关联规则挖掘在高校智慧图书馆个性化服务中的应用研究
2021-05-14蒋天民
蒋天民,王 英
(南通大学,江苏 南通 226019)
智慧图书馆是近几年对图书馆未来发展方向提出的一个新概念,未来的图书馆将不拘泥于空间的限制并且可以被用户切实的感知。这种感知指的是更广泛的互联互通以及在此基础上的智慧化的管理和服务,使用户或读者在这个体系之内能够体验更加贴心的个性化服务。日新月异的科技给网络资源的容量带来了几何级的激增,如何从海量的信息中检索到自己所需要的信息成为人们需要面临的新的问题。智慧图书馆的策略就是通过技术的调整和改进以及信息重组来为用户提供“智慧”的信息服务,以解决用户的需求。这个技术调整和改进以及信息重组的过程就是数据挖掘的过程[1]。
数据挖掘技术是结合了统计方法、计算机技术、人工智能等构成的一种新兴学科[2]。数据挖掘来源于统计分析,是统计分析方法的扩展和延伸。大多数的统计分析技术都基于完善的数学理论和高超的技巧,其预测的准确程度还是令人满意的,但对于使用者的知识要求比较高。而随着计算机能力的不断发展,数据挖掘可以利用相对简单和固定程序完成同样的功能。新的计算算法的产生如神经网络、决策树使人们不需了解到其内部复杂的原理也可以通过这些方法获得良好的分析和预测效果[3]。
数据挖掘的海量基础数据来自各个应用系统的数据库数据,这些应用系统的数据库必须具备高速的存储技术以及高效的索引技术,可以提供海量数据的高性能(并行)查询,并且使用诸如分布式技术和爬虫技术,以快速抓取海量的网络信息数据。与图书馆的发展相比较,数据挖掘技术从计算机科学发展至今已有十多年的历史。从20世纪70年代开始,数据挖掘技术逐渐在图书馆中展开全方位的应用。在国内,数字图书馆的诞生和发展得益于互联网的高速发展[4]。随着数字资源总量和数据库数量的高速增长,数据库自动化管理系统随之进入高校图书馆。所以,数据挖掘技术应用的基础条件已基本具备,伴随着数据挖掘技术应用的不断拓展,在高校图书馆信息管理和信息服务的水平也得到了巨大的提升。
1 数据挖掘的基本算法
1.1 数据挖掘的定义
目前,数据挖掘有许多种定义。简要来说,数据挖掘就是从海量数据中提取或挖掘知识。通常数据挖掘系统包含图1中所示的若干组件。
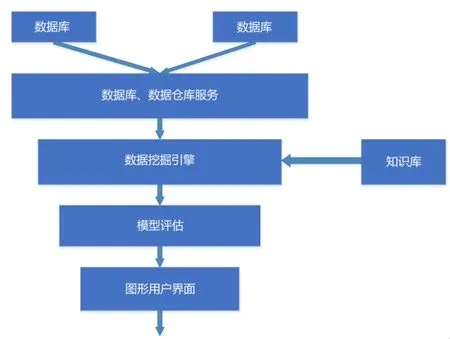
图1 数据挖掘的组成
数据挖掘包括了以下这些学科和技术:数据库技术、机器学习、人工神经网络、模式识别、数据图形化、空间数据分析、统计学、图像和信号处理、知识抽取等。数据挖掘系统除了包括以上这些学科和技术之外,甚至还应用到了心理学、经济学等。
数据挖掘是可以从数据库中提取有趣的知识规律或深层信息来发现的知识,可以用于决策,过程控制,信息管理,查询处理。这些规律和知识可以应用到零售业、制造业、财务金融保险、通讯及医疗服务等领域。数据挖掘系统是用来研究和了解数据挖掘规律性的工具。作为一个多学科交叉的领域,数据挖掘被认为是信息产业21世纪最有前途的学科。
1.2 数据挖掘过程
数据挖掘是通过计算机处理、人工分析等方法进行人机交互的过程,并且是完备且可迭代的,该过程主要包含了以下几个步骤(如图2所示):数据准备、数据筛选、数据预处理、数据挖掘、模型转换和评估[5]。
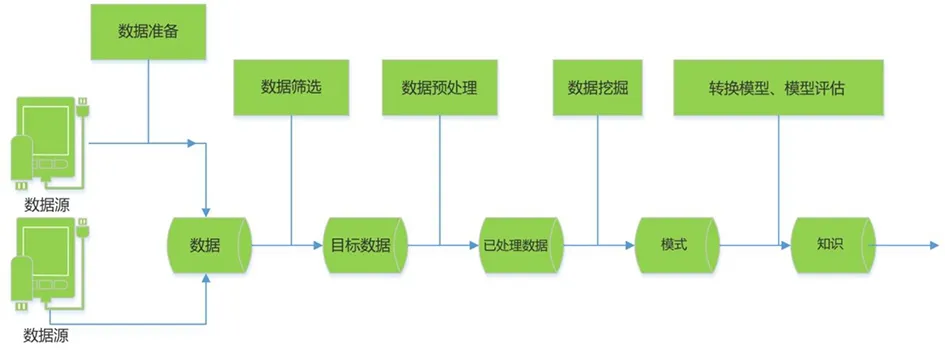
图2 数据挖掘过程
1.3 数据挖掘算法之关联规则分析
关联规则指的是两个或多个变量的相关性规则特征。数据库中的数据之间通常不是孤立的存在,而是存在某种关联。相关性分析是通过分析来发现数据之间的相关性特征,从而获得数据之间的依赖,以便于今后的数据设计和分析。关联规则主要由两个阶段组成:①分析数据并获取数据集中的高频名称;②从这些高频名称中产生关联规则。
通过从关联规则中分析结果,并在个性化图书馆管理系统中采用关联规则,可以帮助图书馆快速找到与当前正在发生的问题的相关事件,还可以通过分析读者的检索内容来获得当前读者用户的信息,以便将相关内容更有效地推送给读者[6]。
1.4 常用的关联规则算法之Apriori算法
1993年R.Agrawal等人首次提出了挖掘顾客交易数据中项目集间的关联规则问题,其核心是基于两阶段频繁集思想的递推算法。该关联规则在分类上属于单维、单层及布尔关联规则,这就是经典的Aprior算法。Aprior算法将发现关联规则的过程分为两个步骤:第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;第二步利用频繁项集构造出满足用户最小信任度的规则。其中,挖掘或识别出所有频繁项集是该算法的核心,占整个计算量的大部分[7]。
Apriori算法思路简单,使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描数据库,累积每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记作L1,然后,L1用于找频繁2项集的集合L2,L2用于找L3,如此迭代,直到不能再找到频繁k项集。找每个Lk需要一次数据库全扫描。
算法下一步是基于频繁项集挖掘关联规则。置信度大于最小置信度的规则称为频繁关联规则。在算法挖掘出的所有关联规则中,既可能是频繁关联规则也可能是非频繁关联规则。然后,将挖掘出的规则的置信度与最小置信度进行比较,大于最小置信度的关联规则即为频繁关联规则[8]。
2 高校智慧图书馆个性化服务模型
2.1 个性化服务模型
高校图书馆不仅是各种实体文献资源和数字资源的存储地,同时,它还承担了学术信息交流中心的角色,为广大师生提供知识服务。智慧图书馆是一种数字化、网络化、智能化的信息科学为基本手段的,有着更加高效和便利特点的一种图书馆运行模式,它的最本真的追求就是用最绿色的方式和数字化的手段来实现阅读。它是未来新型图书馆的发展模式,能实现广阔的互联以及共享,它以人为本,进行智慧化的管理和服务。智慧图书馆提供的是智慧服务,而智慧服务的最本质特征就是完成实时的增值,让知识服务的内涵得以升华,这对于人类的可持续发展有着极其重要的意义[9]。
基于关联规则挖掘的图书馆个性化服务模型(如图3)包含3个功能模块:数据处理、关联规则挖掘、个性化服务。数据处理是第一步,包含了数据导入、数据整合、数据清洗、数据过滤、数据转换、数据归约。第一步过程对于后序关联规则挖掘的效果将起到至关重要的作用。第二步,挖掘读者与图书关系的关联规则以及图书与读者关系的关联规则,建立读者特征和借阅的图书以及图书和图书之间的关联模型。第三步,在读者个性化服务中应用前面挖掘到的关联规则。
该模型主要实现了两个功能:①关联规则挖掘功能。通过挖掘读者的借阅历史来发现某些有价值的关联规则,归纳出隐藏的规则。②个性化服务功能。将上一步中得到的关联规则落实到具体的智慧图书馆的个性化推荐服务中去。平台采用B/S模式,服务器操作系统选择Windows Server 2008。开发环境使用Visual Studio 2010,开发语言选择C#。读者数据存储工具选择SQL Server 2008数据库。关联规则挖掘算法选择Microsoft关联算法[10]。

图3 图书馆个性化服务模型
2.2 高校图书借阅数据中的关联规则应用
高校智慧图书馆管理系统是同时服务于读者用户和图书馆管理者的最重要的信息系统,是图书馆管理工作中非常重要的一环。因此,高校智慧图书馆管理系统必须能为管理者和读者提供及时又充分的信息。高校智慧图书馆常见的信息系统有:图书管理系统、书刊流通系统、书刊查询系统、读者管理系统、费用管理系统。因为都是关系型数据库,所以每个系统都由若干关系表组成。以上这么多信息系统中连接读者(读者借阅历史)和书刊(书刊更新、借阅、归还)之间关系最重要的一个信息系统就是书刊流通系统。笔者讨论的数据挖掘都是基于这部分数据的开发[11]。
通过对读者借阅历史(即图书流通数据)挖掘关联规则的目的是通过分析关联规则来归纳出诸如以下规律:①了解读者的特点和他们借阅图书的规律。调查读者的性别、年龄、专业和其他影响借阅图书的各种属性,从中归纳出读者更有借阅意向的图书特征,可以更有针对性地向读者荐阅图书期刊,这对读者和智慧图书馆的服务工作都具有重要意义。②通过发掘业务数据库中借阅历史之间的关联可以分析出读者的借阅习惯。举例如下:通过挖掘关联规则得到了图书A和图书B之间的某种借阅关系,即图书A的读者中有70%也借了图书B。那么就可以将图书B推荐给借了图书A的读者。合理安排优秀的图书可以增加借阅量和指导读者购买。
利用原始数据来挖掘关联规则的过程也有另一种更广义的说法叫知识发现(KDD:Knowledge Discovery in Database)。图4展示了知识发现的过程。知识发现可以归为3个部分:知识预处理、数据挖掘、结果的解释和评估(解释和评估)。

图4 知识发现过程
2.3 Microsoft关联算法
Microsoft 关联规则算法是Apriori 算法的简单实现,该算法需要合理设定参数,会极大地影响关联规则挖掘的数量。和该算法密切相关的参数有以下几方面。
2.3.1 支持度。 支持度是一个项集或者规则在所有事物中出现的频率,确定规则可以用于给定数据集的频繁程度。对生成规则无影响,对生成项集有影响。项集{A,B}的支持度是包含A和B的所有交易数总和。表达式为:
support(A⟹B)=p(A∪B)=NumbeofTransaction(A,B)
(1)
2.3.2 置信度。 一些文献中也称为概率或可信度。在发生事件A的条件下发生事件B的概率,该规则表达式如下:
probablity(A⟹B)=probablity(B|A)=p(A∪B)/p(A)=NumbeofTransaction(A,B)/TotalNumbeofTransaction
(2)
最小置信度是指,用户只对满足特定频率的规则感兴趣。它的值和最小支持度是相同的。置信度影响规则的生成,但不影响项集的生成。生成的规则数量取决于设置的最小置信度的值[12]。
2.3.3 增益。 一些文献中也叫作兴趣度分数或重要性,对项集和规则的生成、项集的增益、规则的增益都有影响。项集的增益用以下公式定义:
importance(A⟹B)=p(B|A)/p(B)=[probablity(A,B)/probablity(A)*probablity(B)]
(3)
它描述了项集A对项集B的影响程度。它的值域是[0,∞]。如果增益等于1,代表事件A和事件B是相互独立的。如果增益小于1,代表事件A和事件B是负相关的,如果发生了事件A就不可能发生事件B。如果增益大于1,代表事件A和事件B是正相关的,如果发生了事件A也有可能发生事件B。规则的重要性公式为:
importance(A⟹B)=log(P(B/A)/P(B/notA))
(4)
该公式表示:如果增益为0,代表事件A和事件B相互独立。如果值为正代表事件A为真时,事件B的概率会增加。如果值为负代表事件A为真时,事件B的概率会减小。
3 关联规则的挖掘
3.1 图书借阅数据的来源
笔者选取了南通大学图书馆的数据作为研究对象,挖掘关联规则的数据来源于南通大学图书馆汇文管理系统中的读者借阅记录。选取了2014年1月1日~2018年12月31日之间分类号为TP(自动化技术计算机技术)的946 054条读者借阅记录作为数据集,统计如表1所示。每条记录均包含以下属性:校园卡号、读者姓名、院系名称、图书题名、图书分类号、借阅时间。

表1 读者特征和借阅图书的关系规则
3.2 关联规则挖掘工具
数据挖掘和分析工具选择SPSS的Clementine 8.1,期待能找到读者的背景信息与借阅行为之间的关联规则,以及找到图书之间的关联规则。
3.3 实验结果分析
3.3.1 挖掘读者特征和借阅图书的关联。图书馆使用的汇文管理系统是一个关系型数据库,其中包含了多种维度的借阅记录数据,每条借阅记录除了含有借阅图书的相关信息,还包括了和读者相关的信息,例如借阅时间、读者年龄、读者性别、读者专业等。我们把以上属性作为谓词,开始挖掘关联规则,把挖掘到的含有两个以及两个以上谓词的关联规则称为多维关联规则[13]。我们设置最低规则支持度为0.1,最低规则置信度为0.4,获得了186条多维规则。实验结果如表2所示。
通过分析表2得到如下规则:①2014届计算机科学与技术专业大一学生,有10.3%的读者借阅了网页设计类图书,12.6%借阅了多媒体方向的图书,从大二开始,计算机系对学生的根据学生的兴趣方向进行重新分班,其中就包括了网页设计方向班级和图像处理方向,从挖掘结果可以发现这两类的支持度和置信度都有所提升; ②计算机专业大三开始学习计算机网络相关的课程,所以,有15.2%的学生借阅了计算机网络相关的书籍; ③计算机专业的男生借阅计算机网络应用和网络互联技术的图书占比为20.1%和20.2%,从男生更偏向于借阅此类图书很容易联想到男生在专业选择和个人兴趣方面的偏好,可以利用这个规则向他们提供个性化服务;④计算机专业的女生借阅网页设计和图像处理类别的图书分别占比16.8%和18.1%,女生更偏向于选择此类专业和兴趣爱好的图书,因此,可以利用这条规则向她们提供个性化服务。
通过上面的实验数据,我们再来看看规则数与最小支持度和最小置信度之间的关系。将支持度设定为0.05、0.1、0.15、0.2,将置信度设定为0.3、0.4、0.5、0.6,得出二者之间的关系如表2所示。
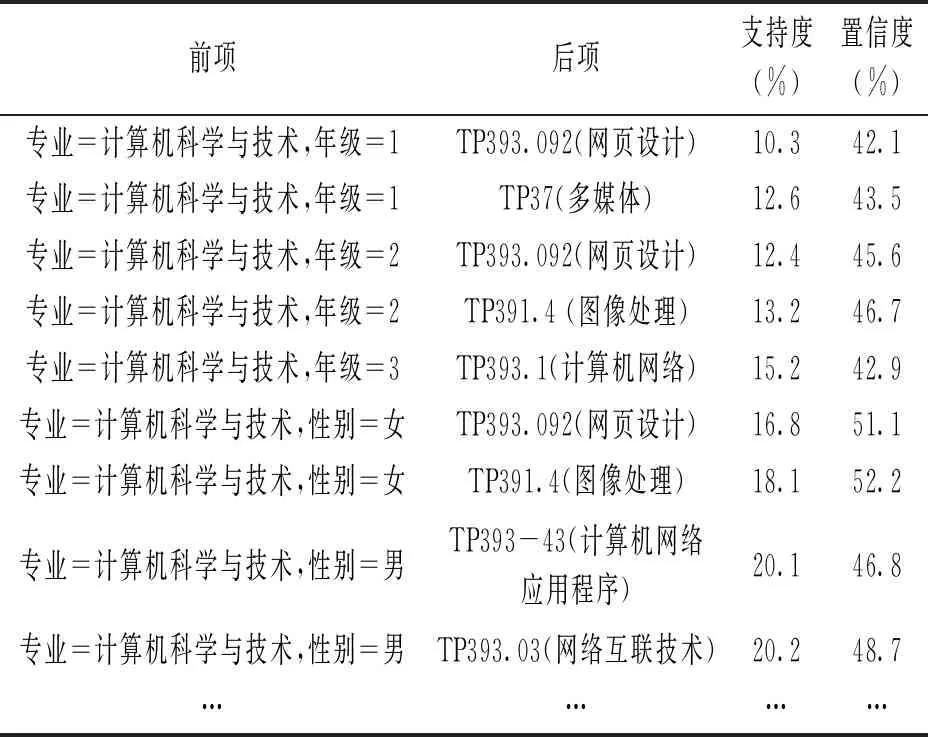
表2 读者特征和借阅图书的关系规则

表3 最小支持度、最小置信度、规则数的6组数据的关系
从表3的结果可以得出,挖掘到有效关联规则的数量多少取决于最小支持度和最小置信度设置的具体值大小[14]。图书馆的业务应用系统中包含了海量的读者数据可用于挖掘,但是选取合适的支持度是个难以估算的难题。因此,最小支持度和最小置信度阈值可以根据生成规则的实际数量和预置目标进行合理调整。在挖掘关联规则的过程中还发现,最小支持度对规则数的影响非常敏感。如果最小支持度大于0.2,挖掘到的关联规则数为零[15]。
3.3.2 挖掘图书关联。由于我们要分析各类图书之间的关联规则,所以我们选择“Apriori”模型建立规则,然后将图书类别字段的方向选项设置为“两者”(输入和输出字段),其他字段设置为“无”。调整算法参数设置最小支持度为0.15,最小置信度为0.45,获得了125条关联规则。实验结果如表4所示。

表4 图书借阅关联规则
通过以上的图书借阅关联规则表可以得出以下规则。
规则1:既借阅了数据库理论和系统又借阅了编程语言类图书的读者占比为15.1%。有47.6%的读者在借阅了数据库理论和系统类图书的前提下,又借阅了编程语言类的图书。
规则2:既借阅了图像处理软件又借阅了文本处理类图书的读者占比为15.2%。有54.8%的读者在借阅了图像处理软件类图书的前提下,又借阅了文本信息处理类的图书。
规则3:既借阅了机器辅助技术又借阅了图像处理方法类图书的读者占比为15.6%。有65.1%的读者在借阅了机器辅助技术类图书的前提下,又借阅了图像处理方法类的图书。
规则4:既借阅了计算机网络安全又借阅了网络操作系统类图书的读者占比为16.3%。有54.2%的读者在借阅了计算机网络安全类图书的前提下,又借阅了网络操作系统类的图书。
规则5:既借阅了软件工程又借阅了编程语言类图书的读者占比为18.4%。有46.9%的读者在借阅了软件工程类图书的前提下,又借阅了编程语言类的图书。
最终,将挖掘得到的关联规则与高校图书馆实际工作以及读者借阅情况的调研结果进行了比较,发现二者非常相似,表明以上挖掘到的结果是真实可用的。无论如何,由于相对于全校学生来说,计算机系的学生数量较小,大多数学生借阅的图书都是和本专业相关的,图书馆的藏书量是有限的,图书更新期较长,这也会产生一些影响,导致挖掘出的关联规则有一定的局限性。
4 结束语
个性化推荐服务是高校图书馆智慧服务建设中的关键内容。笔者探讨了在高校智慧图书馆的个性化信息服务中利用数据挖掘的相关技术来获得关联规则的案例,然后,将关联规则应用到图书的智能查询和个性化信息推送中去。①介绍了数据挖掘技术的相关概念,并以此为基础,研究了如何利用图书馆管理信息系统数据中的数据,利用Apriori算法来挖掘借阅记录等数据,发现读者对借阅文档的相关性。发现如下规律:不同类型的图书有不同类型的读者。借阅的规律性是存在的,不同学科之间具有某种关联等等。通过挖掘这些数据间的关系,图书馆员可以购买提供服务信息的图书,有利于图书馆合理配置馆藏资源,改善资源利用率,促进图书管理的良性循环。②以图书管理系统为例,介绍了高校智慧图书馆个性化服务系统的结构和业务流程。③介绍了Apriori算法并利用改进的Apriori算法对图书馆数据库中的借阅记录等数据进行挖掘。通过挖掘发现,读者借阅记录存在某种关联,不同类型读者的借阅记录具有某种规则,不同学科也有某种关联。通过分析借阅记录中读者和图书的关系,发现这些数据间的关系,为图书馆管理员提供参考,有利于馆藏资源的合理分配、提高资源利用率。同时,也为该方面的其他应用研究提供了一些思路。
