基于分组注意力模块的实时农作物病害叶片语义分割模型
2021-05-09钟昌源胡泽林李华龙杨选将
钟昌源,胡泽林,李 淼,李华龙,杨选将,刘 飞
(1. 中国科学院合肥物质科学研究院智能机械研究所,合肥 230031;2. 中国科学技术大学研究生院科学岛分院,合肥 230026;3. 浙江大学华南工业技术研究院,广州 510700;4. 浙江大学生物系统工程与食品科学学院 杭州 310058)
0 引 言
农业是中国经济建设与发展的支柱,随着科技的发展和数字农业技术的推进,农业获得广泛的发展,但是仍然有许多因素制约着农业的进一步发展。其中,农作物病害严重制约农业的发展。传统农作物病害主要是通过农业专家进行诊断,效率低,治理慢,成本高,准确度随个人主观意愿波动,严重限制现代农业的发展。所以,现代农业亟需高效、准确和智能的农作物病害识别技术。
图像处理技术作为农作物病害识别的方法之一,其首先对农作物图片进行预处理和病斑区域分割,然后提取特征参数训练传统分类器识别农作物病害种类。传统分类器有贝叶斯判别模型[1]和支持向量机(Support Vector Machine,SVM)[2],具有较好的分类效果。柴阿丽等[3]使用贝叶斯判别模型对番茄叶病害进行识别,准确率达到94.7%。Camargo等[4]通过使用支持向量机提取棉花病害的不同特征对3种棉花病害进行识别,准确率达到90%。但是传统图像处理方法受限于数据集样本少,特征参数提取复杂,鲁棒性弱,泛化能力差,难以扩展到不同的农作物且无法应用于自然环境下的农作物病害检测,导致无法广泛推广应用。
随着深度学习(Deep Learning,DL)的发展和应用,特别是卷积神经网络(Convolutional Neural Networks,CNN)的出现,农业领域逐渐成为研究热点。卷积神经网络是一种高效的图像处理技术,能有效克服传统图像处理技术的弊端,具有自动提取特征、拟合特征方程等特点。Liu等[5]利用卷积神经网络模型识别苹果叶片病害,准确度达到97.6%。马浚诚等[6]基于卷积神经网络识别温室黄瓜病害,识别准确率为95.7%。Mohanty等[7]利用卷积神经网络对包含了14类农作物、26种病害的PlantVillage公共农作物数据集进行病害分类,识别精度高达99.3%。
上述研究表明了卷积神经网络在农作物病害识别方面有着独特的优势,但高性能卷积神经网络模型对数据依赖严重。由于农作物和病害的多样性,农业图像资源规模仍然太小。近年来,迁移学习(Transfer Learning,TL)能够从相关领域的大量标注数据中学习知识结构和模型参数,直接改善小规模数据量级农作物病害的识别性能,有效缓解过拟合,受到越来越多的关注。龙满生等[8]借助迁移学习将AlexNet模型[9]在ImageNet[10]数据集学习的知识迁移到油茶病害识别任务,准确率达到96.53%。赵立新等[11]利用 PlantVillage数据集预训练模型,对棉花病害数据集进行参数微调,精确率达到97.16%。李淼等[12]基于迁移学习机制使用VGGNet[13]模型对黄瓜和水稻病害进行特征提取,准确率达到98.33%。
为了扩大农作物病害识别应用领域,Fuentes等[14]将番茄叶片病害识别从分类问题扩展到检测问题,利用快速区域卷积网络(Faster Region-based Convolutional Neural Network,Faster R-CNN)、单次检测器(Single Shot Detector,SSD)构建病害检测模型,有效提高病害的识别和检测性能。刘小刚等[15]使用改进YOLO模型[16]对大量的草莓图像进行训练学习,实现了草莓的定位识别。赵兵等[17]替换传统卷积神经网络的全连接层为卷积层,对葡萄叶片进行特征提取,实现了葡萄病害叶片的语义分割效果。
尽管基于深度学习的语义分割模型在场景分割领域取得较好的分割效果,但是其在农作物病害叶片分割场景的应用文献鲜有报道。由于农作物病害发生受季节、环境、采集等多种因素影响,准确的分割农作物病害叶片具有相当大的挑战性。为了克服传统方法在病害叶片分割应用的缺点,本研究基于卷积神经网络建立实时农作物病害叶片语义分割模型,结合编码-解码框架和多流框架的优点提升模型分割性能,并进行试验验证,拟为现代农业病害识别、自动施肥和精准灌溉等应用提供可行方案。
1 材料与方法
1.1 图片采集与数据集建立
本研究以黄瓜和水稻2种农作物作为研究对象,采集了黄瓜霜霉病、黄瓜靶斑病、黄瓜白粉病、水稻胡麻斑病、水稻稻瘟病和水稻纹枯病,共6类病害(图1)。在安徽省农业科学院试验基地开展采集工作,采集时间从2017年1月起至2018年9月,采集设备为Canon EOS 6D数码单反相机,图片分辨率为900×600像素。本研究共采集原始图片2 337张,其中黄瓜白粉病202张、黄瓜霜霉病200张、黄瓜靶斑病147张、水稻纹枯病893张、水稻稻瘟病694张、水稻胡麻斑病201张。使用图像标注工具VGG Image Annotator[18]标注农作物病害叶片的类别和轮廓,建立农作物病害叶片语义分割数据集。
本研究还从PlantVillage数据集获取高质量图片,包括玉米灰斑病1 000张、马铃薯早疫病1 000张、番茄叶霉病1 000张、胡椒细菌斑1 000张、大豆灰斑病1 000张、南瓜白粉病1 000张,共6类6 000张(图1)。
1.2 数据多样化处理
为了增加农作物病害数据集的多样性,增强模型的泛化能力和鲁棒性,本研究共采用4种图片增强技术:1)翻转:将图片随机反转0°、90°、180°和270°;2)噪声:对图片添加高斯噪声;3)缩放:随机缩放图片,缩放因子为[0.5,2];4)裁剪:在缩放的图片上随机裁剪分辨率为900×600像素的图片。如果裁剪前图片的分辨率小于900×600像素,采用填充0像素的方式将图片的分辨率扩充至900×600像素。
为避免农作物病害样本数量不均衡现象,采用上述数据增强方法将黄瓜白粉病、黄瓜霜霉病、黄瓜靶斑病和水稻胡麻斑病扩充至5倍,对水稻纹枯病和水稻稻瘟病分别扩充至2倍和3倍。增强的农作物病害叶片数据集共包含16 375张图片。训练集、验证集和测试集按7∶1∶2的比例进行划分,数据集详细信息如表1所示。
1.3 评估方法
语义分割性能常见评价指标有像素精度(Pixel Accuracy,PA,%)、平均像素精度(mean Pixel Accuracy,mPA,%)、平均交并比(mean Intersection over Union,mIoU,%)等。本研究采用像素精度和平均交并比作为评价指标。为了便于解释评估指标公式,假设数据集共有k+1个类别,Pnm表示将n类别预测成m类别的像素个数,Pnn表示预测正确的像素个数,Pnm和Pmn分别表示假负和假正的像素个数。
1.3.1 像素精度
基于像素的精度(PA,%)计算是语义分割性能评估的基本指标,其衡量预测正确像素占总像素的比例,如式(1)所示。
1.3.2 平均交并比
平均交并比(mIoU,%)是语义分割和目标检测常用的衡量指标,用于评价预测物体与目标物体的重合比例。相比于像素精度,平均交并比提供更多的信息:预测目标的完整度和与实际目标的重合度。平均交并比定义如式(2)所示。
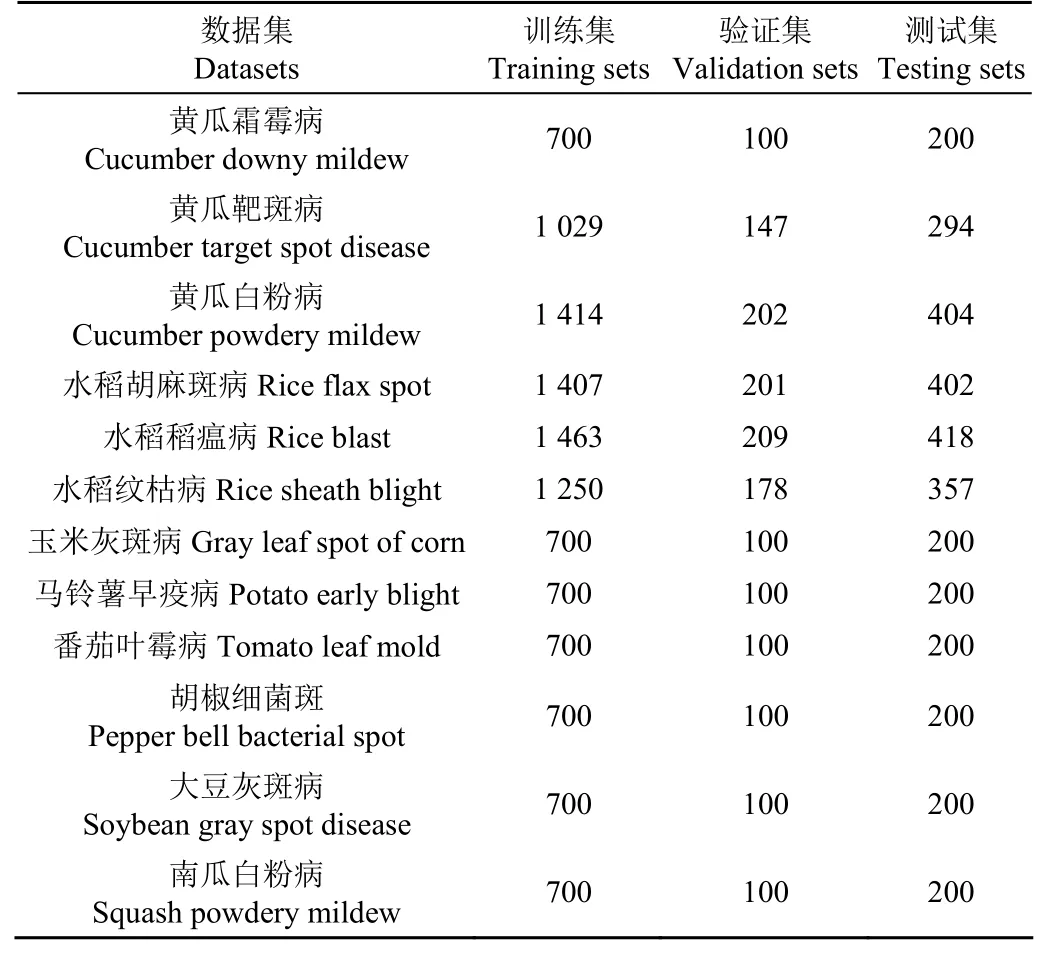
表1 增强的农作物病害叶片数据集Table 1 Enhanced dataset of crop disease leaves
2 分组注意力模块和农作物病害叶片语义分割模型
基于深度学习的语义分割模型主要分为两类,一类是采用编码-解码框架,首先利用逆卷积层[19]提高高阶特征的分辨率,接着融合低阶特征和高阶特征,预测结果。编码-解码框架具有高准确度,但计算量大,运行较慢,经典模型有U-Net[20]、SegNet[21]等。另一类是采用多流框架提取不同感受野尺寸的特征,通过融合多种尺寸特征预测结果,达到精度和运行速度的平衡,经典模型有BiSeNet[22]、ICNet[23]等。为了实现高精度且实时运行的农作物病害叶片语义分割模型,本研究结合编码-解码框架和多流框架的优点,将编码-解码模型的逆卷积层替换为普通上采样层,降低计算量,同时设计分组注意力模块利用高阶特征指导加强低阶特征,最后融合多阶特征提高农作物病害叶片的语义分割性能。
2.1 特征提取网络
特征提取是深度学习的关键,不同特征提取网络具有不同的参数量、速度和性能。常见特征提取网络有VGGNet[13],ResNet[24]和GooLeNet[25]等。得益于ImageNet数据集和迁移学习的发展,特征提取网络在ImageNet数据集预训练后再迁移到特定数据集可以获得更高精度。
He等[24]利用恒等映射原理有效解决由于神经网络层数过深导致的梯度退化问题,提出了具有101层的残差网络(Residual Network,ResNet)并赢得了2015年ImageNet大规模视觉识别挑战赛的冠军。相比于VGGNet[13]和GoogLeNet[25],ResNet[24]具有更少的计算量和更高的性能。为了实现实时语义分割目的,本研究采用计算量更少、性能更优的ResNet18[24]作为特征提取网络。
2.2 分组注意力模块
为了加强特征表达能力,提高模型的分割性能,本研究提出基于分组激活策略的分组注意力模块。传统注意力模块从输入特征通道方向计算特征间的关系系数并重构特征图,凸显有效特征,同时抑制无用特征。为避免梯度爆炸和消失,注意力机制常使用Softmax激活函数对关系系数y进行归一化,Softmax激活函数σ如式(3)所示。
式中yv为第v个关系系数变量,uy为第u个关系系数变量,假设共有N个关系系数变量。
但是由于Softmax激活函数的特点,即分母为特征关系系数的总和,特征之间会产生抑制作用,归一化后关系系数普遍偏低。受到分组卷积[9]的启发,由于特征提取网络的特征具有不同类型的语义概念,因此将特征的关系系数分为不同的组单独进行Softmax激活函数归一化,能有效避免特征组之间的抑制作用,发掘组内关联信息,增强特征。
融合高阶特征和低阶特征能有效提高语义分割性能:高阶特征提供高级语义信息,而低阶特征提供细节信息并优化语义分割结果。由于低阶特征包含较少语义信息,传统注意力模块不能有效加强低阶特征。本研究利用高阶特征计算低阶特征的关系系数,达到加强低阶特征目的,进而提高语义分割性能。
综上所述,本研究结合分组激活策略和由高阶特征指导加强低阶特征的想法,设计了分组注意力模块(图 2)。分组注意力模块一共有2个输入,分别来自特征提取网络的第L-1层和第L层,输出经由分组注意力模块加强的第L-1层特征。假设特征XL∈ℝC×W×H来自特征提取网络的第L层,C、W和H分别为特征XL的通道数、宽度和高度。为了计算特征间的关系系数,首先采用全局平均池化降低特征XL的维度,获得仅保留特征通道维度的特征ZL∈ℝC,如公式(4)所示。然后通过矩阵乘法计算第L-1层特征的关系系数yL-1∈ℝC-1,如式(5)所示。
式中X L(h,w)为特征XL在高度h和宽度w处的通道向量,AL-1∈ℝCL-1×CL为计算第L-1层特征关系系数的可学习参数,CL-1和CL分别为第L-1层和第L层的特征通道数。
受到分组卷积[9]的启发和鉴于特征具有不同的语义概念,特征关系系数分组激活可以有效避免不同语义特征间的抑制作用,从而增强同类语义特征,分组激活并增强特征的公式如式(6)所示。
首先将第L-1层特征XL-1和关系系数yL-1分成G组,即每组关系系数分别进行Softmax激活函数归一化。为了避免因关系系数趋于0造成原始特征信息消失,将归一化的关系系数加1。最后将加强的特征进行拼接。
2.3 语义分割模型
本研究的语义分割模型包含ResNet18[24]特征提取网络、2个分组注意力模块以及一个特征融合模块(图3)。模型首先使用特提取网络提取特征,分别获得来自第二层、第三层和第四层的特征X2、X3和X4。然后使用2个分组注意力模块分别加强特征X2和X3,即特征X3和特征X4作为分组注意力模块二的输入并输出加强特征特征X2和加强特征作为分组注意力模块一的输入并输出加强特征
受到多流语义分割模型的启发,充分利用具有不同感受野的不同阶特征能有效提高语义分割性能。为了复用特征X4、加强特征和加强特征本研究改进了多流语义分割网络中的融合模块(图3),首先将特征X4和加强特征上采样至加强特征的分辨率并进行拼接。然后使用卷积核大小为3×3的卷积层、批归一化层(Batch Normalization,BN)、激活层Relu[26]作为调整层充分融合三者的特征信息。最后通过卷积核大小为1×1的卷积层输出语义分割结果。
2.4 迁移学习和训练机制
为进一步提高模型的分割效果,本研究采用迁移学习将ResNet18[24]在PlantVillage公共数据集学习的农作物共性知识迁移到本研究数据集。首先以0.001学习率和200次迭代的超参数利用PlantVillage公共数据集预训练ResNet18[24]模型,病害识别准确率达到98.6%,即正确分类的样本数与总样本数之比。然后将ResNet18[24]预训练模型加载到本研究的语义分割模型,进行参数微调训练:
1)冻结ResNet18[24]预训练模型的所有批归一化层,被冻结层不参与训练。
2)采用随机梯度下降法(Stochastic Gradient Descent,SGD)微调模型参数。学习率初始化为0.01,更新策略采用多项式衰减法,避免因学习率较大而产生激烈振荡,迭代200次。
3)采用交叉熵计算分类损失,附加类权重参数进行惩罚,以减轻过拟合现象和样本不均衡现象。损失函数Loss(x)和类权重Qclass如式(7)和式(8)所示。
式中x为训练样本集,M为训练样本集数量,x r为第r个训练样本,p(xr)为样本xr真实类别,Qp(xr)为训练样本xr真实类别对应的类权重,q(xr)为模型预测样本xr类别概率,Sclass为类别占类别数量的比例。
3 结果与分析
3.1 帧率分析
本研究提出的语义分割模型采用ResNet18[24]模型作为特征提取网络,在保持性能的同时降低计算量。为验证模型的计算优势,本研究在单张NVIDIA GTX1080Ti显卡上测试运行帧率(Frame rate,FPS,帧/s),试验将不同分辨率的单张图片送入模型计算帧率,重复1 000次,以平均值作为模型的帧率。
为了对比本研究模型的计算性能,本研究复现了目前流行的语义分割模型:UNet[20]和BiSeNet[22]。UNet[20]采用编码-解码框架,为了保证公平性,UNet[20]改用ResNet18[24]模型作为特征提取网络。BiSeNet[22]属于多流语义分割模型,采用ResNet18[24]作为特征提取网络,在保证性能的同时降低计算量。3种模型对不同分辨率图片的帧率如表2所示。得益于分组注意力模块和融合模块的轻量化设计,在不同分辨率的情况下,本研究的语义分割模型计算性能都优于UNet[20]和BiSeNet[22]。对分辨率为900×600像素的图片,本研究模型帧率达到每秒130.1帧。

表2 不同像素下各种模型的帧率对比Table 2 Frame rate comparison of different models at different pixels
3.2 模型性能分析
比较试验UNet[20]和BiSeNet[22]的语义分割性能,验证本研究模型的分割性能。为了保证公平性,所有的模型的训练和预测使用相同的农作物病害数据集和迁移学习训练机制。对比试验结果如表3所示,本研究的语义分割模型的平均交并比达到78.6%,与UNet[20]和BiSeNet[22]相比分别提高1.6个百分点和1.2个百分点。3种模型对本研究自采集数据集和PlantVillage数据集的语义分割结果分别如图4和图5所示,其中本研究模型对局部黄瓜健康叶片具有更优分割效果(图4a~图4c)。

表3 各模型的分割性能对比Table 3 Segmentation performance comparison of different models
3.3 分组注意力模块分析
试验验证分组注意力模块性能,首先验证分组注意力模块在不同分组个数情况下对分辨率为900×600像素的图片分割性能和帧率(表4),共进行8种试验,每个试验分组个数分别为1、2、4、8、16、32、64和128。当分组个数为1时,分组注意力模块退化为传统注意力模块。分组注意力模块在不损失帧率的情况下提高分割性能,当分组个数为16时,本研究模型像素精度和平均交并比分别达到93.9%和78.6%,对比传统注意力模块(分组个数为1),平均交并比提高了1.6个百分点。

表4 不同分组个数下分组注意力模块的性能对比Table 4 Performance comparison of group attention module under different number of groups
为了进一步验证分组注意力模块对特征加强的效果,本研究分别采集了传统注意力模块(分组个数为1的试验)和分组注意力模块(分组个数为16的试验)对来自特征提取网络第二层特征2X前16个特征通道的关系系数y(图6)。分组注意力模块的关系系数普遍优于传统注意力模块,进一步强化特征,让关键特征发挥主要效果,同时抑制无用特征。
4 结 论
本研究基于分组激活策略改进传统注意力模块,提出分组注意力模块,利用高阶特征指导加强低阶特征,能有效避免特征之间互相抑制、加强效果偏弱的现象。分组注意力模块在大幅度加强关键特征表达能力的同时,抑制无用特征,提升模型整体性能。
基于分组注意力模块,本研究提出了一种融合编码-解码语义分割模型和多流语义分割模型优点的实时高效农作物病害叶片语义分割模型,本研究模型具有以下特点:
1)采用轻量级ResNet18模型作为特征提取网络,提取有效特征的同时降低计算量,为模型的实时运算提供基础。
2)使用迁移学习将ResNet18在PlantVillage公共数据集学习的农作物共性知识迁移到本研究数据集。
3)分组注意力模块利用高阶特征指导加强低阶特征,进一步提高特征的表达能力。
4)通过融合模块复用不同感受野的特征,有效提高语义分割性能。
本研究模型对农作物病害叶片的语义分割像素精度达到93.9%,平均交并比达到78.6%,优于UNet和BiSeNet模型。在单张NVIDIA GTX1080Ti显卡的硬件环境下,输入分辨率为900×600像素的图片,模型计算速度达到每秒130.1帧。
