基于CRF模型的英文词性标注研究
2021-04-29刘星宇宁慧张汝波
刘星宇,宁慧,2,张汝波
1. 哈尔滨工程大学 软件学院,黑龙江 哈尔滨 150001
2. 哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001
3. 大连民族大学 机电工程学院,辽宁 大连 116600
如今,人工智能已经逐步走进人们的生活中,并不断为人们提供高质量的服务,所以自然语言处理技术也变得尤为重要。作为人工智能技术的核心,自然语言处理的词性标注分析在多个领域中都有所应用,如机器翻译、文本分析、问题解答及机器人科学等领域都具有很高的应用价值,在未来还会有更高的发展空间。而条件随机场用于词性分析有着更加准确、灵活的特点,因此使用条件随机场进行词性分析的研究具有重大的意义。
针对使用适当的模型或结构来提升词性标注结果准确率的问题,本文使用实验对隐马尔可夫模型和条件随机场模型进行了模拟实现,同时使用条件随机场的不同特征方程进行了多组实验,并对比了每组实验的准确率,结合实验结果得到最终结论。
1 相关技术
1.1 条件随机场
条件随机场是指在给定一组输入随机变量条件下,输出另一组随机变量的条件概率分布模型,并假设输出的随机变量构成马尔可夫随机场。在条件随机场的定义中,若要求条件概率分布P(Y|X),要求条件随机场符合在给定随机变量X的情况下,随机变量Y需满足:
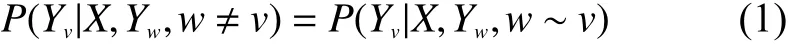
式中:w~v表示与v结点直接有边连接的所有结点w;w≠v表示除了v结点本身以外的所有结点w[1]。
若式(1)对任意结点v成立,则P(Y|X)被称作是一个条件随机场。
“条件”指它是个判别式模型P(Y|X),“随机场”指它是个无向图模型,无向图模型并不关注于每个事件是否有因果关系,并不涉及条件概率的分解。对于边没有方向的无向图模型,它只代表2个事件是有联系的[2]。条件随机场最大的优点是可以着眼于整个句子定义更灵活性的特征函数,并让所有特征可以进行全局归一化,能够求得全局的最优解,甚至可以在特征函数中判断句子是否以问号结尾成为一个问句,从而更加准确地判断每个位置的单词更加接近正确的词性。其中,利用了yt本身的特征称为状态特征,利用了yt-1和yt之间关系的特征则称为转移特征[3]。由于词性标注是一种链型结构,所以可得条件随机场模型的链型表示为图1所示。

图1 CRF链型模型
1.2 英文词性标注过程简介
对于词性标注问题,可以分解为以下3点:learning问题、marginal prob及MAP Inference。首先learning问题就是进行参数估计,也就是参数学习,即利用训练集来训练特征函数来生成并调整特征值,这里的训练集应该由一个个已经标注好的样本构成,并且数量必须尽可能多才能将参数调整到概率上最为准确[4]。marginal prob指的是边缘概率计算问题,即对于某一个单词个体,标注成某词性yt的概率值,即可以用P(yt|x)来表示。MAP Inference指的就是decoding问题,即用一定的算法,找到这样的一种标注序列,使得条件概率达到最大,最后选择这种标注作为结果标注进行预测[5]。
2 英文词性标注过程的研究
2.1 边缘概率计算
对于边缘概率计算,当特征值通过一定算法学习好后,特征值就可以被使用进行词性的预测,而在对整个句子进行预测时,实际上是对每个单词相应的算法进行预测,这时就是要计算其边缘概率,这里使用处于中间推导过程的势函数乘积的公式[6]:
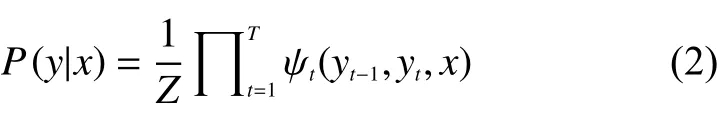
需要注意的是,这里为了运算及表达方便,忽略考虑了边界结点,相当于在最初的y1结点前补充一个y0结点,方便运算处理。式中,P(y|x)中的y代表的是y1,y2,…,yT的所有y值,然而,当进行边缘概率计算时,即计算某一结点的标注P(yt=i|x)时,需要将yt以外的结点值都进行积分处理,又由于y的分布是离散分布,所以对于y的积分即为求和运算,所以可以推导出:
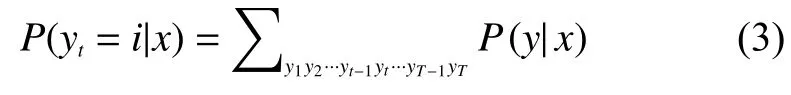
对公式进行简单的分解来简化表达,可以得出:

将原来的势函数乘积公式(2)代入式(4),可以得到:
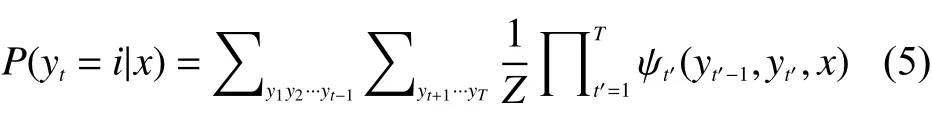
对式(5)进行时间复杂度分析,可以看出,若一个词共有S种标注方式,总共有T个yt构成,也就是T个要标注的词,再计算最后T规模的连乘,总时间复杂度为O(|S|T×T),是指数级的时间复杂度。对于指数级时间复杂度,计算量过大过于复杂,这种暴力求解的方法可以认为是不可解的,所以需要对其进行进一步的化简,化简思路就是将连加进行后移,移到连加运算的主体参数上,使连加提前进行,做到简化运算。可以将公式分为两部分,一部分是y1,y2,…,yt-1,一部分是yt+1,yt+2,…,yT,记为Δ左和Δ右,所以公式可化为式(6)的形式[7]:

下面分别来分析,首先对于Δ左,可以将其展开以便观察和化简为

其中,若一个词共有S种标注方式,yt是属于S集合内的。同理,相对于左侧公式,也可以写出右侧公式:

此时,可以根据动态规划的思想对公式进行化简,就转变成了前向-后向算法的形式。在Δ左中,对于一个线性链结构,积分(对于离散分布也就是连加)可以按照链型的次序进行,将每一步骤的积分结果作为下一步积分的公式参数,就形成了动态规划转移方程的形式,即前向算法的形式。例如,对于 ψ1(y0,y1,x)这个式子,由于y0只存在于本式中,而y1除了本式中存在,还存在于ψ2(y1,y2,x)中,所以对于此式可以将y0进行积分,仅保留y1作为下一步积分的公式参数,此时式子就可以写成:

进一步思考后不难发现,y2既存在于此公式中,也存在于 ψ3(y2,y3,x)中,依此类推,最后,Δ左式可以化为
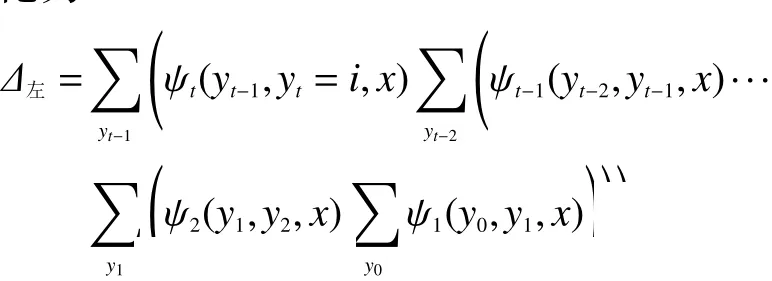
为化简可以将式(9)中多余的括号去掉进行合并,得到式(10):

设 αt(i)表示y0,y1,…,yt-1的所有势函数以及yt=i的左半部分势函数,根据前向算法以及概率图模型中精准推断的变量消除法的思想,原式可以进一步转化为

所以同理,也可以写出yt右侧的后向算法表达式转化为

因此综上所述可以得到边缘概率
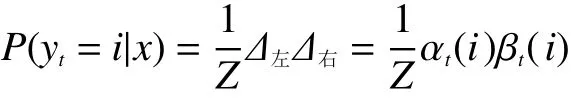
2.2 参数学习
在条件随机场中的参数学习问题就是求特征方程的特征值,这里可以使用梯度上升算法,即通过不断找出偏导数的绝对值最大的方向进行移动,找到最大值[8]。设特征值分别为λ和η,则其表达式为

为简化运算,又由于对数函数为单调函数,所以可以将公式对数化,将连乘转化成连加的形式:
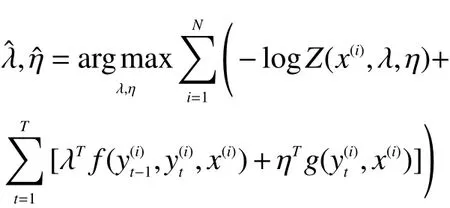
此时将argmax后的部分看成整体,作为一个函数,记为L,根据梯度上升算法原理,需求出λ和η的 偏导 ∇λL和 ∇ηL,寻找梯度最大方向,一步步找到λ和 η的最大值[4]。下面进行求偏导,如式(7):
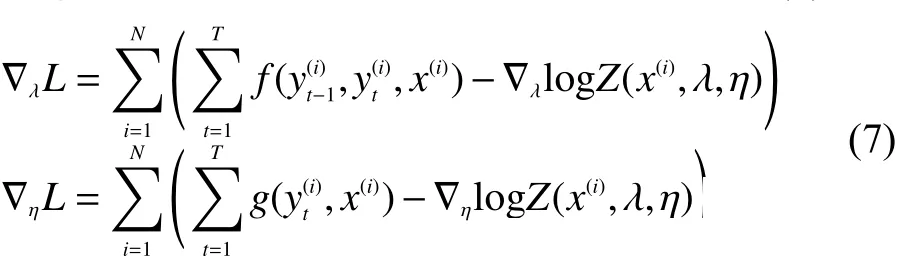
式 中: logZ(x(i),λ,η)称作log-partition function,是一种配分函数,它在指数族分布中是一个非常重要的概念,对其求导所得到的是所对应的充分统计量的期望,其偏导数经过推理后可得
对于边缘概率的计算,依然使用前向-后向算法来求解,即边缘概率计算的过程,唯一的不同点在于本公式为对2个y变量的求解:

综上所述,对于 ∇λL和 ∇ηL,整理可得:

根据梯度上升算法以及上述所求的结果,最后求得参数λ和η[9]:

2.3 词性预测
条件随机场的词性预测所用核心算法为维特比算法,在机器学习中,维特比算法是一种应用非常广泛的算法,它基于动态规划思想,在求解隐马尔可夫模型、条件随机场的预测等问题中均用到了该算法。实际上,维特比算法不仅是很多自然语言处理的解码算法,也是现代数字通信中使用最频繁的算法[10]。
维特比算法的目的是要求出图2中的一条路径,使得该路径对应的概率值最大。对应图2来讲,假设每个时刻x可能取的值为3种,如果直接求解结果的话,会有3N的排列组合数,其中底数3为篱笆网络宽度,指数N为篱笆网络的长度,因此时间复杂度达到无法运算的指数级,计算量非常大,若设每个时刻x可能取的值为D种,则时间复杂度为O(DN)。维特比利用动态规划的思想来求解概率最大路径,使得时间复杂度正比于序列长度,复杂度为O(ND2),从而很好地解决了问题[11]。

图2 维特比算法示意
3 实验过程与结果分析
3.1 隐马尔可夫模型实验
在使用隐马尔可夫模型来实现词性标注时,核心是隐马尔可夫模型的三大矩阵[4],分别是初始状态概率分布矩阵(π矩阵)、输出观测矩阵(A矩阵)和状态转移矩阵(B矩阵)[12]。
其中,初始状态概率分布矩阵指的是第一个单词被标注成各个词性的概率矩阵,若设第一个结点前有一个虚拟的start结点,可以看成在start虚拟结点到第一个结点的概率。输出观测矩阵指的是在当前位置为词性n的情况下,出现单词m的概率。状态转移矩阵指的是在前一个位置为词性n’的情况下,当前位置的词性为n的概率[13]。
1)先将训练集读入。在读入的过程中将单词和词性转化为编号数字存储在数组中以便于进行操作,同时记录不同单词总数M以及词性种类总数N。
2)根据M和N构造相应大小的初始状态概率分布矩阵、输出观测矩阵和状态转移矩阵。
3)再次读入训练集,对三大矩阵进行填充。根据各个单词是否是在首位置出现、出现当前词性时出现了当前单词的次数、上一个词性到当前词性的组合出现的次数,对三大矩阵进行不断累加,训练完毕后将其概率化,即除以矩阵当前行数组总长,将当前数字转化为0-1之间的概率数字。
4)实现维特比算法的函数。输入参数为所要预测的句子x、三大矩阵、最终预测总数组arr。将预测好的词性标注情况逐一增加到最终预测总数组中,以便于最后求解准确度。并且在其中将矩阵间的乘积提前进行对数化,将乘积化为加和,简化运算,以加快运算速度[14]。实现细节如下所示:

5)使用校验集来对所训练好的三大矩阵进行运算,将校验集切分为一个个的句子,不断地使用维特比算法进行计算,每次计算完都会将预测出的词性标注情况加入到最终预测总数组中,最后与校验集原有的正确标注进行对比,得出准确率。实现细节如下:

3.2 条件随机场模型实验
对于使用条件随机场进行词性标注模拟实现,这里使用的是Sklearn_crfsuite库来对参数进行学习和训练,同时为确保结果对比的有效性,训练集和校验集选用的仍然是和HMM相同的数据库。
1)进行数据集读取。将训练集和校验集分割成一个个句子,由于句子之间是没有联系的,所以可以以每个句子为单独样本来进行实验。将各个句子的单词、词性信息加入到train_sents和test_sents数组中。
2)进行特征方程的构造。这里用6组实验,利用不同的思想构造了特征方程,下面分别介绍这6组特征方程组。
①对word2features0特征方程组,使用的是较为共有的特性,例如是否为数字、末尾几个字母是否相同、首字母是否为大写等特性,来进行参数训练。如下:

②对word2features1特征方程组进一步思考是否可以将较为普遍的共性进行具体化。根据这个思想,通过广泛搜集信息,找到并整理出了较为完整的词性后缀集合,通过对后缀的具体要求来构造特征方程,将共性进行具体化[15],部分构造代码如下:

③对于word2features2特征方程组,在word2 features1的基础上,将后n个字母相同的偏向共性的条件注释掉,只保留后缀对词性的要求,来分辨后n个字母相同的条件和具体后缀的条件是否会因为有重叠而影响词性预测准确率。
④对于word2features3特征方程组,保留后n个字母相同的条件和相对其他后缀来说较为共性的特殊后缀,观察更加共性是否是影响词性预测准确率的关键条件,特殊后缀构造代码如下:
# 特殊后缀
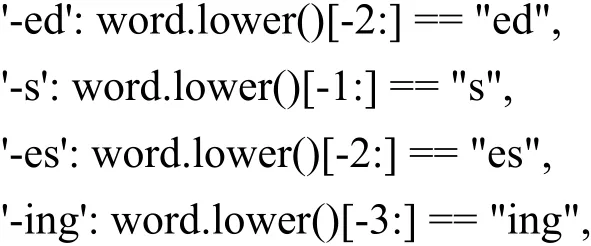
⑤对于word2features4特征方程组,保留后1、2、3、4个字母相同的条件,以及后缀为5个字母及以上的具体后缀条件,观察词性预测准确率,构造代码如下:

⑥对于word2features5特征方程组,根据word2 features4的构造情况进行对比,保留后1、2、3个字母相同的条件,以及后缀为4个字母及以上的具体后缀条件,观察词性预测准确率。
3)根据Sklearn_crfsuite库的要求,构造三维数组参数。其中,对于训练集,第一维为每个句子,第二维为每个句子中的每个单词,第三维为每个单词所拥有的特性。这里的特性就是用第二步的特征方程来判断出来的是否符合各个特征方程的布尔值。对于校验集,第三维为每个单词所拥有的正确词性标注,用于最后判断预测词性标注的准确性。
4)使用Sklearn_crfsuite库中的API并传入相应的参数,使用拟牛顿法进行参数学习,使用维特比算法进行词性预测,并将结果与校验集进行比对,若标注的词性相同,则same+=1,最后将same除以标注总数sum,求出最终准确率,代码实现如下:


3.3 实验结果分析
经过隐马尔可夫模型以及条件随机场的各个不同的特征方程对相同训练集进行训练以及相同校验集进行校验,得出准确率的结果如表1和表2所示。
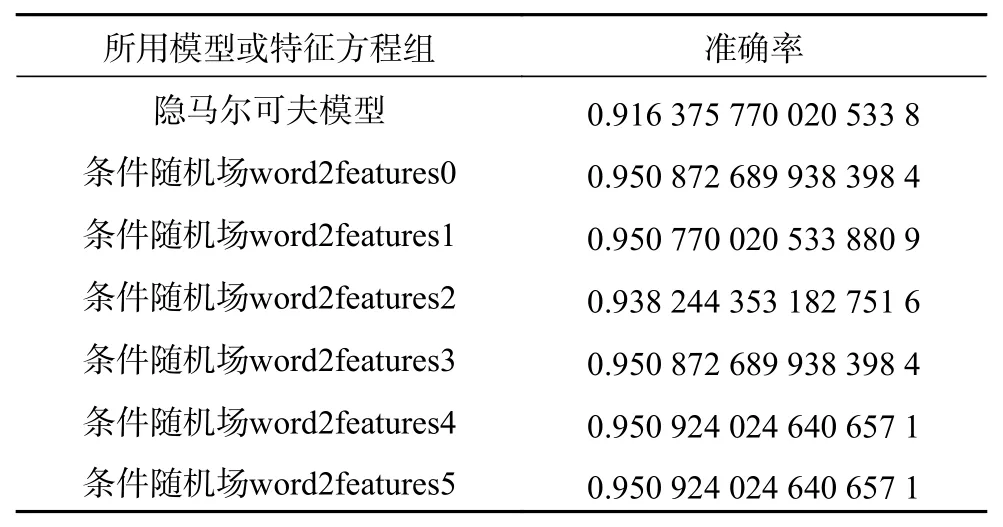
表1 数据库1词性预测准确率结果
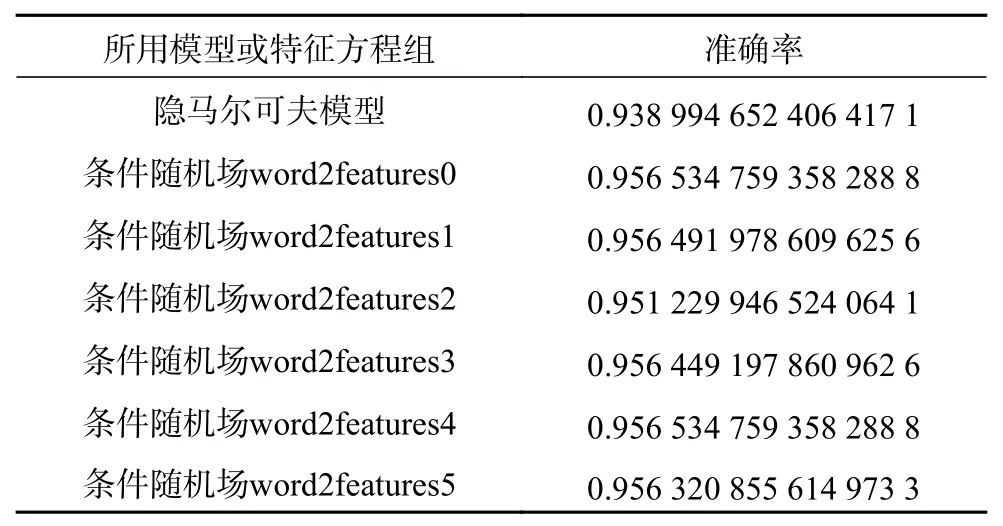
表2 数据库2词性预测准确率结果
可以看出,2个数据库中隐马尔可夫模型的准确率都是完全低于条件随机场的,证明了条件随机场模型更适用于词性标注问题,也证明了条件随机场对于解决词性标注问题的全面性和灵活性。
对于条件随机场模型不同特征方程之间的比较,可以看出2个数据库中word2features4所达到的准确率最高,也就是说,使用相对共性笼统的后n个字母相同加上相对具体的n+1及n+1以上个字母的后缀结合使用所达到的准确率最高。同时,2个数据库中word2features2所达到的准确率在条件随机场模型中都是最小的,也就表明若不用相对共性的后n个字母相同的方法构造特征函数,而只用后缀法来构造特征函数时,准确率会降低,也就是说,共性构造是不可少的一部分,可以大大提高预测准确率。
综上所述,在进行英文词性标记时,条件随机场模型表现出更好的效果,相对其他模型有着更准确的预测。同时,选择使用相对共性的后n个字母相同加上相对具体的n+1及n+1以上个字母的后缀结合使用所达到的准确率最高。
4 结论
本文对隐马尔可夫模型和条件随机场模型进行了模拟实验,同时使用条件随机场的不同特征方程进行了多组实验,并对比了每组实验的准确率。结果表明,条件随机场对于解决英文词性标注问题有着更大的优势,并且将共性的特征与相对具体的后缀特征结合使用所达到的词性标注准确率最高。
