基于K最近邻回归预测的高能效虚拟机合并
2021-05-20王诺,李艳
王 诺,李 艳
(河北传媒学院 信息管理中心,河北 石家庄 051430)
0 引 言
云数据中心中,动态的虚拟机合并实现了运行时虚拟机在不同主机间的在线迁移[1,2],尤其在主机处于较低负载或超载状态下时,迁移将具有诸多好处。因此,通过迁移操作会使得数据中心内的资源管理更加灵活。然而,虚拟机在线迁移对于运行在虚拟机上的应用任务的性能具有负面影响[3]。由于在云服务提供者与其用户间提供相应的服务质量是至关重要的,所以动态虚拟机合并应该着重考虑优化虚拟机迁移次数。此时的服务质量需求通常以服务等级协议SLA来描述,根据吞吐量或服务的响应时间上的性能表现来定义[4]。
比较已有工作最小化主机利用数量,本文将设计一种启发式算法同步最小化虚拟机迁移次数和SLA违例。所提算法进行动态虚拟机合并主要由两个阶段组成:①尝试将负载最低主机上的所有虚拟机迁移至负载最大主机上;②从当前超载或预测在近期会变为超载的主机上迁移出部分虚拟机以防止可能的SLA违例。同时,提出的算法可以根据当前和未来的资源请求将迁移虚拟机分配至合适主机上。为了预测负载,本文设计了一种基于K最近邻回归KNNR模型的预测方法,对未来资源利用率进行预测,该预测方法优于线性回归方法。为了训练和测试预测模型,本文通过运行IaaS云环境中的多种现实负载生成历史数据集,并通过实验验证了所提动态虚拟机合并算法的有效性。
1 相关工作
动态虚拟机合并可以增加资源利用率和提高数据中心能效,已有很多相关研究。文献[5]提出一种动态服务器迁移和合并算法,在给定负载状态和支持SLA违例的条件下可以降低物理能力的使用量,算法利用了装箱启发式方法和时序预测技术最小化主机利用量。然而,算法并没有考虑新部署中虚拟机迁移次数。文献[6]利用蚁群系统寻找最优解,同步考虑了休眠主机量和迁移次数。文献[7]为了避免性能下降,设置门限值防止主机CPU达到100%占用率,将CPU占用率限定在门限值之内。然而,静态的门限值设置无法处理动态的云负载环境,此时主机上运行的负载类型是多样的。因此,门限值应该针对不同的负载类型作出相应改变,并允许有效的任务合并。文献[8]根据历史数据的静态分析设置了自适应的上下限值,而文献[9]则根据数据中心内不同的应用类型,以最大化资源利用率和负载均衡为目标,提出了新的虚拟机部署算法。
虚拟机合并问题可以形式化为装箱问题,装箱问题即是将若干物品装入有限数量的箱子内,并最小化箱子数量。每台虚拟机可视为一个物品,每台主机即为一个箱子。由于装箱问题的NP难属性,有效求解方法为启发式方法。如:首次适应算法FF将物品放入可容纳该物品的第一个箱子中;最佳适应算法BF将物品放入空间最合适的箱子中。此外,FF和BF算法可进一步改进为降序首次适应算法FFD和降序最佳适应算法BFD。然而,经典的装箱方法并不能直接应用于虚拟机合并问题。原因在于:①虚拟机和主机拥有多个维度资源,如CPU、内存和网络带宽。若考虑CPU和内存资源的约束,虚拟机合并问题就是典型的二维装箱问题;②虚拟机合并问题可修正为可变箱子(主机)大小的装箱问题,不同于经典的等同能力箱子的装箱问题;③经典装箱方法仅最小化箱子数量,即单目标优化。而本文考虑的目标包括虚拟机迁移次数和SLA违例问题。文献[10]设计了BFD的改进算法,可以节省部分能耗。文献[11]利用FFD的改进算法在功耗和迁移代价间取得均衡。文献[12]利用改进的FF和BF算法在未考虑性能下降的情况下最小化主机利用量。然而,以上算法多是考虑优化比较单一的目标,没有在能效和服务性能上作出综合的考量。
本文提出了融合了负载预测机制的改进BFD算法,命名为利用率预测感知的降序最佳适应算法UP-BFD,与已有研究相比具有以下几点优势:①算法可以得到能效和SLA违例间的最优均衡解,实现动态的虚拟机合并;②为了降低虚拟机迁移量,算法可以根据当前和未来的资源需求分配迁移虚拟机至目标主机;③为了降低SLA违例,算法选择从当前超载主机或最近未来会变为超载的主机上迁移部分虚拟机,避免无用虚拟机迁移;④算法利用了K最近邻回归方法对负载进行预测,可以基于历史数据预测主机和虚拟机的CPU占用率,实现了前瞻性的虚拟机合并。
2 问题的提出
虚拟机合并可以优化虚拟机部署,减少活跃主机利用量,这其中需要考虑两个因素:SLA违例率和虚拟机迁移量。基于未来负载预测可以强化两个优化目标。以两个实例描述未作负载预测下传统虚拟机合并方法的局限性。如图1和图2所示,现有2台主机和3台虚拟机的部署需求。如图1(a)所示,Host1和Host2的CPU利用率分别为0.35和0.6。由于Host1拥有足够资源部署虚拟机VM3,传统虚拟机合并将VM3迁移至Host1以减少主机利用量,并将Host2转换为休眠。在时间t+1,VM3的CPU请求从0.6增加至0.75,如图1(b)所示。由于Host1没有VM3请求的空闲能力,Host1出现超载,发生SLA违例。因此VM3迁移至Host2以避免SLA违例,如图1(c)所示,此次即为无用迁移。因此,如果迁移前可以预测资源请求,虚拟机合并就可以避免非必要虚拟机迁移并降低SLA违例。

图1 示例1:未作资源利用率预测
如图2所示,在当前时间t,VM3迁移至Host1,由于Host1拥有足够空闲资源部署VM3,如图2(a)所示。如图2(b)所示,Host2转换为休眠,仅Host1为活跃主机。由于VM2的请求CPU利用率增加,此时出现热点主机。VM3迁移至之前的目标主机以避免SLA违例,如图2(c)所示。因此,若虚拟机合并算法可以根据主机的未来资源占用率情况对虚拟机进行迁移分配,将极大减少迁移次数和SLA违例。

图2 示例2:作资源利用率预测
3 系统模型
动态虚拟机合并可以形式化为装箱模型,是NP问题。由于装箱问题仅能在给定物品下最小化箱子数量,直接应用于虚拟机合并中拥有一定局限性。很多算法也以装箱思路求解过虚拟机合并问题。然而,这会产生过多的非必要虚拟机迁移,增加SLA违例风险。虚拟化是云计算数据中心的主要技术,利用虚拟化技术可以在物理服务器上部署多个不同性能的虚拟机,以提高整体的资源利用率。虚拟化的一个主要优势是在数据中心内可以进行动态的虚拟机合并来降低能耗,通过将虚拟机合并到更少数量的物理主机上,并将闲置主机转换为睡眠模式以提升能效。图3是虚拟机合并与迁移系统模型。云数据中心由M台异构主机构成,可通过虚拟机监视器VMM部署N台虚拟机。每台主机拥有不同的资源属性,包括CPU、内存和网络带宽。在给定的时间,数据中心可服务于多个同步的用户需求。用户通过虚拟机请求方式发送需求,每个需求的长度以百万指令数MI描述,CPU性能以每秒百万指令数MIPS描述。模型包括两个代理Agent:一个是主节点上的全局代理GA(global agent),一个是主机上分布的本地代理LA(local agent)。所提出的动态虚拟机合并算法每次迭代中的任务处理次序如下:

图3 系统模型
(1)每个LA监测主机的资源利用率,并利用K最近邻回归预测主机短期的CPU利用率;
(2)GA收集LA的利用率数据,利用UP-BFD算法建立迁移计划(算法详细设计中描述);
(3)GA发送迁移指令至VMM,执行虚拟机合并任务。该指令指定了虚拟机的迁移目标主机;
(4)在接收GA的迁移指令后,VMM执行实际的虚拟机迁移。
4 UP-BFD算法的详细设计
4.1 符号说明
初始时,虚拟机通过传统的BFD算法将虚拟机分配至主机上。BFD算法首先根据资源利用率请求的降序序列将所有虚拟机进行排序,然后选择每个虚拟机分配至一个主机上,使得主机拥有最少的剩余空闲能力。由于虚拟机的资源利用率会随着时间发生变化,即动态负载,初始的虚拟机部署需要周期性地通过虚拟机合并算法进行不断修正。为了实现该目的,本文设计了利用率预测感知的降序最佳适应算法UP-BFD,可以根据当前和未来的资源请求,优化虚拟机部署。为了方便算法设计的描述,表1给出相关参数说明。

表1 参数说明
4.2 负载计算与约束说明
为了降低数据中心能耗,UP-BFD算法通过释放冷点的方式将最低负载主机(冷点)上的虚拟机迁移至负载最高主机(热点)上。如果最冷点主机上的所有虚拟机无法迁移至其它主机上,则全部都不迁移。因此,未释放冷点上的虚拟机迁移并不会实施,这样可以消除不必要的虚拟机迁移。由于将一台虚拟机分配至主机需要确定的主机资源量,有效的虚拟机合并算法必须感知资源维度,这意味着资源利用比例(CPU和内存资源)在决定虚拟机部署过程中就需要在每台主机上予以确定。由于主机的CPU和内存能力是表示负载等级的主要因素,本文的算法也主要考虑CPU和内存利用率两个资源维度。将主机负载定义为每个资源维度的总利用率,即
Lh=RCPU(h)+RMEM(h)
(1)
(2)
(3)
其中,RCPU(h) 定义为主机h上已经分配的CPU能力 (UCPU(h)) 除以主机的总体CPU能力 (CCPU(h)),RMEM(h)
定义为主机h上已经分配的内存能力 (UMEM(h)) 除以主机的总体内存能力 (CMEM(h))。
UP-BFD算法能够决定主机上的哪些虚拟机需要迁移至其它主机上,算法会选择主机上所有虚拟机中最高负载的虚拟机作为迁移目标,由于负载越大的虚拟机越难以插入至其它主机上。虚拟机v的负载Lv定义为
Lv=RCPU(v)+RMEM(v)
(4)
(5)
(6)
其中,RCPU(v) 和RMEM(v) 分别表示虚拟机v的CPU和内存利用率,UCPU(v) 和UMEM(v) 分别表示虚拟机v请求的CPU和内存利用率,CCPU(u) 和CMEM(v) 分别表示虚拟机的总体CPU和内存能力。
为了寻找迁移虚拟机的目标主机,UP-BFD算法使用两种约束避免SLA违例和非必要的迁移。第一个约束是:若主机hd拥有足够的资源部署虚拟机,则可允许虚拟机v迁移至主机hd。由于某些资源利用率可能达到100%而引起SLA违例的风险,算法引入门限值T限制主机上虚拟机的CPU资源请求量。因此,第一个约束条件可表示为
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(7)
第二个约束确保目标主机hd在虚拟机v迁移过来后不会变为短期可能的超载主机。考虑该原因,UP-BFD算法考虑了主机和虚拟机的未来CPU请求。UP-BFD算法利用K最近邻回归方法对CPU利用率进行预测,详细过程见4.3节说明。由于负载的动态变化,UP-BFD算法将侧重于短期的负载预测,以下资源能力约束用于将虚拟机v分配至主机h上
PUCPU(hd)+PUCPU(v)≤T×CCPU(hd)
(8)
其中,PUCPU(hd) 表示主机hd的预测CPU利用率,PUCPU(v) 表示虚拟机v的预测CPU利用率。主机和虚拟机的预测CPU利用率限制在总体能力的门限值以内。如果T=0.5,则表示主机hd和虚拟机的总体预测利用率不能超过总体能力的50%。因此,基于以上两个约束条件,算法在选择目标主机时,需要该主机在当前时刻以及未来均拥有足够的可用资源。
此外,UP-BFD算法还需要从超载和可预测超载主机上迁移部分虚拟机以降低SLA违例。如果当前CPU利用率超过主机能力,则该主机可视为超载主机集合Hover中的成员。因此,部分虚拟机需要从该超载主机上迁移至其它主机以降低SLA违例可能。此外,UP-BFD算法可以根据主机的预测CPU利用率预测到主机何时会成为超载主机。若预测利用率大于可用CPU能力,则该主机可视为预测超载主机集合Hover’中的成员。因此,部分虚拟机也需要从预测超载主机上迁移出去以降低SLA违例。
4.3 基于K最近邻回归的负载预测
负载预测过程分为两个步骤:第一步是确定近邻样本的最优k值;第二步是基于最优k值和样本数据对CPU利用率进行预测。算法1给出最优k值的求解过程。算法输入m个样本的历史利用率数据集X,对于每一个可能的k值(步骤(3)),先将该k值的预测损失值初始化为0,即步骤(4)。然后,遍历m个样本数据(步骤(5)),数据集中所选样本作为测试样本,剩余样本用于训练数据集,即步骤(6)~步骤(7)。然后,调用算法2,基于当前的k值、测试样本和训练数据集,预测在当前测试样本下的利用率,即步骤(8)。预测准确度通过每个k值的损失值的总和进行评估,即步骤(9)。遍历所有可能k值和所有样本,拥有最小损失值的k值被选择为k最近邻回归模型的最优k值,如步骤(12)。最后,可以在步骤(13)~步骤(14)根据所选最优k个最近邻样本预测最终的资源利用率。
算法1: KNN-UP算法
(1)Input:datasetXwithmsamples
(2)Output:predictedUtil
(3)fork=1 tomdo
(4)loss[k]←0
(5)fori=1 tomdo
(6)TestSample←xi//选取测试样本
(7)TrainingDataset←X-{xi}//选取训练样本
(8)yi’←KNN(TestSample,TrainingDataset,k)
(9)loss[k]←loss[k]+power((yi’-yi),2)
(10)endfor
(11)endfor
(12)kbest←argminkloss[k]//得到最优k值
(13)predictedUtil←KNN(currentUtil(host),kbest)
(14)returnpredictedUtil
算法2的目标是根据当前已有的训练数据集、当前k个最近邻数据和样本序列预测下一个CPU利用率,算法总共分3步进行。第一步计算样本xq与训练集中其它所有样本间的欧氏距离,即步骤(3)~步骤(8),第二步选择样本xq的k个最近邻数据,即步骤(10)~步骤(12),最后第三步通过计算其k个最近邻的均值估算CPU资源利用率,即步骤(13)~步骤(17)。
算法2: KNN算法
(1)Input:query-samplexq, training dataset, number of nearest neighborsk
(2)Output:the label of samplexq(y’)
(3)forj=1 tomdo//步骤(1)
(4)distance[j] ←0
(5)fori=1 tondo
(6)distance[j]←distance[j]+(xqi-xji)2
(7)endfor
(8)distance[j]←sqrt(distance[j])
(9)//sort distance array
(10)fori=1 tokdo//步骤(2)
(11)nearestSet[i]=distance[i]
(12)endfor
(13)sum←0//步骤(3)
(14)forallz∈nearestSetdo
(15)sum←sum+yz
(16)y’ ←sum/k
(17)returny’
4.4 UP-BFD算法过程
算法3给出了UP-BFD算法实现的详细过程,由两个阶段组成:①尝试从最低负载主机上迁移所有虚拟机,并关闭该主机以节省能耗;②从超载和预测超载主机上迁移部分虚拟机以降低SLA违例。在第一个阶段中,即步骤(2) ~步骤(21),步骤(2)根据负载等级的降序对主机进行排序,并将排序后的主机存入列表H中。UP-BFD算法将H中最后一个主机(最低负载主机)考虑为源主机hs(步骤(3)),迁移其上所有虚拟机并释放hs。为了选择从主机hs上需要迁移的第一个虚拟机,算法将主机hs上的所有虚拟机根据负载降序进行排列,并将排列后的虚拟机存入列表Vm中(步骤(4))。为了寻找迁移虚拟机的合适目标主机,UP-BFD算法从H中除了源主机hs以外的第一个主机(拥有最高的负载)依次扫描,直到找到第一个能满足迁移需求的主机为止,即步骤(5)~步骤(7)。UP-BFD算法选择目标主机hd需要满足在当前和短期未来迁移虚拟机的资源请求,即步骤(8)。最后,新的虚拟机部署被添加至迁移决策M,即步骤(9)。迁移计划为一个三元组 (hs;v;hd),hs为源主机,v为迁移虚拟机,hd为目标主机。步骤(10)对源和目标主机的已经利用CPU利用率进行更新,以反映出迁移后的结果。变量success用于检测是否源主机上的所有虚拟机已被迁移。仅在所有虚拟机能够迁移的情况下才作出迁移决策,否则不作迁移。因此,如果success为失效,算法将移出迁移计划中的所有元组元素并恢复源主机和目标主机的CPU能力,即步骤(16)~步骤(18)所示;否则,源主机上的所有虚拟机迁移后,该主机将转换为休眠,不再部署任何虚拟机,即步骤(20)。
在第二个阶段,步骤(22)~步骤(40)中,算法首先遍历超载和预测超载主机列表,步骤(23)~步骤(24)根据负载等级的降序对主机上的虚拟机进行排列,并开始迁移请求最大能力的虚拟机。当前CPU利用率或预测CPU利用率超过主机总体能力时,虚拟机v需要迁移至其它主机,即步骤(25)。然后,算法基于两个约束条件寻找迁移虚拟机v的目标主机,即步骤(27)。最后,新的虚拟机部署被添加至迁移计划M中,即步骤(28)。如果算法在所有活跃主机中无法找到部署迁移虚拟机的目标主机,则重新开启一台休眠主机,即步骤(33)~步骤(35)。UP-BFD算法的输出为迁移计划M,GA将发送迁移计划指令至虚拟机监视器VMM执行具体虚拟机迁移。
算法3: UP-BFD算法
(1)M=NULL
(2)H←sort all hosts in descending loadLh
(3)hs←last host inH
(4)Vm←sort VMs on hosthsin descending loadLv
(5)forv∈Vmdo
(6)success=false
(7)forhd∈H-hsdo
(8)if(UCPU(hd)+UCPU(v)≤T×CCPU(hd)) and (PUCPU(hd)+PUCPU(v)≤T×CCPU(hd))then
(9)M=M∪{(hs,v,hd)}
(10) updateUCPU(hs) andUCPU(hd)
(11)success=true
(12)break
(13)endif
(14)endfor
(15)endfor
(16)ifsuccess=falsethen
(17)M=NULL
(18) recoverUCPU(hs) andUCPU(hd)
(19)else
(20) switchhsto the sleep mode
(21)endif
(22)forhs∈[Hover,Hover’]do
(23)Vm←sort VMs on hosthsin descending loadLv
(24)forv∈Vmdo
(25)if((UCPU(hs)≥CCPU(hs))‖(PUCPU(hs)≥CCPU(hs))then
(26)forhd∈H-[Hover,Hover’]do
(27)if(UCPU(hd)+UCPU(v)≤T×CCPU(hd)) and (PUCPU(hd)+PUCPU(v)≤T×CCPU(hd))then
(28)M=M∪{(hs,v,hd)}
(29) updateUCPU(hs) andUCPU(hd)
(30)break
(31)endif
(32)endfor
(33)if((UCPU(h)≥CCPU(h))‖(PUCPU(h)≥CCPU(h))then
(34) switch on a dormant host
(35)endif
(36)else
(37)break
(38)endif
(39)endfor
(40)endfor
5 性能评估
5.1 实验环境
为了评估动态虚拟机合并算法UP-BFD的性能,利用仿真平台CloudSim[13]实现了高能效的虚拟机合并算法。仿真环境中,构建由800台异构主机组成的云数据中心,选择平台支持的具有代表性的两种主机配置:HP ProLiant ML110 G4(Intel Xeon 3040,2cores×1860 MHz,4 GB)和HP ProLiant ML110 G5(Intel Xeon 3075,2cores×2660 MHz,4 GB)。每台服务器主机的网络带宽设置为1 GB/s。虚拟机数量由负载类型决定,实验中测试了两种类型负载:随机型负载和现实负载。随机型负载中,用户发送800个异构虚拟机请求,每台虚拟机运行一种应用负载,应用负载对于CPU的占用服从均匀分布。现实负载中,选择CoMon工程项目中一个时间段内的负载数据,见表2,该数据由PlanetLab平台[14]监测得到。监测数据中,CPU利用率数据是从多于一千台虚拟机上每隔5 min监测得到的结果。虚拟机部署于全球超过500个地理位置,这也是较为典型的Amazon EC2式的基础设施云服务环境下的负载类型。

表2 现实负载的虚拟机请求量
5.2 评估指标及时间复杂度分析
(1)SLA违例SLAV指标。SLAV是一种独立的负载指标,用于评估虚拟机部署中SLA的交付情况。SLAV包括主机超载导致的SLA违例SLAVO和由于迁移导致的SLA违例SLAVM。对于云环境中的虚拟机合并问题而言,两种SLA违例具有同等的重要性,因此,综合的SLA违例指标可考虑为两个参数的乘积,表示为
SLAV=SLAVO×SLAVM
(9)
其中,SLAVO表示活跃主机经历CPU利用率100%所占的时间比例,表示为
(10)
其中,M表示主机数量,Tsi表示主机i经历的CPU利用率100%(导致SLA违例)的总时间,Tai表示主机i活跃状态的总时间。
SLAVM表示由迁移导致的虚拟机性能下降,度量为
(11)
其中,N表示虚拟机数量,Cdj表示由于迁移导致的虚拟机j性能下降的估算,Crj表示整个周期中虚拟机j的总CPU请求量。
(2)能耗指标。该指标表示数据中心中物理主机执行负载消耗的总体能耗。主机能耗取决于CPU、内存、存储及网络带宽的利用率。研究表明,相比其它资源类型,CPU消耗了最多能源。因此,简化能耗模型后,主机能耗可表示为其CPU利用率的关系式。实验中根据SPECpower试验床[15]中现实的功耗数据。表3给出了在不同的负载条件下两类主机HP G4和HP G5的功耗情况。

表3 不同负载条件下主机的功耗/W
(3)虚拟机迁移量。在线虚拟机迁移涉及在源主机上的CPU处理、源和目标主机间的链路带宽以及迁移时的服务停机、迁移时间等多重代价,因此,虚拟机合并过程中需要最小化虚拟机迁移量。
算法时间复杂度分析。UP-BFD算法的实现由两个阶段构成,第一阶段尝试从最低负载主机上迁移所有虚拟机,第二阶段从超载和预测超载主机上迁移部分虚拟机。假设M为主机数量,N为虚拟机数量。第一阶段最差情况下需要遍历所有主机上的所有虚拟机,故其时间复杂度为O(M×N)。 第二阶段同样需要遍历超载和预测超载主机上的虚拟机,预测超载过程利用K最近邻回归预测方法KNN,而此时KNN的最差时间复杂度为O(M×N)。 综上,UP-BFD算法的时间复杂度为O(M×N+M×N)=O(M×N)。
5.3 比较基准
完成以下启发式算法与本文的虚拟机动态合并算法UP-BFD进行对比分析:
(1)改进降序最佳适应算法MBFD。该算法利用一个门限值限定目标主机的CPU利用率,在虚拟机和主机所利用的总CPU能力不超过总体CPU能力的情况下,部署迁移虚拟机至拥有最小剩余能力的主机上,即
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(12)
(2)改进降序首次适应算法MFFD。该算法将迁移虚拟机分配至满足资源需求且不超过CPU能力约束的第一台主机上,即
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(13)
(3)主机资源利用率预测的降序最佳适应算法HUP-BFD。该算法通过K最近邻回归预测了主机的资源请求。算法利用预测模型和门限值T限定主机利用率。若预测主机利用率与虚拟机请求的CPU利用率不超过总的CPU利用率,则将虚拟机v迁移至目标主机hd,即
PUCPU(hd)+UCPU(v)≤T×CCPU(hd)
(14)
(4)虚拟机资源利用率预测的降序最佳适应算法VMUP-BFD。该算法通过K最近邻回归预测虚拟机的资源请求。若主机CPU利用率与预测虚拟机请求CPU利用率不超过总CPU利用率,则将虚拟机v迁移至主机hd,即
UCPU(hd)+PUCPU(v)≤T×CCPU(hd)
(15)
5.4 结果分析
第一个实验中,通过均匀分布的随机负载进行实验。较高的CPU利用率门限值会导致较高的性能下降和虚拟机迁移量,而较低的门限值会导致更高的能耗。因此,为了考虑多个指标系数间的均衡优化,需要寻找一个合适的门限值。实验中设置门限值在50%-100%之间以观察资源利用门限值对于性能指标的影响。图4是在不同的门限值下,5种算法的SLA违例情况。UP-BFD算法比其它算法可以有效降低SLA违例比率,这是由于算法会将迁移虚拟机重新部署至短期未来不会变为超载的主机上,而不是仅考虑主机当前时刻不是超载,这说明K最近邻回归预测是有效可行的。此外,UP-BFD算法可以从当前超载和预测超载主机上进行虚拟机迁移,前瞻性地避免了SLA违例机会。图5显示本文提出的UP-BFD算法能够比其它算法总体降低约28%的能耗,这是由于该算法可以通过将虚拟机装箱至高负载主机上的方式最小化活跃主机数量,进而优化了能耗。图6显示了随机负载条件下虚拟机合并过程中出现的虚拟机迁移量。UP-BFD算法由于更好的资源利用预测,比对比算法更好减少了虚拟机迁移量。
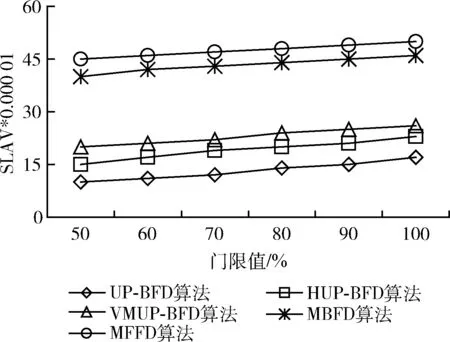
图4 随机负载下的SLA违例

图5 随机负载下的能耗

图6 随机负载下的虚拟机迁移量
第二个实验运行现实负载对算法性能进行评估。实验中每台虚拟机上随机分配一个负载流。图7显示UP-BFD算法比4种对比算法具有更低的SLA违例,这是由于UP-BFD算法通过主机和虚拟机的资源利用预测可以防止SLA的违例,确保了迁移的目标主机在虚拟机迁移后不会再次变为超载主机。图8显示UP-BFD算法在现实负载下比其它算法也节省了更多的能耗,这是由于该算法通过装箱虚拟机至更少量主机上,并释放了最低载主机,降低了能耗。同样地,在图9中,本文的UP-BFD算法也拥有最少的虚拟机迁移量,这是由于算法可以根据未来的资源利用率将迁移虚拟机进行重新部署,而大大降低了目标主机最次出现超载的概率,带来不必要迁移的可能。

图7 现实负载下的SLA违例

图8 现实负载下的能耗

图9 现实负载下的虚拟机迁移量
综合两个实验结果来看,本文算法在实现虚拟机合并过程中较好实现了能耗与SLA违例间的均衡。同时,若门限值取值较大,虚拟机迁移量和SLA违例会有所提高,但UP-BFD算法在门限值接近于100%时仍然完成了更好的能耗节省。
6 结束语
云数据中心中,动态的虚拟机合并和迁移虽然可以有效降低能耗和提高资源利用率。然而,若仅考虑当前资源利用率会带来许多非必要的虚拟机迁移,增加SLA违例风险。提出了一种动态的虚拟机合并算法,算法可以通过K最近邻回归方法预测主机和虚拟机的资源利用率,从而减少非必要的虚拟机迁移,并降低SLA违例风险。在虚拟机迁移选择上,算法可以通过预测模型从当前的超载和预测超载主机上进行虚拟机迁移。通过大规模的仿真实验对比,验证所提算法不仅可以降低主机能耗,还可以同步最小化SLA违例和虚拟机迁移量。
