基于改进密集网络与二次回归的小目标检测算法
2021-04-29张正道
奚 琦,张正道,彭 力
(江南大学物联网工程学院,江苏无锡 214122)
0 概述
小目标检测技术在人们日常生活中使用较广泛[1-3],被应用于多个场景。例如,无人驾驶场景下利用检测摄像头捕获图像中较远和较小的目标,医学图像场景下检测较小尺度的病灶,工业制造场景下检测材料中微小瑕疵等。目前在计算机视觉领域,小目标并未被严格定义为分辨率或者像素点总量小于某尺度的物体,其通常根据研究对象或实际应用场景来定义。本文根据文献[4-5]对小目标的定义,将图像中尺寸小于20 像素×20 像素的物体定义为小目标。相较图像中常规尺度目标,小目标尺度占比更小、像素更少且外形特征不明显,因此,小目标检测成为目标检测亟待解决的难题之一。
近年来,传统Haar[6]、HOG[7]和SHIFT[8]等基于手工设计特征的目标检测算法因检测效率低、检测目标单一、鲁棒性差且速度慢逐渐被淘汰。随着人工智能技术的深入发展,基于卷积神经网络自动学习特征的目标检测算法因具有较高的检测速率和检测精度,被广泛应用于目标检测中的各个领域。现有基于卷积神经网络的目标检测算法主要包括Fast R-CNN[9]、Faster R-CNN[10]等基于候选区域的算法以及YOLO[11]、单激发探测器(Single Shot Detector,SSD)[12]等基于回归的算法。其中,SSD 算法检测性能相对更好,但由于其仅依靠分辨率较高的Conv4_3(尺寸为38×38)浅层特征图进行小目标检测,而Conv4_3 浅层特征图在模型中位置靠前,其特征提取能力不足,且上下文语义信息不够丰富,导致SSD 算法对小目标检测效果较差。
研究人员在改进SSD 算法的基础上对小目标检测性能进行研究并取得众多成果。文献[13]基于残差网络提出一种反卷积单激发探测器(Deconvolutional SSD,DSSD),将SSD 的基础网络部分由VGG[14]网络替换为特征提取能力更强的ResNet[15]网络,并在金字塔网络后设置反卷积模块增加上下文信息,但这种由上到下逐层生成特征金字塔的方式计算量较大且增加多次融合操作,其在英伟达TITAN X 显卡上每秒仅能检测9张图像,无法进行实时性目标检测。文献[16]提出一种多特征图融合的Rainbow单激发探测器(Rainbow SSD,RSSD),采用反复堆叠最大池化和反卷积的方法来融合不同尺度的卷积层特征图,但其计算量较大且特征图融合方向单一,检测性能较DSSD 提升不明显。文献[17]设计一种功能融合单激发探测器(Function Fusion SSD,FSSD),通过双线性插值进行上采样来建立轻量级特征融合模块,提高了浅层特征图的特征提取能力,其检测精度和检测速度较DSSD 和RSSD 有较大提升,且检测速度接近SSD。文献[18]提出一种多尺度反卷积单激发探测器(Multi-Scale Deconvolutional SSD,MDSSD),分别对Conv3_3 和Conv8_2、Conv4_3 和Conv9_2、Conv7 和Conv10_2 的特征图进行融合操作,形成3 个新特征图与原特征图共同进行预测,然而其虽然能满足实时检测的要求,但对检测精度的提升有限。文献[19]参考人类视觉的感受野设计出一种含有感受野模块的感受野单激发探测器(Receptive Field Block SSD,RFB-SSD),并借鉴GoogleNet 构建多分支卷积层来提高网络的特征提取能力。
本文在SSD 算法的基础上,提出一种采用改进密集网络和二次回归的小目标检测算法。以密集连接的DenseNet[20]替换VGG16 作为基础网络,通过优化DenseNet 结构提升特征提取能力和计算速度,利用基于区域候选的检测算法中默认框由粗到细筛选的回归思想,将目标与背景做简单区分后对其进行分类与位置回归以获取精确的默认框信息,设计特征图融合模块提取特征信息,同时采用特征图尺度变换方法进行特征图融合,并利用K-means 聚类方法获取初始默认框的最佳长宽比。
1 SSD 算法
1.1 网络结构
SSD 网络作为基于回归的目标检测算法的典型网络,其利用单个深度卷积神经网络结合6 个不同尺度的特征图进行预测获得目标的类别和位置信息。SSD 网络由基础网络和额外增加网络构成,其结构如图1 所示。
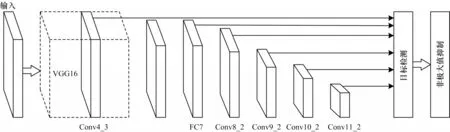
图1 SSD 网络结构Fig.1 Structure of SSD network
在SSD 网络中,基础网络由VGG16 网络去掉最后两个全连接(FC)层并新增两个卷积(Conv)层而形成,额外增加网络将Conv4-3 特征图经过不断下采样操作形成尺度逐渐变小的特征图。
1.2 存在的问题
SSD 算法对常规尺寸目标检测精度较高且检测速度较快,虽然其通过特征金字塔网络可提取不同尺度的特征图进行目标检测,但对小尺寸目标检测效果较差。
1.2.1 特征提取不足
对于小尺度的目标,SSD 算法主要采用分辨率较高的Conv4_3 浅层特征图进行检测,但Conv4_3 浅层特征图在模型中位置靠前,其特征提取能力不足,且上下文语义信息不够丰富。深层特征图的语义信息较多,但其经过多次卷积、池化与下采样后其尺度很小,会丢失部分位置信息和重要的细节特征,且其默认框尺度较大,不适合小目标检测。
1.2.2 正负样本失衡
SSD 算法在6 个不同尺度的特征图上共生成8 735 个默认框,具体生成过程如图2 所示。

图2 默认框生成过程Fig.2 Process of default boxes generating
在模型训练时对匹配成功的默认框进行类别判断和位置回归处理,由于待检测图像中背景占比较大,而检测目标占比较小,因此大部分默认框在匹配后会被标记为负样本,大量负样本损失占模型总损失的绝大部分,从而削弱正样本损失对总损失的影响,导致检测模型训练效率严重下降,模型优化方向也会受不同程度的干扰,造成模型参数无法更新到最佳值。
2 本文改进算法
2.1 基础网络
目标检测算法通常选择在分类任务中表现较好的网络作为基础网络。基础网络是将分类网络模型去除全连接层后得到的网络,其负责提取图像特征,对目标检测算法性能影响较大。SSD 算法使用VggNet作为基础网络,YOLO 算法以GoogleNet 作为基础网络,DSSD 算法利用ResNet 作为基础网络。
不同分类网络的大小不同,该差异会影响到目标检测算法速度,因此,需选择合适的分类网络提高算法的检测准确率和速度。增加分类网络层数或加宽网络结构可提升基础网络的性能,但会造成网络参数量增大进而降低检测速度。DenseNet 从特征的角度出发,通过重复利用特征和设置旁路,大幅降低网络参数量并缓解了梯度消失的现象,可取得较好的检测效果,其网络结构如图3 所示。本文使用Pytorch 框架对VggNet、ResNet、GoogleNet 以及DenseNet 4 种网络的分类性能进行对比分析,以Top-5 错误率和每秒浮点运算次数(Flops)作为评价指标,分析结果如表1 所示。由表1 可知,DenseNet的Top-5 错误率仅为2.25%,每秒浮点运算次数为19 亿次,其具有最低分类错误率和较低的分类速度,因此本文将其作为基础网络来替换SSD 算法中的VGG16 网络。

图3 原始DenseNet 网络结构Fig.3 Structure of original DenseNet network
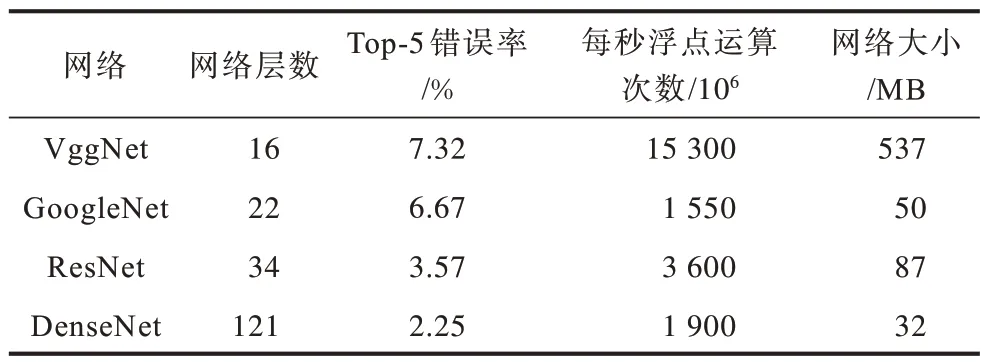
表1 不同网络的分类性能Table 1 Classification performance of different networks
DenseNet 第1 个卷积核的大小为7×7,步长为2,输入图像在经过第一层卷积和池化下采样后,其特征信息还未被充分提取就已部分丢失,从而影响到后续特征提取,因此,本文对DenseNet 进行改进。采用3 个连续的3×3 卷积核代替原始DenseNet 中的7×7卷积核。3 个连续的3×3 卷积相较7×7 卷积在同样尺度感受野下能更有效地减少网络参数量,并降低输入图像特征信息的损耗,最大程度地保留目标的相关细节信息,从而有效提取特征信息。改进DenseNet网络层参数如表2 所示。通过改进DenseNet 得到尺度为19 像素×19 像素的特征图后,再经过下采样得到尺度分别为10 像素×10 像素和5 像素×5 像素的特征图用于下一步检测。
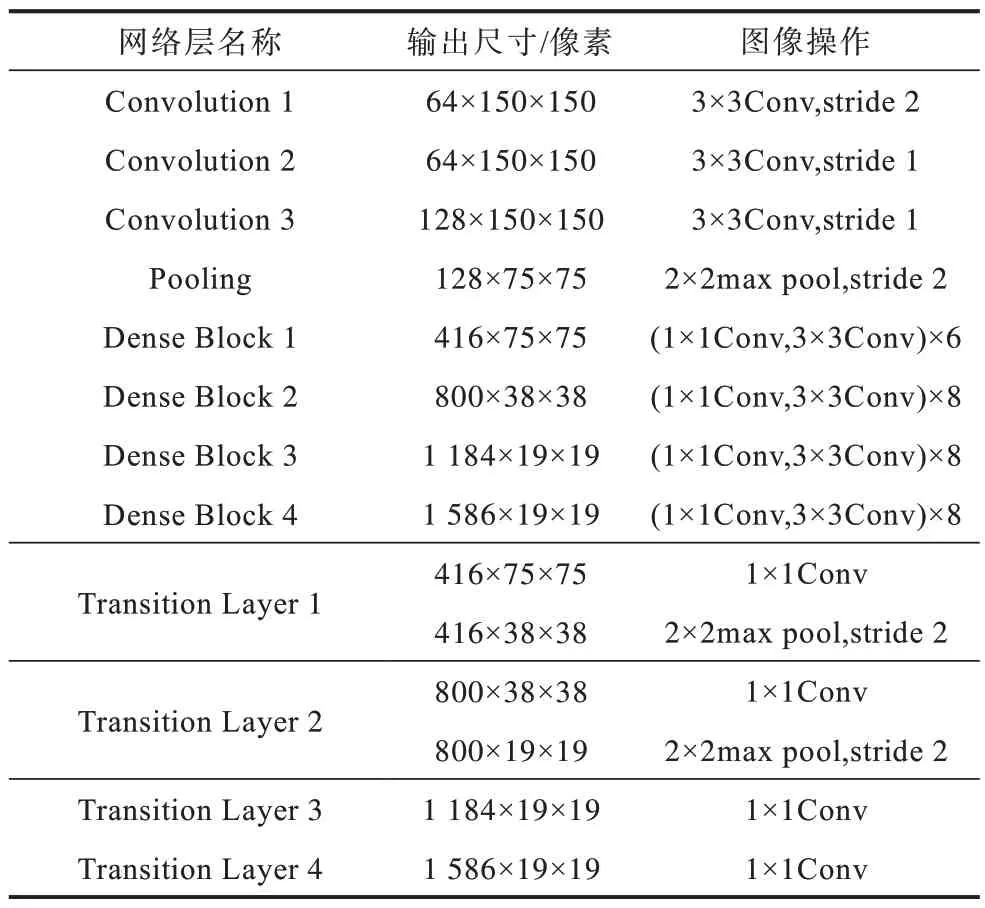
表2 改进DenseNet 网络层参数Table 2 Network layer parameters of improved DenseNet
2.2 二次回归
Faster-RCNN 等基于候选区域的目标检测算法需对候选区域进行预处理,虽然此类算法检测精度较高,但由于存在全连接层和大量网络参数,因此检测速度较慢,无法进行实时检测。SSD、YOLO 等基于回归的目标检测算法为提高检测速度从一定程度上牺牲了检测精度,同时基于默认框、预测框和物体真实框之间的关系对网络进行训练,并对默认框进行回归处理。
类别严重不平衡是导致基于候选区域的目标检测算法精度低于基于回归的目标检测算法的主要原因。在SSD 等一阶段端对端的检测算法中,原始图像经过卷积神经网络后会生成近万个默认框,但其中目标默认框数量占比很小,负样本与正样本的数量比例高达1 000∶1,造成正负样本比例严重失调。为解决类别不平衡的问题,文献[21]提出在线进行难例挖掘,利用bootstrapping 技术对简单的负样本进行抑制,从而提高模型训练效率,然而该方法仅适用于批次数量较少的模型。文献[22]对交叉熵损失函数进行重新定义,通过在标准交叉熵损失函数中添加控制权重使模型在训练时更注重占比较少的困难正样本,但其并未从本质上解决类别不平衡的问题。
本文提出一种Ours-SSD 算法(以下称为本文算法),其网络结构如图4 所示。利用二阶段非端对端目标检测算法中默认框由粗到细筛选的回归思想,设计串级SSD 目标检测网络结构。第一部分SSD(ARM)对物体和背景进行简单二分类与粗略定位,第二部分SSD(ODM)根据第一部分的二分类结果过滤大部分简单负样本,然后进行目标类别的判断与位置回归。串级多次回归的网络结构具有更高的检测精度。本文为增加浅层特征图的语义特征和深层特征图的细节信息,在两个串级部分之间加入特征融合模块。

图4 本文算法网络结构Fig.4 Network structure of the proposed algorithm
2.3 特征图尺度变换
原始输入图像在经过多次卷积、池化和下采样后会得到尺寸逐步减小的特征图,为增加浅层特征图的语义特征和深层特征图的细节信息,需将不同尺度的特征图进行融合。在特征图融合之前,由低分率的底层特征图生成高分率的特征图,具体步骤为:1)在DSSD算法中使用反卷积方法先对特征图及其四周填充0,再对其进行卷积和裁剪,去除右侧最后一列和下方最后一行后即得到高分率特征图;2)在FSSD 算法中使用双线性插值上采样方法,对特征图中无像素值的空位进行插值,将特征图放大到预设尺寸。然而反卷积方法和双线性插值上采样方法均会增加网络参数量,从而延长计算时间,降低算法实时性。为避免降低算法检测速度,本文提出一种特征图尺度变换方法,在不增加参数量的情况下扩大特征图尺寸,特征图尺度变换过程如图5 所示。先将输入特征图在通道维度上划分为C个通道长度为r2的特征图,然后将每个通道数为r2、尺寸为H×W的特征图转换成通道数为1、尺寸为rH×rW的特征图。
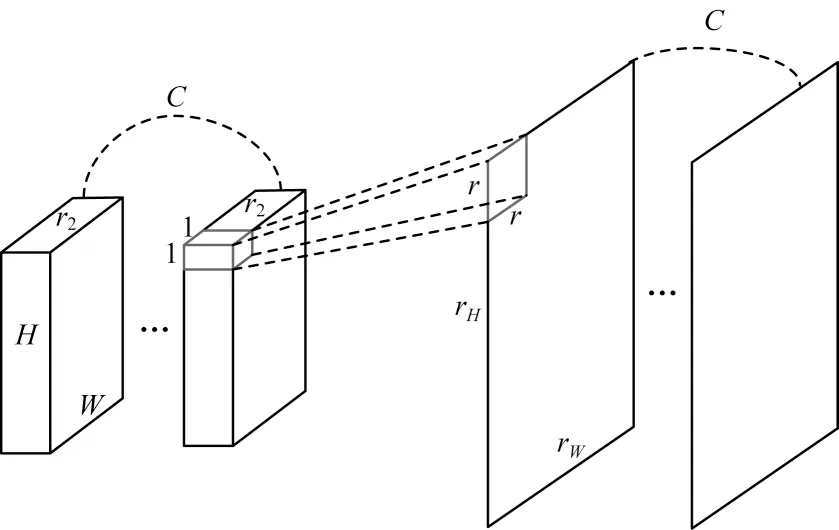
图5 特征图尺度变换过程Fig.5 Process of scale transformation of feature map
2.4 Default boxes 聚类分析
SSD 算法的检测精度和速度受网络中默认框数量的影响,数量较少的默认框能提高检测速度但会降低检测精度,数量较多的默认框虽能提升检测精度却会降低检测速度。此外,SSD 算法默认框的长宽比是根据检测人员经验手工设置,虽然其长宽比会在模型训练过程中自动调整,但如果初始默认框的数量和长宽比更符合数据集中标注目标的特性,则能加快模型收敛并提升检测精度和速度。
本文通过对训练集中所有标注目标框的尺寸进行K-means 聚类计算得到默认框最佳长宽比。在K-means 聚类算法中,选择距离作为目标相似度的评价指标,若目标距离越小则相似度越大。经过K-means 聚类计算可获得距离接近且独立的类簇结果,其具体步骤如下:
1)确定一个k值作为算法聚类分析后所得集合的个数。
2)随机选择训练集中k个数据点作为初始质心。
3)计算训练集中各个点与k个质心的距离,将其划分到距离最近的质心所在集合。
4)训练集中所有目标形成k个集合,重新计算各集合的质心。
5)若新计算的质心和原质心的距离小于预设标准,则算法完成。
6)若新计算的质心和原质心的距离大于预设标准,则需重复进行步骤3~步骤5。
本文为实现检测精度和检测速度的平衡,先选择先验框个数为5(k=5),保证算法检测速度所受影响较小,然后利用K-means 算法对数据集中所有标注框进行聚类分析。
3 实验与结果分析
3.1 实验数据集
本文实验采用PASCAL VOC2007 公共数据集(以下称为VOC 数据集)和自制航拍小目标数据集(以下称为AP 数据集)。VOC 数据集包含交通工具、动物、人物以及生活用品等20类常见目标,共21 503张图像。AP 数据集含有22 761 张源自不同传感器和采集平台的航拍样本图像,包含飞机、车辆、船舶以及建筑物等13 类小尺度目标。AP 数据集中各场景图像的背景较复杂,且目标具有更多尺度变化。采用平移、旋转和灰度变换等方法扩充数据集,以防止模型训练时出现过拟合现象。通过K-means 聚类计算,选定VOC 数据集默认框长宽比例分别为{1.0,0.5,2.6,0.7,1.3},航拍数据集默认框长宽比设定为{1.00,0.80,2.70,0.59,1.73}。VOC 数据集的K-means 聚类结果如图6所示(彩色效果参见《计算机工程》官网HTML版)。
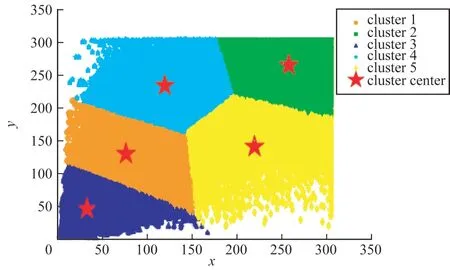
图6 VOC 数据集上K-means 聚类结果Fig.6 K-means clustering results on VOC dataset
3.2 训练步骤与参数配置
在模型训练初始化过程中,采用ImageNet 数据集对本文算法中基础网络DenseNet 进行预训练,具体步骤为:1)将所有图像数据转换为VOC 数据集的格式;2)根据训练样本数量扩充数据集数据;3)利用随机梯度下降法优化损失函数以获取最优网络模型参数。
由于在小目标检测场景下尺度为0.2的最浅层特征图较大,无法检测出较小尺寸的目标,因此将最底层缩放比例Smin调整为0.08,并使用随机梯度下降SGD算法对参数更新如下:初始学习率为0.001,权值衰减项为0.000 5,动量项为0.9,批大小为32。此外,学习率设置为0.001,迭代次数为300。本文算法在Spyder编译器上编写,并基于Pytorch框架进行模型训练。实验环境为64位的Ubuntu16.04系统,Intel®CoreTMi5-8500@3.00 GHz 6 核处理器,英伟达GTX 1080 Ti 显卡,11 GB 显存以及16 GB 内存。
3.3 结果分析
在VOC 数据集和AP 数据集上将本文算法与Faster-RCNN、R-FCN、SSD、RSSD、DSSD 以及YOLO V3 等主流目标检测算法进行对比分析。采用检测平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)作为算法检测性能的评价指标。
3.3.1 VOC 数据集上的实验
上述算法在VOC数据集上的检测结果如表3所示。

表3 不同算法在VOC 数据集上的检测结果Table 3 Detection results of different algorithms on VOC dataset
可以看出,本文算法的mAP 值高于其他算法,其中,较Faster-RCNN 算法提高9.1 个百分点,较SSD 算法提高5.1个百分点,较DSSD算法提高3.7个百分点,较YOLO V3算法提高1.7个百分点,YOLO V3算法与本文算法的检测性能最接近。当检测目标为椅子和鸟类时,YOLO V3 的AP 值较本文算法分别低5.5 个百分点与0.6个百分点。此外,本文算法在检测盆栽等尺度较小的目标时,检测效果明显优于其他算法。
3.3.2 AP 数据集上的实验
不同算法在AP 数据集上的检测效果和检测结果分别如图7 和表4 所示。由图7 可以看出,本文算法的检测效果优于其他目标检测算法。由表4 可见,本文算法的检测指标值均高于其他目标检测算法。当检测目标为船舶和储罐时,本文算法的AP值较YOLO V3算法分别高4.1个百分点与8.4 个百分点。

图7 不同算法的检测效果图Fig.7 Detection effect images of different algorithms

表4 不同算法在AP 数据集上的检测结果Table 4 Detection results of different algorithms on AP dataset
为更好地比较不同算法对小目标的检测效果,本文采用精度-召回率(Precision-Recall,PR)曲线评估算法的检测性能。在PR 曲线中,若算法的精度和召回率均最大,则表明算法的检测性能最好。图8为当检测目标为飞机和船舶时上述算法在不同召回率下的PR 曲线。可以看出,本文算法的精度和召回率均优于其他算法。由上述分析结果可知,本文算法对小目标检测的精度和召回率更高,在不同场景下均能有效进行检测。
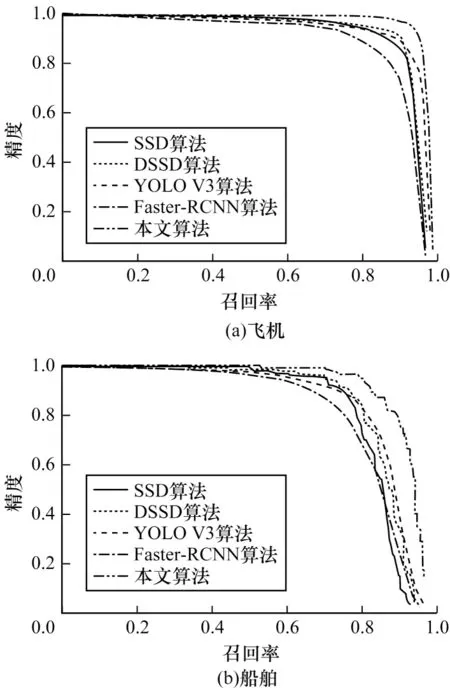
图8 不同算法的PR 曲线Fig.8 PR cruves of different algorithms
4 结束语
本文针对SSD 算法对小目标特征提取能力不强的问题,提出一种改进的SSD 小目标检测算法。将SSD 算法中骨干网络由VGG16 替换为密集连接的DenseNet 提高检测精度,设计二次回归的网络结构解决候选区域默认框正负样本不平衡的问题,采用特征图尺度变换方法在不引入额外参数量情况下融合特征图,并通过K-means 聚类分析获得默认框的个数和最佳长宽比。在PASCAL VOC2007 公共数据集和自制航拍小目标数据集上的实验结果表明,该算法的检测平均精度均值较改进前SSD 算法分别提升5.1 个百分点和9.5 个百分点,较RSSD、DSSD 等目标检测算法检测精度更高,检测速度达到58 frames/s,具有良好的实时检测性能。后续将优化模型结构,进一步提高计算效率。
