基于多智能体的“配电网—代理商—电力用户”需求响应互动模型
2021-05-19林智威刘成骏徐锦江吴英俊汝英涛
林智威,刘成骏,顾 松,徐锦江,吴英俊,汝英涛
(河海大学 能源与电气学院,江苏 南京 211100)
0 引言
近年来,随着我国用电负荷的稳步增长,全国多个省市尖峰负荷连年创下新高,直接影响电力系统运行的灵活性和可靠性[1-2]。电力用户通过需求响应(Demand Response,DR)市场手段与电网进行互动,缓解电网运行的巨大压力已成为我国电网发展的大趋势,也已成为当今电力行业的研究热点[3-6]。
用户对电能的要求综合了质量、可靠性、舒适性等多种维度,充分考虑了自身的经济效益[4-5]。因此,将用户需求响应的经济效益纳入考虑,是反映用户在需求响应中的响应负荷贡献的价值[6-9]。电力需求响应已经不仅以电网可靠、灵活运行本身为核心,更多需要考虑用户如何更好地参与电网的需求响应互动、用户如何更好地体现参与需求响应的价值以及电能在需求响应时的市场价值体现等内容[10]。文献[11]研究了多配用电力公司场景下的需求响应管理问题,其中电力公司间的竞争用非合作博弈构造,而家庭用户间的交互用演化博弈构造,所提出的策略方法表明电力公司和家庭用户两类群体分别可收敛到Nash 平衡点和演化博弈平衡点;文献[12]利用演化博弈论研究了一类网状结构智能电网的需求侧管理和控制问题;文献[13]从演化博弈论视角探讨了需求侧管理技术,并重点关注一种由运营商通过定价方案可强制执行的分布式控制方案。文献[14]则针对实时需求响应问题提出了分布式需求响应策略,并利用演化博弈论的概念来在解析和经验基础上建立确定问题中的收敛特性,研究结果表明该策略具有实时性和较高可扩展性,为需求响应管理实际问题提供了良好的前景。
目前,博弈论在需求响应领域的总体研究思路往往考虑简单的两群体博弈,且注重均衡点稳定性的分析,较少考虑博弈机制对两个决策主体之间交互的影响。所以,提出了一种基于多智能体相关均衡Q(λ)(Correlated⁃Equilibrium⁃Q(λ),CEQ(λ))的电力需求响应分布式交易模型,使得需求响应过程中的经济效益共享,有效地保证了电网与电力用户之间的需求响应互动。而后,由于采用多智能体CEQ(λ)学习算法,有效解决了传统的单主体优化的多维决策求解问题。
1 “配电网—代理商—电力用户”之间的需求响应互动关系
1.1 “配电网—代理商—电力用户”需求响应互动模式
为解决电力用户(Electric Users,EU)参与电力需求响应的问题,建立基于“配电网—代理商—电力用户”三层架构的需求响应互动模式,如图1 所示。在该互动模式下存在配电网运营商、电力用户、需求响应代理商3 个互动主体:配电网运营商实时监控配电网的运营信息,当配电网处于不正常运行状态时,配电网运营商将自上而下发布需求响应指令,提高配电网运行的可靠性;电力用户在保证其用电方式满意度的前提下,向需求响应代理商出售电力需求响应服务以获得经济利益;需求响应代理商促进配电网运营商与电力用户之间的需求响应互动,以获取最大的经济收益。
在该需求响应互动模式中,为了使需求响应代理商更好地促进三个主体的互动,提出一种需求响应互动模式下“配电网—代理商—电力用户”经济效益共享计算方法。在配电网获取电力需求响应容量的过程中,需求响应代理商提供了电网和电力用户间的协调服务,故配电网代理商将因需求响应服务带来可靠性上升的等值经济收益中的一部分分摊给需求响应代理商;需求响应代理商获得了额外收益,故其承担一部分电力用户因参与需求响应使用电满意度下降的等值经济成本。
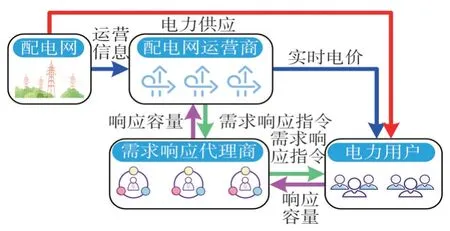
图1 “配电网—代理商—电力用户”需求响应互动模式
1.2 基于多智能体的电力需求响应分布式互动框架
根据所提出的需求响应互动模式,提出了一种基于多智能体的电力需求响应分布式交易模型,各智能体之间的交互关系如图2所示。
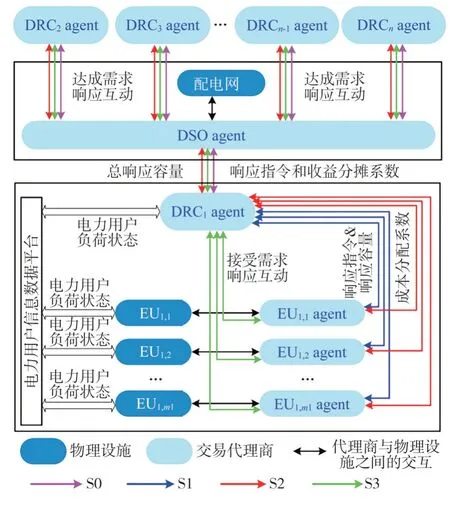
图2 多智能体分布式需求响应互动框架
配电网运营智能体(Distribution System Operator agent,DSO agent)作为配电网的交易代理商,管理整个配电网的运行;需求响应交易智能体(Demand Response Coordinator agent,DRC agent),负责向电力用户智能体(Electric User agent,EU agent)购买需求响应容量并将其提供给配电网,以缓解配电网供电压力;EU agent 作为电力用户的交易代理商,负责向DRC agent 出售需求响应服务,并保证电力用户的经济性和用电满意度。
根据图2 中各智能体的交互关系,可以得到各智能体更加详细的动作时序。以DRC1agent 及其所管理的EU agents 为例,如图3 所示。多智能体之间的指令主要包括通知(INFORM),询问(QUERY),制定方案(PROPOSE),同意(AGREE),拒绝(REJECT),DSO agent、DRC agent、EU agent之间的互动时序:
S0:DSO agent 向各DRC1agent 发出需求响应指令,DRC1agent 询问DSO agent 报价策略,DSO agent根据配电网运行状态确定收益分摊系数,制定报价策略并传递给DRC1agent。
S1:DRC1agent 向管理所有的EU agents 发出响应指令,EU agents 询问DRC1agent 所需响应容量,DRC1agent制定每一个EU agent的响应容量。
S2:EU agents 询问DRC1agent 报价策略,DRC1agent 确定成本分配系数,制定报价策略并传递给EU agents。
S3:DSO agent 和EU agents 反馈DRC1agent 是否达成三方交易,若反馈为AGREE,则达成三方交易,若反馈为REJECT,则返回S0。
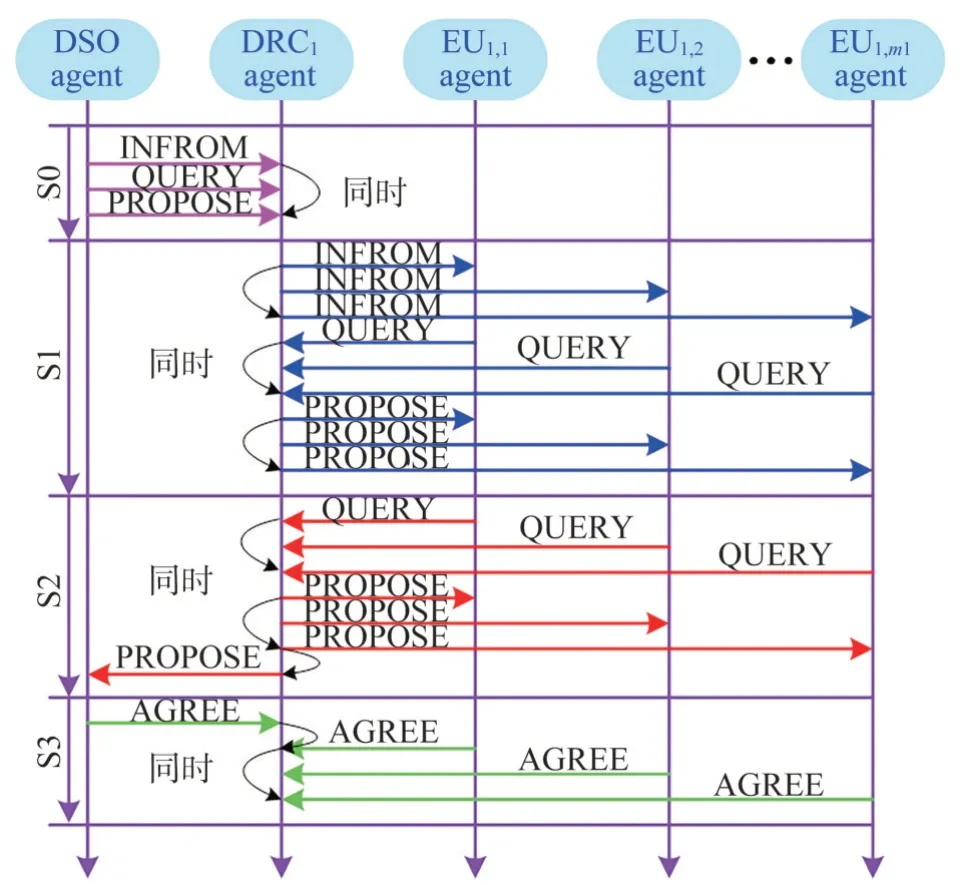
图3 多智能体动作时序图
2 基于多智能体的电力需求响应分布式交易模型
2.1 DSO agent交易模型
DSO agent 在一个电力需求响应时段内的目标函数如式(1)所示,共包含两部分:第一部分为DSO agent 向DRC agents 购买需求响应服务费用;第二部分则是配电网通过需求响应手段使可靠性提升的等值经济收益。
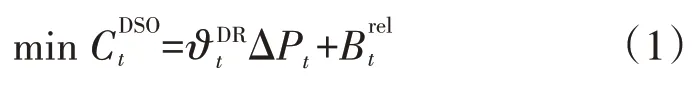
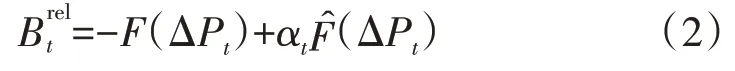
式中:F(ΔPt)为配电网中备用容量下降减少的备用机组投资成本,可由配电网的备用容量成本函数求得;为DSO agent 传递给DRC agents 的机组投资成本函数;αt为中需要分摊给DRC agents的比例。
事实上,配电网获得需求响应服务后的实际收益为式(2)中的第一项,但由于DSO agent 更期望从DRC agents 获得更多的电力需求响应容量,故DSO agent 会向DRC agents 报出虚假的,并根据这一函数与DRC agent 进行可靠性提升带来的等值经济收益分摊。
对于电力系统,其备用容量成本可以二次函数计算[15],为
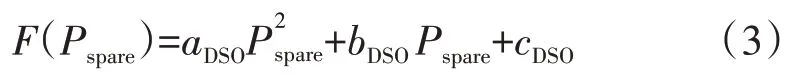
式中:aDSO、bDSO、cDSO为DSO agent 根据配电网的运营状态确定的相关常数;Pspare为系统备用容量。
故配电网由于备用容量下降能够节省的投资成本可表示为
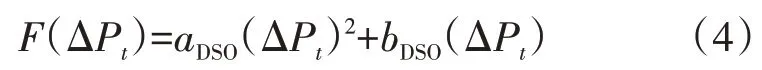
但通常,DSO agent 在向DRC agent 传递这一函数时,通常会根据实际情况对其进行修正,以希望在和DRC agents 的交易中获得更多收益,修正后的表达式为
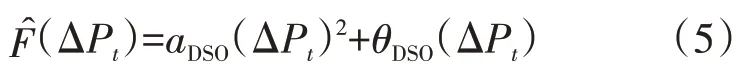
式中:θDSO为DSO agent 根据配电网的实际情况确定的修正系数。
DSO agent受到的约束如式(6)—式(8)所示:
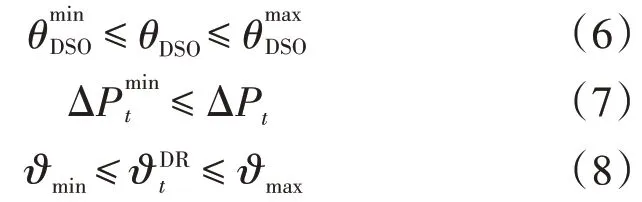
式(6)表示DSO agent 的修正系数是理性的;式(7)保证了最低响应容量,保证了系统的可靠性;式(7)和式(8)保证需求响应价格的合理性。
2.2 EU agent交易模型
第i个DRC agent 下属的第j个EU agent(即为图2 中的EUi,jagent)在一个电力需求响应时段内的目标函数如式(9)所示,包含三部分:第一部分为此用户参与电力需求响应导致用电满意度下降产生的成本;第二部分是此用户参与需求响应后减少的用电费用;第三部分则是此用户参与电力需求响应后从ERCi处获得的收益。
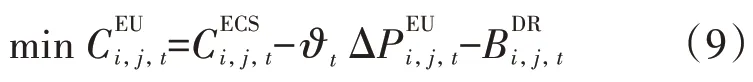

用户参与需求响应后用用功率下降,由此导致用户的用电满意度下降,可把用电满意度系数定义为[16]

式中:μ为与用户自身用电属性有关的常数为EUi,jagent 参与电力需求响应前的电负荷功率。对于不同种类的EU agent(例如工业负荷、商业负荷和居民负荷),由于其自身用电负荷的构成和比例各不相同,所以其用电满意度曲线具有个体差异。
类似地,EUi,jagent 在向DRCiagent 提交用电满意度经济折算成本函数时也会对其进行修正,以期在和DRCiagent的博弈中获得更大的收益,修正后的函数为

2.3 DRC agent交易模型
一个需求响应时段内第i个DRC agent的目标函数由两部分组成:第一部分为它从DSO agent 分摊得到的收益,第二部分为其管理所有EU agents 所分配的成本,为
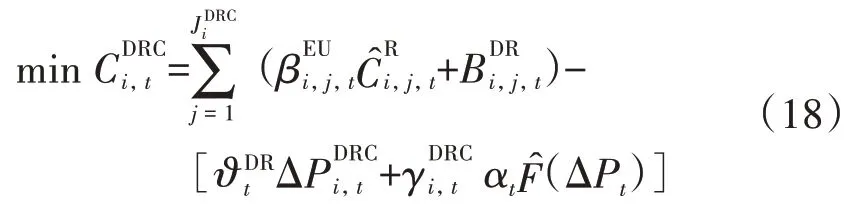
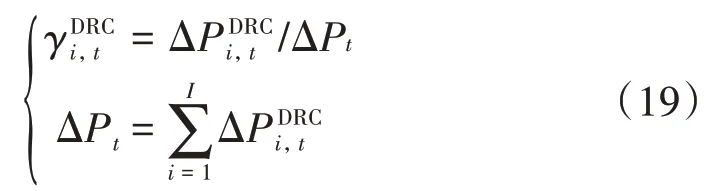
式中:I为协调需求响应互动的DRC agent的总个数。
DRC agent受到的约束为:
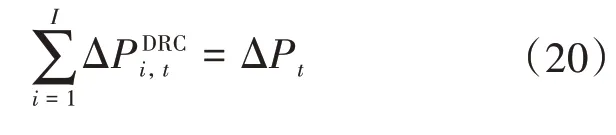

式(20)保证DRC agent 群和DSO agent 间的交易量平衡;式(21)则保证每个DRC agent的最低收益。
3 交易主体的多智能体CEQ(λ)学习策略
搭建的需求响应交易模型中包含1 个DSO agent、m个DRC agent 以及n个EU agent。每个智能体在所有智能体的动作概率分布基础上最大化其奖励值,达到整体奖励最大化的相关均衡,此时获得的联合动作策略为最优互动策略。
3.1 均衡选择函数
一般常用的均衡选择函数有4 类:uCEQ、eCEQ、pCEQ、dCEQ[17]。选用uCEQ,即在任意状态s中,有:
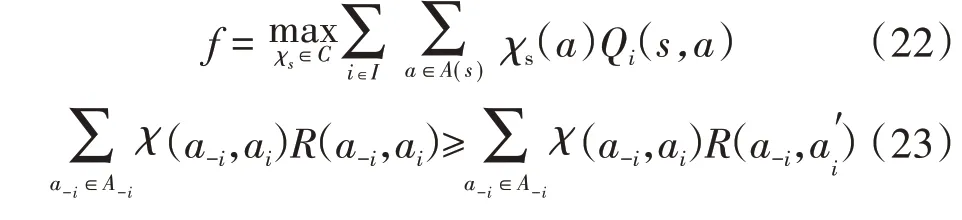
式中:C为多智能体的均衡策略集;A(s)为多智能体的均衡动作集;A-i为除了第i个智能体的其他智能体的动作集合;ai为第i个智能体的动作为第i个智能体的任意可选动作,且a′i ≠ai;a-i为除了第i个智能体的其他智能体的动作;χs为均衡策略(即动作概率);Qi(s,a)为第i个智能体的期望状态函数;R(a-i,ai)为第i个智能体的立即奖励函数。如果某一策略χ对于所有的动作ai,,a-i∈A-i均满足式(23),这一策略即为相关均衡动态平衡点。其中Ai为第i个智能体的动作集合。
多智能体CEQ(λ)学习算法的一般原理是计算所有智能体当前状态下的Q值,并根据整体系统响应、返回奖励值优化所有智能体的Q值直到迭代至相关均衡,其迭代过程[18-19]为:
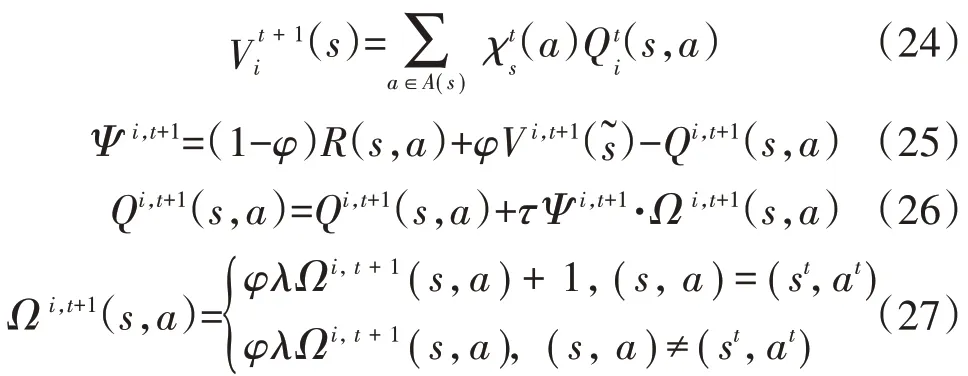
式中:Ψ为各智能体的Q值误差函数;为t时刻状态-动作(s,a)下的资格迹;(st,at)为t时刻实际的状态-动作;φ、τ、λ为算法的超参数,分别为折扣因子、学习因子和衰减因子[20]。
3.2 奖励函数设定
对于在电力需求响应交易模型中的交易主体,根据式(1)、式(9)、式(18)设计其评价奖励函数。对DSO agent,其奖励函数为
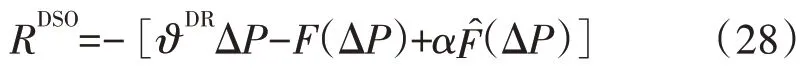
对第i个DRC agent,其奖励函数为
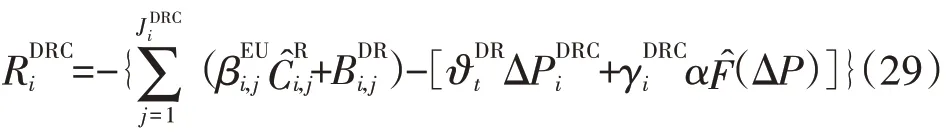
对第i个DRC agent 管理的第j个EU agent,其奖励函数为
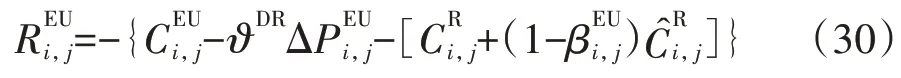
3.3 多智能体CEQ(λ)算法
在DRC agents 促成DSO agent 与EU agents 之间的需求响应互动过程中,描述多智能体CEQ(λ)算法伪代码。
输入:均衡选择函数f;折扣因子φ;学习因子τ;衰减因子λ;
输出:Q、V矩阵更新值;联合动作策略χ*;
初始化:Q、V值矩阵;初始状态s;初始动作a;
迭代:
1)agenti:
a)确定当前状态s下最佳动作ai;
b)根据式(28)—式(30),获得当前状态s下所有agent的奖励函数;
c)根据式(22)和式(23)和均衡选择函数f求取状态s下相关均衡策略χs;
2)agentj(j≠i):
b)根据式(25),更新值误差函数Ψ i,t+1;
c)根据式(27),更新资格迹元素Ω i,t+1(s,a);
d)根据式(26),更新值函数Qi,t+1(s,a);
3)如果当前状态s和下一个状态st是同一个状态,那么输出Q*,V*,χ*;否则执行1)。
4 算例分析
以某省某个示范园区为例,园区内典型电负荷曲线如图4 所示,整个园区包含一个DSO agent 以及两个DRC agents,DRC1agent 管理2 个工业电力用户,DRC2agent 管理1 个商业电力用户和1 个居民电力用户,即该园区有4个EU agents。仿真以13:30—15:30 作为配电网的需求响应时段,以15 min作为一个时间间隔,则表1给出了需求响应时段内的各智能体之间的交易电价。表1 中,峰时段为08:00—11:00,平时段为11:00—18:00 和22:00—23:00,谷时段为00:00—08:00 和23:00—24:00。多智能体CEQ(λ)的超参数φ取0.8,τ取0.001,λ取0.5。
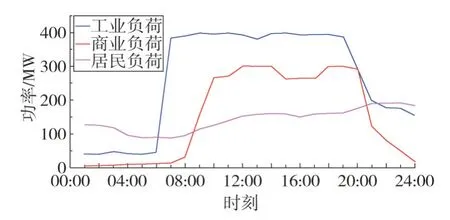
图4 不同类型负荷曲线
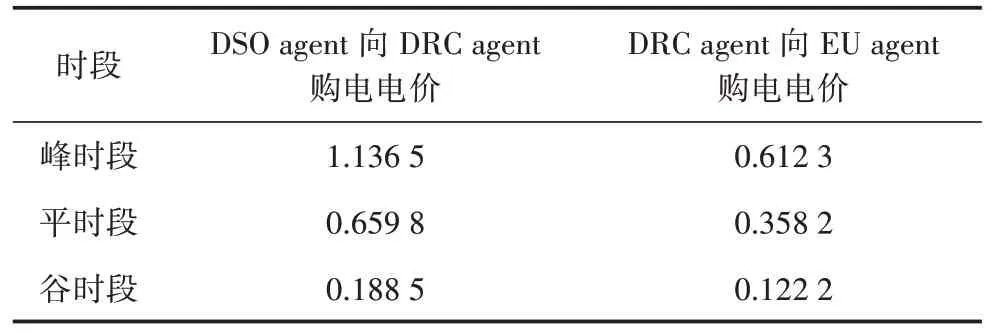
表1 各agent之间交易实时电价单位:元/kWh
4.1 算法收敛性分析
该算例中,经济效应共享参数均取0.4。多智能体CEQ(λ)学习算法的均衡状态数量与迭代次数变化情况如图5 所示。由图5 可知,多智能体CEQ(λ)学习算法迭代约15次时能稳定达到相关均衡状态。
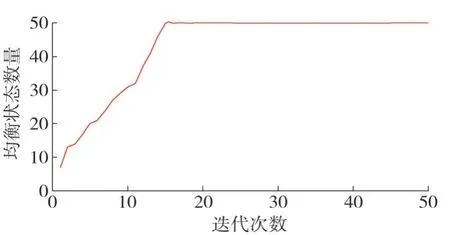
图5 均衡状态数量变化情况
图6 展示了多智能体CEQ(λ)学习算法在电力需求响应互动模式中,DSO agent、DRC agents 群以及EU agents 群三大利益主体的经济效益收敛变化情况。结合图5 可知,三大利益主体均在迭代15次时收敛,迭代次数在10 次之前,各agent 的经济效益都叫低,而在10 次之后,经济效益明显提升,说明了多智能体CEQ(λ)学习算法在求解电力需求响应互动模型的完整性、均匀分布性、收敛性都具有有效性。
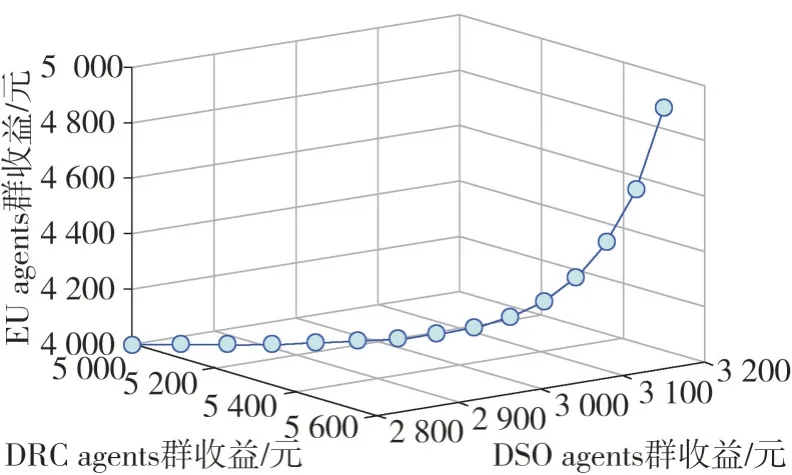
图6 各agent经济收益收敛性变化
4.2 经济效益共享计算方法对各智能体收益的影响
图7给出了DSO agent与DRC agents群之间收益分摊对需求响应互动的影响,在收益分摊系数小于0.25 时,因为此时DSO agent 分摊给DRC agent 的收益较少,所以导致此时各agent 之间的需求响应互动比较平缓,故整体的经济效益偏低;在收益分摊系数大于0.75 时,DRC agent 从DSO agent 处分摊到的收益较多,但是随着响应容量的增加,DRC agent 所需承担EU agent 用电满意度下降的等值经济成本将增加,故此时DRC agent会选择降低需求响应互动的积极性,同时还能保证一定的经济收益,所以该区间在实际情况中应尽量避免。图8 给出了DRC agent 与EU agent 群之间的成本分配对需求响应互动的影响,在成本分配系数小于0.3 时,EU agent 群几乎承担所有用电满意度下降的等值经济损失,所以导致其响应积极性不高;在成本分配系数大于0.7 时,DRC agent 所需承担EU 用电满意度下降的等值经济损失过多,甚至超过了从DSO agent 分摊得到的收益,所以DRC agent 不愿意购买EU agent 群的需求响应服务,导致各agent需求响应互动程度较低。由图7和图8可知,在收益分摊系数与成本分配系数均取得0.4时,各agent之间的需求响应互动达到最佳,经济效益最大;在0.25~0.75之间的收益分摊和0.3~0.7之间的成本分配为较为理想需求响应互动经济效应共享。
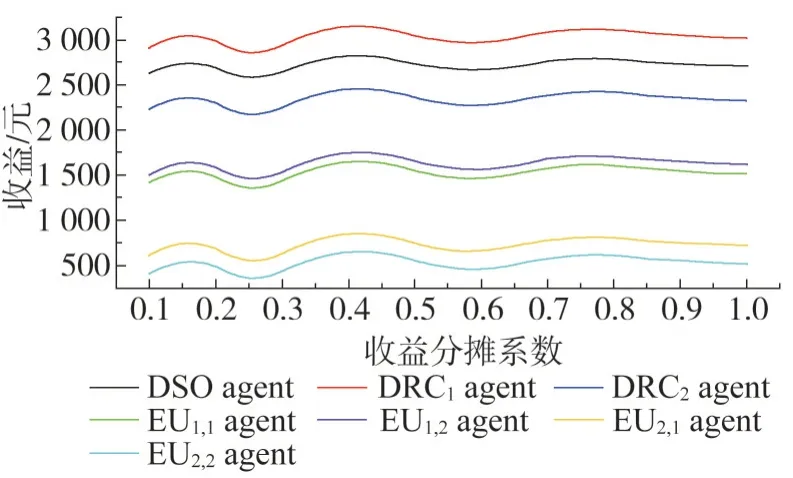
图7 收益分摊系数对各agent收益的影响
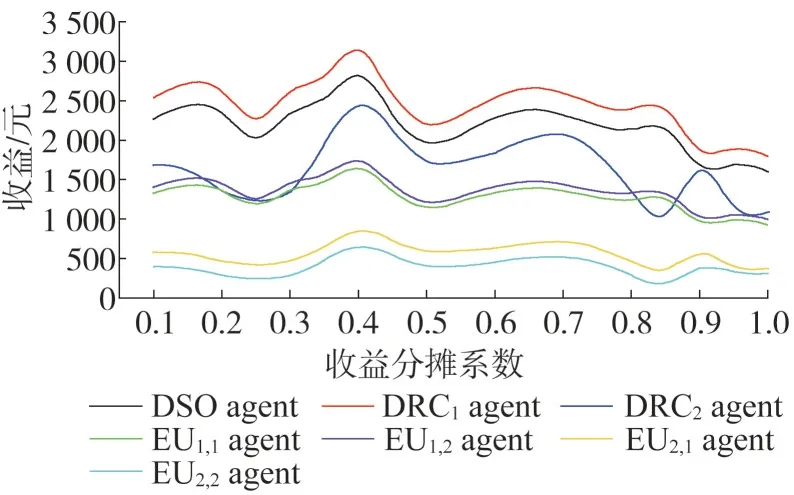
图8 成本分配系数对各agent收益的影响
5 结语
构建基于多智能体的电力需求响应互动模型,以各agent 利益均衡为目标,引入需求响应互动下经济效益共享的计算方法,采用多智能体CEQ(λ)学习算法促进电网与电力用户之间的需求响应互动。
将所提出的电力需求响应互动模式分为配电网代理商、需求响应代理商以及电力用户三大主体,采用多智能体CEQ(λ)学习算法对模型进行求解,使各主体利益均衡。
利用基于多智能体的需求响应互动收益、成本分摊分配计算方法,建立的电力需求响应分布式交互模型,有利于促成三主体的交易,并显著了各主体利益均衡收敛速度。
