遮挡人脸表情图像预处理研究进展
2021-05-17殷柯欣廖冰冰胡文楠
殷柯欣, 廖冰冰, 胡文楠, 包 芳
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
人脸表情是人类表达自我、沟通交流的重要方式,通过表情可以读出人类内心的真实想法。人脸表情识别(Facial Expressions Recognition,FER)技术将心理学、生理学、图像处理与模式识别等研究领域进行交叉融合,在情感分析、心理学、医学分析、军事等领域成为研究热点。人脸表情识别过程包括人脸表情图像采集、图像预处理、特征提取和表情分类四个基本步骤。
表情图像采集作为FER第一步,对表情识别具有重要影响。在采集图像过程中,环境影响是不可避免的。这些影响包括光照、姿态、低分辨率以及遮挡等。文中主要对遮挡表情图像进行详细总结。李小薪等[1]提出引起面部遮挡的因素可以分为:
1)极度光照不均匀造成的光线遮挡;
2)覆盖人脸的实物遮挡;
3)自身姿态造成的自遮挡。
光线造成的面部遮挡可以从去除光线的角度处理,自身姿态造成的自遮挡主要由主观意愿造成,文中重点针对实物遮挡的人脸表情图像进行分析,介绍由实物造成面部遮挡图像预处理方法。实物遮挡包括墨镜、口罩、围巾等造成的面部遮挡,以及周围物体或他人身体造成的遮挡,如图1所示。

(a) 墨镜遮挡 (b) 口罩遮挡 (c) 手枪遮挡
文中主要从CNKI、CCF、IEEE、谷歌学术和百度学术等文献数据库查阅了近3年相关文献。首先介绍了遮挡表情图像的传统处理方法,然后进一步将遮挡表情图像处理算法分为基于面部重要区域、基于图像重构和基于深度学习的处理三个角度介绍。数据集是表情识别研究中重要的一部分,文中对常用的人脸数据集进行了介绍与分析。最后总结了现阶段遮挡表情图像预处理存在的问题,并对其未来研究方向做出了分析。
1 遮挡人脸表情图像的传统预处理
传统的人脸表情图像预处理包括人脸检测、人脸剪裁、图像归一化及特征定点[2],然而这些操作只针对理想的表情图像有效,并不能解决由遮挡造成的表情图像问题。李蕊[3]在传统表情图像预处理的基础上,把预处理扩展为彩色图像进行灰度化、灰度直方图均衡化和尺度归一化,再分块提取Gabor特征和BM-SVM分类,并在JAFFE和RaFD表情库上实验,识别率达到80%以上。加权平均法对彩色图像灰度化、人脸图像灰度直方图均衡化、表情图像尺度归一化分别如图2~图4所示。

图2 加权平均法对彩色图像灰度化
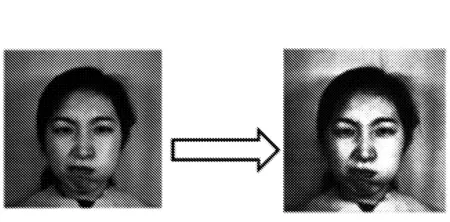
图3 人脸图像灰度直方图均衡化

图4 表情图像尺度归一化
灰度化、均衡化以及归一化等预处理并不能直接解决遮挡造成的人脸表情图像识别问题。对于遮挡表情图像的噪声问题,文献[4]利用高斯滤波来除去归一化后人脸图像噪声,采用差值中心对称局部二值模式(Difference Center-Symmetric Local Direction Pattern)和差值局部方向模式(Difference Local Directional Pattern)提取特征,在JAFFE表情库进行实验,识别率达到85%以上。
2 基于面部重要区域的预处理
对于人脸表情识别来说,人脸面部中每个部分并不像在人脸识别中那样重要,仅使用重要的局部特征也可以实现表情图像的正确识别。文献[5]使用感兴趣区域(Region of Interest, ROI)方案对表情图像进行预处理,使得人脸表情识别的正确率提升了4%~5%,证明了局部面部区域对表情识别的有效性。Lian等[6]研究了局部面孔的表情识别,将人脸面部图像分为鼻子、嘴巴、眼睛、鼻子到嘴巴、鼻子到眼睛、嘴到眼睛以及整个脸部7个区域,如图5所示。
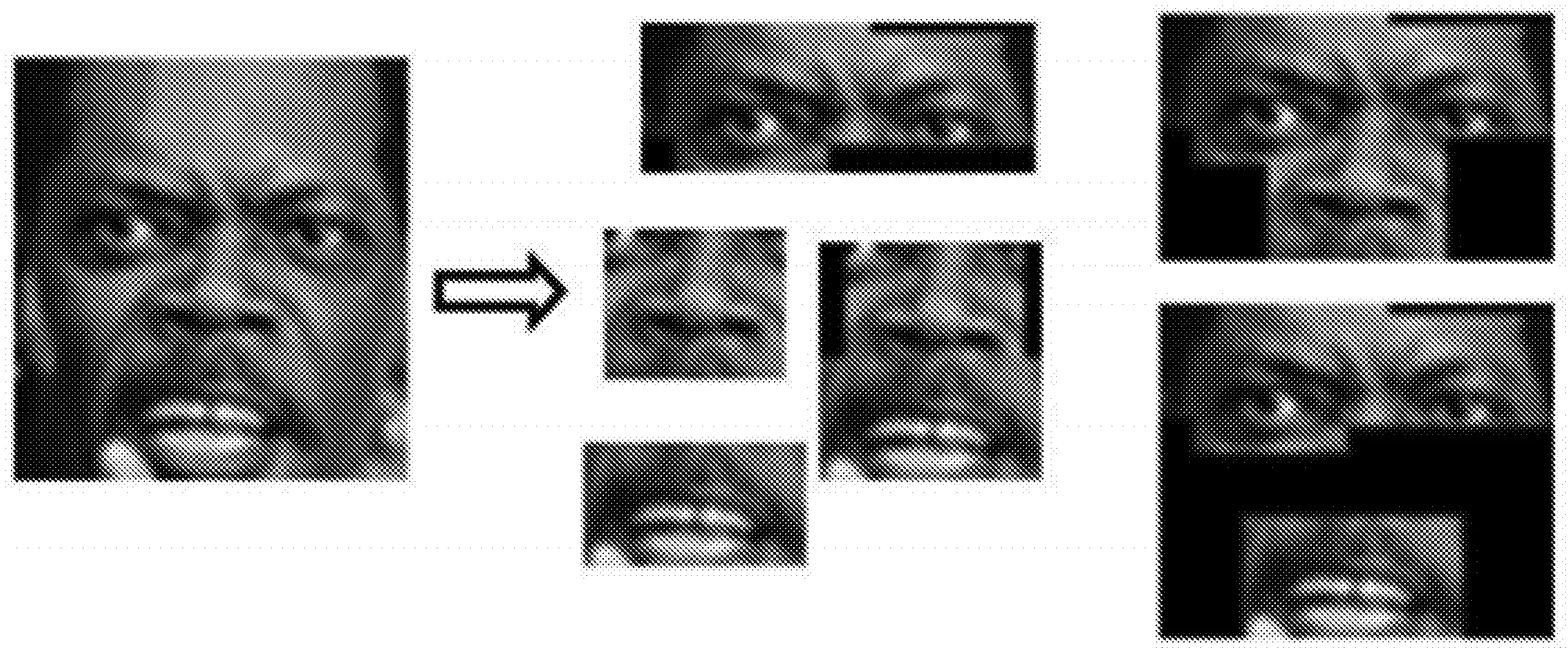
图5 整个面部区域以及被分成的7个子区域
通过混淆矩阵(Confusion Matrix)和类别激活图(Class activation Map)分析,发现嘴巴区域比其他区域包含更多情感信息,为遮挡图像的表情识别明确了更需关注的领域。
基于区域划分的三维面部表情识别算法很难将表情不变区域和表情易变区域准确划分,桑高丽等[7]提出多区域划分方法,将人脸区域划分为多个可重叠的模板区域,利用投票机制确定最终匹配结果。在Bosphorus数据库中遮挡人脸图像的识别率达到了良好效果。
人脸表情图像中的信息包括表情特征、身份特征和噪声等,将它们作为独立部分。董俊兰等[8]提出一种基于非凸低秩分解双字典误差模型(Non-convex Low Rank Decomposition Double Dictionary Error Model)的遮挡表情识别方法。非凸对数函数低秩分解可将每类表情图像的表情特征和身份特征分离,定义单个矩阵表示遮挡引起的误差,该矩阵可以从未遮挡图像特征矩阵中分离出来,测试样本中减去误差矩阵恢复情感分类阶段的图像,最后根据类别表情特征在联合稀疏表示的贡献量进行分类,这种方法对随机遮挡表情图像识别具有鲁棒性。
3 基于图像重构的预处理
常见的图像重构算法有压缩感知(Compressed Sensing, CS)、三维重构(3D Reconstruction)、主成分分析(Principal Component Analysis, PCA)等。CS可以大幅度降低图像数据,通过对图像整体进行重构提高图像质量,但并不适于遮挡人脸表情图像实现部分重构[9]。人脸图像本身具有三维特性,构建三维模型来处理图像问题具有一定有效性。文献[10]使用凹凸贴图对粗略估计的3D人脸模型进行分层,然后扩展到被遮挡的面部区域,生成合理的细节,该方法在查看状态下可以产生详细的3D面部形状。
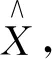
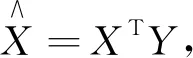
(1)
式中:Y----特征提取后降维的数据。
PCA在处理遮挡图像时没有对遮挡和非遮挡区域分开处理,导致重构图像受遮挡区域的影响较大。李瑞静[11]提出基于信息熵PCA的遮挡重构算法,定义了信息熵内积,
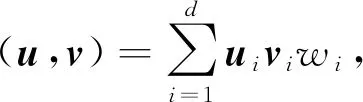
(2)
式中:u,v----特征向量;
w----估计图像遮挡区域的信息熵,信息熵值越大,信息量越大,利用公式对遮挡图像进行加权融合重构。
在JAFFE和CK库的识别率较PCA算法更高。
鲁棒主成分分析(Robust Principal Component Analysis, RPCA)是PCA的扩展,对异常值、数据丢失和观测值严重损坏等问题具有更强的鲁棒性。Ramìrez等[12]通过RPCA重建遮挡图像,并开发了一个Weber本地描述符(WLD)遮挡鲁棒的面部表情识别框架,通过实验证明RPCA提高了遮挡面部表情的识别率。
另外,还有一些其他人脸图像重构方法。文献[13]针对头戴式显示器(Head Mounted Display)带来的面部遮挡问题,介绍了一种仅使用RGB图像的解决方法,利用面部界标点来估计用户的脸部形状、表情和姿势,根据非遮挡区域信息恢复脸部纹理和当前场景照度;文献[14]分析基于机器自动面部表情分析的应用,介绍了早期常用的处理遮挡方法,基于面部的视觉配置重构遮挡部分缺失的几何或纹理特征。
4 基于深度学习的预处理
深度学习算法凭着良好的泛化能力,被广泛应用在各个领域,尤其是图像处理的人脸识别和表情识别。处理遮挡图像的常见模型有卷积神经网络(Convolutional Neural Networks, CNN)、生成对抗网络(Generative Adversarial Network, GAN)和原型网络(Prototypical Networks, PN)。
4.1 基于CNN的处理
Y Li等[15]提出一种基于注意力机制的卷积神经网络(Convolution Neural Network with Attention mechanism, ACNN),它可以感知遮挡区域,将主要注意力集中于未遮挡区域。其具体原理是通过pACNN(path-based ACNN)在卷积层中裁出人脸感兴趣区域,用PG-Unit学习其权值并判断,同时利用gACNN(global-local-based ACNN)整合区域。文献[16]创建了一个具有姿势和遮挡属性的人脸表情数据集,然后提出新型区域注意力(Region Attention Network, RAN),即由CNN产生的各区域特征聚合嵌入到固定长度表示,文献[17]在此基础上通过固定位置、随机和基于人脸关键点,将原始人脸图像裁剪成几个区域,新区域再和原始人脸图像一起输入到神经网络中进行特征提取,通过区域偏置损失函数(RB-Loss)确定人脸区域的注意力权值,达到良好的识别率。
Shi等[18]针对传统CS在随机采样过程中容易忽略信号特性和改进CS算法计算复杂度高等问题,提出基于卷积神经网络的CS框架(CSNet),该框架可以在图像中自适应学习采样矩阵,从而保留更多的图像结构信息。
4.2 基于GAN的处理
深度学习中生成对抗网络是良好的图像重构模型,具有良好的数据生成能力,其原理与“黑盒”相似,可以避免难题推断等问题[19]。文献[20]利用生成对抗网络修补破损区域,图像复原和判断流程如图6所示。

图6 基于GAN的人脸图像重构
遮挡图像通过生成器生成复原图像,复原图像和遮挡图像以及原始的完整图像通过分类器和判别器。与普通CNN比,识别率高出2.99个百分点。
王海涌[21]提出一种改进的GAN模型,利用自动编码器构成生成器和两个鉴别器,对遮挡人脸表情图像填充修复。实现随机遮挡50%以下的人脸图像达到84.56%的识别率,与PCA、稀疏表示方法(Sparse Representation)、CNN算法相比,该算法的识别率更高。但对遮挡面积超过50%的面部修复效果不佳,且对抗函数导致GAN的训练过程较难控制。文献[22]提出人脸局部遮挡图像进行用户无关表情识别的方法,利用Wassertein生成对抗网络(Wasserstein Generative Advertise Net)补全人脸图像,同时使用表情识别网络在表情识别和身份识别之间建立对抗关系,取得用户无关的表情特征并分类。
4.3 基于PN的处理
原型网络是针对机器学习需要大量训练样本的缺陷提出来的,它只需要训练集提供一个小样本的支持集,深度原型网络架构如图7所示[23]。
文献[24]指出在现实生活中遮挡图像的数据远少于完整的人脸图像,提出基于原型网络的识别方法,将遮挡人脸图像的表情识别问题分为几次学习问题,实现通过较少的训练样本从遮挡面部图像中识别表情。
5 相关数据库
充分了解数据库的特点,选择合适数据库,才能保证实验的科学性和严谨性。由于人脸表情库的数量很多,常用人脸数据库及其基本特点见表1。
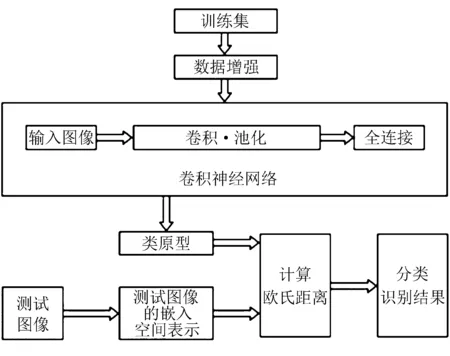
图7 深度原型网络架构

表1 常用人脸数据库及其基本特点
6 结 语
人脸表情图像预处理作为提高表情识别率的重要环节,关系到FER技术是否可以很好地用于日常生活中。遮挡表情图像的传统预处理方法只对图像大小、颜色等进行处理,没有对图像内容进行深入研究,没有从根本上解决遮挡给图像造成的问题;基于重要区域的预处理介绍了图像中影响表情识别较多的面部区域,遮挡表情图像可以侧重面部局部研究,还从三维图像和图像信息两个角度分别对遮挡表情图像划分区域,一定程度上提高了遮挡图像的表情识别率;基于图像重构的预处理介绍了常用的图像重构技术和用于遮挡表情图像重构算法及其改进算法;基于深度学习的预处理以不同的网络模型为基础,从不同角度介绍了遮挡表情图像的预处理,CNN通过改进其网络结构、计算等对遮挡图像处理,GAN及其改进算法通过图像重构或者修复破损区域处理遮挡表情图像,PN将其小样本训练的优势用于研究。
目前,遮挡表情图像的预处理在不同方向都有一定的研究成果,识别率都较传统的处理算法更高。未来研究可从以下几点进行:
1)遮挡图像的人脸识别有了一定的研究[25],但表情识别相较于人脸识别更侧重五官间的联系变化和面部纹理特征等,所以可以在遮挡人脸图像的基础上进一步研究,从而应用于遮挡表情图像。例如目前3D重构技术被广泛用于人脸图像重构,文献[26]提出一种多视角的3D面部重构框架,其中利用纹理约束提高了3D面部形状精确度,重构图像具有一定的鲁棒性。
2)语义环境是图像处理中的重要部分,研究自然场景中遮挡人脸表情图像同样可以合理对图像语义进行分析。文献[27]从光谱分割的角度提出一种包含图像纹理、颜色特征和神经网络生成高级语义信息的图形结构,该结构可以使图像自动生成语义软段,从而进行图像编辑。X Zhan等[28]针对自然环境遮挡图像的语义研究提出的部分补全网络具有良好的借鉴意义。
