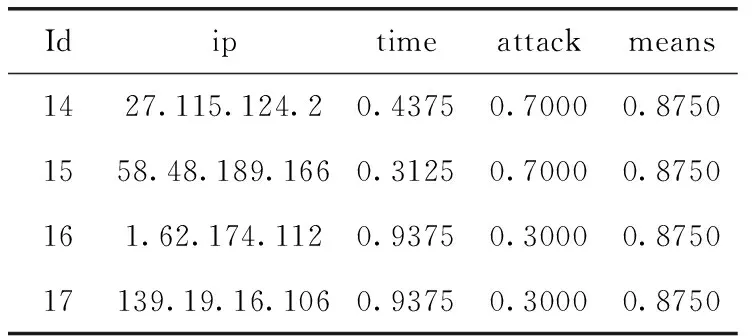
表6 用户画像数据规范化
2.3.2 相似度计算
常见的距离算法有很多,其中包括欧几里得距离(Euclidean distance)、曼哈顿距离(Manhattan distance)和切比雪夫距离(Chebyshev distance)等,由于我们已经将数据进行了归一化处理变为纯数据类型,因此本文使用欧几里得距离来计算相似度,如式(2)所示,两个n维数据x和y的距离
(2)
2.3.3 聚类算法步骤
算法1:K-Means++算法的优点是解决了初始化异常的问题,在选择初始中心点时首先选择一个点作为第一个初始簇的中心点,然后通过距离计算选择离该点最远的点作为第二个初始簇的中心点,以此类推,直至选出k个初始中心点。它的步骤如下:①随机选取一个样本作为第一个聚类中心;②计算每个样本(已选为聚类中心的样本除外)与当前已有的聚类中心的距离,这个值越大,表示被选取作为聚类中心的概率较大;③重复步骤②,直到选出k个聚类中心;④计算数据集中每一个样本到已选的k个聚类中心的距离,判断与哪个聚类中心距离最近,该样本便属于这个聚类中心所在的簇;⑤针对每个簇,通过平均值重新计算聚类中心;⑥重复上述④和⑤两个步骤,直到聚类中心趋于稳定不再发生变化。
算法2:K-Medoide算法是在K-Means算法上面进行改进的,主要是解决K-Means算法对噪音和异常点敏感的问题,其与K-Means算法主要的不同集中在聚类中心点的选择上面,K-Means算法是通过计算每个簇中所有样本的平均值,以此作为聚类中心,而K-Medoide算法是在每个簇中依次选取样本,计算每个样本与其同簇中其它样本距离之和,取距离最小的样本作为聚类中心。
2.3.4 评估算法
本文采用轮廓系数法来评估聚类算法的效果,采用准确率来测试预警模型效果。
轮廓系数法的核心指标是轮廓系数(silhouette coefficient),那么某个样本点xi的轮廓系数计算方式如式(3)所示
(3)
其中,a表示xi的凝聚度,是通过计算该样本与其同簇中其它样本距离之和的平均值得到的,b表示xi的分离度,是通过计算该样本与最近簇中所有样本距离之和的平均值得到的。而最近簇的定义是如式(4)所示
(4)
其中,p表示簇ck中的一个样本,计算xi到除其所在簇外其余每个簇中所有样本距离之和的平均值,选择平均值最小的那个簇作为最近簇。
计算所有样本的轮廓系数之和的平均值,平均轮廓系数越大,聚类效果越好,当平均轮廓系数最大时,它的k值便是最佳的聚类簇数。
准确率p用来测试聚类模型的响应效果,其中分子表示正确响应的个数,分母表示测试样本总数,式(5)如下
(5)
3 实验与分析
3.1 实验结果对比
实验1:通过轮廓系数法对K-Means++和K-Medoide算法的聚类效果进行评估,其中k的取值范围为[2,10],X轴为k的取值范围,Y轴是计算的轮廓系数,节点为圆点表示K-Means++算法随着k值的变化所得到的轮廓系数值,节点为三角形表示K-Medoide算法随着k值的变化所得到的轮廓系数值如图3所示。
由图3可知当k取值范围为[2,10],K-Means++算法k为7时轮廓系数值最大,K-Medoide算法k为8时轮廓系数值最大,但是K-Means++算法轮廓系数最大值小于K-Medoide算法轮廓系数最大值,因此就上述两种聚类算法而言,本数据集的聚类算法为K-Medoide算法,聚类簇数为8时效果最佳。

图3 实验结果对比
实验2:取10 000条、30 000条和50 000条测试数据对聚类模型进行测试所得的响应准确率结果见表7。

表7 模型效果
3.2 攻击手段响应表及簇特征与响应手段表
表8为8种主要攻击手段所对应的响应表,表9为每个簇的主要特征及其预防手段,其中预防手段所对应的数字为表8中每个攻击方式所对应的响应手段,例如:簇0预防手段为7,代表着攻击方式为目录穿越时的响应手段。

表8 攻击手段响应

表9 簇特征及其响应手段
3.3 实验小结
本次实验结果表明,当簇数的取值在[2,10]之间时,本数据集使用K-Medoide算法进行聚类效果最好,簇数为8时聚类结果最优,同时给出了主要的攻击方式的预防手段,以及各个簇的主要特征,为预警模型的构造提供了必要的条件,通过50 000条数据进行测试,聚类预警模型的响应准确率达到98.3%以上,验证此模型的可行性较高。
4 结束语
本文通过对军运会期间某网站安全日志数据进行统计分析与数据挖掘,构建黑客画像,通过K-Medoide聚类算法构建黑客群体画像,并以此设计了一套安全预警模型,给出了相应的预防手段,对网站的安全防护有一定的借鉴意义。
当然本文设计的黑客群体画像仍然具有一定的局限性,首先仅仅只是网站的安全日志,无法提炼出更多的维度信息,数据量少,数据的周期短,后续不仅可以结合武汉市军运会期间多个区域安全日志数据一起进行分析,还可以结合外网防火墙、内网防火墙、态势感知数据一起分析,使黑客画像的构建更为全面准确,其次是聚类的效果仍然不是很好,每个簇特征过多,后续可以进行二次聚类,同时与现有的预警模型相结合,以期达到更好的预警效果。
