结合语义分割和特征融合的行人检测方法
2021-05-10翟明浩黄子龙
翟明浩,张 威,黄子龙,刘 晨,李 巍,曹 毅
(1. 江南大学 机械工程学院, 江苏 无锡 214122;2. 苏州工业职业技术学院, 江苏 苏州 215104)
行人检测旨在识别并定位图像中的行人目标,是计算机视觉领域的一个重要研究方向,被广泛应用于自动驾驶汽车、交通安防、视频监控、智能机器人等领域[1],具有重要的研究意义。近年来,行人检测技术受到国内外学者的广泛关注。目前,行人检测方法主要有基于人工特征的检测方法和基于深度学习的检测方法两大类[2]。
基于人工特征的行人检测方法采用人工特征表征图像,使用高质量分类器实现行人检测。Dalal等[3]提出方向梯度直方图(histogram of oriented gradient,HOG)特征作为行人的特征表示,并使用支持向量机(support vector machine,SVM)分类器进行分类,成为行人检测领域的经典方法。Felzenszwalb等[4]使用可形变部件模型(deformable parts model,DPM),结合Latent SVM,缓解遮挡问题,在保证实时性检测的同时可提高检测精度。Dollar等[5]提出聚合通道特征(aggregate channel feature,ACF)方法,提取多种通道特征构成特征金字塔,并通过AdaBoost分类器检测行人,极大地加快了行人检测速度。但是,上述方法依赖手工设计的特征,其泛化能力和稳健性较差,存在一定的局限性,对复杂场景下行人的表征能力不足。
近几年,随着深度学习技术的不断发展,卷积神经网络(convolutional neural network,CNN)因其强大的特征表征能力和泛化能力,在图像分类、目标检测、音频分类[6]等领域取得突破性进展。许多学者开始将CNN引入到行人检测领域,基于深度学习的行人检测方法逐渐成为主流。Ouyang等[7]提出JointDeep,将特征提取、变形处理、遮挡处理和分类等4部分结合在一起,形成一个联合的深度学习框架,提高了行人检测的精度。Paisitkriangkrai等[8]提出SpatialPooling,在深度CNN中使用空间池化进行行人检测,增强了行人检测模型的稳健性。Angelova等[9]提出一种基于级联网络的行人检测方法DeepCascade,该方法将深度CNN与级联分类器相结合,进一步提升了行人检测的准确率。Zhang等[10]利用区域建议网络(region proposal network,RPN)生成候选区域,将提取出的特征输入到增强森林(boosted forest,BF)分类器进行分类,大幅度提高行人检测的精度。Cai等[11]提出一种用于端到端行人检测的多尺度卷积神经网络(multi-scale convolutional neural network,MSCNN),提高了小目标行人检测准确率。Liu等[12]提出多阶段检测网络ALFNet,利用渐近定位模块获取高质量行人样本,在精度和速度方面均取得很好的效果。
虽然近年来行人检测方法已经取得巨大的进展,但由于在复杂场景下存在遮挡、光照变化、人体姿态变化、尺度等干扰因素,这些因素会导致行人目标发生畸变,为行人检测增加许多新挑战。为改善复杂场景下遮挡行人和小尺寸行人的检测效果,提出一种结合语义分割和特征融合的行人检测方法:通过深度CNN提取特征,利用语义分割所得到的语义信息来辅助行人检测,抑制遮挡因素对行人的干扰;通过特征融合实现不同卷积层的跳跃连接,融合不同层次特征,增强特征质量,提高检测精度,降低行人检测的漏检率;最后在行人检测标准数据集上进行试验,验证行人检测方法的有效性。
1 行人检测框架
提出的结合语义分割和特征融合的行人检测方法如图1所示,以区域全卷积神经网络(region-based fully convolutional networks,R-FCN)[13]为基础框架,根据行人检测任务进行改进,由5部分组成:特征提取网络、语义分割网络、特征融合模块、区域建议网络、检测网络。

图1 行人检测总体框架Fig.1 The general framework of pedestrian detection
1.1 特征提取网络
特征提取网络能够从原始图像中提取出多层次的特征映射图,其特征表征能力在一定程度上决定行人检测方法的性能。选择残差网络Resnet-50[14]作为特征提取网络。残差网络使用残差连接,在加深网络层次的同时,避免梯度消失和网络退化问题的出现,提高网络的收敛速度。在原网络结构的基础上,进行如下改进:(1)去除平均池化层、全连接层和分类层,只使用全卷积神经网络部分;(2)在Conv5_x模块后增加一个1×1×1 024 卷积层,以实现特征降维,降低参数规模。具体网络结构参数和特征图尺寸如表1所示。

表1 特征提取网络结构参数表Table 1 The structure parameters of feature extraction network
1.2 语义分割网络
遮挡问题是行人检测领域的一大难题。在复杂场景下,受遮挡行人易受到周围物体干扰,从而导致其部分信息损失。因此,在检测过程中,被遮挡的行人经常被误判为背景区域而剔除,增大了行人检测的漏检率。为了抑制遮挡因素产生的干扰,利用语义分割网络将原始图像按照类别分割成若干个区域,获得具有像素级别分类结果的语义分割图,并将其融入到行人检测网络中,增强网络模型对于遮挡目标的辨识能力。语义分割网络的具体结构如图2所示。
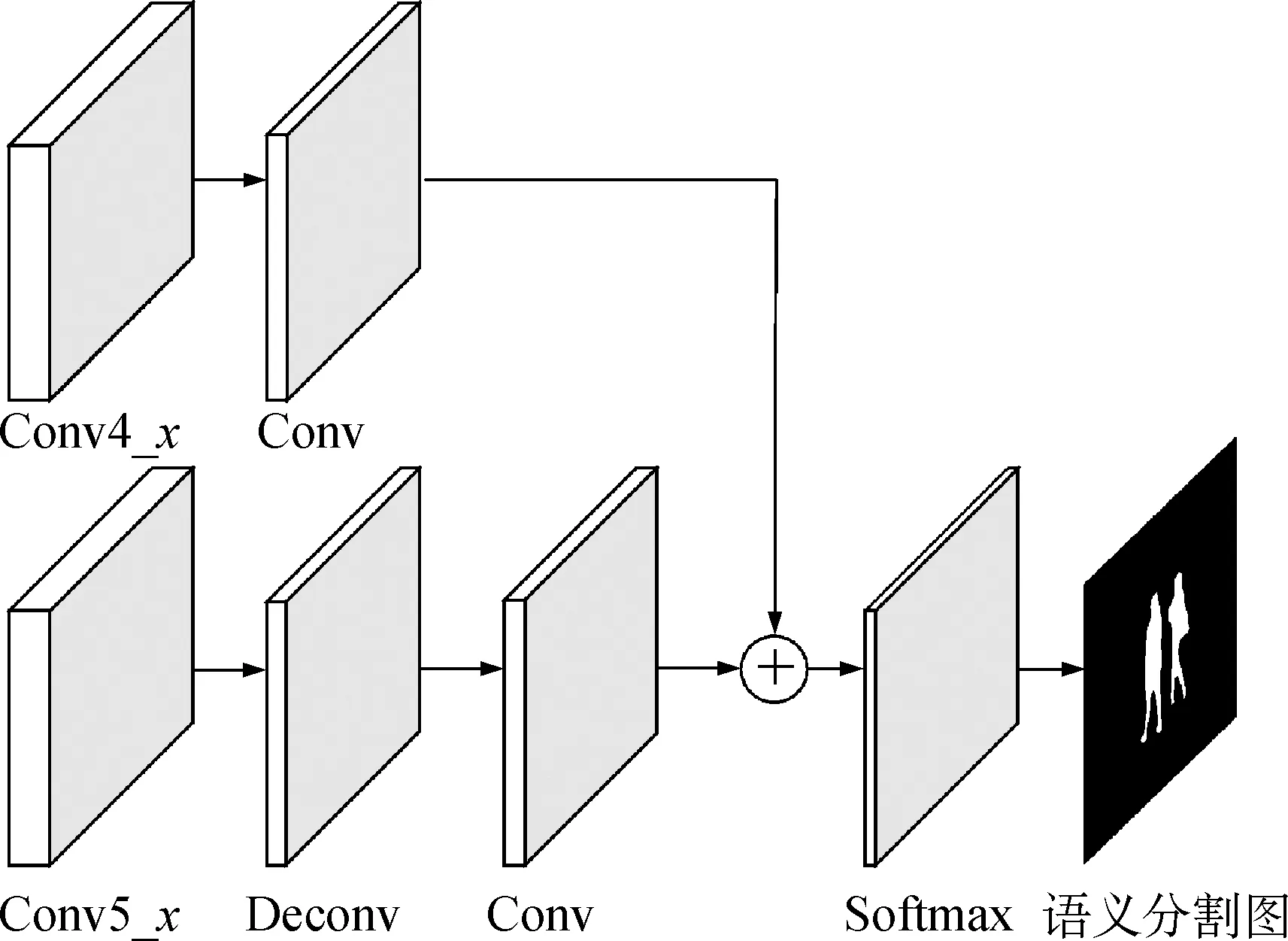
图2 语义分割网络结构图Fig.2 The structure of semantic segmentation network
由图2可知,语义分割网络使用Conv4_x和Conv5_x两个特征图作为输入。在Conv5_x之后连接1个反卷积层和1个卷积层:反卷积层的卷积核个数为512,大小为4×4,步长为2;卷积层的卷积核个数为512,大小为3×3,步长为1。在Conv4_x后连接1个卷积层,卷积核个数为512,大小为1×1。然后通过求和运算进行特征图融合,得到分辨率为原图1/16的特征图。最后通过Softmax分类层得到语义分割结果。
目前,语义分割网络的学习方法主要有两种:监督学习和弱监督学习[15]。监督学习利用图像和其对应的像素级别标注信息对神经网络进行训练,虽然需要耗费大量的人工成本,但语义分割结果精度高。弱监督学习使用粗糙的标签信息,如边框、线条、点以及图像标签等,利用这些不完全可靠的标签信息对网络进行训练,可以使网络获得简单的语义分割能力。为了使网络实现精确的语义分割,本文采用监督学习。由于常见的行人检测数据集只具有边框标注信息,不具有像素级别标注信息,因此借助Cityscapes语义分割数据集[16]训练语义分割网络。Cityscapes数据集包含大量具有像素级别标注信息的图像,在网络训练前,对数据集进行处理,将行人在标签中的对应位置标注设为1,其他类别在标签中的对应位置标注设为0,突出行人目标。
1.3 特征融合模块
原R-FCN方法在行人检测过程中存在小尺寸行人检测效果不佳的问题。其主要原因在于:(1)小尺寸行人的分辨率较低,携带的位置信息较少,特征表达能力弱;(2)卷积神经网络中浅层特征感受野小,是一种局部信息,深层特征感受野大,是一种全局信息,而原R-FCN方法只使用特征提取网络的最后一层特征图,虽然其语义信息丰富,但是分辨率低且感受野大,导致小尺度行人的检测能力进一步降低。在目标检测领域,基于特征融合的单次多框检测器(feature fusion single shot multibox detector,FSSD)[17]、HyperNet[18]、特征金字塔网络(feature pyramid network,FPN)[19]等方法充分证明,多尺度特征表示及其特征融合能够有效提高小目标的检测精度。行人检测属于目标检测的一种特殊情况,因此将特征融合方法移植到行人检测领域,通过特征融合模块将细节信息丰富的浅层特征与高度抽象的深层特征结合起来,同时利用语义分割图的语义特征,充分利用不同层次、不同形式的特征,可以检测不同尺度的目标,提高小尺寸行人的检测精度。特征融合模块结构如图3所示。
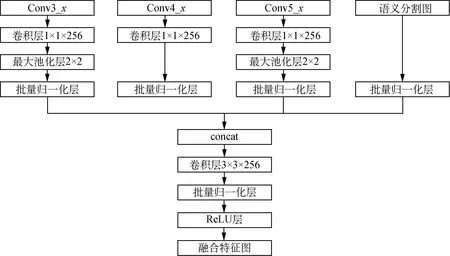
图3 特征融合模块结构图Fig.3 The structure of feature fusion module
设输入特征图为Xi,选择Conv3_x、Conv4_x、Conv5_x共3个特征图;经过语义分割网络得到的语义分割图为S;特征融合模块输出的融合特征图为Y。特征融合过程如式(1)和(2)所示。
Xf=φf{γ(Xi, …,S)}
(1)
Y=φc(Xf)
(2)
式中:γ为特征融合之前的组合变换函数;φf为特征融合函数;Xf为特征融合后生成的特征图;φc为特征融合后的组合变换函数,包括3×3卷积、批量归一化和非线性激活函数ReLU。
为保证不同尺度的特征图与语义分割图正常融合,组合变换函数γ根据特征图的尺度采取不同的设置。首先,在每个特征图后使用1×1卷积变换实现特征降维,降低参数规模,增强网络非线性程度;其次,针对不同分辨率的特征图,采用不同的采样策略,Conv3_x通过2×2最大池化实现下采样,Conv5_x通过2×2反卷积实现上采样;最后,使用批量归一化(batch normalization,BN)将特征图归一化。语义分割图后只需进行批量归一化操作以防止过拟合。常见的特征融合函数有拼接(concat)、元素求和(element-wise summation)和元素点积(element-wise product)[20]。拼接将特征图在维度通道上进行合并级联,元素求和将特征图对应位置元素相加,元素点积将特征图对应位置元素相乘。由于元素求和、元素点积均要求特征图尺度相同、维度相同,拼接仅需保证特征图尺度相同。融合前的特征图尺度相同、维度不同,因此特征融合函数选择拼接函数。
1.4 区域建议网络
区域建议网络的主要作用是提取出高质量的候选区域,其结构如图4所示。输入为特征融合模块生成的融合特征图,输出为一组感兴趣区域(regions of interest,RoI)。区域建议网络采用滑动窗口策略,在融合特征图上使用3×3窗口进行滑动选择,每个滑动窗口区域通过卷积层映射为512维的特征向量,然后将特征向量输入到分类层和边框回归层。其中在每个滑动窗口位置,同时预测k个不同大小的感兴趣区域,称为锚(anchor)[21]。本文将k值设为12,区域尺度设为{64, 128, 256, 512},区域长宽比设为{1, 1/2, 2}。分类层对感兴趣区域进行打分,输出行人与背景的概率,输出参数数量为2k。边框回归层对感兴趣区域的边框位置参数进行回归,边框位置参数形式为(x,y,w,h),包括边框的左上角坐标及宽和高,输出参数数量为4k。

图4 RPN示意图Fig.4 The diagrammatic drawing of RPN
1.5 检测网络
首先,检测网络由两个并行连接的子网络组成,即分类子网络和边框回归子网络,其具体结构如图1中检测网络部分所示。分类子网络首先利用卷积操作在融合特征图Y后生成位置敏感分数图z,如式(3)所示。
z=Fk2×(C+1)(Y)
(3)
式中:F(·)为1×1卷积变换;C为物体类别数,加上背景类,共有C+1类;k2为子区域数量,代表位置敏感RoI池化层将每个感兴趣区域平均划分成k2个子区域。每个类别都有k2个位置敏感分数图描述对应空间位置的信息。
其次,通过位置敏感RoI池化层对每个RPN网络生成的RoI进行平均池化操作,输出维数为C+1的特征图。位置敏感RoI池化只在编码相应位置的位置敏感图时做出池化反应。对于RoI中任意1个子区域,位置敏感RoI池化操作定义如式(4)所示[13]。
(4)
式中:bin(i,j)为子区域, 0≤i,j≤k-1;rc(i,j|Θ)为子区域对第c类的池化响应;Θ为网络学习得到的参数;n为子区域中的像素点数;zi, j, c为子区域所对应的位置敏感分数图;(x,y)为子区域内任意一点的坐标;(x0,y0)为RoI左上角的坐标。
然后,将池化后的特征图在维度通道上求均值得到C+1维特征向量,如式(5)所示。
(5)
最后,利用Softmax回归计算得到RoI属于每个类别的概率,如式(6)所示。
(6)
式中:sc为RoI属于第c类的概率;rc为RoI对应第c类的特征向量;rc′为RoI对应第c′类的特征向量,0≤c′≤C。
边框回归子网络旨在保证RoI更加精准,网络结构与分类子网络相同,在融合特征图后构建另外1个维度为4k2的位置敏感分数图,然后使用位置敏感RoI池化层为每个RoI生成1个四维特征向量,对RoI的边框位置参数进行回归修正,位置参数形式与区域建议网络保持一致。
检测网络生成预测框后,存在一些高度重叠的预测框。为了减少冗余,采用非极大值抑制(non-maximum suppression, NMS),阈值设置为0.7, 去除重叠预测框,利用剩余的预测框实现行人检测。
1.6 目标损失函数
损失函数代表预测区域与真实标记区域之间的误差,每个RoI的目标损失函数由分类损失和位置损失两部分组成,其表达式如式(7)~(10)所示。
L(s,tx, y, w, h)=Lcls(sc*)+α[c*>0]Lloc(t,t*)
(7)
Lcls(sc*)=-log(sc*)
(8)
(9)
(10)
式中:L为总损失;Lcls(sc*)为分类损失,采用交叉熵损失函数;c*为感兴趣区域的真实分类标签,行人为1,背景为0;sc*为Softmax输出的分类概率集合;t为预测框的位置参数;t*为真实框的位置参数;Lloc(t,t*)为预测框的位置回归损失,采用smooth损失函数;α为权衡系数,用于调整分类损失和位置损失之间的比例,α取1;[c*>0]为指标系数,如果参数为真,则等于1,否则为0,感兴趣区域是行人时才激活位置损失。
2 试 验
2.1 试验环境
CPU:Intel i7-7700k;内存:32G DDR4;显卡:Nvidia Geforce GTX1080Ti;操作系统:64位Ubuntu16.04 LTS;在深度学习框架Caffe[22]上进行网络训练和测试。
2.2 试验数据集
为验证行人检测方法的有效性和可靠性,将该方法在Caltech数据集[23]和ETH数据集[24]上进行试验。Caltech数据集和ETH数据集是用于行人检测性能评估的标准数据集。Caltech行人检测数据集包含30万行人标注框,图像原始分辨率为640像素×480像素。数据集有Set 00~Set 10共11个部分。选择Set 00~Set 05作为训练集,并以5 Hz采样,得到42 782张训练图像;选择Set 06~Set 10为测试集,并以1 Hz采样,得到4 024张测试图像。ETH数据集包括3个视频序列,分别在正常光照、阴天、强光等3种光照条件下拍摄,采样频率设为1 Hz, 得到1 799张图片,每张图片分辨率为640像素×480像素。
2.3 模型训练
训练数据在训练前经过左右翻转、旋转变换和随机采样实现数据增广,随机采样的最小重叠率设为0.5。训练数据与测试数据分辨率均设置为640像素×480像素。采用预训练模型来初始化网络参数,初始学习率为0.001,迭代160 000次后学习率降为0.000 1。网络每迭代1 000次,在验证集上测试网络模型的损失,当模型的损失达到收敛时,停止迭代。通过随机梯度下降法(stochastic gradient descent,SGD)优化网络模型,权重衰减率(weight decay)设为0.005,动量设为0.9。模型训练采用在线难例挖掘方法(online hard example mining, OHEM)[25],每次迭代随机选择1张图,选择128个感兴趣区域为一个批次进行梯度回传。
2.4 评价指标
评价指标使用漏检率-每幅图像误检数曲线,当评估行人检测方法性能时,通过设置不同的参数,得到不同组的漏检率和每幅图像误检数值,从而画出漏检率-每幅图像误检数曲线。漏检率(miss rate,MR)和每幅图像误检数(false positives per image,FPPI)计算方法分别如式(11)和(12)所示。
(11)
(12)
式中:M为漏检率;T为被正确识别的正样本数量;F为负样本被错误识别为正样本的数量;P为每幅图像误检数;N为图片总数目。
2.5 Caltech数据集试验结果
根据图片中行人目标的尺寸与被遮挡情况,将Caltech数据集的测试集划分成不同子集。其中:All子集行人高度大于20像素,任意遮挡;Reasonable子集行人高度大于50像素,无遮挡或部分遮挡;Far子集行人高度小于30像素,为小尺度行人;Medium子集行人高度大于30像素且小于80像素;Near子集行人高度大于80像素。模型训练结束后使用不同测试子集测试模型性能,并根据评价指标绘制漏检率-每幅图像误检数曲线,取每幅图像误检数为0.1 条件下的漏检率进行对比。本文方法与其他方法在All、Reasonable测试子集下的测试结果对比如图5所示。
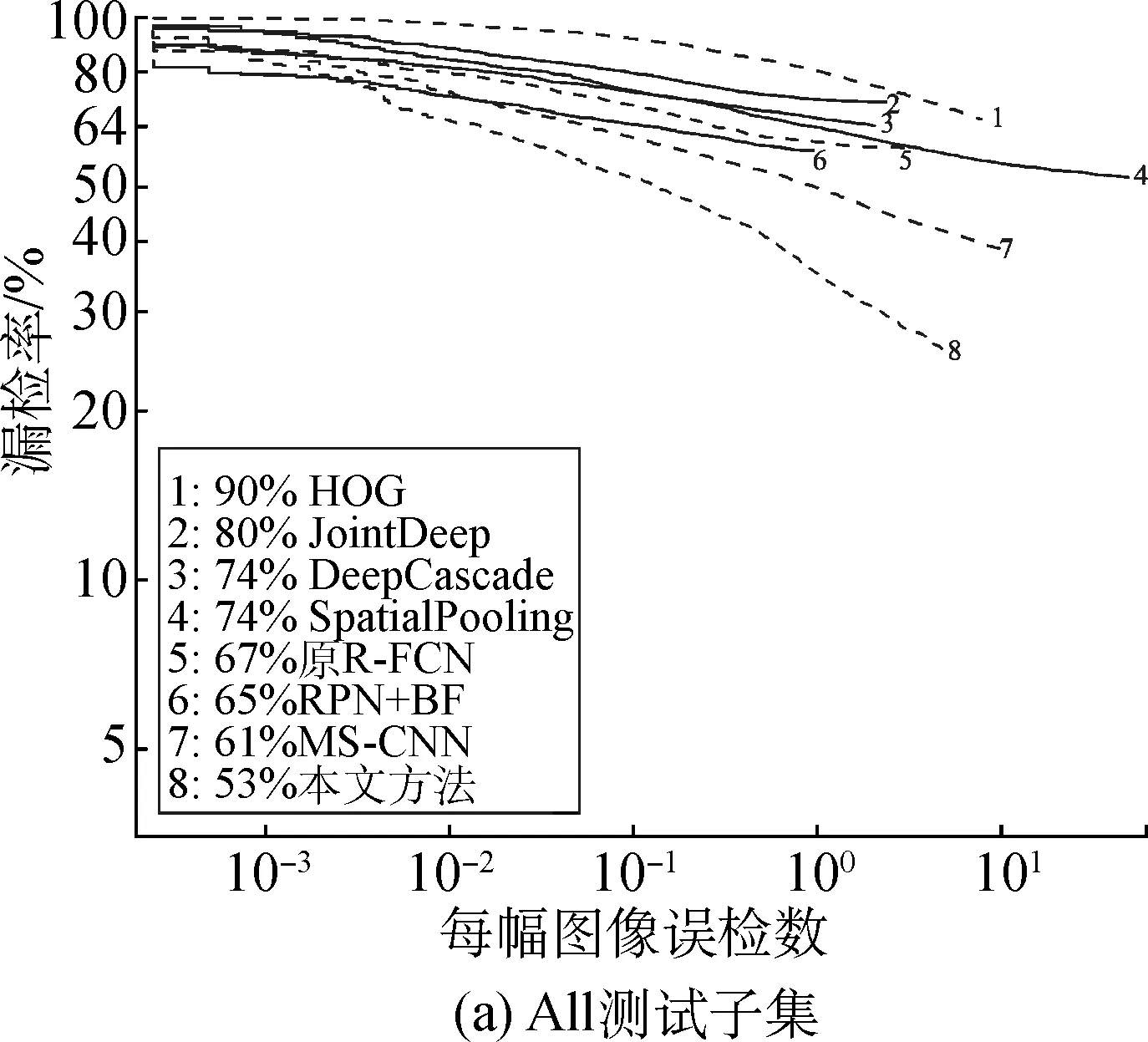
图5 本文方法与其他方法在All、Reasonable测试子集下的测试结果对比Fig.5 Comparison of test results of this method and other methods on the test subsets underAll and Reasonable setup
由图5所示曲线可知:
(1) 本文提出的改进R-FCN方法在All测试子集下的漏检率为53%,在Reasonable测试子集下的漏检率为9%,较原R-FCN方法分别降低了14个百分点和5个百分点。在任意遮挡情况下的漏检率明显降低,说明本文方法通过添加语义分割网络,能够提升网络模型对遮挡目标的识别能力,提高遮挡行人的检测精度。
(2) 相对于MS-CNN方法,本文方法在All子集和Reasonable子集的漏检率分别降低8个百分点和2个百分点;相对于RPN+BF方法,本文方法则分别降低12个百分点和1个百分点。结果表明,与其他方法相比,本文方法在遮挡情况和无遮挡情况下,均具有更好的行人检测性能。
本文方法与其他方法在Far、Medium、Near测试子集下的漏检率测试结果对比如表2所示。

表2 在Far、Medium、Near测试子集下不同方法的漏检率测试结果对比Table 2 Comparison of miss rate test results of different methods on the test subsets under Far, Medium and Near setup %
由表2数据可知:
(1) 与MS-CNN、RPN+BF等主流方法相比,本文方法在Far、Medium测试子集下的漏检率更低,在Near测试子集下的漏检率非常接近。由此说明,本文方法能够更精确地检测小尺寸行人,对中尺寸、大尺寸行人也取得较高的检测精度。
(2) 原R-FCN方法基本完全漏检小尺度行人。与原R-FCN方法相比,本文方法在Far测试子集下的漏检率降低7.4个百分点,说明通过增加特征融合模块和语义分割图,小尺度行人的检测性能得到提高。
本文方法与原R-FCN方法在Caltech数据集下的部分检测结果如图6所示,图中方框为检测结果框,椭圆虚线框为漏检目标框。从图6可以看出:原R-FCN方法虽然能够检测出大部分大尺寸行人,但是对遮挡行人和小尺寸行人的检测效果较差;本文提出的改进R-FCN方法可以检测出一些在近景和远景下的被部分遮挡目标,尽管依旧无法识别被完全遮挡目标,但对遮挡目标的漏检更少,预测框更精细,有效缓解了遮挡问题;许多原R-FCN方法漏检的小尺寸行人被本文方法成功检出,在小尺寸行人上的检测效果有所改善。

图6 本文方法与原R-FCN方法在Caltech数据集下的部分检测结果Fig.6 Some detection results of this method and the original R-FCN on Caltech datasets
2.6 ETH数据集试验结果
为更进一步验证本文方法的有效性和泛化能力,在ETH数据集测试模型,并与其他方法对比,测试结果如图7所示。
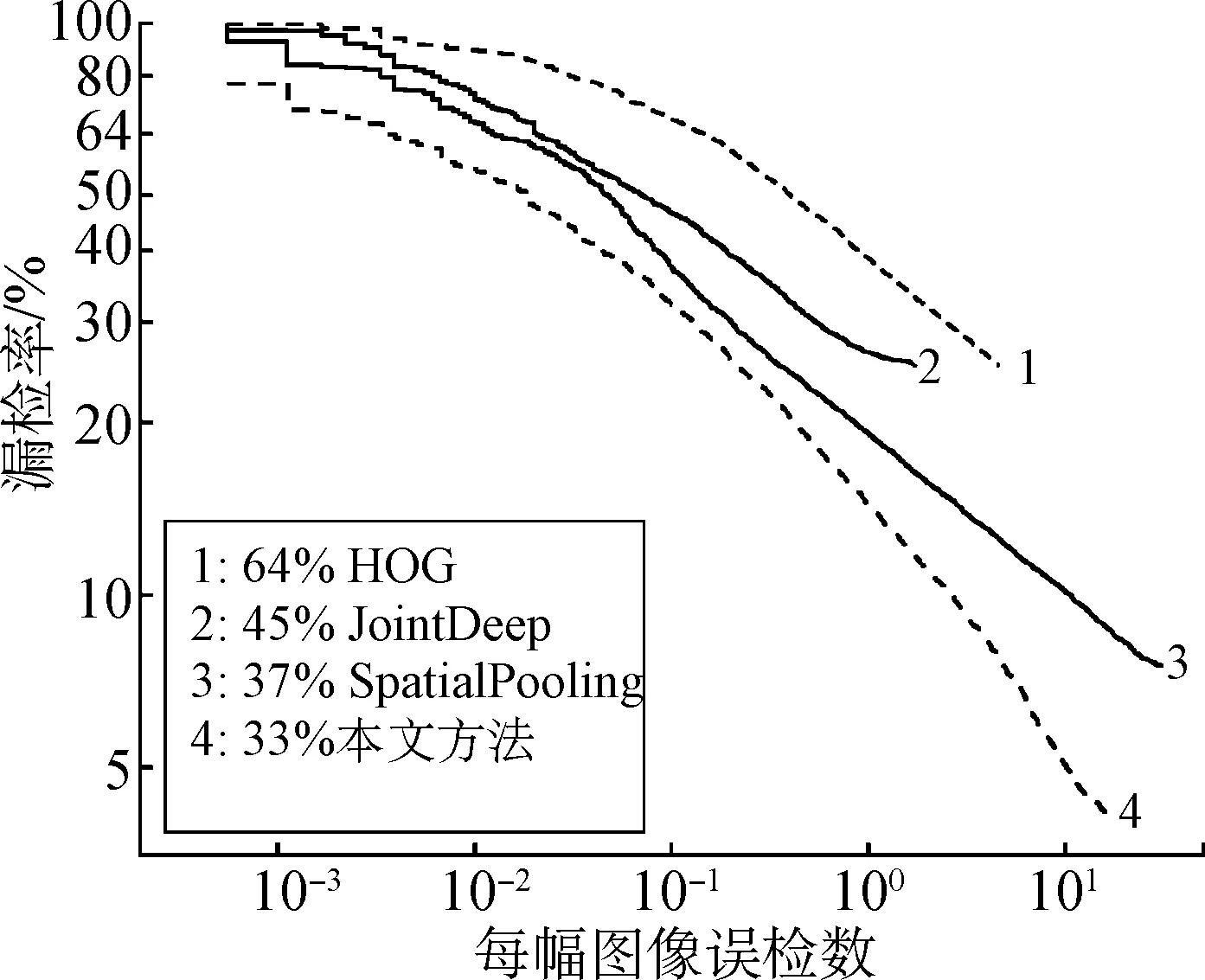
图7 ETH数据集下不同方法的测试结果对比Fig.7 Comparison of test results of different methods on ETH datasets
由图7可知,本文方法在ETH数据集下的漏检率为33%,与JointDeep和SpatialPooling方法相比,漏检率分别下降了12个百分点和4个百分点,并且明显优于传统HOG方法。由此表明,通过语义分割和特征融合,本文方法具有更高的检测精度、良好的泛化能力。
2.7 速度分析
为测试本文方法的检测速度,从数据集中随机选取200张图片进行测试,使用每秒检测图像数(frame per second, FPS)作为检测指标,并与其他方法进行对比,测试结果如表3所示。
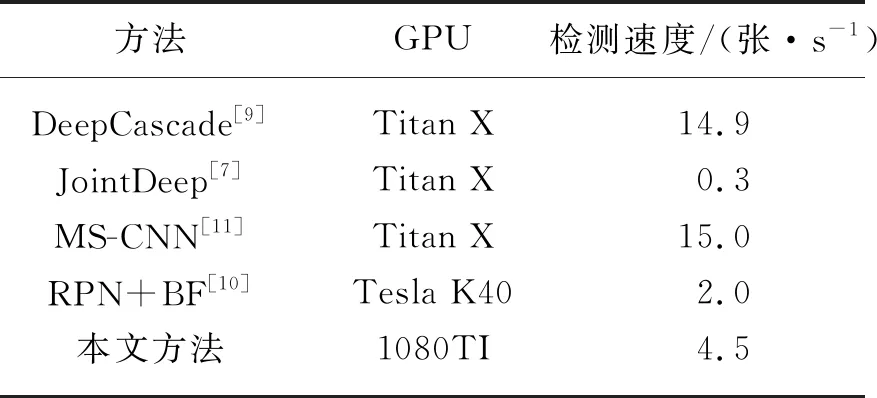
表3 不同方法检测速度对比Table 3 Comparison of detection speed of different detection methods
由表3可知,本文方法的检测速度为4.5张/s,快于JointDeep和RPN+BF,慢于DeepCascade和MS-CNN。检测速度受到影响的主要原因:(1) 与其他方法相比,本文方法的整体网络层次更深,参数规模更大;(2) 特征提取网络和语义分割网络阶段导致网络模型的计算量增加,耗费大量运行内存,降低了模型运行速度。但是本文方法平均每幅图像检测时间约为0.22 s,能够满足行人检测的实时性要求。
3 结 语
本文提出一种结合语义分割和特征融合的行人检测方法。利用语义分割网络提取出语义分割图,并融入到网络中,提升遮挡行人检测精度;利用特征融合模块,引入上下文信息,充分利用高层语义信息与低层细节信息进行检测,改善小尺度行人的检测效果。在Caltech数据集和ETH数据集上的试验结果证明,该方法具有很强的准确性与稳健性,能够有效降低遮挡行人和小尺度行人在复杂场景下的漏检率,同时满足实时性要求。未来将使用本文方法与更好的目标检测框架相结合,并调整相应的结构,进一步提高行人检测性能。
