基于深度学习的实时人脸检测
2021-05-17郭昕刚屈诺希
郭昕刚, 屈诺希, 杨 洛
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
近几年来,随着人工智能领域的飞速发展,深度学习也得到了极大发展,已经成为机器学习中主流的分支之一。它的广泛应用不计其数,随着研发者对网络性能的不断提升,计算量也随之增加,运行环境需要配置很高的显卡,而几乎无法在移动端部署。这让基于深度学习的方法成为产品的进程变得艰难,特别是在一些边缘设备上,这些设备主要为一些非密集任务而生成,所以在部署的时候会面临功耗大、时延长的缺陷。很多人选择将工程部署在服务器端,但是由于计算过多,成本也会上升。其中一种方法是设计各种神经网络芯片,针对给定的计算任务用特定的硬件加速;而另一个思路则是首先思考模型中所有的计算是否必不可少,如果存在非必要计算,能否通过将模型简化去缩减计算量和存储占用。文中所采用的方法就属于此类,称为模型压缩(Model Compression)[1],其可以归类于软件方法,应用成本不高,并且和硬件加速可以产生相辅相成的效果。其中模型压缩又包含了很多方法,如模型剪枝(Pruning)[2]、模型量化(Quantization)[3]、低秩分解(Low-rank factorization)[4]、知识蒸馏(Knowledge distillation)[5]等。每一子类方法根据不同的应用场景部署硬件环境而选定。
由于深度学习的人脸检测方法已经越来越成熟,模型性能也越来越完善,同时采用的深度学习神经网络越来越深,参数量越来越多,如果直接将训练得到的模型部署到计算资源较少的FPGA[6]移动设备端,不能满足实时人脸检测的需求。WIDER FACE[7]是现有评估人脸检测算法最权威的数据集,WIDER FACE数据集是由香港中文大学发布的大型人脸数据集,含32 203幅图像和393 703个高精度人脸包围框,该库中人脸包含姿态、表情、遮挡和光照等不同的状态。因此,基于WIDER FACE数据集和原始Retinaface[8]网络训练人脸检测模型进行模型剪枝,减少模型网络中卷积核数量,从而减少模型参数,并且在FPGA设备端实时运行人脸检测模型。经过测试,在原有模型精度损失不明显的情况下,可以在FPGA达到实时检测速度。
1 基本原理
1.1 Rtinaface原理
Rtinaface网络改进了基于传统物体检测网络RetinaNet[9],为提高精度增加了SSH[10]网络的模块,其中提到三种基础网络,基于ResNet[11]的ResNet50和能提供更好精度的ResNet152版本,以及基于mobilenet[12](0.25)的轻量版本。Rtinaface模型网络结构如图1所示。
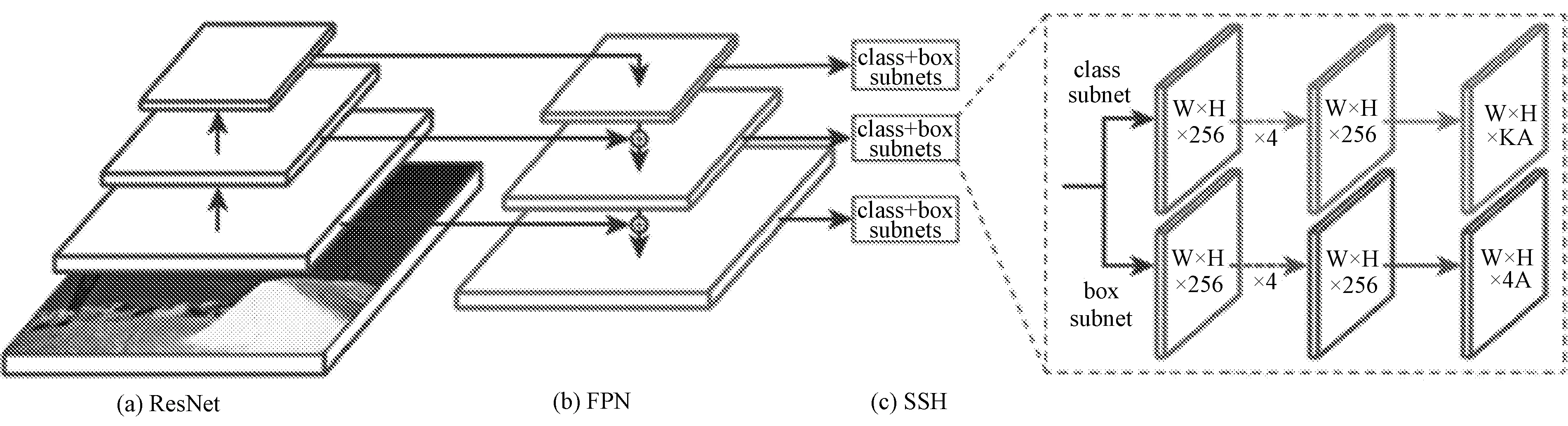
图1 Rtinaface模型网络结构
ResNet网络是微软研究院提出的,成功运用Residual Unit训练深度为152层的神经网络,在ILSVRC 2015比赛中夺冠,结果是3.57%的top5错误率,并且参数量要远低于VGGNet[13]。ResNet结构在极大提高准确率的前提下,还极速训练超深神经网络。Residual block通过shortcut connection实现,通过shortcut将block的输入和输出进行一个elementFACEwise的加叠,通过这样一个并不复杂的加法,没有增加网络中多余的参数和计算量,却可以显著提高模型的训练速度,并使训练效果明显提升,而且如果模型层数加深,此方法也可以在解决退化问题时有很好的表现。残差单元的两种结构分别如图2和图3所示。
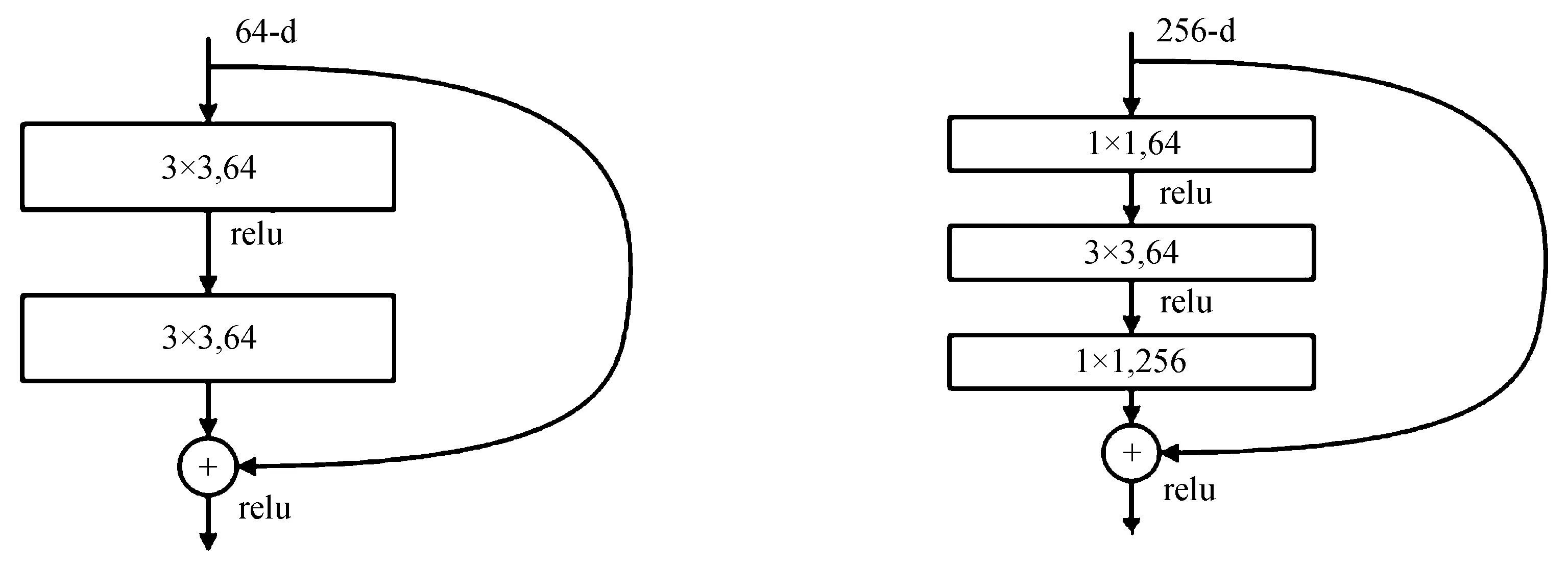
图2 ResNet34残差单元结构 图3 ResNet50/101/152残差单元结构
这两种结构分别针对ResNet34(图2)和ResNet50/101/152(图3),一般称整个结构为一个“building block” 。图3又称“bottleneck design”,其降低了参数数量,实际中,为节约计算成本,在残差块部分进行了计算优化,具体是用1×1+3×3+1×1代替两个3×3的卷积层(见图3)。其中3×3卷积层在第一个降维1×1卷积层下减少计算量,并且在第二个1×1卷积层达到还原,不仅没有损失精度,还减少了计算量。第一个降维1×1卷积层把channel维度从256降低为64维,在第二个1×1卷积恢复,总体用到的参数数目为
1×1×256×64+3×3×64×64+1×1×64×256=69 632,
而不使用bottleneck的话就是两个3×3×256的卷积,参数数目为
3×3×256×256×2=1 179 648,
差了16.94倍。一般的ResNet可以在34层或34层以下的网络中应用,而Bottleneck Design的ResNet则可以在更深的网络中应用,例如101这样的网络达到了减少计算和参数量的目的。
1)特征金字塔FPN[14]。RetinaFace运用从第2层到第6层的特征金字塔层,第2层到第5层使用一个自顶而下和横向连接,用来计算ResNet残差部分的输出。然后在第5层处一个步长为2的3×3卷积计算得到第6层。其中第2到第5层的结构为ImageNet数据集上训练好的ResNet分类网络,第6层通过“Xavier[15]”随机初始化得到。
2)上下文模块(SSH)。使用的是单独的上下文模块,达到了在五个特征金字塔层增加感受野和增强刚性上下文建模的能力,并替换掉每一个3×3卷积层,在横向连接和使用可变形卷积网络(DCN)的上下文模块中,更加显著地提升了非刚性的上下文建模能力。
1.2 模型压缩方法
滤波器剪枝的关键问题是在给定压缩比条件下选择不重要的滤波器进行剪枝。为了解决这个组合优化问题,大多数研究首先评估滤波器的重要性,然后用一次性的方式对其进行剪枝,或者用迭代的方式对模型进行剪枝再训练。文中提出过滤剪枝方法来近似地获得分层最优剪枝率,该方法能够在给定损失变化的情况下剪枝率最大的一层,而不需要费时地剪枝-再训练迭代。对于整个网络预定义的剪枝率,该方法无需额外微调就能收敛到特定的剪枝率。通过引入二值搜索方法,使剪枝网络的整体剪枝率收敛,从而达到剪枝网络性能和剪枝速度的平衡。该方法可广泛应用于常见的卷积网络结构。综合实验表明,与现有的剪枝方法相比,文中方法能够获得更大的压缩比和更低的正确率。
ResNet网络中短连接的分组剪枝方法如图4所示。

图4 Resnet网络中短连接的分组剪枝方法
对于一个阶段,每个块的最后一层在一个组中被修剪在一起,这样它们就有相同的保留过滤器。黑色表示相应的过滤器被修剪。由于阶段a有3个块,每个块中的快捷方式为标识连接,因此引入了通道选择(block1d=1中的channel_select)来屏蔽经过修剪的输入通道;而阶段b有3个block,第一个快捷方式通过卷积向下采样连接,所以可以在一组中进行修剪。
式中di表示第i块在一个阶段的深度,其中i=[1,2,…,K],K为块的数量。在剪枝过程中,根据得分排序将组中索引相同的过滤器剪枝在一起。在某些阶段,输入通道直接短连接到块,因此引入了一个非参数层来进行通道选择,它的输出通道布局是复制自组滤波器修剪。同理,Rtinaface网络中除了resnet后面的FPN和SSH模块,经过逐层搜索最优剪枝率后,将逐层搜索结果连接到剪枝网络中,然后微调训练数据集,获得最终的剪枝网络模型。
2 实验与模型部署
2.1 模型剪枝实验
基于resnet网络模型剪枝框架,对Retinaface网络模型进行剪枝,配置文件如图5所示。

图5 配置文件
工程入口为 get_start.py,Config/config.yaml配置文件如上,model目前示例为6种不同的基础网络,也可设为自己的网络,type可选sensetivity,prune。其中sensetivity为分析过程,prune为剪枝,流程先sensetivity后prune,即可得到剪枝后的模型。 method目前仅有ours,无需更改。delta_loss为loss的变化阈值,可通过该值的设定获得不同的压缩率,一般初始设定为0.01或0.001。save_dir 为分析后生成的文件保存地址,用于后续剪枝工作。pretrain 为预训练模型地址。Last_layer 为停止剪枝的最后一层(到该层为止,该层不减),分类网络一般为最后一个全连接层。对于一些特殊结构,需要手动添加配置,以便剪枝工作的正常进行。在配置文件中增加了4个字段,其中包括downsample、groups、stage和concat。若没有特殊结构也要加入字段,其值为空。
Retinaface人脸检测模型压缩实验数据见表1。

表1 Retinaface人脸检测模型压缩实验数据 %
Easy_Val_AP、Medium_Val_AP和Hard_Val_AP代表WIDER FACE数据集中人脸图像检测难易程度。其中剪枝率为31.81%、43.54%、49.16%,平均精度损失(不同剪枝率下三个子数据集实验精度与原模型精度的差值平均数)为2.09%、2.64%和2.94%,因此可得剪枝后模型与原模型检测精度对比,损失不严重。
2.2 模型部署及测试
FPGA作为移动设备硬件加速器在各个领域被广泛用于AI推断,研究嵌入式多核环境下最大化SOC系统硬件资源和计算性能的方法,包括CHaiDNN开源框架和DNNDK闭源框架;研究CHaiDNN 框架下自适应处理机制和硬件函数拆分与优化方法;研究基于DNNDK支持深度学习和其他功能加速的调度策略;研究匹配任务调度的多尺寸DPU设计方法,最大化FPGA的资源利用率。
本次模型部署主要利用DPU在FPGA7020上做并行加速。将基于pytorch框架训练的人脸检测模型压缩,然后化为开发应用较为成熟的Caffe模型,包括模型参数文件、模型网络描述文件(模型结构)以及矫正数据集(其中选取训练数据集中500张图像作为矫正数据集)。利用DECNET对模型进行量化,利用DNNC进行编译,最后得到可执行文件,利用WIDER FACE数据集中测试集人脸图像在FPGA(DPU)端测试模型,得出检测推理时间,见表2。

表2 不同的压缩率模型推理速度
可见剪枝率为43.54%的模型,推理速度为39 ms,可以达到实时运行。
在FPGA(DPU)上检测人脸效果与置信度如图6所示。

图6 人脸检测效果与置信度
3 结 语
在FPGA上实时运行的人脸检测方法能够更好地解决基于pytorch框架以及Retinaface网络训练人脸检测模型参数量大,无法在FPGA边缘侧端实时运行这一问题,使用模型压缩方法对人脸检测模型进行剪枝,部署在FPGA上,经过一系列仿真实验后,对实验数据分析可以得出,压缩后的模型在保持检测精度损失很小的情况下可以在PFGA上达到实时运行,充分说明了文中方法的有效性。
