基于面部特征点的单幅图像人脸姿态估计方法
2021-04-29傅由甲
傅由甲
(重庆理工大学计算机科学与工程学院,重庆 400054)
0 概述
基于图像的人脸姿态估计是指在输入图像中确定人脸在三维空间中偏转角度的过程,通过姿态估计得到头部转动方向和眼睛注视位置,是多视角环境下的人机交互、视觉监视的基础。
人脸姿态估计的途径多种多样,如激光雷达、立体相机、阵列相机或深度传感器等,虽然从这些途径中获取的人脸姿态角精度很高,但在实际应用中由于受限于环境条件往往不能得到,因此仅从单幅图像中估计人脸姿态的方法变得非常实用。
单幅图像由于可利用的信息量少,使得人脸姿态估计成为一个十分复杂的模式识别问题。基于深度学习的方法因其训练过程依赖大量的标注样本和硬件设施,训练时间长,因而在一定程度上限制了其应用的范围。本文针对以上问题,提出一种基于面部特征点定位的头部姿态估计方法。
1 相关工作
基于图像的人脸姿态估计方法主要有基于深度学习的方法、基于子空间分析的方法和基于模型的方法3 类。
基于深度学习的姿态估计方法是目前使用较多的方法。文献[1]使用基于脸部关键点的热力图神经网络回归器(heatmap-CNN)预测人脸姿态。文献[2]使用在300W-LP 上训练的基于多均方误差损失的卷积神经网络直接从图像中预测人脸姿态。文献[3]利用单独的CNN 融合DCNN 的中间层,并运用多任务学习算法处理融合特征,通过任务之间的协同作用提高各自任务的性能。文献[4]使用细分空间结构获得更精细的偏转角度预测。文献[5]采用由粗到细的策略,在粗分阶段中人脸姿态被分为4 类,然后送入到细分阶段被进一步求精,以此增加对光照、遮挡和模糊的鲁棒性。
基于子空间分析方法假设人脸姿态和人脸图像的某些特征间存在某种关系,通过统计学习建立这种关系实现姿态鉴别。文献[6]提出一种将线性回归与部分潜在输出混合的方法,该方法结合了无监督流形学习技术和回归混合的优点,可以在遮挡情况下预测头部姿势角度。文献[7]提出一种多层次结构混合森林(MSHF)方法,从随机选择的图像块(头部区域或背景)中提取多结构特征,使用MSHF回归得到头部轮廓,再选择相应图像块的子区域输入到MSHF 进一步得到头部姿态。文献[8]在连续局部回归方法中将HoG 特征和广义判别性公共向量相结合,以减小头部姿势估计中的误差。
基于模型的方法利用人脸几何模型表示形状,建立模型和图像之间的对应关系,然后通过某种方法实现姿态估计。文献[9]提出一个统一框架来同时处理人脸特征点定位、姿态估计和面部变形,该框架使用基于模型的头部姿态估计进行级联增强,实现迭代更新。文献[10]利用人眼、鼻孔的位置实现头部姿态的分类估计。文献[11]在鼻下点、双眼眼角和嘴角点的基础上通过牛顿迭代法估计人脸在双眼可见状态下绕3 个坐标轴的偏转值。文献[12]提出基于四叉树描述子的姿态估计方法,该方法基于脸部标记点来逐层细分人脸区域,通过测量描述子与参考模型间的距离来估计人脸的姿态方向。与深度学习方法相比,虽然基于模型的单张图像人脸姿态估计方法的精度受到标记点精度的影响,但其具有计算简单、占用内存小、利于部署在移动设备上的优点。
本文提出一种建立关联特定人脸标记点定位器的稀疏通用3D 人脸模型方法,通过关联Adrian Bulat 人脸特征点定位器[13],使其能适应平面内任意旋转的且具有自遮挡的大姿态角度的人脸姿态估计。通过3 个公共数据库上的测试,验证了算法适用于俯仰角在[-50°,50°]、偏航角在[-90°,90°]和桶滚角在[0°,360°]的大范围人脸姿态的估计,具有较高的平均姿态估计精度。
2 人脸姿态估计算法
2.1 人脸稀疏3D 模型
基于模型的人脸姿态估计方法受到人脸标记点的影响,而不同的人脸标记点定位器定位的人脸标记点偏好有所不同,在从人脸检测到姿态估计的自动化过程中,用于人脸姿态估计的3D 通用模型要与相应的人脸标记点定位器相匹配才能获得较好的姿态预测精度。
本文使用Adrian Bulat 人脸标记点定位器,定位出CMU Multi-PIE 数据库[14]中337 个正面人脸的标记点轮廓,并运用ASM 人脸规格化方法[15]对标记点轮廓集进行归一化,形成如图1(a)所示的平均人脸。将图1(b)所示的Candide-3 模型[16]中用于姿态估计的五官特征点正面对齐到图1(a)的平均人脸上,保留对齐后的五官特征点的z坐标,而其x、y坐标则使用图1(a)的平均人脸相应点的x、y坐标替换,形成与Adrian Bulat 人脸标记点定位器相匹配的稀疏通用3D 模型。

图1 归一化平均人脸与Candide-3 人脸Fig.1 Normalization mean face and Candide-3 face
2.2 人脸姿态估计算法
人脸偏转坐标轴如图2 所示,其中,绕X轴的偏转称为俯仰(pitch),绕Y轴的偏转称为偏航(yaw),绕Z轴的偏转称为桶滚(roll)。
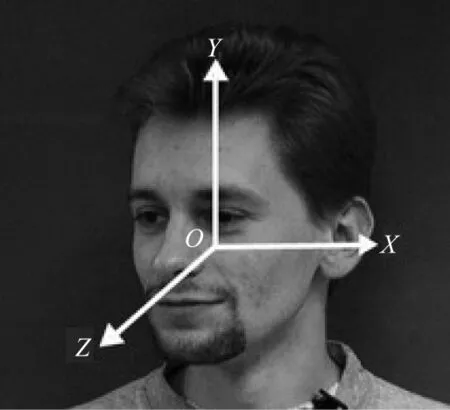
图2 人脸姿态及其坐标轴Fig.2 Facial pose and its coordinate axes
本文使用Adrian Bulat 人脸特征点定位器完成人脸五官特征点(双眼眼角、嘴角、鼻尖和鼻下点)的定位,如图3(a)所示。该定位器适应于平面内旋转人脸的特征点定位,而且除了可见的特征点外,还能定位出那些被遮挡或者不可见的人脸特征点。在人脸五官特征点基础上,本文采用图3(b)所示的INewton_PY+R 算法估计人脸姿态。该算法为了减小损失函数中的估计参数,将同时估计人脸绕3 个轴的旋转过程转换为搜索稀疏模型绕Z轴一定旋转范围内的绕X、Y轴的最佳旋转角的过程,消除损失函数中的roll角参数。通过将3D模型上的鼻下点与图像上的鼻下点对准,约束模型只能以鼻下点为中心旋转来消除损失函数中的平移参数,使得损失函数仅保留缩放因子、pitch 角和yaw 角3 个参数。

图3 本文人脸姿态估计方法流程Fig.3 Procedure of proposed facial pose estimation method
设s为3D 模型全局尺寸参数,tx和ty分别为3D模型向XY平面平行投影后的X及Y方向平移参数。若已知人脸roll 角度γ,采用如下方法估计人脸深度方向偏转角度α和β:将3D 模型的鼻下点与图像上人脸的鼻下点重合并固定,然后调整s、α、β,使图像上的其他特征点与经二维投影后的3D 模型上的相应点对齐(满足最小距离平方和)。
最小距离平方和公式如下:

将式(2)代入式(1),并由限制条件式(3)使用内点罚函数方法构造增广目标函数(损失函数):

其中,rk>0 为障碍因子。
使用修正牛顿法[17]计算满足式(4)的图像人脸在指定γ角度情况下的pitch 和yaw 的偏转参数α和β,以及3D 人脸模型的缩放系数s。
将人脸平面内旋转角度的估计与平面外偏转角度估计相结合,以双眼中心连线倾斜角θ为基础,通过搜寻θ±90°范围内最佳偏转角α、β来获得人脸绕各坐标轴偏转的最终估计角度。具体算法如下:
算法1迭代求解α,β,γ

3 实验结果与分析
3.1 实验数据集
本文使用了3 个公共人脸库来对本文方法进行验证。第1 个是CMU Multi-PIE 人脸数据库,该数据库包含337 个人,每个人的多视角图像由15 个围绕在该对象周围的摄像机同时拍摄完成,如图4 所示。该数据库一共包含750 000 张不同表情、光照和视角的人脸图像。

图4 CMU Multi-PIE 多视角人脸及其摄像机分布Fig.4 CMU Multi-PIE multi-view pose and its distribution of cameras
第2 个是BIWIi Kinect Head Pose 人脸数据库[18]。该数据库包含20 个人(6 个女性和14 个男性),超过15 000 张RGB 图像。每个对象坐在离摄像机前面1 m 左右的位置转动头部,由深度摄像机和视频摄像机记录下相应的动作,给出每个人脸头部的精确位置和姿态矩阵标签,如图5 所示。本文将其中能被人脸特征点定位器捕捉到的pitch 角为[-50°,50°]的共14 813 个样本作为测试样本。

图5 BIWI Kinect Head Pose 人脸库中的人脸样本Fig.5 Face samples from BIWI Kinect Head Pose face library
第3 个是Annotated Facial Landmark in the Wild(AFLW)数据库[19]。该数据库包含来自网络相册的大约25 000 个没有经过裁剪和调整大小的样本,大多数是RGB 图像,涵盖不同姿态、年龄、表情、种族以及成像条件。由于成像于非约束环境,数据库使用POSIT 算法[20]给出了这些样本中人脸的估计姿态。本文随机抽取其中5%的样本作为测试样本。
3.2 结果分析
本文在公共人脸库上进行了2组实验测试。第1组测试本文算法在3 个人脸库上的精度,第2 组则是对比本文算法与当前主要算法在精度上的差异。
第1 组实验包括在人脸库上进行精度测试的3 个实验。图6 是本文算法分别在3 个人脸库上的累计误差分布。以标签姿态的±15°为容许误差[4],由图6(a)可知,在Multi-PIE 上pitch 角满足容许误差的样本占比为97.0%,yaw 角占比为99.7%,roll 角占比为100%。同样,由图6(b)可知,在BIWI 上pitch 角满足容许误差的样本占比为97.7%,yaw 角占比为95.0%,roll 角占比为99.9%。由图6(c)可知,算法对AFLW 数据集pitch 角满足容许误差的样本占比为88.3%,yaw 角占比为85.8%,roll 角占比为96.8%。图7 展示了该算法在3 个人脸集上的测试样例及人脸方向线,其中,N为法向量,U为垂直切向量,T为水平切向量,第1 行为Multi-PIE 数据集,第2 行为BIWI 数据集,第3 行为AFLW 数据集。

图6 本文算法在3 个数据集上的位姿估计累计误差分布Fig.6 Pose estimation cumulative error distribution of the proposed algorithm on the three datasets

图7 裁剪后的部分测试结果Fig.7 Partial test results after tailoring
为对精度进一步评估,表1 为本文算法在3 个公共人脸测试集上的平均误差统计结果,包括平均绝对误差(MAE)、标准差(STD)和均方根误差(RMSE)。

表1 本文算法在公共人脸数据集上的误差Table 1 Error of proposed algorithm on the public face datasets(°)
从表1 可以看出,在Multi-PIE 上的实验效果好于BIWI,除Multi-PIE 数据库中的人脸质量明显好于BIWI 的外,另一个原因在于BIWI 中人脸的位置偏移带来的误差。
人脸的空间状态由头部姿态和位置组成。当人脸不在摄像机光轴中心时,透视投影会使人脸相对于摄像机产生偏转效应,如图8 所示,摄像机位于坐标系∠x′o′z′的原点,同一姿态的人脸在a、b、c3 个位置产生的图像ac、bc、cc并不相同。因此,图像上人脸呈现的姿态是由人脸实际姿态和由位置产生的偏转姿态两部分构成,这也是本文算法所测的人脸相对于摄像机的姿态。从图4 可知Multi-PIE 数据库中所有人脸位于摄像机光轴中心,而如图5 所示,BIWI数据库中人脸由于自身运动使一些样本偏离摄像机光轴较大,造成实际姿态与相对姿态间产生差异。本文使用文献[21]中的方法计算了BIWI 中人脸相对摄像机的姿态,表2 展示了使用该姿态作为标签姿态的统计结果,相比于实际姿态作为标签,算法的误差明显减小。

图8 透视投影下不同位置人脸产生的偏转Fig.8 Offset of rotation produced by different face positions under perspective projection
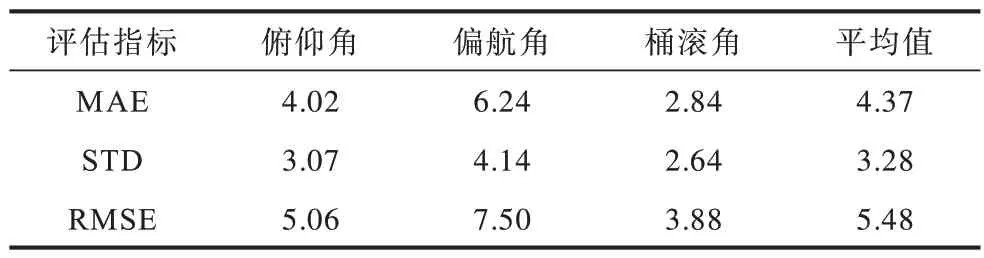
表2 本文方法在BIWI 人脸数据集上的误差Table 2 Error of proposed method on the BIWI face dataset(°)
另一方面,不同于BIWI 中的精确人脸姿态,AFLW 数据库中的人脸姿态是由算法生成的粗略姿态。为对比本文算法估计姿态和AFLW 中由POSIT算法生成的标签姿态的准确度,本文分析了所有误差超过容许误差(±15°)的测试样本,根据估计姿态和标签姿态的对比结果将它们分为3 组,其中,“估计姿态好于标签姿态”组包含了通过观察估计姿态明显好于标签姿态的样本,“标签姿态好于估计姿态”组包含了标签姿态好于估计姿态的样本,“不确定”组包含了仅凭观察无法确定两者哪个更准确的样本。表3 列出了各组样本占测试样本的比率。图9 显示部分估计姿态好于标签姿态的样本以及两者的人脸方向线。

表3 AFLW 中估计姿态误差较大的测试样本中各组样本比率Table 3 Sample ratio of each group in the test sample with large estimated attitude error in AFLW %

图9 估计姿态与标签姿态的比较Fig.9 Comparison of estimated pose and label pose
由表3 可知,在所有估计姿态超过容许误差的样本中,10.03%的样本的估计姿态明显比标签姿态更合理,而仅有5.15%的标签姿态好于估计姿态。而且随着估计姿态与标签姿态差异的增加(error >25°),估计姿态好于标签姿态的样本个数增加明显,这意味着本文算法的精度非常接近POSIT 在AFLW 上的结果,甚至可能更接近真实的人脸姿态。表4 显示了从估计误差超过容许误差的样本中剔除估计姿态好于标签姿态的样本后的本文算法的误差统计结果。
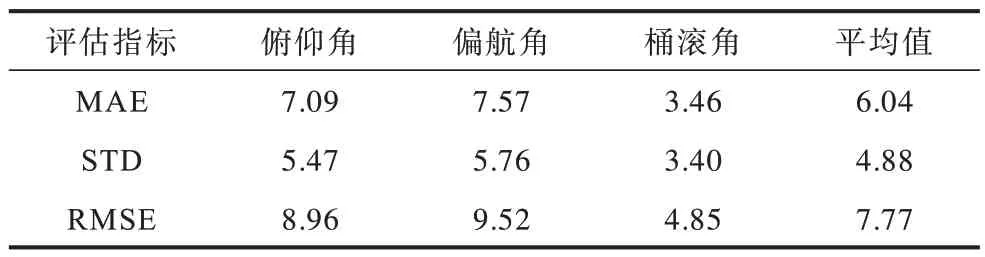
表4 剔除估计姿态好于标签姿态样本后的精度Table 4 Pose errors of the proposed algorithm after removing the samples with measured poses better than label(°)
第二组实验是本文算法与当前主要人脸姿态估计算法在MAE 上的比较,包括与基于深度学习的算法和非深度学习算法的比较。表5 是不同算法在BIWI 数据库上的比较,其中,文献[4]实现平台为Nvidia GTX 1080 Titan GPU,文献[5]实现平台为Nvidia GeForce GTX 1080 GPU,文献[12]实现平台为i5 quad core CPU+Intel Iris 540 GPU,*为姿态参数估计时间。表6 是不同算法在AFLW 数据库上的比较,其中,文献[1,3]实现平台为Nvidia GTX Titan-X GPU,文献[12]实现平台为i5 quad core CPU+Intel Iris 540 GPU,*是表4 的统计结果。为对比本文算法与同类算法的性能,表中包含了一些当前效果最好的非深度学习算法。从表5、表6可以看出,本文算法平均精度超过了所有非深度学习算法,在BIWI 上比文献[12]的结果高1.32°。虽然在AFLW 上本文算法仅比文献[12]高0.7°,但本文算法的测试样本涵盖所有pitch在[-50°,50°]的姿态,而文献[12]则限定姿态范围pitch 在±30°,yaw 在±45°之间。在与基于深度学习的方法对比中,本文算法在BIWI 上比最好的文献[4]算法平均误差高0.77°,在AFLW 上比最好的文献[3]算法平均误差高0.87°,比其他的当前深度学习算法的结果,如文献[2,5]在BIWI 上的结果以及文献[1]在AFLW 上的结果要好。如果考虑到AFLW上的一些样本有着比标签姿态更准确的估计姿态的事实,则本文算法的MAE 指标将降至6.04°,与文献[3]的5.89°非常接近。考虑到本文算法没有利用样本学习,因此与主流深度学习算法性能接近。
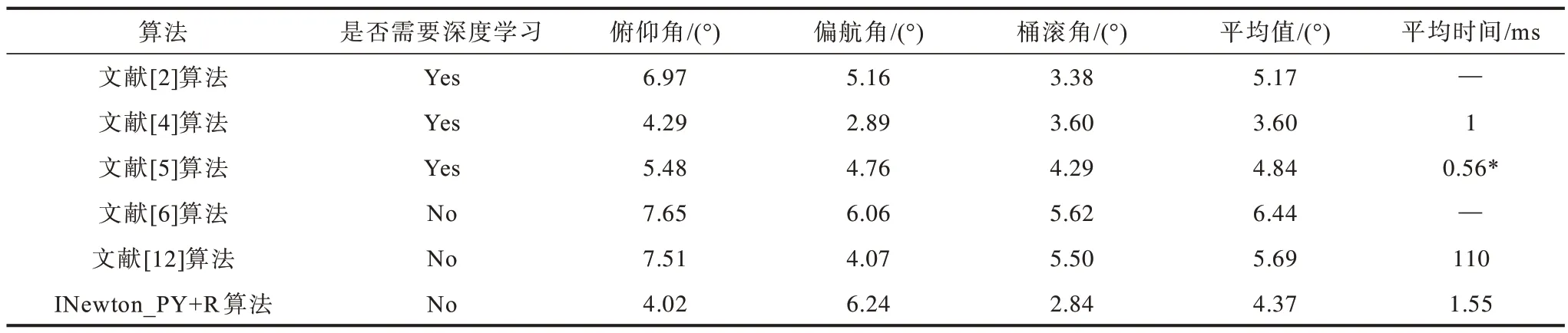
表5 BIWI 数据集上不同算法的MAE 对比Table 5 MAE comparison of different algorithm on BIWI dataset

表6 AFLW 数据集上不同算法的MAE 对比Table 6 MAE comparison of different algorithm on AFLW dataset
本文算法实验环境为Intel®CoreTMi7-3632QM 2.2 GB 单CPU,Windows 笔记本电脑,姿态参数估计在C++平台上运行时间小于2 ms,远低于同类方法的时间。虽然高于深度学习型方法[4-5],但本文运行平台为笔记本上的普通CPU,如果使用文献[12]所用的实时人脸特征点检测器[22],则有望超过文献[1-3]的运行时间,达到实时估计的效果。
4 结束语
本文提出一种使用稀疏通用模型估计单幅图像中人脸姿态的方法。该方法通过容易定位的人脸特征角点完成人脸的pitch、yaw 和roll 3 个角度的大范围姿态估计,在Multi-PIE、BIWI 和AFLW 3 个人脸库上表现良好。在BIWI 和AFLW 上的平均误差测试结果表明,姿态估计准确度高于目前主流的非学习类型的方法,与主流的学习型方法具有可比性。本文INewton_PY+R 方法不依赖于训练样本,不受限于硬件设备,通过关联特定人脸标记点定位器的稀疏通用三维人脸建模方法完成与不同的人脸特征点定位器搭配,可以实现人脸大姿态角度估计或者实时姿态估计的任务。下一步将引入稀疏可变模型及考虑透视投影下的人脸姿态估计,以提高算法的精确度。
