基于CWMD和SP的微博话题发现算法
2021-05-20方梁雨
孙 悦,罗 倩,方梁雨
(北京信息科技大学 信息与通信工程学院,北京 100192)
0 引言
2020年新浪微博第一季度财报数据显示,截至 2020 年 5月,微博的月活跃用户已达5.50亿,同比呈增长趋势。微博发布的信息往往具有时效性短、动态性强和结构不规范等特点[1]。从大量的文本数据中发掘出有价值的信息,具有重要意义。
微博话题发现过程就是一种有价值信息的发掘过程,其中最重要的环节是文本聚类过程。常见的聚类算法有基于划分的K-means聚类[2],基于密度的DBSCAN算法[3],基于层次的Single-Pass算法[4]。武国胜等[5]对文本聚类使用了改进的密度峰值算法,使用潜在语义分析模型(LSA)进行建模,使用密度敏感距离作为聚类的标准。Wang等[6]使用Word2vec对文本进行表示,引入了Canopy算法对文本进行K-means聚类。刘金硕等[7]使用LDA模型表示文本,并使用K-means算法对文本进行聚类处理,在食品安全文本类的数据集上进行算法验证。车蕾等[8]融合了向量空间模型、潜在狄利克雷分配模型和构建命名实体模型3种方法,使用Single-Pass算法进行新闻话题的发现。
这些聚类的相似度策略采用传统的欧氏距离、余弦距离来计算文本之间的距离,用于相似度判断的标准,忽略了当文档词数不同时,词与词之间存在的“一对多”关系。因此,本文使用融合了余弦距离和WMD(word mover′s distance)的CWMD(cos-word mover′s distance) 来计算文本之间的距离,并且使用TF-IDF值代替WMD中的词频权重。同时,在微博话题发现中,因无法确定聚类后簇的个数,所以K-means算法并不适用;DBSCAN基于密度聚类,不能增量式聚类,即新到来的数据无法对已有的簇产生影响,也不适用于微博话题的检测。对此,本文选取了基于层次聚类的Single-Pass算法进行博话题检测。
1 文本表示
常见的文本表示有向量空间模型(vector space model,VSM)、潜在的狄利克雷主题模型[9]等。在深度学习领域,Mikolov等[10]提出了Word2vec 模型,该模型结合上下文信息表示文档中特定单词的语义和语法信息。
VSM文本表示模型只考虑词频对文档的影响,认为词之间独立存在,忽略了其相关性。LDA主题模型对本文中微博数据的短文本信息不适用,因为较短的文本特征维度较高,数据比较稀疏,信息量少[11],无法准确地确定主题。
基于本文数据特点和各文本表示模型的优缺点,提出TF-IDF & Word2vec文本表示模型。步骤如下:

输入:文本语料M= {m1,m2,…,mn} 输出:文本向量集 Step1:输入文本语料集,对文本进行Jieba分词以及去除停用词。每一条文本变为含有特征词的集合,即mi= {fi1,fi2,…}; Step2:将处理后的文本集合输入到Word2vec模型中进行训练,对于每一个特征词fij都会得到一个N维的特征向量V(fij); Step3:利用TF-IDF公式计算文档中特征词的权重W(fij); Step4:根据Step2和 Step3中的计算结果,向量化表示mi= {(V(fi1),W(fi1)),(V(fi2),W(fi2)),…}。
2 CWMD算法
2.1 传统文本距离计算方式
对文本进行聚类,需要确定一种标准来判断不同的文本是否相似,这个标准就是距离函数。常见的距离函数有欧氏距离、余弦距离、马氏距离、曼哈顿距离等。在文本聚类中,欧氏距离和余弦距离因计算简便、易于理解而被广泛使用。图1展示了空间内P、Q两点的欧氏距离和余弦距离。
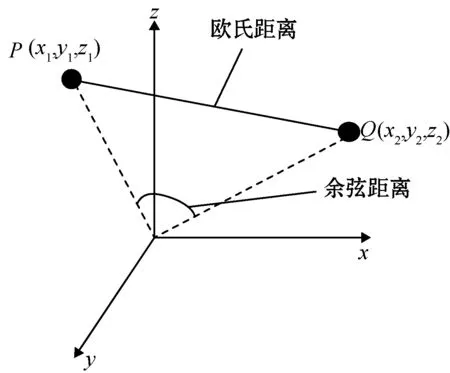
图1 欧氏距离和余弦距离
假设计算两个特征词都为p维的文档m1、m2的距离,m1的空间向量表示形式为W1=,〈w11,w13,…,w1p〉,m2的表示形式为W2=〈w21,w22,…,w2p〉,其欧氏距离为
(1)
余弦距离为
(2)
式(1)、(2)计算的是特征项个数相等的两个文档的距离,即W1的维度等于W2的维度。图2展示的是当两个文档特征项个数不同时,利用传统方式计算文档1到文档2距离的情况。如果仅考虑两文档距离和最小,则最佳解决方案是使文档1、2中每两个单词的距离最小。在这种情况下,可能会出现文档2中的一个词对应文档1中多个特征词,而忽略了文档2中其他特征词与文档1中该词的距离,极端情况下会出现一对所有的情况,这样的计算方式并没有考虑整个文档中所有词对于该文档的贡献。

图2 传统的文本距离计算方式
2.2 WMD计算方式
WMD是Kusner等[12]提出的一种基于EMD(earth mover′s distance)计算词移距离的度量方式,与欧氏距离、余弦距离不同,WMD本质是线性规划问题,计算的是两个分布之间的距离,其计算公式如下:
(3)
图3为使用WMD算法计算文档P1和P2距离的方式。
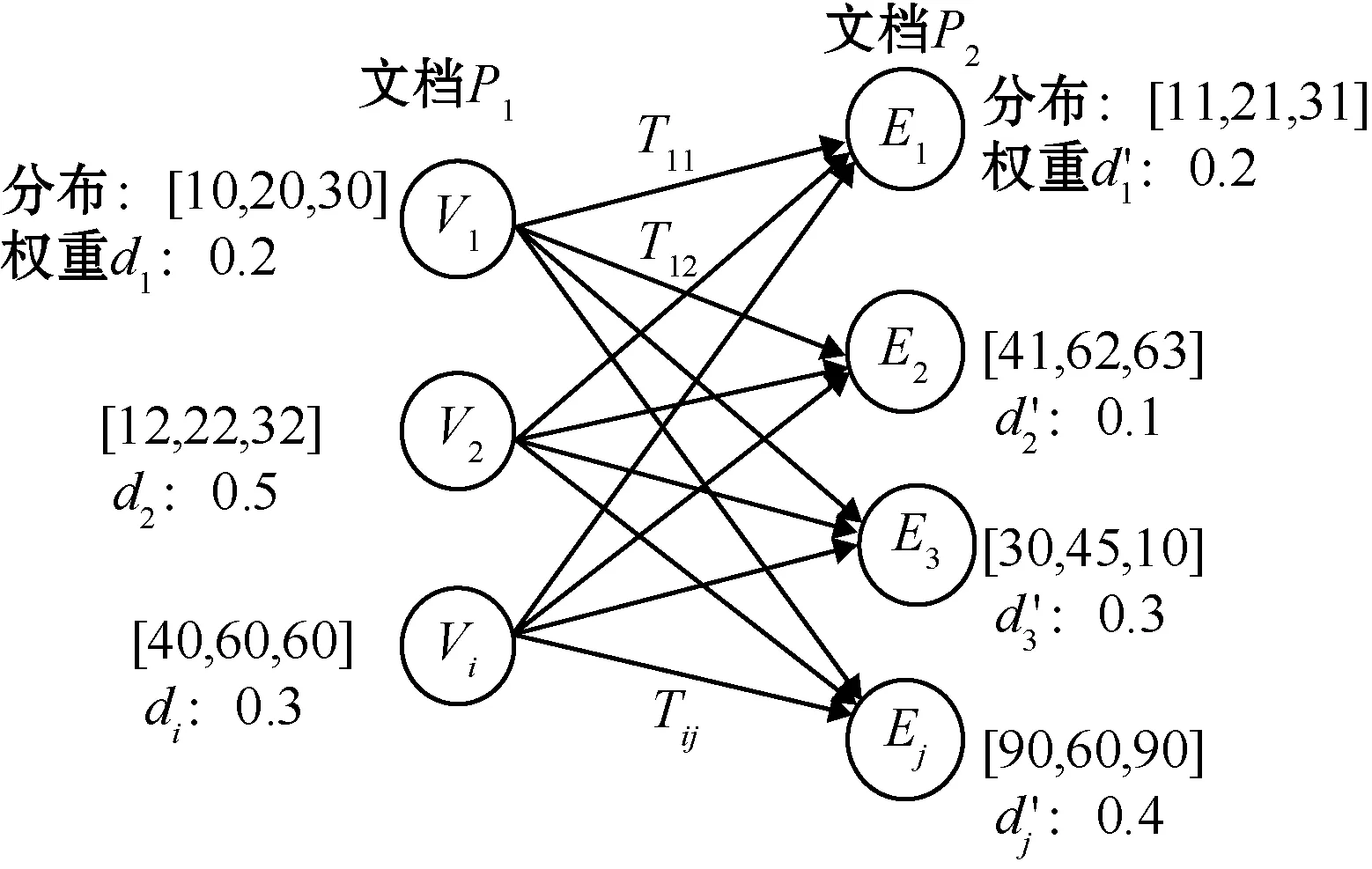
图3 WMD计算距离的方式
WMD具体算法过程如下:
两个文档P1、P2经过Word2vec模型表示后,P1中的第i个词和P2中的第j个词的欧氏距离为
c(i,j)=‖xi-xj‖2
(4)
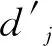
2.3 CWMD计算方式
在WMD中,Kusner等[12]使用欧氏距离衡量词间的转移代价。Word2vec模型属于嵌入式模型,欧氏距离侧重于数值上的绝对差值,计算结果受维度的影响。而余弦距离在维度变化情况下,仍体现方向上的差异,计算结果与维度无关。所以本文提出将余弦距离作为WMD词转移代价的度量方式,即提出CWMD算法。
WMD用词频来表示词的权重,认为一个词出现的次数越多,则权重越大,忽略了关键词信息。考虑到不同的词对句子的贡献不同,本文使用TF-IDF值代替原始的词频作为WMD权重的输入。
3 聚类算法
聚类分析也称为群集分析。针对实验数据特征,本文采用结构性聚类的层次聚类算法——SP文本聚类算法。传统的SP算法中,语料库中的每条数据按照顺序参与一次聚类,而且对文本输入的顺序比较敏感,即一个文本簇中初始的文本对该簇的影响较大。微博文本长度较短,包含的信息量较少,针对短文本数据的特点,本文提出了一种对初始文本集预处理的SP聚类算法。
为了使簇中初始的文本向量相对准确,当处理文本向量Di时,先不对其进行相似度比对,而是判断向量的长度。如果小于规定的阈值L,则进入待定区U,否则进入预处理集合M。等M中文本数据聚类完成后,对待定池U中的数据进行聚类。这样可以有效避免因初始文本长度较短、信息量较少而使簇的初始中心不准确的问题。算法流程如图4所示,伪代码如图5所示。

图4 加入文本待定池的SP算法流程

图5 改进的SP聚类算法伪代码
4 实验
4.1 实验数据与评价指标
本文使用中文分析语料库中京东和携程网上采集到的评价数据,包括书籍、衣服、计算机、酒店、平板、水果、洗发水、牛奶、手机8种类别共62 774条文本作为原始数据。原始数据中存在大量噪声信息,为了使聚类的质量有所提高,对其进行筛选,删除噪声数据后,最终选用书籍、衣服、计算机、酒店4种类别各1 000条数据进行实验。
为了节省算法运行空间,提高运行速度,使用Jieba分词对实验数据进行处理。将分词之后对文档贡献值较小的助词、语气词等“停用词”剔除。
使用准确率(P)、召回率(R)和F1值作为分类效果好坏的评价指标。其中
(5)
准确率、召回率越高,F1值越大,说明模型的效果越好。
4.2 对比实验
4.2.1 SP聚类算法对比实验
将CWMD分别与传统的SP聚类算法和改进的SP聚类算法相结合,进行文本聚类实验,使用F1值作为评价指标,实验结果如图6所示。
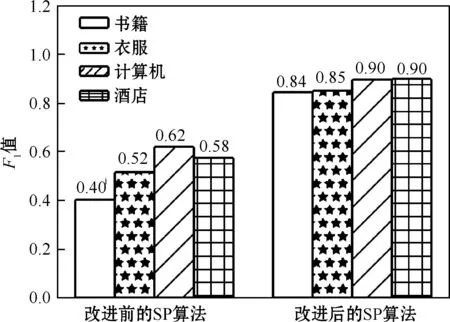
图6 改进前后SP聚类算法实验效果对比
从图6可以看出,改进后的SP算法 4类文本的F1均值提高了35.52%,聚类的效果有了明显提升。
4.2.2 距离标准对比实验
使用改进的SP算法,将CWMD、余弦距离和欧氏距离分别作为其聚类标准进行实验,F1值作为评价指标,实验结果如图7所示。
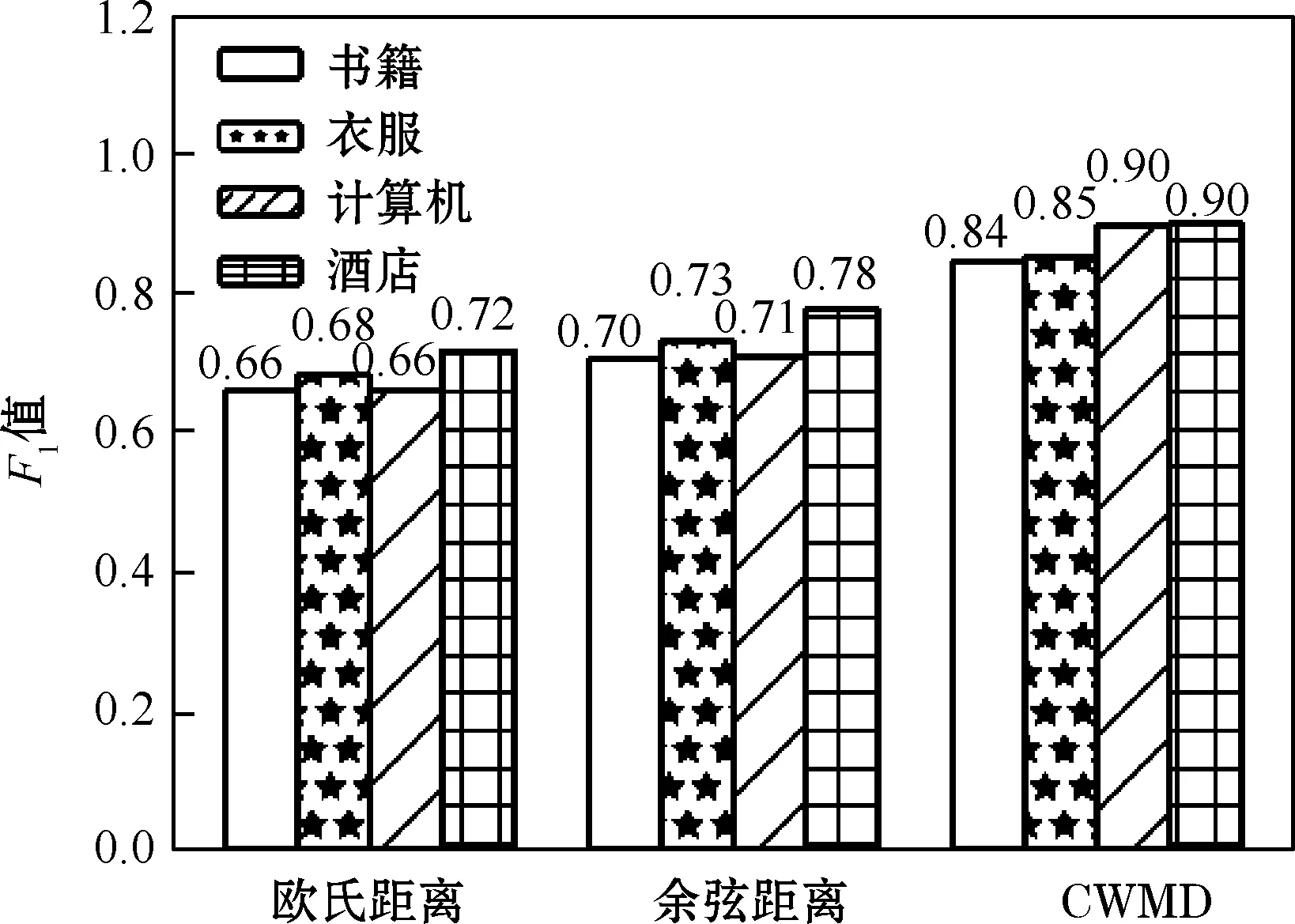
图7 使用不同距离标准的实验效果对比
从图7可以看出,当文本数据集相同时,使用CWMD作为聚类标准的算法效果最好,4类文本的F1均值比使用欧氏距离、余弦距离作为聚类标准分别提高了19.25%、14.45%。使用相同的距离标准进行聚类时,不同类别的文本效果略有差异,主要是受文本数据本身的影响。
5 应用实例
将CWMD与改进的SP相结合的聚类算法应用到微博文本中,进行话题发现分析。
5.1 微博数据采集以及文本聚类
本文采用Python语言对微博进行网络爬虫,采集到了2020-8-25至2020-9-1期间部分微博数据,共计2万余条,包括博主的ID、昵称、博文、发布时间以及发布终端等。将获取到的博文进行文本预处理,去除噪音和一些特殊符号等。之后进行Jieba分词,去除停用词并对数据作向量化表示。将处理后的数据结果输入CWMD和改进的SP聚类模型中。
5.2 聚类结果分析
针对聚类结果,根据包含文本数量取前3个话题簇,对其提取关键词,将关键词和微博官网提供的热点话题进行对比,从而验证聚类后话题词与现实微博话题的一致性,结果如表1所示。
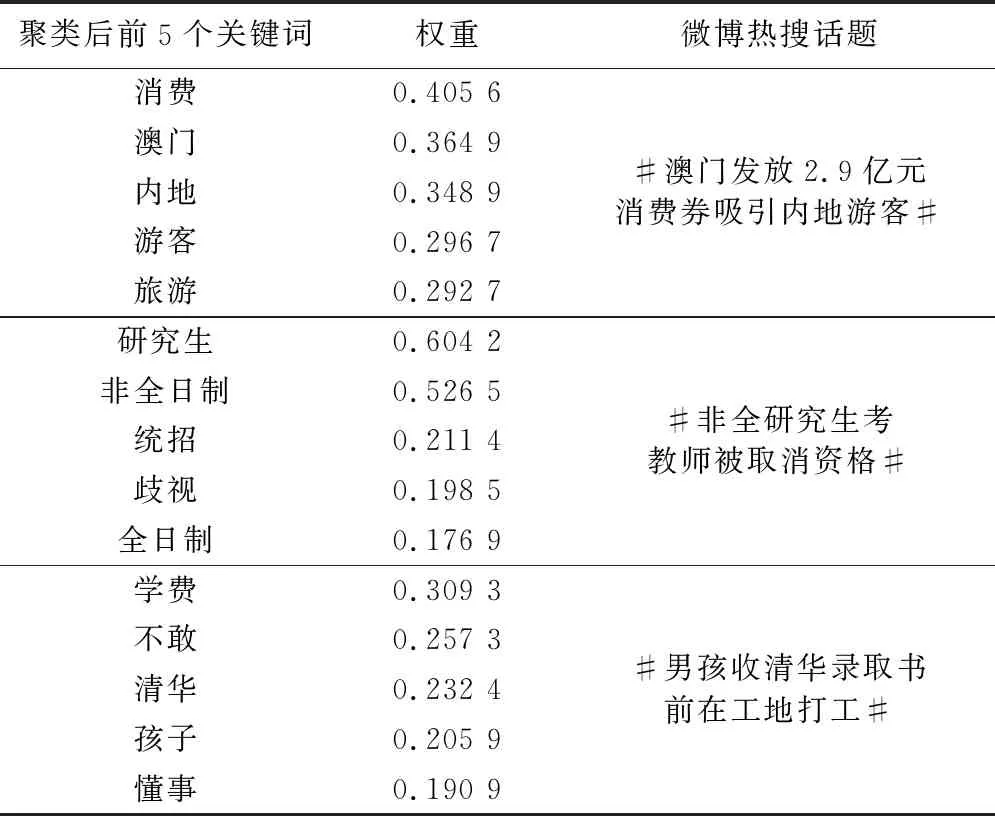
表1 微博文本聚类结果与热搜话题对比
最右侧一栏的3个话题是在数据采集时间段中新浪微博的热搜话题。该时段正值国内疫情放缓,国民经济复苏,“澳门发放2.9亿元消费券吸引内地游客”话题引起人们的广泛关注,网民就此开展广泛讨论。从聚类结果可以看出,“消费”、“澳门”、“内地”等词是文本簇中的关键词,这些词与实际的热搜话题紧密相关。在“非全研究生考教师被取消资格”话题中,网民就全日制和非全日制产生的学历歧视问题进行讨论。可以看出,每个文本簇提取到的关键词和微博实际热搜话题联系紧密,证明本文提出的聚类模型可以较好地应用到微博话题检测中。
6 结束语
本文针对传统的微博话题检测中文本向量高维稀疏且无关键词信息等缺陷,将Word2vec模型训练好的词向量进行TF-IDF加权表示,引入CWMD距离计算文本之间的差距。并且采用改进的SP增量聚类的方式进行最终的文本聚类。对有标签评论数据的实验结果表明,本文提出的聚类模型比传统的聚类模型效果更好。在此基础上,对爬取到的无标签微博文本进行处理,将聚类结果与微博官方热搜话题进行比对,证实了聚类结果的有效性。下一步将增加爬取微博的时间跨度,进行更全面的话题发现。
