大数据治理中数据整理技术的研究和应用
2021-05-12洪德华张翠翠徐敏孙佳丽
洪德华,张翠翠,徐敏,孙佳丽
(国网安徽省电力有限公司信息通信分公司,合肥230041)
0 引言
信息系统和数据,是大数据建设的基础[1-2]。国家电网公司高度重视信息化工作,始终将信息化作为公司核心战略[3-4]。经过过年的信息化建设,信息化取得显著成效,建成全球规模最大的电力通信网和一体化集团级信息系统,覆盖各级单位、各项业务和各类人员,在能源互联网公司建设中发挥了重要作用,多年来位居央企和国内各行业信息化水平前列[5-6]。当前,电力信息化已经进入“深水区”和“无人区”,各专业、各单位精益化管理、创新发展和数据价值挖掘需求呈“井喷”趋势,需要进一步加强业务数据治理,促进数据共享,发挥信息化价值[7-8]。
1 现状分析
目前电力企业已经全面开展数据综合治理工作,围绕数据梳理、数据管理、数据质量、数据应用四条主线开展数据综合治理工作,并取得了一定成效。随着信息化建设和应用不断深入,用户对数据的需求持续增长,用户范围从数据部门扩展到全业务全场景,数据治理不能再只是面向数据部门,需要成为面向全场景用户的工作环境,从给用户提供服务的角度,管理好数据的同时为用户提供自助获得大数据的能力,帮助企业完成数字化转型。
数据基础较为薄弱,电网积累了海量的数据,为电力大数据应用工作奠定了基础。但电力信息化主要从各专业角度出发开展建设,信息系统中的数据内容、频度仅考虑了各专业当前自身业务需求,未考虑后期分析应用和跨业务领域的需求,存在系统间数据标准不一致,以及数据缺失等数据质量问题,给大数据应用带来困难。
数据治理能力不足,以往数据治理人为干预比较多,未形成了一整套以用户为中心的大数据治理能力,最终为用户直接使用数据提供了帮助,从而使数据治理完成了从以管控为中心到以业务为中心的转变。
上述现象,是信息化发展到一定阶段必然面临的问题,信息化反映业务,信息系统固化流程,信息化与企业管理相互促进,螺旋上升。国内外领先企业的信息化成功实践也经历了类似过程,符合信息化发展的客观规律。
2 数据整理技术
数据整理技术是数据治理工作中一项繁重的工作,本文提出了基于知识图谱的数据资产库与企业级数据库访问管理要求,重点给出了数据资产库和知识库的自动补全算法。
2.1 数据资产梳理
数据资产梳理是构建数据资产库的基础,是保证数据安全使用和统一管理的重要手段,能够实现数据安全保护、敏感数据管理和合规性的需求。数据资产梳理涉及相关的关键流程、内容和方法,具体数据资产梳理流程如图1 所示。
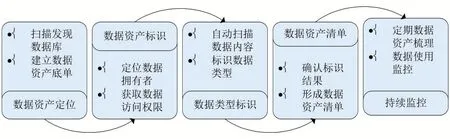
图1 数据资产梳理流程
数据资产定位是数据资产梳理的第一步,其目的是掌握目前企业已有数据库和它们各自的组织方式,充分扫描发现数据库后,由企业内数据管理技术人员建立数据资产的底单,以便为后续的数据资产标识和建立清单提供数据基础。
数据资产标识是在数据资产定位和建立数据资产底单后,像整理企业实体资产一样获取数据资产的拥有者和访问权限情况,使数据资产形成统一的数据资产标识,便于后续的数据管理和数据治理。因此数据资产标识的主要内容是定位数据资产的拥有者,同时获得数据的访问权限。
数据资产标识只是获得了单个数据资产的信息,但是还需要形成体系,因此下一个难点就是要对数据类型进行标识,扫描数据资产的具体内容,对数据资产进行分类,按照统一标准进行数据类型的标识。
在扫描获取数据资产标识和数据类型的标识后,首先确认前两个步骤形成的数据类型和数据资产标识,并对整个电网企业进行数据资产统一梳理,形成数据资产目录、数据资产清单。
由于数据资产也在不断的增长,所以数据资产梳理不是一劳永逸的,而要对已梳理的数据资产进行持续监控,并设定定期数据资产梳理的机制,对新增的数据资产进行新的梳理,对整个企业的数据资产形成持续的监控。
2.2 数据资产库模型构建
根据电网企业数据资产库的需求分析,采用双向建模的设计思路。一方面,从现有系统的数据出发,梳理国网数据平台所接入的数据实体,以及数据实体之间的关系,对其进行抽象、提炼,分析数据实体所属的数据主题域并进行归并,分析主题域之间关系,形成非结构化数据关联模型。另一方面,从业务需求出发,基于SG-CIM 统一信息模型和现有业务系统,分析提炼和梳理各业务线条的非结构化数据的业务需求,根据业务流程,提炼关键实体,分析实体所属主题域及实体间的关系,以及非结构化数据实体与结构化数据实体之间的关联关系,形成数据关联模型。
数据资产库属于非结构化关联模型,其中主要描述的是非结构化数据实体与结构化数据之间的关联关系。非结构化模型与结构化模型进行关联,结构化数据中心的表中添加非结构化数据实体的编码进行关联。申请访问数据资产库中的数据的过程分为四步,数据资产库的访问过程如图2 所示。

图2 数据资产库的访问过程
业务应用调用数据资产库管理平台对外提供的服务,向结构化数据中心发送请求,查询相关设备的基础信息与非结构化数据实体编码。结构化数据中心根据业务应用提交的请求,将设备等基础信息和非结构化数据实体编码返回给业务应用。业务应用根据结构化数据中心提供的非结构化数据实体编码,向非结构化数据管理平台发送请求,查询相关文档等信息。非结构化数据管理平台根据业务应用的请求,通过数据实体编码来获取目标文档,最终返回给业务应用。
2.3 数据补全算法
知识库补全是知识库自动构建的重要技术,也是实现数据资产库各实体间关系分类和链接预测的重要手段。知识库补全的作用是,在数据资产库中引入新的数据实体时,知识库补全能够通过已有的结构化三元组和实体集与关系集,推理与此数据实体存在关系的已有实体。
对于知识图谱G,假设G 中含有实体集E={e1,e2,…,eM}(M 为实体的数量)、关系集R={r1,r2,…,rN}(N为关系的数量)以及三元组集T={(ei,rk,ej)|ei、ej 属于E,rk 属于R}。由于知识图谱G 中实体和关系的数量通常是有限的,因此,可能存在一些实体和关系不在G中。记不在知识图谱G 中的实体集为E*={e1*,e2*,…,es*}(S 为实体的数量),关系集为R*={r1*,r2*,…,rT*}(T 为关系的数量)。根据三元组中具体的预测对象,知识图谱补全可以分成3 个子任务:头实体预测、尾实体预测以及关系预测。对于头(尾)实体预测,需给定三元组的尾(头)实体以及关系,然后预测可以组成正确三元组的实体。数据资产库补全算法流程图如图3所示。

图3 数据资产库补全算法流程图
知识库补全步骤:对于缺失的尾实体,将语义空间中头实体的向量表示与关系的向量表示相加,得到预测的尾实体向量表示,从实体列表中选择与预测尾实体最接近的实体作为预测结果;对于两个实体之间缺失的关系,以尾实体的嵌入向量减头实体的嵌入向量,然后将结果与备选关系的嵌入向量做差,选择与预测关系向量最相似的关系作为预测结果。
3 实验验证
本文选取公开通用的设备时序数据集,即凯斯西储大学(Case Western Reserve University)的轴承数据库来进行试验[9-10]。作为对比,统计正确实体在所有实体中的平均排名(Mean Rank)以及正确实体在所有实体中排名前十的数据所占百分比(Hit@10%)作为实体链接预测评价指标。知识库补全链接预测结果如表1所示。

表1 知识库补全链接预测结果
为进一步验证数据治理方法的可行性和有效性,选择电网资产设备开展数据治理应用,针对输变电数据设备台帐与图形存在不一致情况,选择合肥供电公司所辖范围内的输变电设备,通过校验数据与模型对应关系,核查系统垃圾数据,进行删除或退役处理,台帐与图形对应率由85%提升至98%,大幅提升输变电数据质量。生产管理系统与ERP 中设备帐卡物存在不一致情况,对主变压器、断路器、开关柜、组合电器及输电线路五类设备展开治理,通过检查错误字段、维护校验规则,在大数据治理原型系统中实现帐卡物一致率100%。数据治理前后对比结果如表2 所示。

表2 数据治理前后结果对比结果
综合来说,本文的数据资产库补全算法相对其他传统的算法在数据补全预测性方面指标方面表现更好,数据补全方法可以为数据治理工作提供可以遵循的方法,改变传统人工方式开展数据治理工作,进一步提升数据治理的效率。除此之外,随着数据的积累,数据补全算法模型的准确率能够进一步提高。
4 结语
为了解决当前电力大数据治理难题,本文提出了大数据治理中的数据整理算法,给出了数据资产梳理方法流程,阐述了数据资产库模型构建过程,设计了基于知识图谱的数据补全算法,通过实验验证了数据补全算法的可行性。
