Forestry big data platform by Knowledge Graph
2021-04-30MengxiZhaoDanLiYongshenLong
Mengxi Zhao · Dan Li · Yongshen Long
Abstract Using the advantages of web crawlers in data collection and distributed storage technologies, we accessed to a wealth of forestry-related data. Combined with the mature big data technology at its present stage, Hadoop’s distributed system was selected to solve the storage problem of massive forestry big data and the memory-based Spark computing framework to realize real-time and fast processing of data.The forestry data contains a wealth of information, and mining this information is of great signif icance for guiding the development of forestry. We conducts co-word and cluster analyses on the keywords of forestry data, extracts the rules hidden in the data, analyzes the research hotspots more accurately, grasps the evolution trend of subject topics, and plays an important role in promoting the research and development of subject areas. The co-word analysis and clustering algorithm have important practical signif icance for the topic structure, research hotspot or development trend in the f ield of forestry research. Distributed storage framework and parallel computing have greatly improved the performance of data mining algorithms. Therefore, the forestry big data mining system by big data technology has important practical signif icance for promoting the development of intelligent forestry.
Keywords Intelligent forestry · Co-word analysis ·Knowledge Graph · Big data
Introduction
Forestry data collection systems are mostly built by public organizations such as government and research institutes,with the participation of private enterprises relatively minor(Bovenzi 2009; Ruslandi et al. 2014). Because of the relatively weak development of forestry on the Internet compared with other industries such as f inance (Frank et al.2015), data coverage and data customization services are still lacking (Tang et al. 2009). Combining forestry data with big data platforms to achieve forestry data collection,cleaning, storage, calculation, analysis and information mining is key to digital forestry (Li et al. 2016). Achieving this requires leveraging existing mature big data architectures.Only the combination of analytical and platform technologies can make better use of the value of multi-source forestry data. Therefore, the development of a forestry big data platform system is an important direction for the development of intelligent forestry.
Developed countries such as the United States and Canada have long noticed the importance of sharing of forestry spatial data. Systems have been established (Jie et al.2016) such as the Forest Resources Survey and Analysis System of the US Forest Service. In order to facilitate access to various resources, users can f ind the required spatial data through the Geospatial One-Stop geospatial data website home page, query results, view the metadata information, and save the map. Canada has established the National Forestry Information System which provides authoritative information on Canadian forests. The system includes basic map information, forest maps, vegetation maps, and ecological maps at diff erent scales. Europe also attaches great importance to forestry spatial information,as the data collection process in diff erent countries has its own system. To coordinate and assimilate forestry data within the European Union (EU), the European Forest Information and Communication System (EFICS) was established to solve forestry information needs at the European level with the aim of standardizing and processing data related to forestry.
With the development of computer and network technologies to strengthen the sharing and integration of forestry data and meet the needs of government, scientif ic research institutions and all sectors of society for forestry data, China has established China’s sustainable forest resources sharing network (Hou et al. 2009). Its data resources include a forestry sustainable development security system, forest resource dynamics, forest ecosystem health, forestry industry development, biodiversity conservation, ecological environment monitoring, socio-economic culture and other aspects (Li et al. 2016). The public can browse forest policies, access and query data related to forest resources, or download information to the local level but cannot directly call and integrate these spatial data.
With the existing big data framework and data mining algorithms, we developed a practical system that can realize forestry big data storage and analysis. The system selects the distributed f ile system HDFS in Hadoop as a data storage tool to build a forestry big data storage and analysis system.The co-word analysis and clustering algorithm are used to process the forestry data keywords and realize the mining of forestry data. In addition, the system also has the function of data query, f ile uploading and automatic crawling of web data. The platform is based on an advanced big data system framework, taking advantage of web crawlers in data collection combined with distributed storage, to obtain a large amount of forestry-related data. The user-friendly forestry retrieval function is accomplished by using advanced word segmentation methods and knowledge map-related technologies. At the same time, the use of multi-level cache to improve the query effi ciency of the system aims to provide a common query platform for forestry experts and scholars to achieve the goal of forestry metadata sharing in digital forestry (Zhao et al. 2011). This article includes the following:
(1) The analysis of Chinese forestry national standards and establishment of a dictionary-based vocabulary by using web crawlers and similar search techniques;
(2) The development of distribution storage technology to improve the storage performance of forestry dictionaries;
(3) The development of multi-level caching based on metadata relationship to improve the query speed of forestry dictionary;
(4) The use of rich semantic information of the knowledge map to establish a forestry big data platform, enabling users to search for information more accurately and quickly.
Materials and methods
Forestry dictionary basic thesaurus establishment
A digital forestry basic database was established with more than thirty forestry national standards (Mohai 2010; Ruslandi et al. 2014). National standards refer to documents that are approved by the national standardization authority and are purchased through formal channels after they have been announced. In addition to standards enforced by national laws and regulations, there are those that have a signif icant guiding inf luence. National standards are divided into legal standards, recommended standards, trial standards, and draft standards.
For the f irst part of this study, forestry national standards were scanned into an electronic PDF, and then FineReader software was used to parse the PDF. Photos were also converted into text and manual verification performed.FineReader is a document-recognition software that supports multi-languages and provides powerful functions such as color and font recognition.
After manual verif ication, related database tables were created according to the structure of the system design. The writing program stored the recognized text from the tables.The creation of the tables complied with digital forestry regulations and forestry national standards which ensures that the basic database has authority.
Crawling of related articles
The explanation of each term in the forestry national standard is concise but insuffi cient for a professional search. We,therefore, used the URL connection class in Java to implement a web crawler based on keyword crawling, whereby a designated keyword crawls a web page for information associated with it.
Because a large amount of forestry data is on the Internet,it would be an immense task to collect it manually. To solve this, a web crawler was developed, and when the crawler user sets the rules and the URL of the portal, the crawler automatically starts crawling and saves the information(Groc 2011 ; Stevanovic et al. 2012). Crawlers commonly used in search engines belong to the general web crawler(Zheng 2009). The objective of this paper was to build a database with network crawler technology focusing on the collection, cleaning and utilization of complex forestry data.The structure of the web crawler is shown in Fig. 1.

Fig. 1 Structure of the web crawler
Web crawler is a type of program or script that automatically collects information on the World Wide Web according to certain rules. It is widely used in Internet search engines and similar websites and automatically collects the content of pages it has access to, in order to obtain and update the content and retrieval methods of these websites. Functionally speaking, the reptiles are divided into three parts: data acquisition; processing; and, storage. The web crawler, or simply crawler, starts with and obtains one or more URLs of the initial web page. In the process of crawling the web page,it continuously extracts new URLs from the current web page and places them into the queue until it meets certain stopping conditions of the system. All web pages captured by web crawlers are stored in the system, analyzed, f iltered,and indexed for subsequent queries and retrievals.The crawled web page is eventually stored in the distributed HBase. The database design shows that the tables used to store related information include f ields such as wordname,content, urladdress, text, and type. Wordname is the entry name, content the source f ile for crawling the page, urladdress the address of the crawled page, text the textual information of the crawled page used as a training sample for the word2Vec algorithm, and type is used to record types of web pages (Fig. 2).
Distributed storage implementation
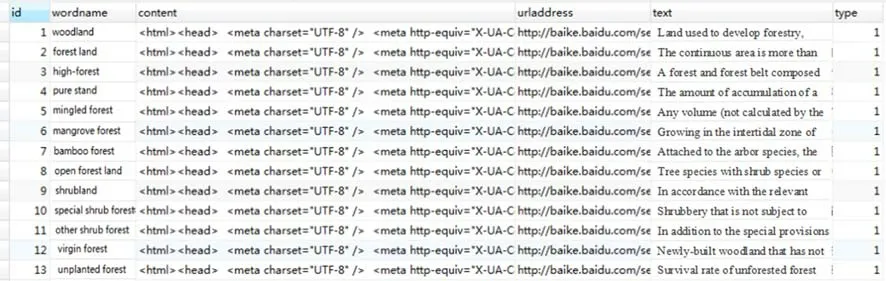
Fig. 2 Entry-related page information
The rapid development of Internet applications has greatly promoted distribution storage (Gong et al. 2014). More and more network users produce a large amount of data and how to manage this data Effectively and realize network sharing has brought new ideas to the existing storage system; one such idea is distributed storage technology (Wu et al. 2016).
There are many common distributed f ile systems, all of which are application-level. Among them, the application of the Hadoop Distributed File System (HDFS) is particularly extensive (Shvachko 2010). It is designed to run on commodity hardware and has much in common with existing distributed f ile systems. However, at the same time, it is also very diff erent from other distributed f ile systems. HDFS can provide high throughput data access and is very suitable for large-scale data sets. It is an open source project of Apache(Jiang et al. 2011) and has the characteristics of resource transparency, concurrent access, and high availability. It realizes shared storage and distributed storage.
According to analysis of the original data, the relational database stored after the data is divided into structured data(Fig. 3).
Due to the portability of Java, this platform is written in the Java language and runs on both the Windows and the Linux operating systems. The business logic inside the platform adopts the Model View Controller (MVC, it organizes code with a method of separating business logic,data and interface display, and gathers business logic into a component. It does not need to rewrite business logic while improving and personalizing the interface and user interaction.) mode which separates the view layer and the business layer of the system. It does not rewrite the business logic so the model and controller code are not recompiled when the view layer code is changed which reduces the coupling degree of the code.
Fig. 3 Table structure
When the user initiates a read or write request, the platform performs logical processing such as determining whether the f ile exists, and then submits the request to the NameNode through the RPC call. In order to speed up the response of the system, we used MemSQL in-memory database as the cache of big data analysis platform. The cache saves the directory structure of distributed f ile system the HDFS (Hadoop Distribution File System). This has the advantage of not only improving the access effi ciency of the f ile system, but also Effectively alleviating it. The pressure on the NameNode node is because a portion of the f ile access request is completed by the cache.
The user selects the f ile to be opened through the visual interface. The ordinary f ile directly reads the f ile content from HDFS. If it is a connection f ile, the cache f ile is f irst accessed to obtain the real f ile indicated by the connection f ile, and then accessed according to the ordinary f ile.
The forestry big data platform encapsulates some of the user’s operational processes, and users do not need to conf igure the environment or load operations to submit applications. The whole process uses asynchronous mode to interact. First, the local application is sent to the FTP server of the platform through the FTP protocol, and a message is sent to the ActiveMQ queue. An application management process, AppManager, runs on the FTP server. The process continuously detects the resource usage of the platform,extracts a message from ActiveMQ and parses it, f inds the application’s binary Jar package based on the parsed result,submits it to the Spark cluster for analysis, and returns the f inal result.
Knowledge Graph implementation process
Word segmentation technology
Recent information environment-dominated by text information, and how to process text information effi ciently and accurately have become hot topics for research and business applications. Before processing the text information, the text is separated into smaller vocabulary units. This process is word segmentation (Li 2012; Zhang et al. 2012).
Word2vector is Google’s open source project that converts words into vectors. It transforms text processing into spatial vector transformations. In this way, the similarity of texts can be used to represent the semantic similarity of texts(Sun 2012). Word2vec is based on a neural network language model which calculates the distance between words by calculating the cosine angle between words.
This study uses word2vector to calculate the semantic similarity between each metadata so as to reveal similar terms with the current metadata in order to predict user operations.
The construction of a forestry-related knowledge network is then explored with the help of Knowledge Graph which reveals the research situation in this f ield objectively in order to better conduct in-depth research and provide a new idea for forestry research and hot spot mining.
The realization process of Knowledge Graph is formulated into six modules: knowledge acquisition, fusion, and storage, query semantic understanding, knowledge retrieval,and visualization (Pujara et al. 2013; Paulheim 2017). Construction of a knowledge base is the core of the Knowledge Graph implementation. The content stored in the knowledge base needs extensive knowledge acquisition and full knowledge fusion. When the user performs a “query and retrieval”operation, the user’s query language enters the retrieval system after semantic analysis processing and matches and integrates the content in the knowledge base. Feedback results are then presented to the user in a visual form.
Knowledge acquisition
To improve the quality of knowledge services and provide users with reasonable answers, Knowledge Graph not only includes common sense knowledge in the f ield of forestry,but also discovers and adds new knowledge in a timely manner. The quantity and quality of knowledge determines the breadth and depth of all knowledge services it provides and the ability to solve problems (Fisher 1987). Therefore, the construction of the Knowledge Graph needs to be supported by effi cient knowledge acquisition. Common sense knowledge is obtained from structured data of encyclopedia and various vertical sites such as extracting information about pests and diseases from the Baidu encyclopedia, and extracting domain-related facts based on a specif ic extraction strategy. At the same time, instances and attributes are extracted from semi-structured and unstructured data which enriches the description of related entities (Gu et al. 2012).
With the emergence of a large amount of user interaction information, user generated content (UGC) continues to increase, and users are involved in the creation, organization, and dissemination of network information. Some of the knowledge generated in this manner is also an important aspect of knowledge acquisition. New knowledge can discover new entity attributes from the user’s query log and continuously expand knowledge coverage.
Knowledge fusion
Because of the wide range of knowledge sources in Knowledge Graph, there are problems such as uneven quality of knowledge, duplication of knowledge from different data sources, and unclear association between knowledge sources. Therefore, knowledge must be integrated (Dong et al. 2014). Knowledge fusion is a high-level knowledge organization which enables the knowledge from diff erent sources to carry out heterogeneous data integration, entity importance calculation and reasoning verif ication (Dong et al. 2015), and other steps under the same framework specif ication. Heterogeneous data integration involves data cleansing, entity alignment, attribute value decisions, and the establishment of relationships. Entity alignment solves the problem of inconsistency in the description and format of the same attribute in the same entity from diff erent data sources and regulates the entity description method and format. The attribute value decision is mainly for cases where diff erent attributes of the same value occur.[Select the number of data sources and reliability to extract more accurate attribute values.] In essence, the process of building relationships within Knowledge Graph can be simplif ied as related to entity mining, that is, looking for co-occurring entities in user-like queries or other entities mentioned in the same query through the extraction of statistics on links and to users.
The degree of importance of an entity is calculated by algorithms such as PageRank, and the relationship between entity attributes and entities, the prevalence of diff erent entities and semantic relations, and the degree of conf idence of extraction, all aff ect the result of entity important calculations. After an entity in a user query is identif ied, a structured summary of the entity is presented to the user.When the query involves multiple entities, it is necessary to select entities that are more relevant to the query and more important to exhibit. If you search for “Larix caterpillar”,the relevant entities are harmful to larch, Korean pine, Chinese pine,Pinus sylvestris, spruce, f ir and other conifers, and these entities would be sorted according to the calculation of importance. The rules of reasoning generally involve two categories, one for attributes and the other for relationships.
Co-word analysis
Although the current methods of forestry domain analysis meet some needs to a certain extent, it is still necessary to improve the subject search related to forestry and the accuracy of analysis results to meet the needs of rapidly changing and developing disciplines. Therefore, the purpose of this study is to improve the accuracy of forestry subject research by using co-word analysis to identify the key links in forestry subject recognition.
According to the relevant literature, most researchers choose the author keyword as the analysis object. Keyword is a word or phrase that the author considers as revealing and summarizes the main content of the author’s work (Callon et al. 1991; Liu et al. 2012). Therefore, this study selected the author keyword as the object of the search keyword. An improved graph analysis process and the specif ic analysis f low is shown in Fig. 4.

Fig. 4 Improved subject map recognition and analysis process based on Knowledge Graph and co-word analysis
A forest-related keyword set is established using web crawler with the range of the set determined by an artif icial test. It is also necessary to identify the relationship between backbone words by constructing a common word matrix of those words. If the frequency of co-occurrence between two words is high, it means that the relationship between them is relatively similar. In the actual measurement analysis process however, since the frequency of occurrence of keywords is an absolute value, it is diffi -cult to ref lect the true degree of mutual dependence. It is,therefore, necessary to use a special correlation coeffi cient calculation method to convert the original co-word matrix into a correlation matrix, that is, to conduct matrix normalization before subsequent analysis.
The more commonly used four common word standardization calculation methods are: correlation strength, cosine coeffi cient, tolerance index, and Jaccard coeffi cient.
(1) Correlation strength formula:

(2) Cosine coeffi cient formula:

(3) Inclusion index formula:
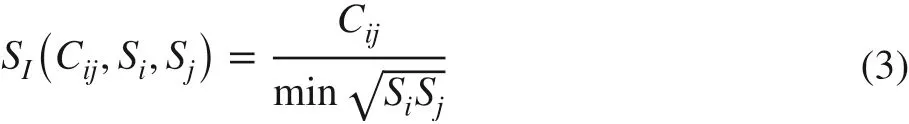
(4) Jaccard coeffi cient formula:

whereC ijrepresents the frequency of co-occurrence of the wordsiandjin the document set, whileS iandS jrepresent the total frequency of the wordsiandjin the document set.
Through a comparative analysis of the four standardization methods, the number of two phrases co-occurrence is aff ected by two factors: correlation and frequency between phrases (Boettcher and Wolfe 2015). Recent research compared the correlation between a phrase and other phrases(calculated by the average values of diff erent coeffi cients),with the phrase frequency. It was found that the cosine coeff icient, the inclusion index, and the Jaccard coeffi cient have no correction Effect on phrase size. It does, however, have a correction function with the inf luence of other phrase modules, so it is considered that the correlation strength formula is best suited for the standardization of co-occurrence data,while the cosine coeffi cient, the inclusion index, and the Jaccard coeffi cient are not.
According to the method of domain topic detection, the f irst step is to obtain the subject words of the literature as the target object of subsequent co-word clustering analysis.For example, the key word of woodland is analyzed through a total analysis (Fig. 5).
Knowledge storage and retrieval
The acquired knowledge is stored in the database and is a largescale association set. Chaotic information is integrated and processed in the early stages to form orderly, relevant and usable knowledge. The key words of knowledge are classif ied and stored in diff erent modules in the knowledge base in a standardized form, and the index is generated to make knowledge retrieval more intelligent in terms of Effective matching and deep knowledge mining. With BigTable and depending on the Hadoop Distribution File System (HDFS) database, the distributed storage of massive forestry data was chosen for this study.
Knowledge retrieval is an intelligence retrieval method to recognize knowledge association and concept semantic retrieval on the existing forestry large data platform. Knowledge retrieval in knowledge atlas has two core tasks: one to f ind the corresponding entity in the knowledge base by using relevance; the other to f ind the relevant entity according to the information of entity category, relationship, and relevance. Knowledge mining and ref ining are carried out on a forestry database, and the retrieval system provides users with accurate and complete importance ranking of knowledge and recommends relevant knowledge.
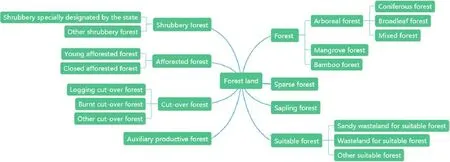
Fig. 5 Topological relation diagram of woodland co-word analysis

Fig. 6 System data f low
Visualization
To achieve a user-friendly query interface, the project uses JAVA EE’s SSH (Struts + Spring + Hibernate) component as the background support for the system.
The search interface is divided into the following layers: domain object layer, data access layer, business road base layer, control layer, and presentation layer (Fig. 6).The Model View Controller (MVC) organizes the code in a way that separates business logic, data and interface display. While improving and customizing the interface and user interaction, it does not need to rewrite business logic. MVC has been uniquely developed to map traditional input, processing and output functions in a logical graphical user interface structure. The Data Access Object(DAO) design pattern is used to separate the underlying data access logic from the high-level business logic.Implementing the DAO pattern can focus more on writing data access code.
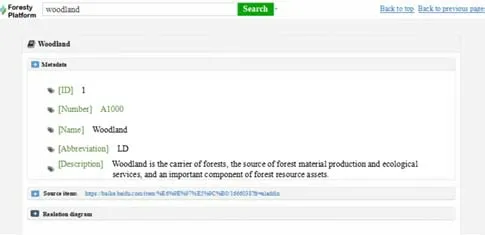
Fig. 7 Results of forestry search

Fig. 8 Terms related page display
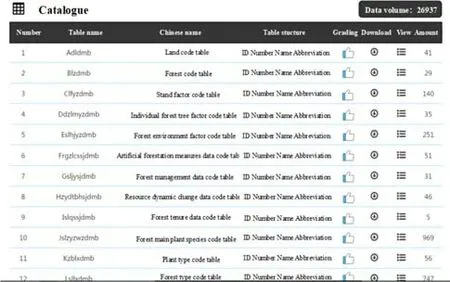
Fig. 9 Forestry national standard display page
Results
Display of results
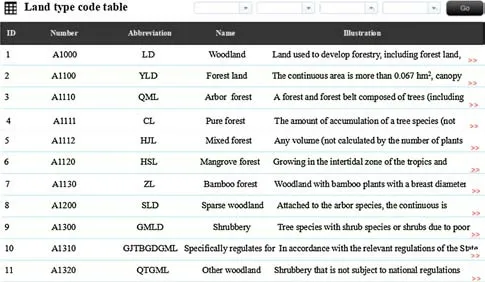
Fig. 10 Details of the forestry national standard

Fig. 11 Entire network search
After accessing the home page of the Forestry Big Data Platform, the word to search for, e.g., ‘woodland’, is entered into the input box. The system will automatically prompt based on existing entries in the dictionary. The user can then click on search and the results will show the def inition of woodland in the dictionary (Fig. 7).
The interface is divided into three modules: metadata,relational web pages, and related words. Metadata is the data in the forestry basic database. Item-related web pages are the items related to the items obtained by the crawler (Fig. 8).
Viewing forestry national standards
After entering the search interface, the user clicks to display forestry national standards and the interface will show the general situation of forestry national standards, including the name of national standards, table structure, and the number of records (Fig. 9). The specif ic contents of the national standard input to forestry national standards is shown in Fig. 10.
Searching the entire network
When there is no query term in the Thesaurus, the user is prompted to perform a complete network search (Fig. 11). At this point, the system will return a list of key related pages for user reference (Fig. 12).

Fig. 12 Key related pages from the network
Conclusion
With the emergence of a large number of forestry data, how to store, calculate and carry out data mining has become a frontier topic in the development of forestry information technology. We analyzed the existing mature big data technology, and choose Spark as the core technology, designs and implements a mining system with massive forestry data storage and analysis. Major work has been done in the following aspects:
(1) The function modules were understood, the storage function of the forestry big data system discerned by HDFS, the data acquisition of forestry science website carried out using network crawler tools, and the function of forestry data mining recognized using Co-word Analysis and clustering algorithms. The system data query and interaction function were accomplished.
(2) The big data technology has been studied, the advantages and disadvantages of each big data framework compared, and Spark was selected as the core framework of the system. The application scenarios and functions of various tools and frameworks in Spark ecosystem were analyzed.
(3) The forestry big data mining system was designed as well as the plan design and the function module design.A large data mining system with three-tier architecture and the ability to store, analyze and manage large forestry data was created.
(4) Forest land data was examined by cluster analysis using forestry big data mining system. The results show that the system could get the co-word analysis results of forest land keywords to determine the subject structure of the research f ield. Compared with traditional clustering algorithms, the spectral clustering algorithm implemented in the system has a good accuracy and conf irms the reliability and practicality of the forestry data mining system.
Publisher’s NoteSpringer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affi liations.
杂志排行

Journal of Forestry Research的其它文章
- Sacred groves of India: repositories of a rich heritage and tools for biodiversity conservation
- Relationship between H 2 O 2 accumulation and NO synthesis during osmotic stress: promoted somatic embryogenesis of Fraxinus mandshurica
- Changes in leaf stomatal traits of diff erent aged temperate forest stands
- Somatic embryogenesis and plant regeneration in Betula platyphalla
- Hydrogen peroxide as a systemic messenger in the photosynthetic induction of mulberry leaves
- Production and quality of eucalyptus mini-cuttings using kaolin-based particle f ilms