基于大数据分析的变频器异常检测方法
2021-04-30闫会玉郑泽宇
闫会玉,郑泽宇,宋 宏,高 原
(1.中国科学院沈阳自动化研究所,辽宁 沈阳 110016;2.中国科学院机器人与智能制造创新研究院,辽宁 沈阳 110016;3.中国科学院大学,北京100049)
1 引言
随着工业自动化、智能化进程的不断发展,变频器被广泛应用于钢铁、化工、石油、冶金、水处理等各行业中,已成为当今节电、提高生产过程自动化水平、改造传统工业、推动技术进步的主要手段之一[1]。然而,在复杂的自然环境(结露、腐蚀、粉尘、高低温等)和电磁环境(EMI、过电压、过电流等)下,变频器极易发生故障,严重危害操作人员安全[2-3]。异常检测是故障诊断的第一步,在整个故障诊断过程中是最为关键的一步,因此变频器异常检测研究具有重要的意义。目前,异常检测在变频器方面的研究还不够成熟。主要的检测方法有基于分析模型的方法,基于定性经验知识的方法和基于数据驱动的方法。参数估计、状态估计、分析冗余法都是常用的分析模型[4-5]方法,但随着系统复杂度的不断提升,该方法难以获取足够多的系统复杂原理的每一个细节,无法建立精确的数学模型,虽然这种不精确性能够使模型的鲁棒性变好,但同时也容忍了故障的发生。基于定性经验知识的方法,主要有专家系统[6]、符号有向图等,该方法需要领域专家提供深厚的专业知识和长期积累的经验知识,现实操作性较难。数据驱动的方法是结合先进的人工智能技术、信号处理技术以及一些数理统计方法,通过监测设备运行,提取设备运行异常特征,根据特征变化识别异常。常用的数据驱动方法,如模糊控制[7-8]、小波变换[9-10]、神经网络[11]等,这些方法的诊断需要大量的正常、异常运行数据来训练模型。而在现实生产中的变频器数据量很大,但大部分都是正常数据,异常样本非常少,降低了以上方法的现实可行性。
针对以上问题,提出一种基于密度峰值聚类与概率统计分析的方法,该方法属于数据驱动的方法,但该方法不需要大量的异常数据样本,适用于长期处于在同一种工作条件下的设备进行异常检测。该方法通过对特定条件下的设备正常运行数据进行分析,构建该条件下的正常运行模式,利用该模式来识别异常行为。首先对设备海量历史运行数据进行密度峰值聚类,然后计算不同类簇之间的转移概率,基于历史类簇及其相互间的转移概率并结合滑动时间窗口模型提出异常检测框架,对新的设备运行数据运行情况进行异常判别,最后通过变频器异常数据案例验证了该方法用于异常检测的有效性。该方法通过密度峰值聚类能够简化多维参量的复杂关系;同时通过聚类识别异常来代替阈值限定识别异常,可以解决传统阈值限定方法中阈值设定无参考的问题;最后通过分析类簇转移规律,用概率表示不同类簇间的转移特点,能够从时间维度上发现设备运行的异常状况。
2 算法介绍
2.1 密度峰值聚类方法对变频器运行数据聚类

表示当点i为局部密度最大点时,求与i距离最远点的距离。否则,求比i点密度大的点距i点的距离的最小值。
步骤2 确定聚类中心
(1)根据决策图,设置密度阈值ρth和距离阈值δth。(2)当xi的最小距离δi>ρth,且ρi>ρth时,xi为聚类中心,并赋予类别标签。(3)按照(2)遍历所有数据点,找到所有的聚类中心。
步骤3 为非聚类中心点归类
将非聚类中心点的比其局部密度大的邻居点的类别标签,作为该点的类别标签。若其所有高密度邻居同为无类别属性,继续迭代,直至找到为聚类中心的高密度邻居点。
2.1.2 密度峰值聚类方法优化
从前文可知,在密度峰值聚类算法中,超参数截断距离dc,对聚类结果有较大的影响。截断距离dc过大,导致数据点的局部密度值差别太小,降低聚类的差异性;若dc过小,又会使簇类结果变多,降低聚类的内聚性。因此,找到一个合适的截断距离,对密度峰值聚类方法非常重要。参考文献[13]中的方法,该方法引入了K近邻的思想,提出确定dc的新方案。

2.2 时序变化过程挖掘
通过密度峰值聚类,得到类簇时序数据S={S1,S2,…,St,…,Sn},其中St表示t时刻运行数据所属类簇编号,S∈{1,2,…,M}。设备的整个运行过程就是在不同类簇之间进行转移的过程,通过分析类簇时序的转移概率Pij能够找到设备正常运行时的变化规律。Pij表示从类簇i向类簇j转移的概率。

假设聚类结果共M簇,那么类簇转移概率分布,如表1 所示。

表1 类簇转移概率分布表Tab.1 Cluster Transfer Probability Distribution Table
根据类簇转移概率分布,得到概率转移时序P={PS1S2,PS2S3,…,PSn-1Sn}
由于概率值是在正常运行模式下计算得到,那么概率值越大说明这两种类簇之间的转移更频繁,那么这种转移情况便更符合正常运行模式。但是设备的运行随时随地都会有噪声的存在,正常数据向噪声数据转移的概率较低,影响异常判别。通过滑动时间窗口取平均的方法利用正常数据转移的大概率,来补偿噪声数据出现时的小概率问题,能够提高判别的准确率。同时实时异常检测作业,本质上属于短小批处理作业过程,利用滑动时间窗口模型,能够快速找到非正常的运行模式,实时处理监测数据。

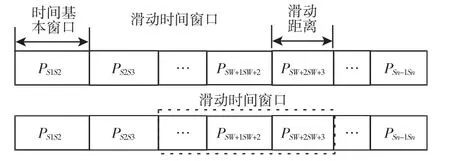
图1 时间滑动窗口模型Fig.1 Time Sliding Window Model
异常检测整体框架图,如图2 所示。首先利用大量的正常运行时的历史监测数据进行密度峰值聚类,并计算滑动窗口下的平均转移概率;然后对新的监测数据进行类簇匹配,并计算新数据的平均转移概率;当数据频繁出现与现有类簇均不匹配或者平均转移概率值低于正常概率值时,判定设备出现异常;根据出现类簇不匹配的时间和概率值开始下降的时间,判断设备异常发生的时间。
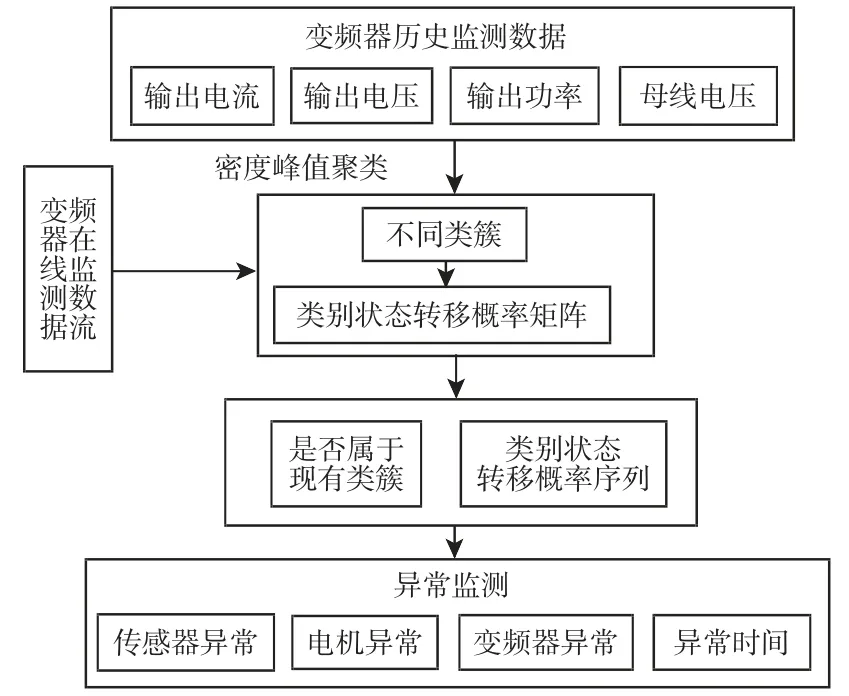
图2 异常检测框架图Fig.2 Framework for Abnormal Detection
3 方法验证
3.1 基于实际数据挖掘正常运行模式
利用某油田变频器的运行数据来验证文章中提出的方法,该油田变频器长期工作在一种不变工况下,数据采样周期为1s,数据标签有时间、母线电压、输出电压、输出电流、输出转矩、运行频率。模型训练环境:python3.6,win10 操作系统。利用120 天的正常运行数据训练正常运行模式。油田变频器前5 条数据,如表2 所示。

表2 变频器运行数据Tab.2 Inverter Operation Data

表3 类簇转移概率分布矩阵Tab.3 Cluster Transfer Probability Distribution Matrix
在密度峰值聚类中,K值取15,计算得到dc=0.27。通过密度峰值聚类,最后得到10 个正常类簇,并将离群点作为异常类簇0,类簇间的转移概率分布,如表3 所示。取滑动时间窗口大小W=30,经过滑动窗口模型处理后的状态转移序列,如图3 所示。

图3 正常模式下平均转移概率Fig.3 Average Transfer Probability in Normal Mode
从图3 中可以看出,正常运行情况下,滑动窗口下的平均转移概率集中在(0.45~0.55)之间,该变频器在该工况下的正常运行模式需要符合(0.45~0.55)之间的概率变化,反之,若小于该概率,说明设备运行有异与以往的运行规律,可能是异常的出现所导致。
3.2 异常案例验证
案例1:电磁环境干扰,变频器内部工作机制紊乱。
从第153 点开始变频器运行紊乱,如图4(a),图4(b)所示。输出电压、输出电流有别于正常运行情况下的波动规律,但并未超出阈值限值,单纯依靠内部阈值检测电路并不能发现异常。通过分析其各个状态转移概率的变化,如图4(d)所示。发现从第153 个数据点开始滑动窗口下的平均转移概率迅速下滑,概率值低于正常模式水平,判断是一种异常现象。


图4 故障1 数据及分析图Fig.4 Fault-1 Data and Analysis Chart
案例2:制动单元故障。
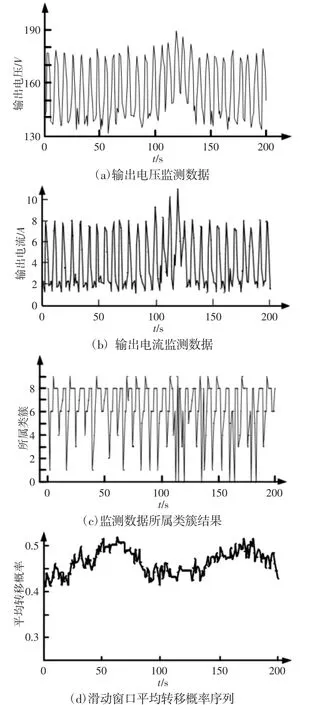
图5 故障2 数据及分析图Fig.5 Fault-2 Data and Analysis Chart
油田变频器在下行过程中,电机在高速运转时突然制动,但电动机的转子带着负载有较大的机械惯性,不可能很快的停止,这样就产生反电势,电动机处于发电状态,其产生反向电压转矩与原电动状态转矩相反,而使电动机具有较强的制动力矩,迫使转子较快停下来。但由于通常变频器中的整流电路是不可逆的,因此无法回馈到电网上去,能量将在滤波电容上累积,产生泵升电压,它对变频器有极大的破坏力。但在工作过程中这种现象无法避免,因此通常会在直流母线之间接通一个能耗电阻,当母线电压超过一定值时,通过电阻将多余的能量吸收。图5(b)从第100 个点开始,变频器输出电流出现过高数据点,图5(a)从126个数据点开始输出电压有明显的冲高现象,同时变频器报过压警告,如图5 所示。根据前文提出的异常检测方法,如图5(d)所示。虽然经滑动平均后的转移概率并没有明显的低概率出现,但在图5(c)聚类结果中,从113 个数据点开始频繁出现一些不属于任何现有类簇的数据点,所以该方法仍能够提前识别出异常。
4 结语
变频器设备原理复杂,监测数据量大,基于模型与基于经验的方法实现困难,而普通的神经网络、模糊控制等方法又因为异常样本不足问题仍无法实现。针对以上问题,提出一种基于密度峰值聚类和概率统计分析的异常检测方法,充分了利用变频器监测数据量大的特点,找到了一种工况不变情况下的设备正常运行模式,并通过对比正常模式,识别出了设备异常行为。但该方法只适用于同一设备在固定工况下工作时的异常识别,不能识别在多变工况下工作的设备异常行为,下一步将在这方面进行深入的研究。
