基于BP神经网络与Kriging结合的土壤有机质空间分布模拟
——以福建省华安县为例
2021-05-17张宏帅朱高龙吴家煜吴锡麟
张宏帅, 朱高龙, 吴家煜, 吴锡麟
(1.福州大学空间数据挖掘与信息共享教育部重点实验室,福建 福州 350108; 2.闽江学院海洋学院,福建 福州 350108)
耕地土壤有机质是农作物生长的重要物质基础之一。土壤有机质含量是监测土壤肥力的重要指标之一,很大程度上决定了农田的肥力状态[1-2]。快速精准地掌握耕地土壤有机质的空间分布,对于提高农田的水肥利用效率与改善田间管理,推进“精准农业”具有重要意义[3]。土壤有机质的涵养、运移、分布是复杂的物理、化学和生物过程,受气候、地貌、地下水、微生物以及土壤类型、土地利用方式等多种地表环境因素的共同作用[4-7],这些因素可以分为定量因素(如海拔高度、坡度、地理坐标等)和定性因素(如土壤类型、土地利用等)两种类型。
引入外界辅助变量可在一定程度上提高土壤有机质空间分布的预测精度[8]。在引入外界辅助信息进行土壤有机质空间分布的预测方法中,回归克里金法(regression Kriging, RK)应用较为广泛[9-10]。RK法主要利用多元线性回归得到辅助信息与目标变量的回归方程,能够给出最优线性无偏估计,但难以模拟土壤有机质含量的影响因素之间的非线性和复杂性。近年来随着神经网络算法的迅速发展,尤其是BP神经网络,具有强大的非线性运算能力为预测土壤有机质含量提供了新方法[11]。江叶枫等[12]以地理坐标、高程和坡度及邻近样点信息作为网络的输入变量,研究表明集成BP神经网络模型预测效果最好。刘二永等[13]结合外界环境因子,利用回归—光滑薄板样条插值法得到了较好的预测结果。George et al[14]研究发现,利用可见—近红外高光谱反射率构建人工神经网络模型可快速准确地预测有机质的空间分布。目前大多数预测模型仅仅引入定量因素,忽略了定性因素对有机质空间分布的影响,在一定程度上影响预测结果的精度[15]。
本文以漳州市华安县为例,利用与县域尺度土壤有机质含量紧密相关的土壤类型、土壤质地、土地利用、海拔高度、地形坡度等数据,采用BP神经网络与克里金插值相结合的方法(BP_OK)进行耕地土壤有机质空间分布模拟,并与回归克里金插值法(RK)、普通克里金插值法(ordinary Kriging, OK)对比,探索县域尺度上快速准确获取土壤有机质空间分布的新方法。
1 材料与方法
1.1 研究区概况
华安县位于福建省漳州市西北部,九龙江北溪中游,地理坐标为117°15′~117°42′E、24°38′~24°15′N。华安县地貌以山地、丘陵为主,占全县总面积的95.5%,台地平原仅分布在南部,占4.5%。根据2018年度华安县土地利用现状图(http://www.dsac.cn/)统计,华安县土地总面积127 760.49 hm2,其中耕地面积16 166.13 hm2,占土地总面积的12.65%。耕地以水田为主,面积15 129.60 hm2,占耕地总面积的93.59%;旱地1 035.33 hm2,占耕地总面积的6.40%;水浇地1.20 hm2,占耕地总面积的0.01%。受地形影响,耕地类型主要包括山垄田、洋面田、梯田、溪边田等。根据第2次土壤普查结果(http://vdb3.soil.csdb.cn/),华安县耕地土壤类型可分为红壤、水稻土、赤红壤和黄壤,其中红壤面积(约7 518 hm2)最大,水稻土面积(约5 774 hm2)其次,赤红壤约2 668 hm2,黄壤约206 hm2,分别约占耕地总面积的46.51%、35.72%、16.50%、1.27%。
1.2 数据来源及处理
1.2.1 土壤有机质数据 样地土壤有机质含量数据来源于2014—2018年华安县耕地质量等别年度更新评价中的实地采样数据。所有样地采样均在每年秋收后进行,在边长为10 m的正方形样地内采用梅花形采样法布设5个样点,每个样点使用土钻获取表层0~20 cm深度的土样。每个样地的土样经充分混合后,利用四分法取1 kg混合土样送往实验室,利用重铬酸钾外加热法[16]测定该样地的土壤有机质含量。全县共采集215个有效样点,其中185个用于空间插值建模,30个用于模型精度验证(图1)。全县土壤样点有机质含量最小值为10.00 g·kg-1,最大值为36.92 g·kg-1,平均含量为21.07 g·kg-1,变异系数为30.85%,属于中等性变异,说明华安县耕地土壤有机质存在中等程度的空间变异性。
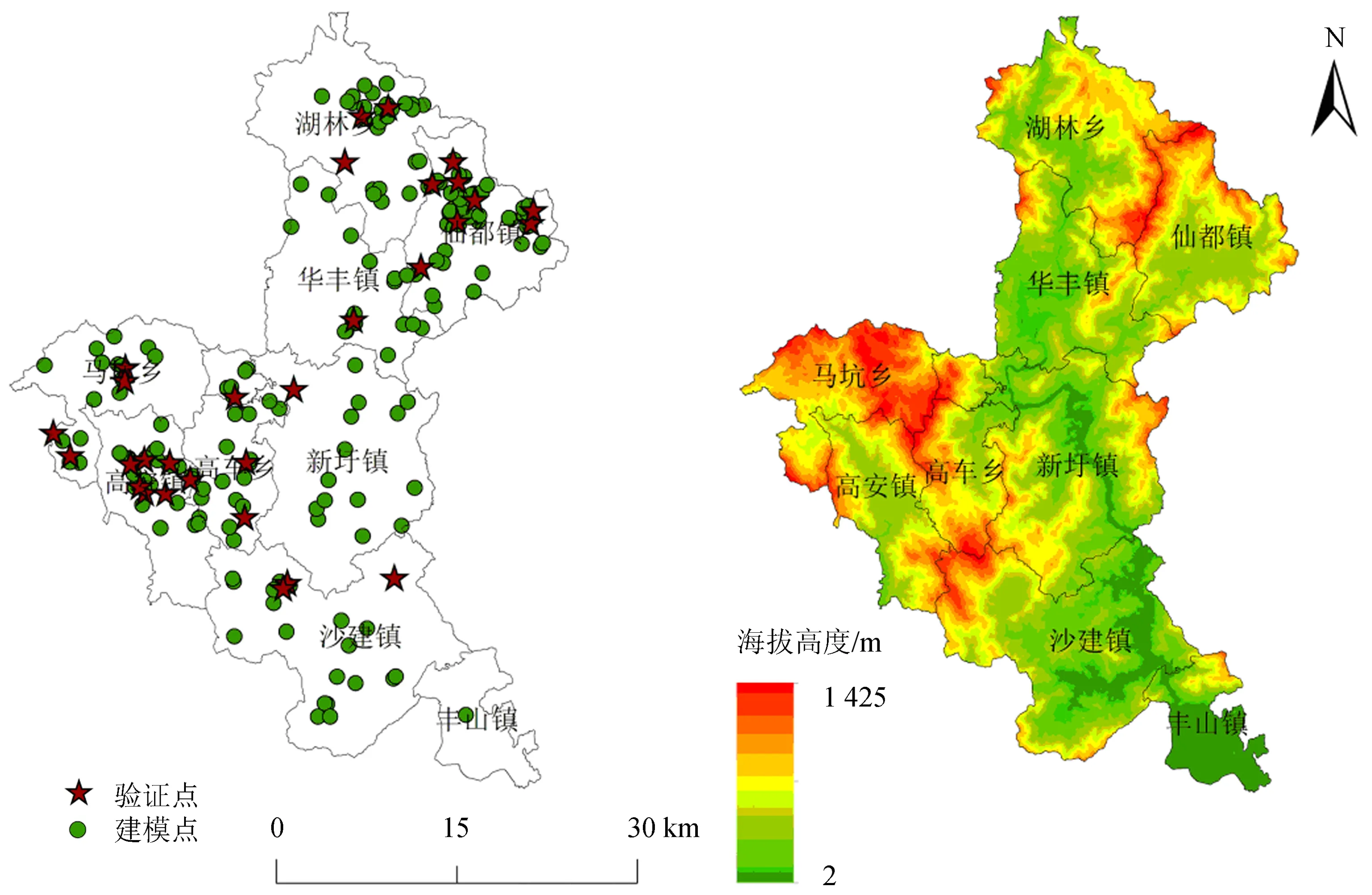
图1 华安县耕地土壤有机质样地及海拔高度分布图Figure1 Distribution map of cultivated soil organic matter plot and altitude in Hua′an County
1.2.2 基础地理数据 土地利用类型采用了2018年度华安县土地利用现状图中水田、旱地、水浇地3种二级地类。海拔高度采用从地理空间数据云(http://www.gscloud.cn/)下载的30 m空间分辨率的ASTER GDEM数据,坡度由ASTER GDEM数据在ArcGIS 10.2中生成导出。土壤类型、土壤质地数据来自于全国第2次土壤普查,其中土壤质地数据为砂土、粉砂土与黏土所占的百分比。上述影响因素的图层均重采样为30 m空间分辨率的栅格数据,用于土壤有机质空间插值分析。
1.3 研究方法
1.3.1 虚拟变量的引入 土壤类型、土地利用、土壤质地等因素在很大程度上影响着土壤有机质的空间分布,因此在预测过程中应综合考虑这些因素所带来的影响。与海拔高度、坡度等连续型变量不同的是,土壤类型、土地利用为定性变量中的分类变量,其数值只代表不同分类,需要将其转换为虚拟变量代入回归分析[17]。将虚拟变量引入回归模型,虽然使模型变得较为复杂,但可以更直观地反映出该自变量的不同属性对因变量的影响,提高了模型的精度和准确度。
虚拟变量取值通常为0、1,其数值用来反映某个变量的不同属性,不代表实际大小[18]。在回归分析中,定义虚拟变量时为了避免共线性,当回归模型包含截距时,如果变量具有n个分类,需定义n-1个虚拟变量来表示这些类别[19]。其赋值方法有多种,本研究选取的赋值方法为:
(1)
式(1)中,Xi为分类变量,i表示分类变量下的不同属性,通常需选取分类变量中的某一属性作为参考类型,且该属性应有一定的样本量。本研究中将土壤类型和土地利用转换为虚拟变量。土壤类型选取水稻土、红壤、赤红壤三类,以水稻土为参考类型;耕地利用类型选取水田和旱地两类,以旱地为参考类型。
1.3.2 OK插值 OK插值是基于变异函数模型在有限区域内对区域化变量的取值进行无偏最优估计的空间插值方法,是地统计学的主要内容之一[20]。该方法克服了经典统计学将地学变量看成纯随机变量而忽略其空间相关性的不足,降低了估计误差。经检验,本研究样本数据近似符合正态分布,满足地统计学的基本要求,再利用地统计模块选择最佳半变异函数模型参数,在ArcGIS 10.2中完成OK插值过程。
1.3.3 RK插值 RK插值首先通过分析外界环境变量与目标变量之间的关系,然后利用多元逐步回归分析得到一个线性回归方程;再通过该方程得到关于确定性部分的趋势项以及代表随机部分的残差项,将残差项作为一个新的随机变量进行克里金插值,最后将趋势项和残差项进行叠加,即得到该区域的土壤有机质的空间分布模拟图。其过程可表示为:
f(x)=m(x)-ε(x)
(2)
式(2)中,f(x)为RK插值在点x处的土壤有机质预测值;m(x)为在x处经多元逐步回归得到的趋势项;ε(x)为克里金插值在x处的残差项。
在回归分析输入虚拟变量的过程中,为确保所有虚拟变量具有正确的含义,需要使用强制进入法以保证所有虚拟变量都能留在最后的模型中。其回归过程如表1所示。由于砂土、粉砂土和黏土为百分比数据,其总和为1,三者存在共线性,因此在回归过程中剔除黏土数据。最大方差膨胀系数(variance inflation factor, VIF)为4.021,小于10,说明变量之间不存在共线性。标准化前系数是拟合方程的实际参数,而标准化后参数的大小说明了自变量对因变量的重要程度[21]。在α=0.05的检验水准下,土地利用和土壤类型虚拟变量的回归系数检验P值均小于0.05,说明不同分类下土壤有机质含量(SOM)存在显著差异。最终选取的回归模型为:
SOM=40.163+5.432x1-34.714x2-30.235x3+0.008x4-0.143x5-2.392x6-5.154x7
(3)
式(3)中,SOM为土壤有机质含量(g·kg-1);x1为水田,x2为砂土,x3为粉砂土,x4为海拔高度,x5为坡度,x6为红壤,x7为赤红壤。
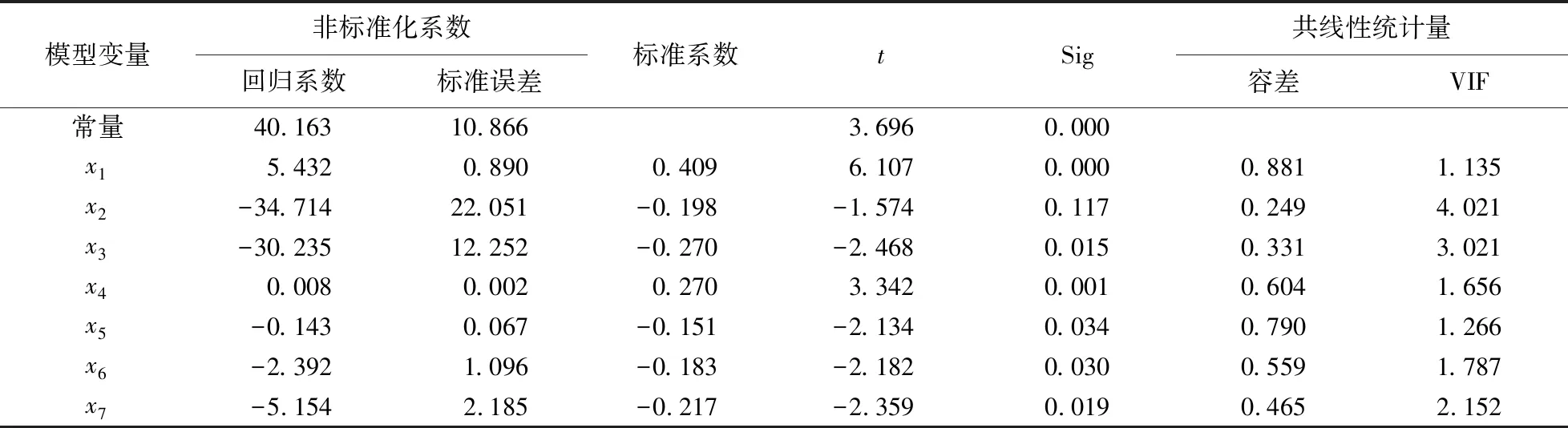
表1 RK插值回归过程1)Table 1 RK interpolation regression process
1.3.4 BP_OK 插值 BP_OK 插值模型是将BP神经网络与克里金插值相结合的一种方法,其原理与RK插值相似,但其中趋势项为BP神经网络计算的预测结果。BP神经网络是一种多层前馈神经网络,采用后向传播学习算法,是目前应用最多也是最成功的神经网络之一[22-23]。其模型由输入层、隐含层和输出层组成,相邻层的神经元之间基于权重系数进行相互连接,同一层内部的神经元是平行的、相互之间没有连接关系[24]。根据实际需要可选择单层神经网络和多层神经网络。在神经网络预测中,首先读取训练数据和测试数据,利用Python编程实现BP神经网络训练。训练方式选择梯度下降方法,激活函数为Relu函数,通过调节隐含层个数及节点数、学习率、迭代次数等参数,确定最优模型。由试验可知,当迭代次数在500左右时,其损失函数趋于稳定。采用双隐含层结构(第1个隐含层为11个节点,第2个隐含层为5个节点),学习率为0.01时预测模型最好。再将整个研究区的栅格数据输入到训练好的模型中,最终以图像格式输出研究区的土壤有机质含量分布图。
1.3.5 精度评价 为验证实验结果的预测精度,随机选取30个土壤有机质样点作为验证样本,以均方根误差(RMSE)、平均绝对误差(MAE)及相关系数(R)作为精度评价标准。
(4)
(5)
(6)
2 结果与分析
2.1 土壤有机质空间插值模型
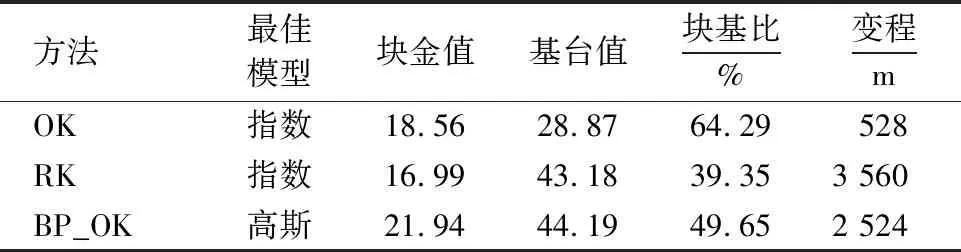
表2 3种插值方法的最佳理论模型Table 2 Optimal theoretical models of three interpolation methods
表2列出了3种插值方法最佳模型的块金值、基台值、块基比和变程。OK、RK法最佳理论模型为指数模型,BP_OK法最佳理论模型为高斯模型。3种方法的块基比均在25%~75%之间,表现为中等强度的空间依赖性[25],说明该研究区土壤有机质空间分布受自然因素和人为因素的双重影响。OK插值变程为528 m,相对较小,说明其空间自相关性较小,这与华安县复杂地形地貌空间结构特征相符合;RK、BP_OK插值变程相对较大,分别为3 560、2 524 m,说明结合辅助因素后削弱了外界因素的影响,插值点的空间自相关范围变大。将残差插值结果与趋势面进行栅格运算叠加,并由土地利用矢量图斑裁剪可得出该区域的耕地土壤有机质含量空间分布。
2.2 土壤有机质的空间分布特征
由图2可知,3种插值方法得出的土壤有机质含量空间分布规律基本一致,总体上呈现北部和西部较高、南部及中部偏低的空间格局。这与地貌类型空间分布特征基本吻合,其中高值区主要分布在仙都镇、高车乡、湖林乡东部及马坑乡东部,低值区主要分布在华丰镇、沙建镇、丰山镇。3种插值方法得到的低值区分布面积依次为:OK>RK>BP_OK,高值区分布面积依次为:RK>BP_OK>OK。但是,不论高值区或低值区,OK插值结果都明显小于RK法和BP_OK法。从视觉效果上看,OK插值呈块状分布,不同区域(高值区、低值区)之间分级明显,低值区主要出现在海拔较低的平原区,高值区主要分布在海拔较高的山地、丘陵区,这与华安县海拔高度变化情况相吻合。由于OK法仅考虑有限样点的空间相关性,无法拟合局部变异现象,只能反映研究区土壤有机质空间变异的总体趋势。RK法和BP_OK法插值结果局部空间变化相对显著,均在一定程度上缓和了OK插值块状图斑现象,这是因为BP_RK法与RK法采取逐个像元计算的方法,充分利用了自然因素及人为因素对土壤有机质含量空间分布影响的先验知识,弥补了样点数据有限的问题,能够反映因局地因素变化而导致的土壤有机质含量的空间分异现象。
3种插值方法中,OK插值的有机质含量值域范围最小,最小值为13.94 g·kg-1,最大值为28.41 g·kg-1,主要集中在15~25 g·kg-1之间,平均值最小(20.88 g·kg-1)。RK插值的有机质含量最小值、最大值、平均值分别为7.00、43.80、23.35 g·kg-1,其值域范围和平均值在3种插值方法中都最大。BP_RK插值结果位于OK法和RK法之间,有机质含量最小值、最大值、平均值分别为9.94、32.69、22.71 g·kg-1。从地貌上看,山地区平均有机质含量最高、丘陵区次之、平原区最低,表现为土壤有机质含量与海拔高度呈正相关,这与前人研究成果相一致[26-27],主要是因为高海拔地区有利于土壤有机质的积累。从土地利用上看,水田的有机质含量明显高于旱地,说明耕作方式导致土壤有机质含量在空间分布上存在差异。从土壤类型上看,水稻土有机质含量最高、红壤次之、赤红壤最低, 这与建模样点具有同样的空间分布特征。
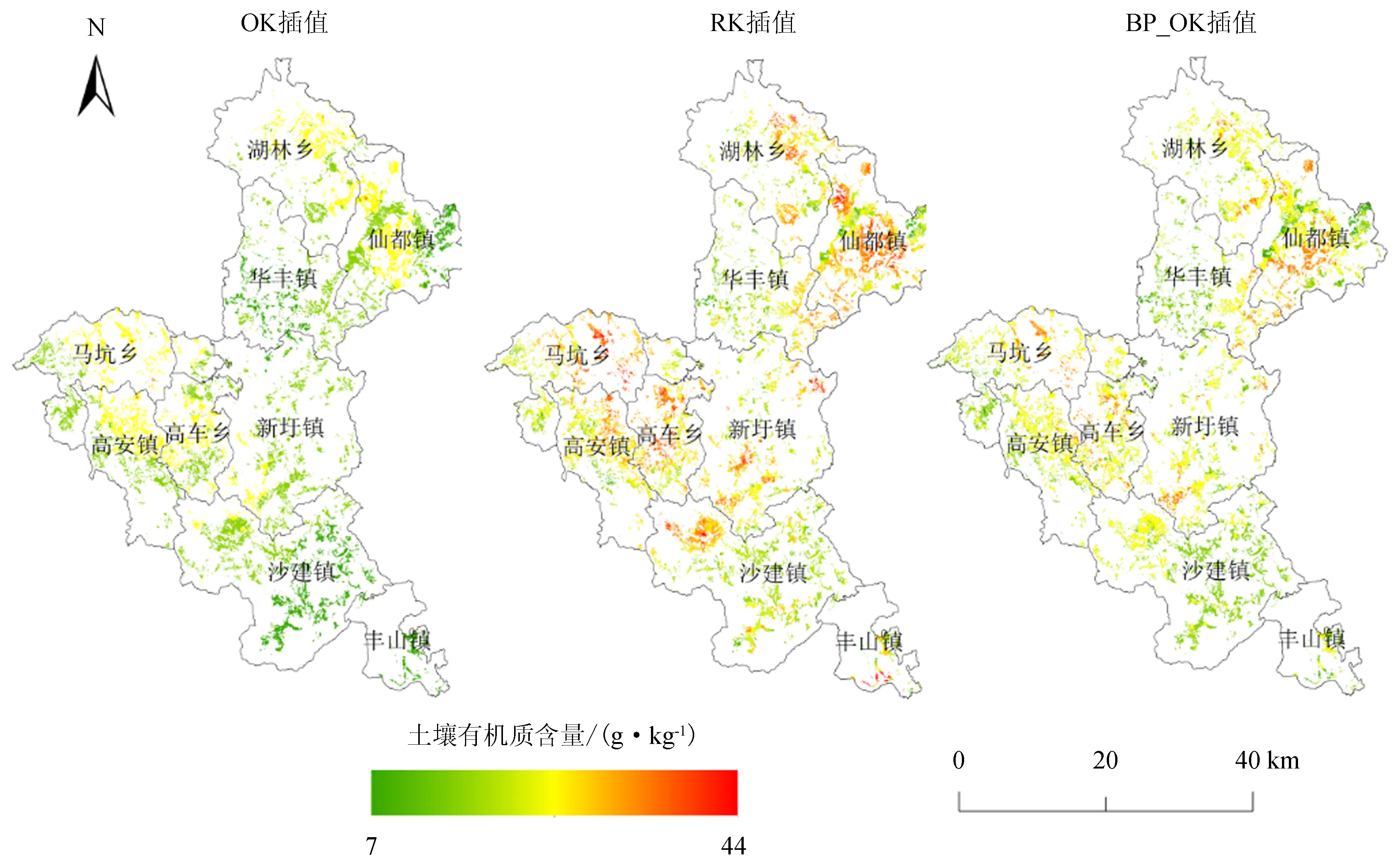
图2 不同插值方法的华安县耕地土壤有机质空间分布图Figure 2 Spatial distribution map of cultivated soil organic matter by different interpolation methods
2.3 精度分析
利用30个土壤有机质样点验证不同插值方法的预测精度(表3)。从表3可见,3种插值方法的RMSE分别为3.55、3.73、4.92 g·kg-1,以BP_OK法最小,表明预测值离散程度最小;MAE分别为2.96、3.06、4.02 g·kg-1,以BP_OK法最小,说明整体上其预测值与实测值最为接近;R分别为0.72、0.68、0.35,表明BP_OK法和RK法预测值与实测值呈高度相关,OK法表现为中等相关。综上可知,结合土壤类型、土壤质地、土地利用、海拔高度和地形坡度等辅助信息的BP_OK法、RK法插值精度明显优于仅考虑样点空间自相关性的OK插值法。与RK插值结果相比,BP_OK插值结果的预测值和实测值相关系数更高,预测值RMSE、MAE更小。以上表明,BP_OK法整体拟合效果最优,这是因为BP神经网络具有高度非线性和较强的泛化能力,能以任意精度逼近任意连续函数,能够更好地拟合输入数据与土壤有机质含量的影响因素的非线性关系,具有较好的预测能力。BP_OK法可以有效提高县域尺度下耕地土壤有机质空间分布模拟精度。
3 讨论
OK法是土壤有机质空间分布模型中最常用的方法,能够从变量自身出发,充分考虑有机质的空间变异,利用邻近采样点之间的相关性来预测未知点,并且能够统计预测结果的误差,因此在土壤属性的空间预测中得到广泛应用。姜赛平等[28]认为,OK插值结果不够精细,图斑较大,不能刻画土壤有机质含量的细部特征,仅能预测有机质含量整体空间分布,通常适用于土壤属性变化较为均匀的区域,这与本研究结果相一致。
在地貌特征复杂的地区,土壤有机质的空间分布更受限于外界人为因素和自然因素的影响,仅仅依靠采样点的空间自相关性往往不能准确模拟土壤有机质的空间分布。因此,很多学者尝试利用结合外界辅助信息的空间插值方法如回归模型、 地理加权回归模型、神经网络模型等,预测土壤有机质的空间分布,均在不同程度上提高了有机质的空间预测精度。回归模型不仅能够筛选出对有机质含量有显著性影响的环境因子而建立模型,还能利用残差信息进行普通克里金插值,考虑了对结构性和随机性的空间模拟[29],地理加权回归模型克服了回归模型中不同空间位置的环境因子权重一致的不足,提高了插值精度[30];神经网络模型能够刻画外界因素与土壤有机质含量之间的非线性关系,更加切合实际[31]。
多数学者通常选取海拔高度、坡度、地理坐标、邻近信息等定量因素作为预测模型的输入信息,而忽略了土地利用、土壤类型等定性因素对土壤有机质的影响,而在地貌特征复杂的南方地区,土壤有机质含量很大程度上取决于土地利用类型和土壤类型。本文将土壤类型、土地利用等定性因素转化为虚拟变量,再结合土壤质地、海拔高度、坡度等定量因素引入RK和BP_OK插值模型,其插值精度明显优于仅依靠有限采样点之间空间相关性的OK插值法,证明了该方法引入的各种定量和定性先验知识,可有效提高土壤有机质含量空间插值精度,且可弥补样点信息量不足,反映局地范围土壤有机质含量的空间分异变化。
从模型的精度及性能上看,BP_OK插值精度较高,但存在需要反复训练、不断调节参数才能使模型收敛的问题,而RK插值训练过程简练、计算量少,相关因素与土壤有机质含量之间的关系可用公式具体表示,能够直观地看出每种因素对土壤有机质含量的影响,但模型过于简单,在一定程度上不能准确地描述外界因素与土壤有机质之间的真实关系。
受限于县域尺度耕地土壤有机质含量影响因素的可获取性以及空间分辨率的要求,本文仅考虑了与土壤有机质含量密切相关的土壤类型、土壤质地、土地利用、海拔高度、地形坡度等5种因素。实际上,耕地土壤有机质含量影响因素复杂多样,除了土壤类型、质地、微生物、pH值等土壤本身各种属性外,还包括影响土壤发育的各种自然环境因素如气候、母质、地貌、植被和地下水等,以及强烈的人为干扰,如施肥、灌溉、耕作制度和利用方式等。引入更多更全面的外部辅助信息,有助于提高土壤有机质含量空间插值精度,但是引入影响因素较多,各因素之间可能存在相关性,则需要消除冗余数据、降低模型复杂度,进一步提升模型预测能力。
4 结论
本文以华安县为研究区,结合外界定性、定量因素,构建了基于非线性拟合的BP_OK插值法,并以OK法、基于线性拟合的RK插值法为参照,对华安县耕地土壤有机质进行空间分布模拟。插值结果显示,华安县耕地土壤有机质在整体上呈现北部和西部较高,南部及中部偏低的空间分布特征,这与地貌特征、土地利用类型和土壤类型密切相关。验证结果显示,构建结合外界因素插值模型的BP_OK法和RK法其插值精度较OK法有明显提高,说明外界因素对有机质的空间分布有重要影响;BP_OK插值结果的RMSE、MAE及R等精度指标均优于RK插值结果,说明了BP神经网络与克里金插值相结合的非线性拟合法优于多元线性回归克里金插值法,这是因为线性模型难以模拟土壤影响因子之间复杂的非线性关系,BP神经网络具有非线性映射能力,可以进一步提高县域尺度下耕地土壤有机质空间分布模拟精度。
