显著区域保留的图像风格迁移算法
2021-05-13屈时操郑晓妹马利庄
林 晓,屈时操,黄 伟,郑晓妹,马利庄
显著区域保留的图像风格迁移算法
林 晓1,2,3,屈时操1,3,黄 伟3,4,郑晓妹1,3,马利庄5
(1. 上海师范大学信息与机电工程学院,上海 200234; 2. 上海师范大学上海智能教育大数据工程技术研究中心,上海 200234; 3. 上海市中小学在线教育研究基地,上海 200234; 4. 上海理工大学光电信息与计算机工程学院,上海 200093; 5.上海交通大学电子信息与电气工程学院,上海 200240)
基于神经网络的风格迁移成为近年来学术界和工业界的热点研究问题之一。现有的方法可以将不同风格作用在给定的内容图像上生成风格化图像,并且在视觉效果和转换效率上有了较大提升,而侧重学习图像底层特征容易导致风格化图像丢失内容图像的语义信息。据此提出了使风格化图像与内容图像的显著区域保持一致的改进方案。通过加入显著性检测网络生成合成图像和内容图像的显著图,在训练过程中计算两者的损失,使合成图像保持与内容图像相一致的显著区域,这有助于提高风格化图像的质量。实验表明,该风格迁移模型生成的风格化图像不仅具有更好的视觉效果,且保留了内容图像的语义信息。特别是对于显著区域突出的内容图像,保证显著区域不被扭曲是生成视觉友好图像的重要前提。
风格迁移;图像变换;显著区域保留;卷积神经网络;显著性检测
图像风格迁移是计算机视觉的一个研究热点。其将一幅风格图像的风格应用于另一幅内容图像;是一项艺术创作和图像编辑技术。最近,受到卷积神经网络(convolutional neural networks, CNN)[1]在视觉感知任务中的启发,涌现出大量的基于CNN的风格迁移算法。在油画绘制[2-3]、卡通动漫制作[4]、图像季节转换[5-6]和文字风格变换[7-8]等方面有重要贡献。并且,一些流行的APP成功地应用了这项研究[9]。因此,风格迁移在学术界和工业界得到了普遍关注。
风格迁移是纹理合成的一项扩展工作。纹理合成利用图像局部特征的统计模型[10]来描述纹理,然后通过生成更多的类似纹理结构组成更大的纹理图。基于纹理合成的方法,风格迁移中风格图像就可以视为一种纹理,利用图像重建方法将纹理和内容图像结合即可实现图像的风格转换。
到目前为止,风格迁移的方法大致可分为2类[11]:
(1) 基于图像优化的风格迁移算法。该算法分别从内容图像和风格图像中获得内容和风格信息,然后进行图像重建将两者结合。GATYS等[12]首次提出基于神经网络的风格迁移算法,其主要依赖于经过预训练的VGG网络[13]。该方法的内容信息是使用内容图像经过VGG网络后的高层特征来表示,风格信息是使用风格图像经过VGG网络后的特征表达上计算Gram矩阵来表示,然后通过图像重建合成2种信息完成风格迁移。LI 和WAND[14]提出基于马尔可夫随机场(Markov random field, MRF)的非参数化纹理方法建模,其核心思想是以新的MRF损失取代Gram损失,该方法可以很好地保留图像中的局部结构等信息。然而这类图像重建过程依赖于多次迭代,每次风格迁移会花费很长的时间和大量的计算成本。
(2) 基于模型优化的风格迁移算法。该方法通过训练不同的前向网络,生成不同的风格迁移模型,解决第一类算法时间开销和计算开销的问题。JOHNSON等[15]首次提出一种实时迁移算法,通过为每种风格训练一个前向残差网络来提高转换速度并减少计算消耗。文献[16]提出条件实例归一化(conditional instance normalization,CIN),在训练好的风格化模型基础上在实例归一化(instance normalization,IN)层做一个仿射变换即可得到不同的风格效果,实现了单网络模型迁移多种风格。文献[17]受CIN层的启发,提出自适应实例归一化(adaptive instance normalization,AdaIN),AdaIN在特征空间中通过传递信道的均值和方差的统计量来进行风格迁移,首次实现了实时的任意风格迁移模型。LI等[18]提出增白和着色转换(whitening and coloring transforms,WCT),通过整合WCT来匹配内容和风格特征之间的统计分布和相关性来实现风格迁移。第二种方法通过预先训练的前向网络来解决计算量大、速度慢的问题。
显著性检测是计算机视觉领域中非常具有代表性的问题,其目的是定位出那些最吸引人视觉注意的像素或区域[19]。近年来,基于CNN的显著性检测方法大大提高了检测结果的准确性。HOU等[20]提出基于全卷积神经网络(fully convolutional neural networks,FCNN)[21]的显著性检测方法,其在深度特征提取和预测方面表现出优异性且有非常高的准确性。
与之前的工作不同,本文提出了一种显著信息保留的风格迁移算法。首先,在风格迁移网络中加入了显著性检测网络。以生成合成图像和内容图像的显著图,其使风格化图像和内容图像保持几乎一致的显著区域,避免显著区域扭曲。其次,设计了显著性损失函数,在训练过程中计算合成图像和内容图像的损失。并且在总损失中加入显著性损失,使得训练好的风格迁移模型能够生成保留内容显著区域的风格化图像。最后,通过与其他算法的比较,本文算法生成的风格化图像不仅运用了艺术效果且具有良好的语义信息,在视觉上更令人满意。
1 本文算法
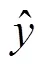
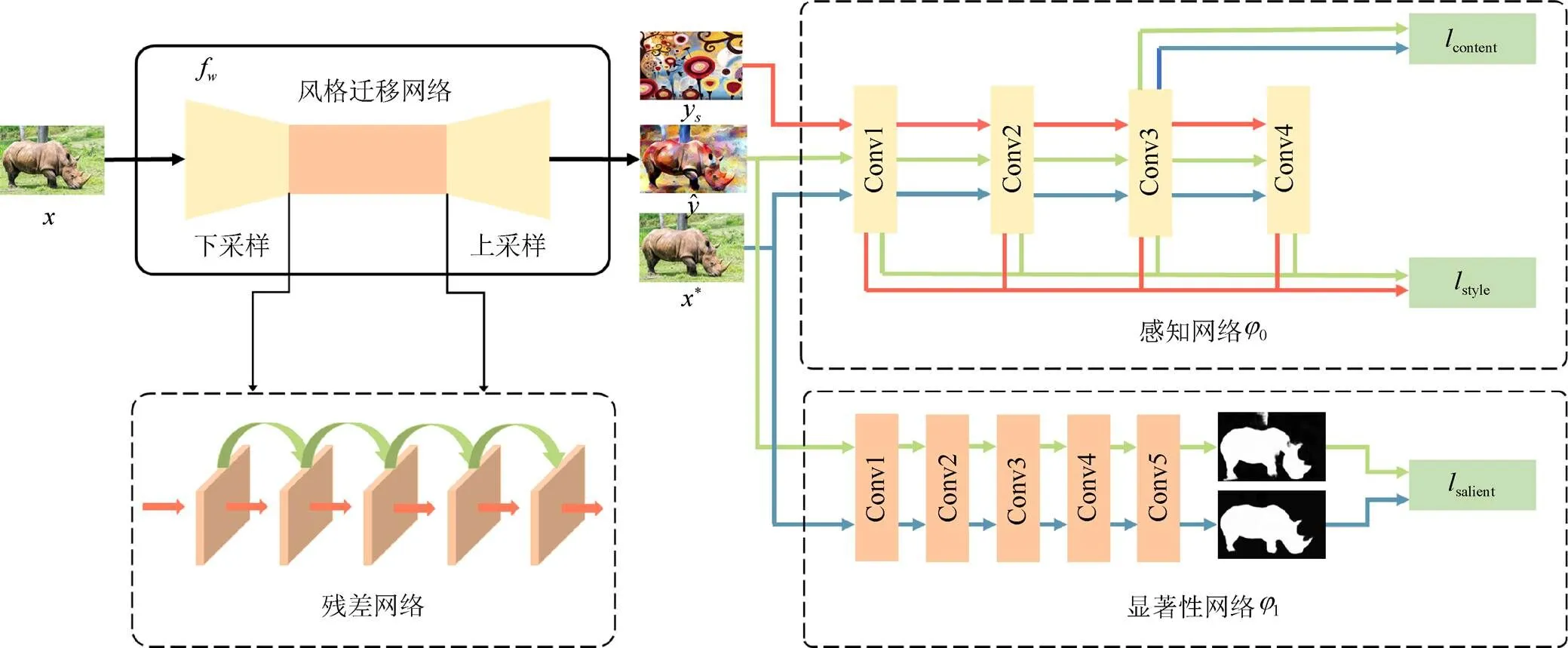
图1 本文算法流程图
1.1 图像风格迁移网络
本文算法包括图像风格迁移网络、感知网络和显著性网络3个部分。训练风格迁移网络,可通过感知网络和显著性网络中内容损失、风格损失和显著性损失的引导下生成的风格迁移网络模型来生成显著信息保留的风格化图像。风格迁移网络本质上是一个深度残差神经网络。如图1所示,其由3层卷积层,5个残差块[22],再加3个卷积层组成。训练输入和输出均为彩色3通道图像,尺寸为256×256。该网络未使用池化层,而是使用2个步幅为2的跨步卷积对输入图像进行下采样,使用2个步幅为1/2的微步卷积进行上采样。下采样和上采样在保证输入图像和输出图像有同样的尺寸大小,还有2个显著的优点:
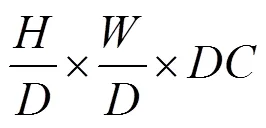
(2) 在相同层数时,下采样可以增加有效感受野。如,若不进行下采样,每增加一层3×3的卷积层可以增加2个感受野。经过因子的下采样,有效的感受野可以增加2。即有效感受野越大,可得到更好的风格迁移效果。
风格迁移网络的主体使用了GROSS和WILBER[22]提出的残差网络,使用残差网络更容易学到识别功能,使输出图像与输入图像可以共享结构,残差网络共使用了5个残差块,每个残差块包含2个3×3的卷积层。
除了输出层之外,在所有的非残差块后均使用批归一化处理(batch normalization)[23]和ReLU非线性激活函数。在网络的最后一层使用tanh函数保证输出图像像素在0~255之间。
1.2 感知网络
根据文献[15]的方法,感知网络使用由文献[13]提出的ImageNet[24]对VGG-16模型进行对象分类预训练。感知网络计算内容和风格的相似特征表示并不是精确计算图像的每个像素值,而通过计算目标图像和合成图像的距离来产生相应的损失。内容损失在VGG-16模型的ReLU3_2上计算,风格损失在ReLU1_2,ReLU2_2,ReLU3_3,ReLU4_3上计算。
1.2.1 内容损失
假设第层VGG-16网络有C个大小H×W的特征图。H和W分别表示层特征图的高和宽。层的响应可用矩阵表示为

内容损失通过计算内容图像在VGG-16网络第l层的特征图和合成图像之间的欧氏距离的平方获得,即
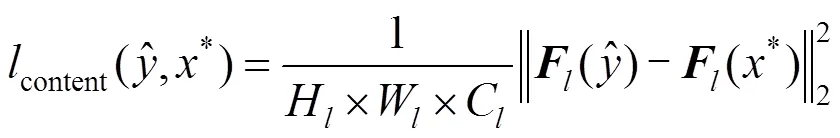
1.2.2 风格损失
风格损失是计算风格图像和合成图像在VGG-16网络中特征图的Gram矩阵的F范数的平方。风格损失计算如下
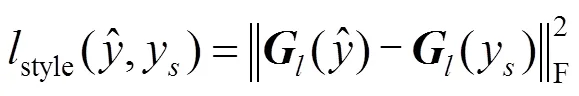
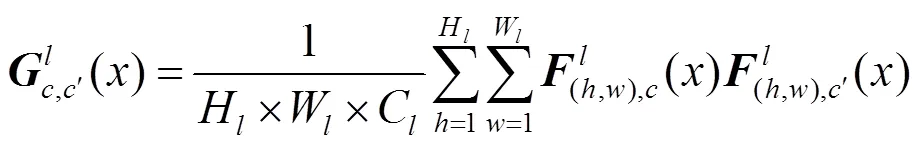
1.3 显著性网络
显著性损失网络1是用来弥补感知网络在计算内容和风格损失时未考虑内容图像中显著信息被扭曲的不足,保证风格迁移过程中保留内容图像语义信息,其生成的结果图效果更令人满意。
HOU等[20]提出一种新的深度监督的显著性检测方法,其通过在HED(holisitcally-nested edge detector)架构中引入跳跃层结构的捷径连接。通过这些短连接,激活每个输出层,既能突出整体又能准确定位边界。该框架充分利用从FCN提取的多尺度特征,为每一层提供更高级的表征,这是分割检测中极为重要的属性。并且在效率、有效性等方面具有优势,且能在非常复杂的区域内捕获显著区域。图2为该显著性检测算法的效果图。

图2 显著性检测((a)原图;(b)效果图)

1.4 总损失
本文模型的总损失total,其将感知损失和显著性损失合并为一个线性函数,即
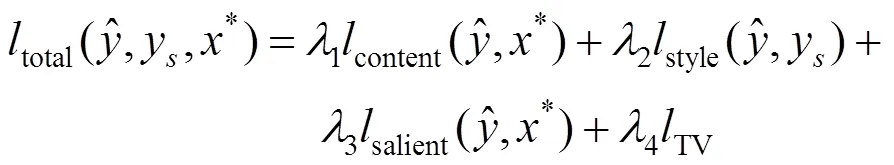
根据总损失,进行风格迁移网络迭代优化。最终生成风格迁移网络模型。该模型生成的风格化图像不仅自然,富有吸引力,而且保留了内容图像原有的显著区域。风格化图像保留了语义信息,避免了显著区域丢失和被扭曲。
2 实验结果
图1中的感知网络和显著性网络均加入训练。将内容图像和合成图像一起输入感知网络和显著性网络。在训练过程中,固定感知网络和显著性网络,更新风格迁移网络中的参数。这样,由感知网络和显著性网络相互作用优化,风格迁移网络参数保持不变,即在改变图像风格的同时保持了内容图像中的显著区域。生成的风格化图像具有良好的语义信息。图3为本文算法的效果图。

图3 本文算法效果图((a)风格化图像;(b)显著图对比)
2.1 实验结果比较
本文对比了文献[12]、文献[15]、文献[17]在相同内容图像和风格图像下的风格化图像效果。图4为风格化图像对比,图5为风格化图像显著图对比。为了保证对比实验的公平性,所有算法均使用作者上传的源码并选用与本实验相同的数据集及同样的配置进行训练。

图4 风格化图像对比((a)内容图像;(b) Gatys方法;(c) Johnson方法;(d) AdaIN方法;(e)本文方法;(f)风格图像)

图5 风格化图像显著图对比((a)内容显著图;(b) Gatys显著图;(c) Johnson显著图;(d) AdaIN显著图;(e)本文显著图)
通过图4可以看出,文献[12]方法是将内容特征和风格特征通过迭代完成图像重建,所以生成的风格化图像出现了显著的物体扭曲情况,使得风格化图像丢失了语义信息。文献[15]提出的感知损失函数在一定程度上保留了内容图像的感知信息,但是显著区域和背景风格化程度相似,缺少层次感。文献[17]提出的AdaIN基本上保留了内容图像的显著区域,但是出现了较为明显的“网格化”现象,影响视觉效果。本文算法可生成具有良好视觉效果的风格化图像。显著区域的信息作为前景,和背景的风格改变有着较突出的差异,并着重关注显著区域。结合图5可看出,本文算法生成的风格化图像和内容图像保持了几乎一致的显著区域,风格化图像具有较好的视觉效果和语义信息。Gatys,Johnson,AdaIN和本文方法的用时分别为35.15 s,2.37 s,5.41 s和2.29 s,其中本文用时最少。
2.2 消融实验
本文在风格迁移网络中加入了显著性检测网络,其负责捕捉显著特征,在风格转换的过程中,保留内容图像的显著区域。本文对显著性模块进行消融实验,以验证该模块的有效性。
首先,使用风格迁移网络和感知网络训练生成的模型来生成风格化图像,结果为图6(a)。然后使用风格迁移网络、感知网络和显著性网络训练生成的模型来生成风格化图像,结果为图6(b)。通过对比可以看出,添加了显著性检测网络之后生成的风格化图像可以更好地保留内容图像中的显著区域,使其更加突出。
2.3 实验评价
风格迁移是一项具有挑战性的计算机视觉任务,也是一项艺术类的任务,所以本文采用用户调查的方式来评估各类算法的表现。随机使用15张不同类的内容图像10张风格图像,随机搭配生成风格化图像,每个算法生成30张风格化图像。随机选择20名用户对风格化图像进行打分。
根据生成的风格化图像设计了2个调查问题。第一,要求参与者选择能够更好地表达风格图像中的色彩和纹理的风格化图像。第二,要求参与者选择能够更好地保留内容图像中的显著区域的风格化图像。本文按照随机顺序排列每个算法生成的风格化图像,让参与者分别给2个问题的同一内容和风格的不同算法生成的风格化图像进行打分。总分为10分,对20名用户的打分计算平均值,结果如图7所示。根据调查结果显示,本文算法生成的风格化图像既有令人满意的色彩和纹理,又保留了内容图像中的著性区域。

图7 用户调查结果
3 结束语
本文提出一种端到端的卷积神经网络来实现风格迁移。相比之前的基于卷积神经网络的风格迁移算法,本文提出的算法有3点改进:①在风格迁移网络中加入显著性检测网络,在训练阶段生成合成图像和内容图像的显著图,使风格化图像和内容图像保持几乎一致的显著区域,避免显著区域扭曲;②设计了显著性损失函数,并且在总损失中加入显著性损失,使得训练好的风格迁移模型能够生成保留内容显著区域的风格化图像;③本文算法生成的风格化图像与其他算法相比不仅运用了艺术效果并且具有良好的语义信息,而且在视觉上更令人满意。特别是在处理显著区域突出的图像,因为图像在显著区域的扭曲会严重影响风格化图像的视觉效果。
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems.California:NIPS, 2012: 1097-1105.
[2] GATYS L, ECKER A, BETHGE M. A neural algorithm of artistic style[J]. Journal of Vision, 2016, 16(12): 326.
[3] GATYS L A, ECKER A S, BETHGE M, et al. Controlling perceptual factors in neural style transfer[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 3730-3738.
[4] WU R Z, GU X D, TAO X, et al. Landmark assisted CycleGAN for cartoon face generation[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/usercenter/paper/show?paperid=1k5n00d0b7160va0xu7 u0aw0gb439758&site=xueshu_se.
[5] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 2242-2251.
[6] LUAN F J, PARIS S, SHECHTMAN E, et al. Deep photo style transfer[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6997-7005.
[7] WANG W J, LIU J Y, YANG S, et al. Typography with decor: intelligent text style transfer[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 5882-5890.
[8] GOTO K, NISHINO H. A method of neural style transfer for images with artistic characters[M]//Advances in Intelligent Systems and Computing. Cham: Springer International Publishing, 2018: 911-920.
[9] LIAO J, YAO Y, YUAN L, et al. Visual attribute transfer through deep image analogy[J]. ACM Transactions on Graphics, 2017, 36(4): 120.
[10] PORTILLA J, SIMONCELLI E P. A parametric texture model based on joint statistics of complex wavelet coefficients[J]. International Journal of Computer Vision, 2000, 40(1): 49-70.
[11] JING Y C, YANG Y Z, FENG Z L, et al. Neural style transfer: a review[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(11): 3365-3385.
[12] GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2414-2423.
[13] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/usercenter/paper/show?paperid=2801f41808e377a1897a3887b6758c59&site=xueshu_se.
[14] LI C, WAND M. Combining Markov random fields and convolutional neural networks for image synthesis[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2479-2486.
[15] JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 694-711.
[16] DUMOULIN V, SHLENS J, KUDLUR M. A learned representation for artistic style[EB/OL]. [2021-03-12]. https://openreview.net/forum?id=BJO-BuT1g¬eId=BJO-BuT1g.
[17] HUANG X, BELONGIE S. Arbitrary style transfer in real-time with adaptive instance normalization[C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 1510-1519.
[18] LI Y J, FANG C, YANG J M, et al. Universal style transfer via feature transforms[C]//In Advances in Neural Information Processing Systems. California: NIPS, 2017: 386-396.
[19] 李岳云, 许悦雷, 马时平, 等. 深度卷积神经网络的显著性检测[J]. 中国图象图形学报, 2016, 21(1): 53-59. LI Y Y, XU Y L, MA S P, et al. Saliency detection based on deep convolutional neural network[J]. Journal of Image and Graphics, 2016, 21(1): 53-59 (in Chinese).
[20] HOU Q B, CHENG M M, HU X W, et al. Deeply supervised salient object detection with short connections[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 2015: 815-828.
[21] SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[C]//IEEE Transactions on Pattern Analysis and Machine Intelligence. New York: IEEE Press, 640-651.
[22] GROSS S, WILBER M. Training and investigating residual nets[EB/OL]. [2021-03-12]. http://torch.ch/blog/2016/02/04/resnets.html.
[23] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL]. [2021-03-12]. https://xueshu.baidu.com/usercenter/paper/show?paperid=4634f864791a3f3a0817edabeacf4c49.
[24] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 248-255.
[25] MAHENDRAN A, VEDALDI A. Understanding deep image representations by inverting them[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 5188-5196.
[26] D’ANGELO E, ALAHI A, VANDERGHEYNST P. Beyond bits: Reconstructing images from Local Binary Descriptors[C]//Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012). New York: IEEE Press, 2012: 935-938.
[27] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]//Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 740-755.
[28] KINGMA D, BA J. Adam: a method for stochastic optimization[EB/OL]. [2021-03-12]. https://arxiv.org/abs/1412.6980v4.
Style transfer algorithm for salient region preservation
LIN Xiao1,2,3, QU Shi-cao1,3, HUANG Wei3,4, ZHENG Xiao-mei1,3, MA Li-zhuang5
(1. The College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 200234, China; 2.Shanghai Engineering Research Center of Intelligent Education and Bigdata, Shanghai Normal University, Shanghai 200234, China; 3.The Research Base of Online Education for Shanghai Middle and Primary Schools, Shanghai 200234, China; 4. School of Optical-Electrical and Computer engineering, University of Shanghai for Science and Technology, Shanghai 200093, China; 5. School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Style transfer based on neural networks has become one of the hot research issues in academia and industry in recent years. Existing methods can apply different styles to a given content image to generate a stylized image and greatly enhance visual effects and conversion efficiency. However, these methods focus on learning the underlying features of the image, easily leading to the loss of content image semantic information of stylized images. Based on this, an improved scheme was proposed to match the salient area of the stylized image with that of the content image. By adding a saliency detection network to generate a saliency map of the composite image and the content image, the loss of the saliency map was calculated during the training process, so that the composite image could almost maintain a saliency area consistent with that of the content image, which is conducive to improving the stylized image. The experiment shows that the stylized image generated by the style transfer model can not only produce better visual effects, but also retains the semantic information of the content image. Ensuring the undistorted ness of salient areas is a significant prerequisite for generating visually friendly images, especially for the content image with prominent salient areas.
style transfer; image transformation; salient region preservation; convolutional neural network; saliency detection
TP 391
10.11996/JG.j.2095-302X.2021020190
A
2095-302X(2021)02-0190-08
2020-08-09;
9 August,2020;
2020-08-27
27 August,2020
国家自然科学基金项目(61775139,62072126,61772164,61872242)
National Natural Science Foundation of China (61775139,62072126,61772164,61872242)
林 晓(1978-),女,河南南阳人,教授,博士。主要研究方向为图像处理。E-mail:lin6008@shnu.edu.cn
LIN Xiao (1978-), female, professor, Ph.D. Her main research interest covers image processing. E-mail:lin6008@shnu.edu.cn
郑晓妹(1973–),女,安徽来安人,讲师,博士。主要研究方向为图像视频处理。E-mail:xmzheng@shnu.edu.cn
ZHENG Xiao-mei (1973–), female, lecturer, Ph.D. Her main research interest covers image and video processing. E-mail:xmzheng@shnu.edu.cn
