利用层次聚类对移动曲面拟合滤波算法快速分类的研究
2021-05-11邢承滨邓兴升丁美青
唐 菓,邢承滨,朱 磊,邓兴升,丁美青
(长沙理工大学 交通运输工程学院,湖南 长沙 410004)
激光雷达是利用红外光技术对地物进行探测。相较于数字摄影测量的被动式扫描,激光雷达发射脉冲是一种新型的主动式遥感方式。激光雷达具有全天候观测,受外界干扰少等优点。并且激光雷达利用GPS和IMU可以直接获取物体的三维坐标,这不同于摄影测量繁琐的数据处理过程,但是激光雷达缺少纹理,不能像数字摄影测量那样直观辨别测区地物。激光雷达现在应用于各个行业,如电力、林业、古建筑保护、精密仪器组装等行业[1-2]。其高密度、高精度数据在各个行业发挥着越来越重要的作用。
如今激光雷达技术硬件已经趋于完善。但是数据处理仍然是众多学者研究的难点。其中滤波技术(地面点和非地面点的分离称为滤波)更是重点。多年来,众多学者提出了多种滤波算法:形态学滤波算法、三角网滤波算法、坡度算法、局部分割算法等。虽然各种算法对于部分地形取得较好滤波效果,但是仍然存在较多问题需要解决[3-4]。
张小红首先提出移动曲面滤波算法,该算法实现简单,能够适应多种地形点云过滤[5];苏伟提出一种多级改进型移动曲面滤波算法[6];朱笑笑提出多级移动曲面拟合的自适应阈值点云滤波方法,用于尝试点云阈值自适应的问题[7];邢承滨提出置信区间估计理论,旨在检验种子点选取中存在的粗差问题[8]。本文基于移动曲面算法高差阈值难以确定的问题,提出一种层次聚类算法,利用相邻数据点的水平距离与高差进行聚类,判断地面点与地物点的分类。
1 建立初始地面
改进型滤波算法首先将测区划分为大型规则格网,每一个格网中包含一定数量的数据点。通常格网大小由测区内最大建筑物的大小决定,邢承滨提出等值线方法确定格网内最大建筑物大小[9]。对于每一个网格建立索引,保证每一个点都有相应格网索引与其对应。i,j为格网索引号,位于同一格网内数据点索引号相同。
i=floor[max(y)-min(y)/l]+1,
(1)
j=floor[max(x)-min(x)/l]+1.
(2)
如图1所示,图1(a)表示测区内数据点的分布,利用xmin,ymin,xmax,ymax确定数据分布;图1(b)为将测区分割为大型格网,其中i为大格网的行号,j为大格网的列号,为了格网划分均匀并且易于建立格网索引,使得格网为正方形,步长dx=dy。
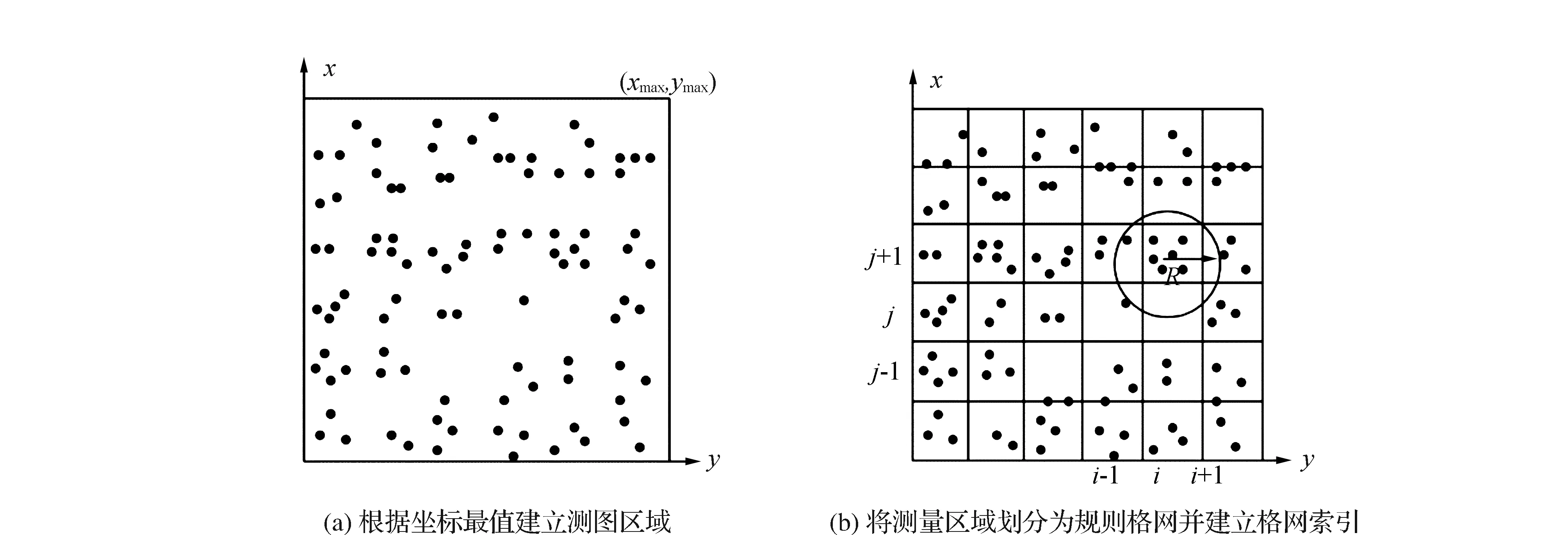
图1 数据点建立格网索引
对于划分的格网,每一个格网都是一个独立的测区,判断每个格网内的数据点的类型需要借助格网的初始曲面。拟合初始曲面通常采用选取地面种子点拟合的方式,由于每个格网大小在一定范围内,通常格网内区域地形较为简单,因此可以采用二次曲面拟合初始格网内的地面。式(3)为二次曲面拟合公式。
f(x,y)=a1x2+a2y2+a3xy+a4x+a5y+a6.
(3)
对于格网内初始地面的建立,需要借助格网中的初始种子点。为了更好选择格网中的初始种子点,通常建立一个4×4的小型格网,如图2所示将每个格网划分为16个均分的小型格网,选取小型格网中最低点作为种子点,并将其拟合曲面作为真实参考地面。
如图3所示对于某一区域内,利用种子点拟合的初始地面曲面与原始地形曲面相对比,显示地面点和非地面点的分布。
对于测区内所有数据点,都会存在两个数据值,相同的平面坐标(x,y),一个真实的高程值HT,一个拟合地面高程Hn。真实高程值HT表示数据点的真实高程,Hn表示数据点拟合出的地面高程,如果数据点为地面点,该点的真实高程值与拟合高程值近似,h趋近于0;如果该数据点为地物点(非地面点),真实高程值与拟合高程的高差h表示该地物点的高程。例如,此数据点为树木,h表示树木的高度。
h=HT-Hn.
(4)

图2 格网内种子点的选择

图3 拟合地形与原始地形曲面比较
2 层次聚类自适应阈值分类方法
2.1 三维数据的降维处理
利用相邻点的水平距离和高程距离进行分类。数据点三维空间坐标转换为二维平面坐标Δx,dh,将水平距离和高差作为新的变量对每一个格网内数据点进行滤波处理。
如图4所示,曲线表示种子点拟合曲面的剖面。白色圆形点表示真实地面,红色圆形点表示地物点(非地面点)。A,B为相邻两个数据点,A为地面点,B为建筑物点,hA为地面点高程与拟合高程之间高差,hB为B点地物点高程与拟合地面点之间的高差;ΔAB为AB两点之间水平距离,dhAB为相邻点AB的高差。
dhAB=hB-hA.
(5)

图4 相邻点高差分布图
2.2 层次聚类算法
将上述降维处理后的Δx与dh利用层次聚类的方式进行分类处理,以此作为滤波结果的重要判断标准。聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类技术经常被称为无监督学习,广泛应用于遥感影像的分类处理中。本文提出分层聚类阈值确定算法,通过计算样本间或者簇间的距离进行样本合并,最终合并为几个大类。本算法研究的重点是建筑地区,通常会将数据集合分为3类:高大地物区域、低矮地物区域、地面。
2.3 分层聚类的并项原理
对于层次聚类的数据都会增加新的属性,如图5所示,圆形、米状、星状表示3种不同的地物分类。高大地物区域和低矮地物区域统称为地物点区域(非地面点),滤波的完成需要合并高大地物和低矮地物。层次聚类的结果只会描述点的分类属性,例如一类、二类、三类,但是并不能确定每一类的性质。算法的难点在于3类地形的属性未知,层次聚类本身是一种非监督分类,缺乏先验条件。本文统计三类地形点云的个数,将个数最多的数据点定为地面点,另外两种地形合并为地物点。
2.4 算法过程
具体算法如图6所示。

图5 分层聚类并项

图6 层次聚类移动曲面算法流程
1)将测区数据划分为规则大格网,并建立索引;
2)将大格网划分16个小格网,选取小格网中最低点作为种子点拟合为二次曲面;
3)计算大格网内拟合曲面与真实地面之间的高差作为地物点的高差;
4)利用k-d树搜索格网内每个种子点平面内最邻近的数据点,计算水平相邻点水平距离;
5)利用最邻近点的索引,索引出相邻点的高差,计算相邻点之间的相邻高差;
6)将相邻点水平距离和对应高差距离建立层次聚类数据集,利用层次聚类算法将数据集分为三类;
7)将地物地面边界点与低矮地物点合并为地物点,集中于0点附近数据点归为地面点;
8)遍历所有大格网,统计格网内数据点的分类;
9)合并所有地面点,合并所有地物点完成测区滤波。
3 实验分析
本文通过3种方式验证本文算法的科学性:将算法应用于不同地区检验算法的可行性,每一个测区包含整体滤波效果和格网内滤波效果;将本文层次聚类算法对城市地区和村镇地区进行对比分析,验证本文算法在何种地形更优越;与其他多种滤波算法进行对比,分析本文算法的优缺点和适用范围。
3.1 实验数据
本文数据采用2003年摄影测量与遥感协会(ISPRS)公布的雷达点云数据。该数据为Optech ALTM机载激光扫描仪获取的Vaihingen/Enz和Stuttgart市的点云数据。其中4个城市数据:Site1~Site4,点间距1.0~1.5 m;村庄数据:Site5~Site8,点间距2.0~3.5 m。在8个数据集中选取15组样本,表1对每个样本的属性进行详细解释[10]。

表1 测区地形特征
误差的判别标准依据2003年ISPRS小组的评估报告。表2将滤波误差分为3种:I类误差(Type I Error):将地面点误分为非地面点;II类误差(Type II Error):将非地面点误分为地面点;总误差(Total Error):所有误分点数/数据点总数[11]。

表2 滤波误差定义
3.2 层次聚类算法滤波精度对比分析
3.2.1 层次聚类算法实验结果分析
本文算法统计15个样本数据进行计算,见表3。不仅计算整个样本的三类误差,同时随机抽取部分格网样本中数据进行单独格网的计算。
测区内数据进行统计计算,得到整体样本,I类误差获得较好的拟合效果。对于地面的分离具有较高精度,均保持在5%以内,但是II类误差,城市测区Samp11~Samp42均能取得较好的分类。以样本Samp41为例,样本城区聚类低值点。样本包含14个大型格网,统计计算每一个格网的精度。
由表4可知,对于城市地区总体效果较好,格网15存在NAN现象为本测区15格网内不存在地面点,而分层聚类算法判断出2个地面点,按照标准无法计算出I类误差。
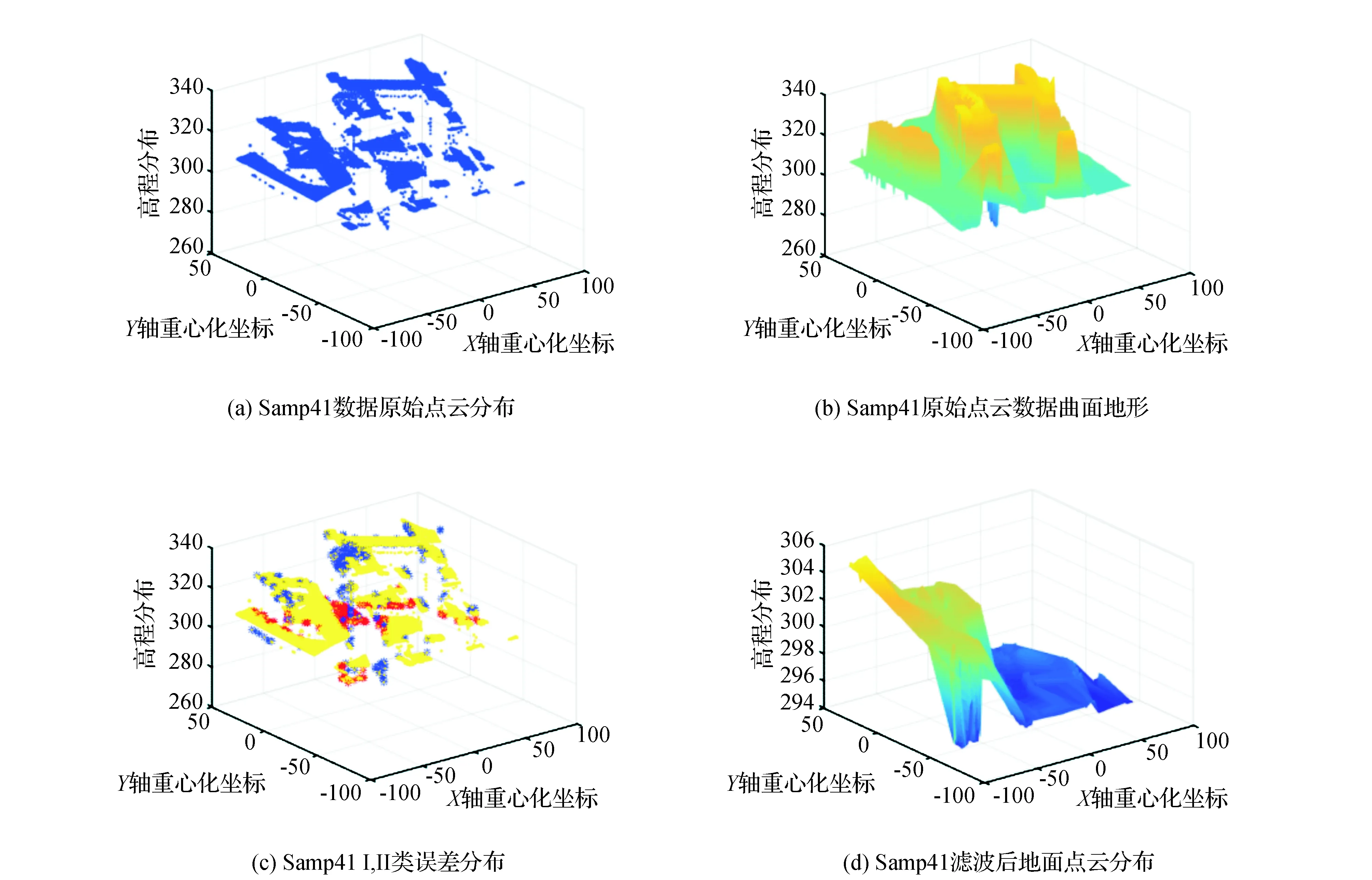
图7 Samp41数据分析描述

表3 15组样本三类误差统计

表4 Samp41全部格网数据统计
图7为样本Samp41的数据描述。由图7(a)和图7(b)可以看出,地形为不连续地形。部分地形间断明显。由图7(c)显示,红蓝颜色为I,II类误差分布,误差主要分布在间断地形。地形高程陡变造成分层聚类算法的部分失真,存在较为明显的错误分类。由图7(d)地面点分布与图7(b)对比,间断地形内利用聚类算法得到很好的消除。
从数据结论判断层次聚类移动曲面拟合算法可较精准的对地面点保留和对地物点剔除。
3.2.2 层次聚类算法与其它滤波算法对比分析
自适应移动曲面算法为朱笑笑提出的新型移动曲面滤波算法[7],PTD(三角网致密化算法)滤波算法为Axelssion提出的三角网渐进加密算法[3]。两种算法都在同一组样本下取得较好的滤波效果,其中PTD滤波算法应用在专业软件。表5通过3种算法对比,说明本文算法对于城区样本滤波效果较好,I类误差的计算结果要略优于自适应多级移动曲面。且对样本Samp11有较大程度提高,由21.52%提高到2.36%,说明利用水平距离和相邻点高差聚类对于地面点的判断能取得较好效果。
但是本文算法也存在一些问题。对于村镇测区,Samp51—Samp71中,I类误差精度保持较高,误差控制在6%以内,但是II类误差较大,普遍在15%左右。对上述数据进行统计计算,对于不同地形结构进行统计分析。
以样本Samp53间断地形样本为例。将最初格网阈值选择为40 m,将Samp53划分为132个格网。每一个格网选择最低点拟合为初始地面。为了体现本文算法对于样本的普遍适用性,随机选取10个格网。统计格网中数据点的I,II类误差,如表6所示。

表5 3类算法15组样本精度对比

表6 Samp53随机格网I,II类误差统计
以第3个格网为例,格网中包含297个数据点,利用初始种子点拟合为初始地面模型,图8(a)为初始地面种子点的分布,图8(b)为初始地面模型。利用初始地面模型,计算每一个数据点的拟合高程。利用k-d树搜索数据点水平距离最邻近点,计算相邻点高差。将水平距离和相邻高差作为层次聚类的依据,如图8(c)表示格网聚类成果。通常地形分类为3类:地面点、低矮地物、大型地物。地面点的特点:水平距离和高差距离集中在0附近。大型地物出现在高差较大地区,小型地物会出现在高差较小地区。具体分布需利用分层聚类算法计算,图8(d)描述测区误差点的分布。
同时图9(a)选择Samp53样本中第一个格网,格网中有数据点248个。又聚类算法呈现出相邻点高差存在巨大差异但是不呈现集聚性,由此判断为山体断裂线。由初始数据点呈现测区为山体地形。同时由二类误差分布显示。绝大多数误差集中在断裂线处。断裂线处误差主要因为断裂线处地面点误分为地物点,造成I类误差偏高。断裂线处个别山体陡峭,真实高程远远大于拟合高程,造成层次聚类中存在错误分类。

图8 Samp53第3格网数据描述

图9 Samp53第1格网数据描述
图9(b)为第1格网中数据点聚类为3类,星号为I类误差,点号为II类误差,米状为地面点,米点具有集聚性,并且集中在0轴附近。图9(c)所示I,II类都有明显的特征,高差较大,但是I类误差水平距离较小,II类误差水平距离较大,高差距离较小。但是从图9(d)和图9(e),过滤后的地面区域较为平滑,剔除绝大多数地物点。整体分析,层次聚类对于山体地区还有较大需要改进的地方,对于城镇地区滤波效果良好。
4 结束语
本文提出的聚类算法利用拟合地面和真实地形做高差,利用水平距离和相邻点高差层次聚类,在城区取得较好效果,但是在山体地区,由于山体断裂线和陡变的地形,使得拟合地面与真实地形高差较大,造成II类误差较大,总体而言滤波精度较好。由于实验数据有限,本文算法并没有进行对于大规模地形的检校,对于大规模地形的适应性处理还有待研究。
